
NSDT工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器 - REVIT导出3D模型插件 - 3D模型语义搜索引擎 - AI模型在线查看 - Three.js虚拟轴心开发包 - 3D模型在线减面 - STL模型在线切割 - 3D道路快速建模
科技界现在已经进入了人工智能时代。过去几年,我们在基础模型层看到了大量的创新:除了 OpenAI,我们还看到了 Mistral、Anthropic、Meta’s Llama、Google Gemini 等的出现。今年,焦点似乎已经从基础模型转移到应用层。a16z 现在定期发布 50-100 个最佳 GenAI 应用程序列表,每天都有新的AI应用程序融资公告。我们看到的是新一波消费者赢家,还是仅仅是为未来更多成功公司铺平道路的早期实验?
1、AI = 软件*(有一些注意事项)
在我们深入研究之前,总结一下我们所处的位置可能会有所帮助—AI是软件的新发展。软件本身是一种商品,不具有防御性。成功的软件公司依靠一些机制来产生防御性—规模经济、转换成本、以及最重要的网络效应。我将在本文中讨论前两个,但重点讨论第三个。如果你之前关注过我的文章,这应该不会让你感到惊讶。🙂
AI公司和普通老软件公司之间最大的经济差异归结为边际成本,即为新客户生产额外产品的成本。软件(例如 OG Microsoft Windows 或 Lotus 1-2-3)的边际成本为零—一旦开发出产品,你就可以为新客户生产无限份。互联网通过让客户更容易访问这些产品,使这一过程更加有效。它确实产生了一些额外的成本来服务每个客户(媒体存储和计算),但这些成本通常占收入的百分比并不大(例如谷歌)。
另一方面,AI公司的边际成本不为零,因为训练和计算的成本很高。训练一个模型需要数千万的前期投资。此外,通过 ChatGPT 等产品查询大型语言模型 (LLM) 的成本比在 Google 上进行标准关键字搜索的成本高出 10 倍(不包括培训成本)。这种动态在基础模型层引入了规模经济。简而言之,训练和运行这些模型的高昂成本为新竞争对手设置了进入门槛。
当然,规模经济对新公司的有效性充其量是值得怀疑的—原因有两个。首先,许多这些模型可能在经济上不可行,即它们的成本高于它们所赚的钱。谷歌、Meta、Salesforce、Snowflake 等大型公司在这里具有优势,因为他们可以用现有的现金流补贴这些模型。其次,更轻量、计算强度更低的模型可能足以满足大多数用例的需求。
在应用层,规模经济也不是一种可行的防御机制—因为与模型层相比,计算成本要低一个数量级。你支付 OpenAI API 或为你的应用计算的能力并不是相对于未来竞争对手的可持续优势。一些应用程序(如 Character.ai)试图通过垂直整合(即构建自己的定制模型)来避免此问题。同样,出于我之前提到的同样原因,规模经济的有效性值得怀疑。
这使得网络效应和转换成本成为大多数应用程序唯一现实的防御模式。让我们来看看它们如何应用于三大类 AI 应用程序,借用过去三十年互联网的术语。
1、AI 单人应用:AI 1.0
这些应用可实现用户与 AI 产品(即软件)之间的直接交互。这包括写作助手(如 Quillbot)、头像生成器(如 Lensa 或 Remini)。它们代表了基础模型出现后最早的 AI 应用浪潮。我将这一类别称为 AI 1.0,因为用户直接与 AI(由公司创建)交互,类似于 Web 1.0,用户访问信息(由公司创建)。
这里不可能存在网络效应。当增加一个用户会增加产品对所有用户的价值时,就会存在网络效应—这需要多人交互,即两个或多个用户之间的交互。这里的交互是单人交互,即用户与软件交互。因此,根据定义,网络效应不可能存在。
那么切换成本呢?如果你可以将应用程序深深嵌入到用户工作流程中,那么它将很难被取代——Salesforce 就是最明显的例子。到目前为止,我还没有看到任何明显的单人 AI 应用程序案例。相反,我们在这一类 AI 应用程序(尤其是消费者)中看到的是各种快速商品化的应用程序。其中一些可能会因为 AI 的新颖性(和明显的实用性)而流行起来(例如 Lensa),但这很少是可持续的。
这只剩下垂直整合——构建你自己的定制模型。正如我之前提到的,这种模式的可持续性也是一个悬而未决的问题。
2、支持 AI 的轻量级多人游戏应用:AI 1.5
还有另一类 AI 应用,其产品比“纯软件/AI”略多。相反,用户创建 AI 生成的内容或供应单元,然后将其展示给其他用户。至关重要的是,创建 AI 生成内容的过程是无摩擦的,只需点击几下或一个简单的提示即可。Character.ai 就是一个很好的例子,创建一个新机器人只需几分钟。Suno 和 Udio 等 AI 歌曲生成器也是很好的例子,用户可以创建其他人可以发现的 AI 生成的歌曲。
网络效应确实存在……理论上。用户采用会导致更多 AI 生成的内容,其他用户可以与之互动。挑战在于,创建供应(AI 聊天机器人或歌曲)的摩擦非常低,达到内容临界量的障碍也是如此。
当然,每个人都知道内容是 AI 生成的,因此内容产生的情感价值也很低—创建该内容单元的人的身份完全无关紧要。在产品变得“足够好”之前,你只需要这么多用户+人工智能生成的内容。这是一个相对较低的竞争壁垒,这些网络效应(或它们的“强度”)赋予的防御能力微乎其微。这就是为什么我认为这个类别是人工智能 1.5—介于人工智能 1.0(早期、明显的用例)和人类互动的真正推动者之间。
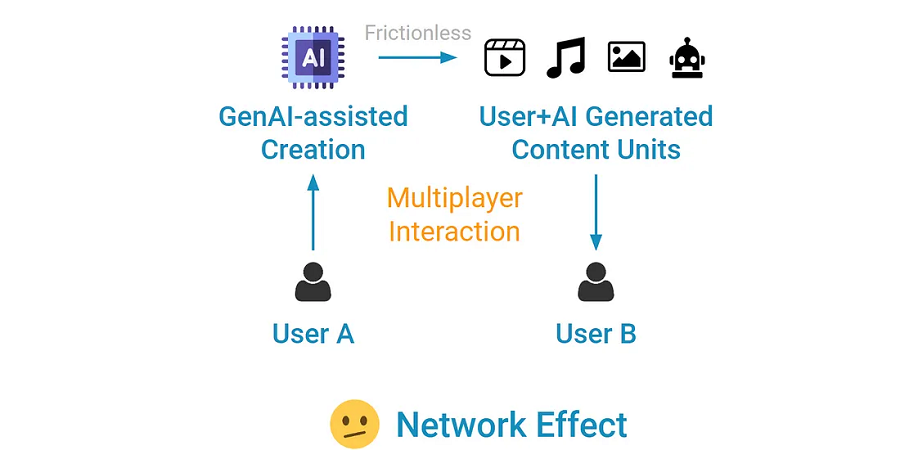
这里可能存在转换成本,也许以不同的形式存在。你可以说 Character.ai 用户与他们创建的机器人形成了情感纽带(可以想象成 AI 男朋友/女朋友),这可能会带来心理上的转换成本。这当然是一种可能性,但我还没有看到任何证据来支持这一说法—强大的长期留存率将是一个很好的起点。到目前为止,我们所看到的只是显示高会话频率和花费时间的数据。这总是好的,但它并没有告诉我们任何关于转换成本或可防御性的信息。
3、真正的 AI 支持的多人网络:AI 2.0
那么,如何使用 AI 应用程序创建真正的、有意义的网络效应呢?根据我们到目前为止所讨论的内容,该应用程序需要具有 AI 支持的多人互动,这涉及的不仅仅是另一个用户创建的 AI 生成的输出。这些应用程序使用 AI 来实现以前不可能实现的(更高摩擦力的)多人互动。我在 Speedinvest 博客上对 AI 市场的定义就是其中的一部分。
AI 2.0 的一个(非常早期的)例子是 Haz——我最近的投资组合公司—它将电子邮件收据输入 AI 模型,以根据用户过去的购买情况创建社交信息流。该模型帮助 Haz 过滤掉与社交信息流无关的购买(例如锤子),并提取或查找相关产品信息以填充信息流。然后,这个内容单元成为用户之间互动的基础——从“喜欢”到竞标朋友拥有的东西。

如果这听起来有点耳熟,那确实如此。这反映了从 Web 1.0 到 Web 2.0 的过渡,即从允许用户访问信息的应用程序到允许用户创建和消费内容的应用程序。Web 2.0 支持多人互动,就像我们今天在 Facebook 等社交网络和 Airbnb 等市场上看到的那样。虽然网络效应在技术世界中已经存在了数百年(从最初的电话开始),但 Web 2.0 导致建立在其上的公司数量大幅增加—从而创造了价值。
AI 2.0 能否在具有网络效应的 AI 应用程序中带来类似的扩展?当然是可能的。我们还处于非常早期的阶段,所以我还不能指出任何大规模的成功。然而,我们开始看到一些早期的产品概念围绕这个想法形成,包括 Haz 和其他一些。我只能说这是我非常关注的一个领域。
原文链接:AI 2.0: Introducing Network Effects to the AI Era
BimAnt翻译整理,转载请标明出处





