
NSDT工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器 - REVIT导出3D模型插件 - 3D模型语义搜索引擎 - AI模型在线查看 - Three.js虚拟轴心开发包 - 3D模型在线减面 - STL模型在线切割 - 3D道路快速建模
在这篇文章中,我们将回顾 ICCV’17 上提出的 Simple 3D Pose Baseline ,即用于 3d 人体姿势估计的简单而有效的基线,也称为 SIM。
1、模型简介
大多数估计单个人的人体姿势的工作都使用单个图像或视频。 SIM模型还估计单个人的人体姿势。 作者着手构建一个系统,在给定 2d 关节位置的情况下预测 3d 位置,以便了解误差来源。 在这项工作中,作者实现了一个轻量级且快速的网络,能够每秒处理 300 帧。 相对简单的深度前馈网络在 Human3.6M 上的性能比最佳报告结果高出约 30%。
2、网络设计
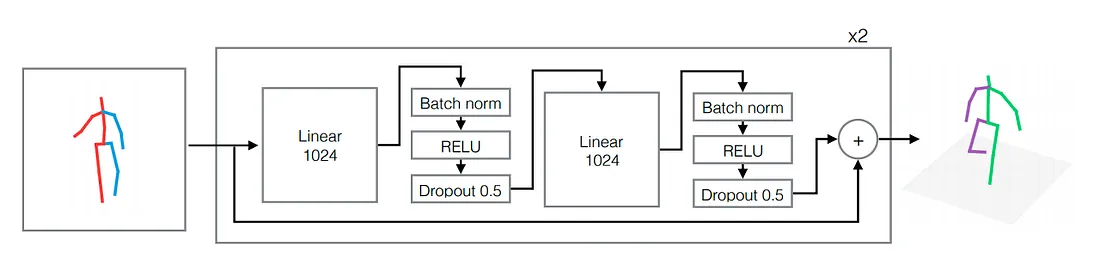
系统的输入是一组 2d 关节位置,输出是一系列 3d 关节位置。 在提取二维关节位置后,作者使用了一个简单的神经网络,该网络具有少量参数且易于训练。 网络的构建块是一个线性层,后面是批量归一化、dropout 和 RELU 激活。 该构建块重复两次,并且这两个块被包裹在残差连接中。 具有两个块的外部块重复两次。
3、实验评估
作者提出了两种类型的评估方案。
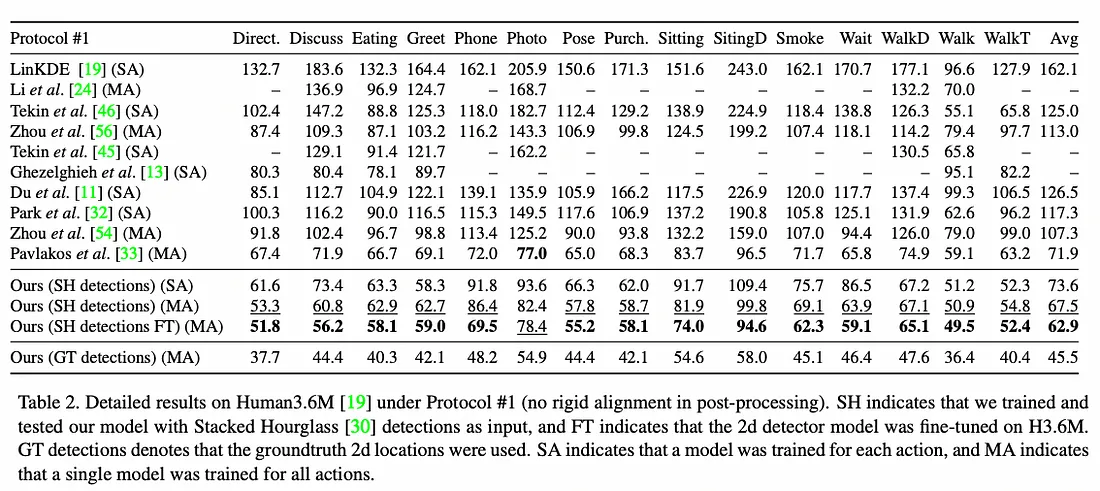
3.1 协议#1
协议 #1 是在根关节对齐后,计算所有关节和摄像机的地面实况与预测之间的平均误差(以毫米为单位)。 协议#1下的详细结果如下:
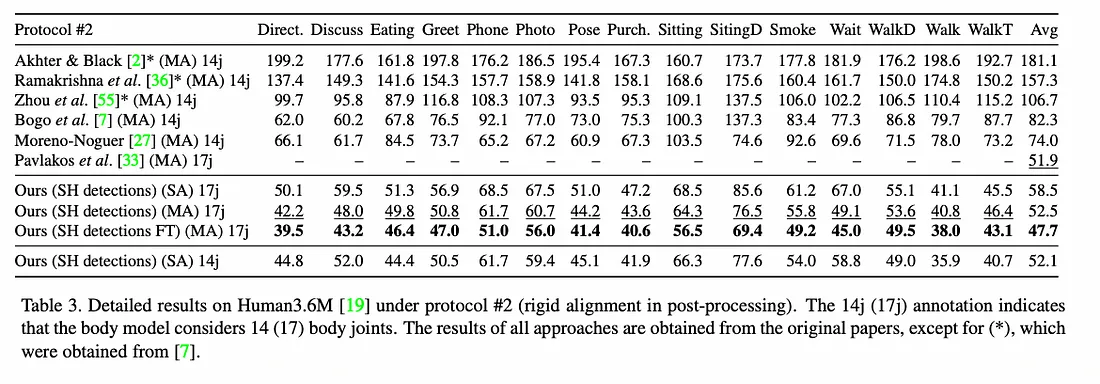
3.2 协议#2
协议 #2 使用严格变换后计算的误差。 在数学中,刚性变换(也称为欧几里德变换)是欧几里德空间的几何变换,它保留每对点之间的欧几里德距离。协议#2下的详细结果如下:
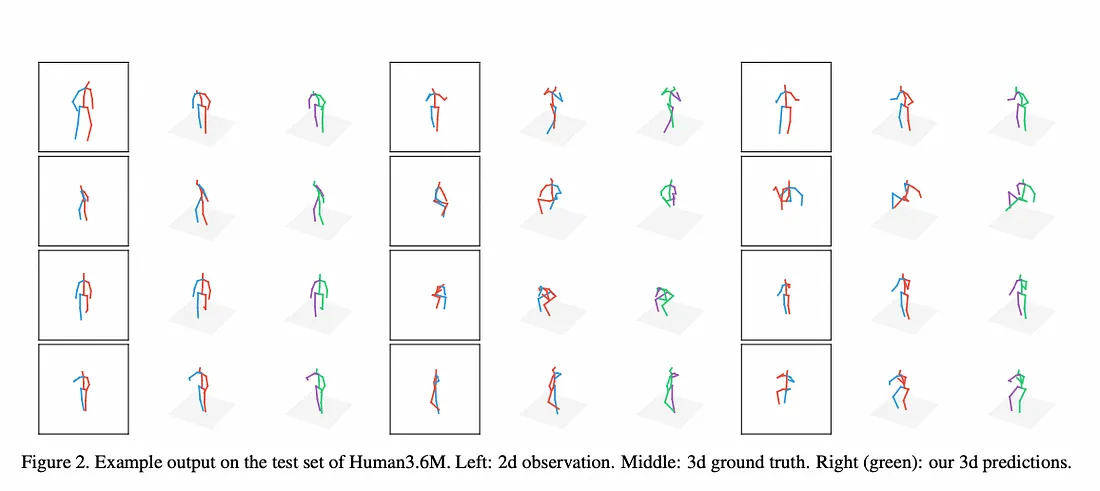
作者还给出了 Human3.6M 测试集的示例输出。 左边的图是 2d 观察结果,中间的图是 3d 基本事实,右边是 3d 预测:
4、模型实现
在这个存储库的帮助下,我使用 PyTorch 实现了模型,因此我想分享结果。
4.1 下载数据集
Human3.6M 是用于 3D 人体姿势估计任务的最大数据集之一。 它拥有 360 万个 3D 人体姿势和相应图像。 该数据集包含 11 名专业演员(6 名男性,5 名女性),每个主题有 15 个动作。 提供 2d 关节位置和 3d 地面实况位置。
对于数据预处理,作者根据相机的逆变换旋转和平移 3D 基础事实,使用工具程序来处理 human3.6m 的摄像头。
要做的第一件事是下载数据集。 尽管 Human3.6M 在官方网站上可用,但确认我的注册需要时间。 我在这里下载了预处理的数据集。 预处理后的数据集如下:
- train_2d.pth.tar:2D 训练数据集
- train_2d_ft.pth.tar:使用堆叠沙漏检测进行 2D 训练数据集
- train_3d.pth.tar:3D 训练数据集
- test_2d.pth.tar:2D 验证数据集
- test_2d_ft.pth.tar:使用堆叠沙漏检测进行 2D 验证数据集
- test_3d.pth.tar:包含 3D 验证数据集
- stat_3d.pth.tar:2D 输入和 3D 输出的 main/std,用于对数据进行非标准化并计算 MPJPE
4.2 训练
我首先下载数据集并将存储库放入我的谷歌驱动器中。 设置目录后,我运行 main.py。 你可以从 opt.py 更改运行选项:
# ===============================================================
# Running options
# ===============================================================
self.parser.add_argument('--use_hg', dest='use_hg', action='store_true', help='whether use 2d pose from hourglass')
self.parser.add_argument('--lr', type=float, default=1.0e-3)
self.parser.add_argument('--lr_decay', type=int, default=100000, help='# steps of lr decay')
self.parser.add_argument('--lr_gamma', type=float, default=0.96)
self.parser.add_argument('--epochs', type=int, default=200)
self.parser.add_argument('--dropout', type=float, default=0.5, help='dropout probability, 1.0 to make no dropout')
self.parser.add_argument('--train_batch', type=int, default=64)
self.parser.add_argument('--test_batch', type=int, default=64)
self.parser.add_argument('--job', type=int, default=8, help='# subprocesses to use for data loading')
self.parser.add_argument('--no_max', dest='max_norm', action='store_false', help='if use max_norm clip on grad')
self.parser.add_argument('--max', dest='max_norm', action='store_true', help='if use max_norm clip on grad')
self.parser.set_defaults(max_norm=True)
self.parser.add_argument('--procrustes', dest='procrustes', action='store_true', help='use procrustes analysis at testing')我训练了 200 个 epoch,在 Google Colaboratory(Pro+) 上大约需要 10~15 个小时。 训练后,创建检查点文件并使用 ckpt_best.pth.tar 进行测试。
4.3 测试
我通过加载 ckpt_best.pth.tar 测试了训练后的模型。
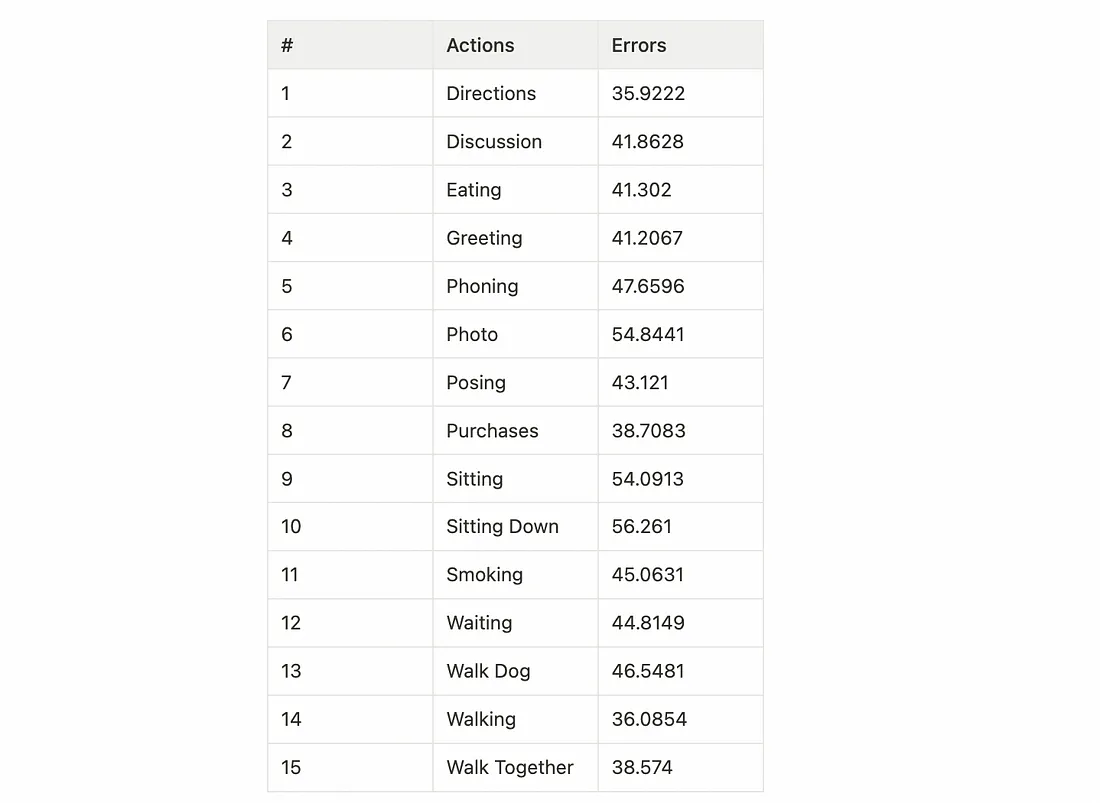
%run 'main.py' --load ('.\\test\\ckpt_best.pth.tar') --test原始版本的错误平均值是 45.5,我得到的是 44.4。

各个动作的错误如下:
原文链接:[PyTorch] Simple 3D Pose Baseline implementation (ICCV’17)
BimAnt翻译整理,转载请标明出处





