
NSDT工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器 - REVIT导出3D模型插件 - 3D模型语义搜索引擎 - AI模型在线查看 - Three.js虚拟轴心开发包 - 3D模型在线减面 - STL模型在线切割 - 3D道路快速建模
第一个计算机漏洞实际上是一个 bug。1947 年,一只飞蛾飞进哈佛大学的一台计算机,导致计算中断。当工程师打开计算机机箱时,他们很快就发现了导致问题的 bug。如今,bug 不太可能爬进我们的计算机并破坏计算流程。但是,原理保持不变。
软件 bug 是一种小的、难以察觉的错误,它会潜入我们的软件项目并导致问题。不幸的是,与发现飞蛾不同,软件 bug 更微妙,更难以检测。在大多数情况下,软件开发人员通过在他们的代码中犯一些乍一看无害的小错误来创建这些 bug。这就是存在许多帮助程序员调试代码的工具和方法的原因。
在本文中,我将深入探讨调试深度学习模型的主题并解释如何做到这一点。
什么是深度学习模型调试?
在软件调试中,程序员遵循一组预定义的规则,这些规则使他们能够找到问题的根源。从某种意义上说,它类似于沿着汉塞尔和格莱特创造的白色鹅卵石路径。在软件调试中,技巧在于将白色鹅卵石放在何处,以便可以轻松检测到错误。
然而,机器学习是不同的。我们不只是解决一个定义明确的任务,该任务对于给定的输入具有确定性的输出。我们正在训练一个模型,该模型捕获给定域中的数据结构,以便算法学习识别可用于预测未来示例行为的模式。模型的实现可能没有任何软件错误,但模型可能会有错误。例如,考虑一个使用错误预处理的数据进行训练的模型。显然,这是一个严重的限制,需要重新训练模型。但是,从软件的角度来看,模型没有任何问题,它对于提供的输入正常工作。
模型越强大,错误就越复杂。
以上情况对于深度学习尤其如此。有人可能会说,深度学习模型的主要优势在于它们能够从数据中学习相关特征。虽然这会产生强大的模型,但这也是一个挑战。就像可解释性是深度学习的一个严重问题一样,调试也可能特别具有挑战性。再次考虑错误预处理输入的示例。例如,我们使用有符号整数而不是无符号整数转换了输入图像的颜色。CNN 模型将学习如何处理错误的输入并仍然获得出色的结果。但是,当对新的、正确预处理的数据进行评估时,算法将失败。
在本文中,我们专注于调试深度学习模型。可以说,神经网络产生了最先进的预测模型。同时,它们在设计、调试和维护方面是最具挑战性的模型。我们将讨论这些挑战并提出应对这些挑战的策略。
如何调试深度学习模型?
基于神经网络的模型的设计应与其调试策略齐头并进。我们列出了在实施和评估深度学习模型时应始终遵循的基本步骤。
1、调试实现代码
深度学习的强大功能可能会隐藏软件错误。例如,我们在 Keras 中实现了以下卷积神经网络:
inp = Input(shape=(28, 28, 1))
x = Conv2D(32, kernel_size=(3, 3), activation="relu")(inp)
x = MaxPooling2D(pool_size=(2, 2))(x)
x = Conv2D(32, kernel_size=(3, 3), activation="relu")(inp) # bug: inp as x
x = MaxPooling2D(pool_size=(2, 2))(x)
…对于第二个卷积层,我们可能会复制第一个卷积层使用的代码,即 x = Conv2D(32, kernel_size=(3, 3),activation=”relu”)(inp),并忘记将输入更新为 x。该模型仍将起作用,只不过它比我们实际想要实现的模型更简单。
提示:创建测试,断言神经网络架构看起来符合预期,检查层数、可训练参数总数、输出的值范围等。理想情况下,将网络架构可视化,如图 2 所示:
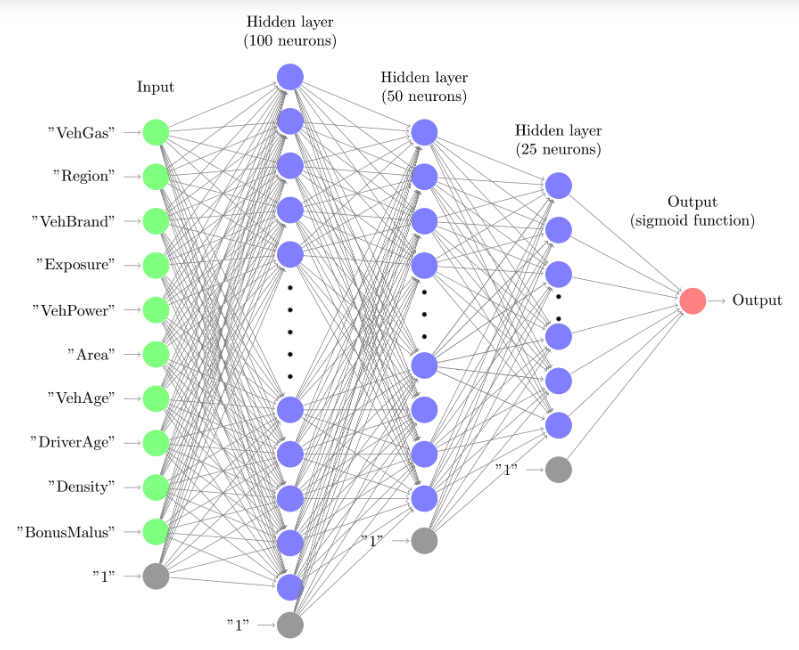
2、检查输入
由于索引错误而导致模型只提供部分特征等简单错误可能很难发现。即使提供的特征较少,深度学习模型仍能正常工作。更一般地说,如果我们在预处理输入数据时出现系统性错误,深度学习的能力可能会变成一种祸害。模型将适应错误的输入,一旦我们修复了预处理错误,它将无法正常工作。
提示:实施断言输入特征的格式和值范围的测试。
3、仔细初始化网络参数
在开始训练之前,我们必须初始化模型的参数。最有可能的是,我们使用可用的平台 TensorFlow 或 PyTorch 来负责初始化。但是,由于参数是根据每个神经元的输入和输出数量选择的,因此在此阶段仍然可能出现错误。这是 Andrej Karpathy 关于初始化的建议。
寻找随机表现的正确损失。确保在使用小参数初始化时获得预期的损失。最好先单独检查数据损失(因此将正则化强度设置为零)。例如,对于使用 Softmax 分类器的 CIFAR-10,我们预计初始损失为 2.302,因为我们预计每个类的扩散概率为 0.1(因为有 10 个类),而 Softmax 损失是正确类的负对数概率,因此:-ln(0.1) = 2.302。
提示:更一般地说,编写测试来断言训练之前输入会产生预期的结果。在上面的例子中,我们可以断言,k 个预测类的概率分布的熵接近 -k ln 1/k = k ln k。
5、从简单开始并使用基线
观察到可以使用神经网络实现几个基本模型。例如,我们可以将线性回归实现为一个浅层网络,以均方误差作为损失函数。类似地,逻辑回归可以通过一个浅层网络实现,以 S 型激活函数作为输出,以二元交叉熵作为损失函数。图 3 显示了通过从图 2 中的网络中删除隐藏层而得到的逻辑回归模型:
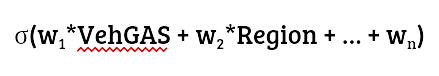
其中 w1 到 wn 是可学习参数。
此外,我们可以使用具有线性激活函数的自动编码器来模拟 PCA。因此,将我们针对基本算法的神经网络实现的结果与我们从 scikit-learn 等平台中公开可用的相同算法实现获得的结果进行比较是一个好主意。这将使我们能够尽早发现不同类型的错误,例如权重初始化错误、学习率问题、错误输入预处理等。
提示:编写测试,断言我们的深度学习实现和一些现成算法的相同输入的结果是可比的。
5、检查中间输出
我们可以将深度学习模型视为(非线性)函数的串联。连续的层计算越来越复杂的特征。因此,我们可以跟踪这些新特征。这对于深度卷积神经网络模型尤其直观,因为每个层计算的特征都可以可视化。
与标准软件调试类似,我们设置断点以允许我们跟踪分配给程序中变量的中间值,我们也可以跟踪深度学习模型的中间输出。
特别是,我们可以使用调试工具。
提示:编写测试来检查每个层之后的输出值。此外,使用可视化工具显示模型的不同层。
6、确保我们的模型设计正确
你应该特别注意:
- 特征归一化。输入特征具有相同的量级非常重要,因此对于不同尺度的特征,使用适当的归一化技术非常重要。常用的选择是标准化和最小-最大归一化:
1、标准化
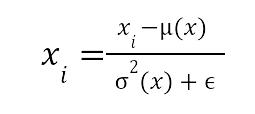
2、最小-最大归一化
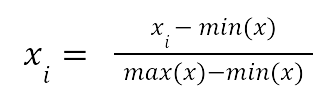
在上面,x 是输入向量,xi 是各个坐标。
- 防止梯度消失。对于某些损失函数,我们可能会遇到梯度消失的问题。每一层的梯度都乘以后续层的梯度。考虑 S 型函数 σ(z) = 1/(1+e-z)。对于 z 的大值或小值,梯度将接近 0,因此我们在将其用作激活函数时应小心谨慎。经验法则是仅对输出层使用 S 型函数或更一般的 softmax。提示:检查每一层输出的测试应该检查中间层的输出是否接近 0。
- 批次大小。在训练神经网络时,使用小批次方法是标准做法。在这种情况下,我们使用数据的子样本来计算损失,并使用反向传播计算的梯度下降来更新网络参数。当然,小批次的确切大小取决于计算硬件约束和数据集大小。它认为,小的批次大小会导致许多训练周期,而较大的批次大小会导致训练缓慢。
- 批次规范化。我们通过规范每个输入特征来规范每个层的输入。这里需要记住的是,平均值和方差是针对每个小批次计算的,但在推理过程中,它们是针对整个训练数据集计算的。(我们可能希望针对单个示例评估模型。)提示:编写测试以确保每个层的输入确实经过了规范化。
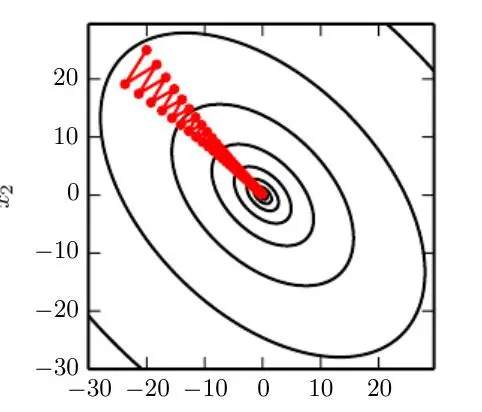
- 围绕最佳值振荡。需要调整学习率以解决复杂函数曲率的变化。具体来说,不同方向的梯度可能相差很大,因此使用恒定的学习率可能会导致振荡。实践中流行的选择是 Adam 方法(自适应矩估计),其中学习率在每次迭代后通过使用过去梯度的指数递减平均值进行调整。
7、防止过度拟合
另一个需要记住的重要点是,模型应该能够推广到新数据。神经网络的强大功能很容易导致过度拟合,以至于我们在输入实例中学习到噪音。这里我们列出了一些常用的正则化技术。
- 节点权重正则化。使用权重正则化是标准做法,它可以防止某些权重变得太大,从而导致输入过度拟合。标准选择是 L1 和 L2 正则化:我们在损失函数中添加一个项 λ||W||p,其中 W 是模型的可学习权重,>0 是正则化的强度。
- Dropout。在训练期间,我们随机删除给定层中的一小部分神经元。这可以防止神经元变得过度指定并学习更可能是随机伪影的非常特殊的模式。
- 提前停止。在设计模型时,我们会在未用于训练的数据子集(即所谓的验证数据)上评估其性能。一旦验证性能在一定数量的时期内似乎没有改善,我们就会停止训练模型。
- 数据增强。为了强制模型仅学习数据中的重要模式,我们可以通过增强数据集来生成一些人工数据。对于计算机视觉应用,我们可以旋转或镜像输入图像,或更改颜色,以使生成的新数据仍然看起来像自然图像,参见图 5 的示例。请记住,数据增强对于某些领域可能具有挑战性,我们在应用时应小心谨慎,以免在训练数据中产生偏差。

8、记录和跟踪实验
神经网络使用不同类型的随机化来训练高质量的模型。内部层的权重根据不同的策略由随机权重初始化,我们可能使用 dropout 进行正则化,或者在设计模型时使用交叉验证。
提示:使用随机种子并存储随机化选择。
上述操作将使神经训练过程可重复,并简化错误的检测。特别是,某些问题可能是由底层硬件的差异引起的,可以通过重现完整的训练流程来检测。
9、要有耐心
请始终牢记,深度学习模型训练是一个缓慢且通常很痛苦的过程。有时我们可能会获得意想不到的结果,但这并不一定意味着我们的模型存在问题。例如,请考虑这个已经获得一定人气的 reddit 讨论。正如 Andrej Karpathy 所报道的:
“有一次,我在寒假期间不小心离开了一个模型训练,而当我在一月份回来时,它已经是最先进的了。”
等待几个小时直到我们的模型性能开始改善可能看起来违反直觉,而且这种情况并不常见,事实上,提前停止是基于这实际上不可行的前提。但这不一定表明我们的模型存在问题。在高层次上,深度学习模型会针对给定目标搜索最佳参数集。针对这个目标进行优化不是一项定义明确的任务,而是一种基于反向传播概念的启发式方法,可以保证找到所讨论的损失函数的局部最优值。然而,具有数千个参数的非凸函数很可能有许多局部最小值。
因此,在某些情况下,搜索可能会收敛到对函数参数空间的详尽搜索,并且看起来没有取得任何进展。在最近的一篇论文中,研究人员设计了一组学习问题,这些问题的学习肯定会花费很长时间才能找到最佳解决方案。事实上,对训练数据的过度拟合是找到最佳解决方案的必要条件。当然,这是一个人为的设置,现实生活中的数据不太可能表现出相同的行为。但我们应该记住,检测复杂模式可能比我们的直觉告诉我们的要花费更长的时间,并花一些时间来检查我们的模型是否不是这种情况。
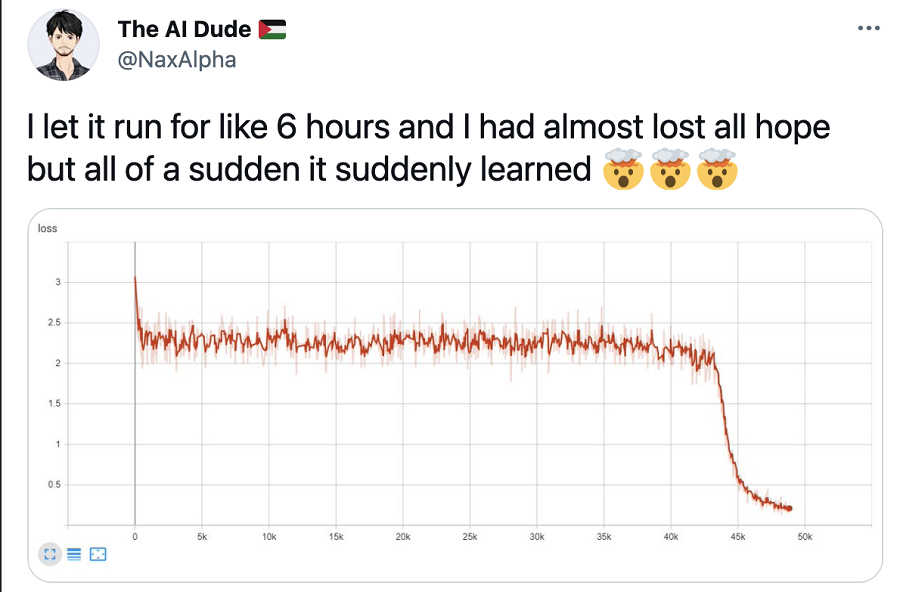
提示:在规划模型开发工作时,请留出足够的时间进行模型训练,以确保我们不会遇到损失函数突然下降的情况。
10、结束语
调试神经网络模型可能是一项具有挑战性的任务,可能需要对软件开发和机器学习技术的不同领域有深刻的理解和经验。因此,在设计神经网络解决方案之前,制定一个明确的策略以简化模型调试非常重要。制定一个如何处理潜在问题的计划不仅会增加模型的稳健性,还可能带来新的见解和更强大的模型。
原文链接:9 Steps of Debugging Deep Learning Model Training
BimAnt翻译整理,转载请标明出处





