
NSDT工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器 - REVIT导出3D模型插件 - 3D模型语义搜索引擎 - AI模型在线查看 - Three.js虚拟轴心开发包 - 3D模型在线减面 - STL模型在线切割 - 3D道路快速建模
如果你曾经训练过 BERT 或 RoBERTa 等大型 NLP 模型,就就会知道这个过程非常漫长。 由于此类模型规模庞大,训练可能会持续数天。 当需要在小型设备上运行它们时,可能会发现你正在为当今不断提高的性能付出巨大的内存和时间成本。
幸运的是,有一些方法可以减轻这些痛苦,同时对模型的性能影响很小,这些方法称为蒸馏(distillation)。 在本文中,我们将探讨 DistilBERT [1] 方法背后的机制,该方法可用于提取任何类似 BERT 的模型。
首先,我们将讨论蒸馏的一般情况以及为什么我们选择 DistilBERT 的方法,然后如何初始化该过程,蒸馏过程中使用的特殊损失,最后是一些足够相关的额外细节,需要单独提及。
1、DistilBERT 简介
蒸馏的概念非常直观:它是训练小型学生模型以尽可能接近地模仿大型教师模型的过程。 如果我们只在用于微调的集群上运行机器学习模型,那么蒸馏将毫无用处,但遗憾的是,事实并非如此。 因此,每当我们想要将模型移植到较小的硬件(例如有限的笔记本电脑或手机)上时,蒸馏就会出现,因为蒸馏模型运行速度更快,占用的空间更少。
你可能已经注意到,基于 BERT 的模型自在 [2] 中首次引入以来,在 NLP 中非常流行。 随着性能的提高,参数也随之增加。 准确地说,BERT 的数量超过 1.1 亿,而且我们甚至不是在谈论 BERT-large。 因此,蒸馏的必要性显而易见,因为 BERT 用途广泛且性能良好。 此外,后来的模型基本上都是以相同的方式构建的,类似于 RoBERTa [3],因此通过学习正确提炼 BERT,你可以一石二鸟。
第一篇关于 BERT 蒸馏的论文是我们的灵感来源,即 [1]。 但其他人紧随其后,比如 [4] 或 [5],所以很自然地想知道为什么我们将自己限制在 DistilBERT 上。 答案有三个:首先,它非常简单,因此这是对蒸馏的一个很好的介绍; 第二,它会带来好的结果; 第三,它还允许对基于 BERT 的模型进行蒸馏。
DistilBERT 的蒸馏有两个步骤,我们将在下面详细介绍。
2、复制教师模型的架构
BERT 主要基于一系列相互堆叠的注意力层。 因此,这意味着 BERT 学习的“隐藏知识”就包含在这些层中。 我们不会关心它们是如何工作的,但对于那些想要更多细节的人,除了原始论文 [1] 之外,我可以推荐这篇 TDS 文章,它做得非常出色 [6]。 目前,我们可以将注意力层视为黑匣子,这对我们来说并不重要。
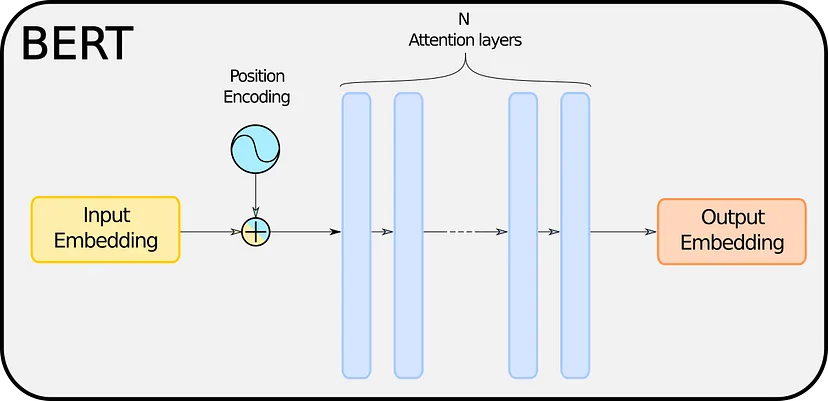
从一个 BERT 到另一个 BERT,层数 N 各不相同,但模型的大小当然与 N 成正比。因此,训练模型所需的时间和前向传递的持续时间也取决于 N,以及 用于存储模型的内存。 因此,提炼 BERT 的逻辑结论是减少 N。
DistilBERT 的方法是将层数减半,并从教师的层初始化学生的层。 简单而高效:
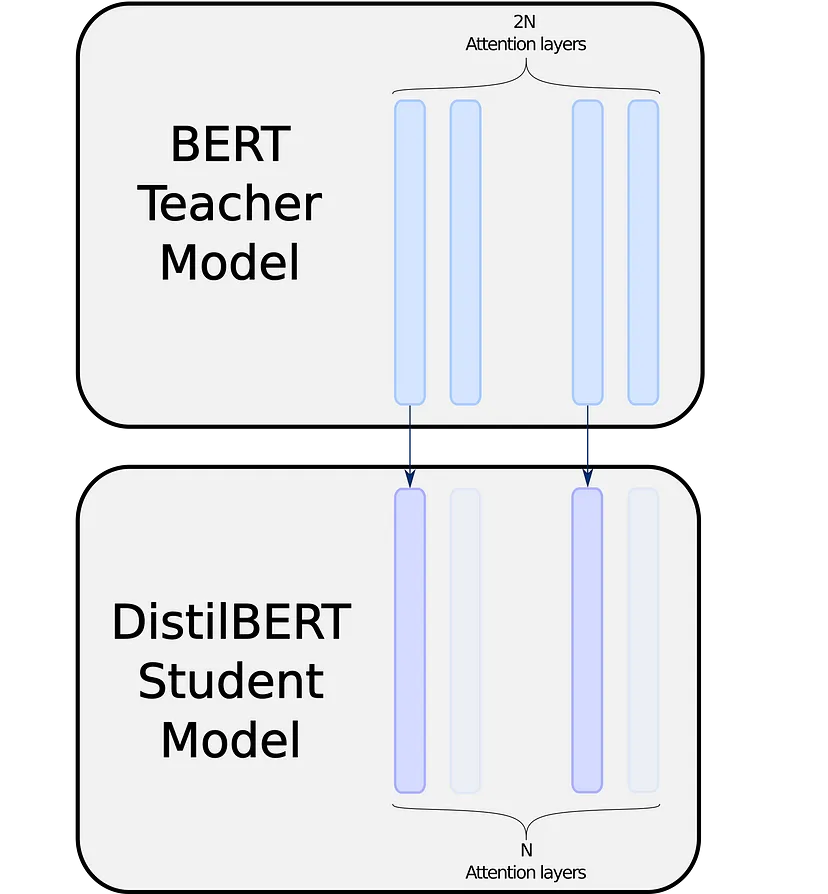
DistilBERT 在一个复制层和一个忽略层之间交替,根据[4],这似乎是最好的启发式,它尝试优先复制顶层或底层。
多亏了huggingface的transformers模块和对其内部工作原理的一点了解,这可以很容易地实现。 我们将在另一篇文章中展示如何实现,因为在这篇文章中我们将只限于理论。
当然,如果你使用基于 BERT 的模型来完成特定任务,比如说序列分类,那么你还需要为学生复制老师的头部,但一般来说,BERT 头部与其注意力层相比小多了。
我们现在有了一个可以教授的学生模型。 然而,蒸馏过程并不是一个经典的拟合例程:我们并不是像平常那样教学生学习一种模式,我们的目标也是模仿老师。 因此,我们必须调整我们的训练程序,尤其是我们的损失函数。
3、蒸馏损失
我们的训练程序将基于损失,正如前面所说,它旨在实现几个目标:最小化教师训练的经典损失函数并模仿教师本身。 更糟糕的是,模仿教师需要混合使用两种损失函数。 因此,我们将从更简单的目标开始:最小化经典损失。
3.1 经典损失
关于这一部分没有太多可说的:类似 BERT 的模型都以相同的方式工作,核心将嵌入输出到特定问题的头部。 教师微调的任务有其自己的损失函数。 为了计算该损失,由于该模型是由具有与教师相同的特定问题头的注意力层组成,因此我们只需插入学生的嵌入和标签即可。
3.2 师生交叉熵损失
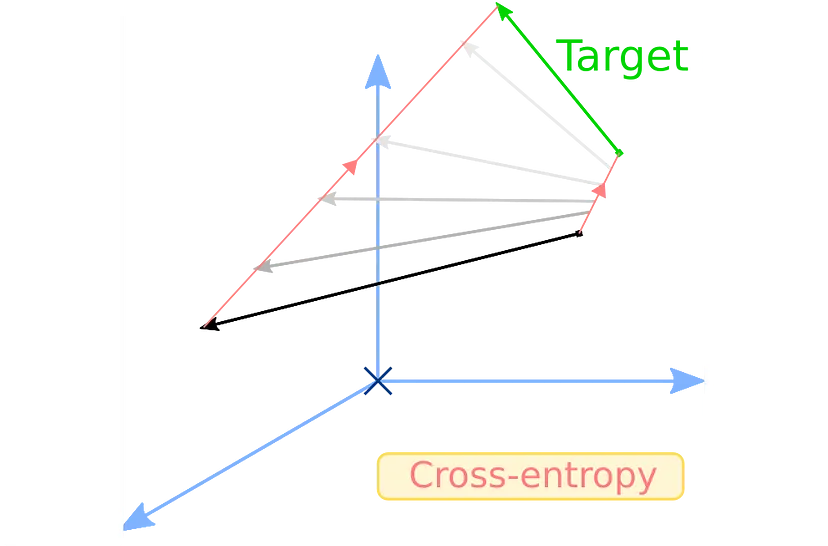
这是第一个旨在缩小学生和教师概率分布之间差距的损失。 当类似 BERT 的模型对输入进行前向传递时,无论是用于掩码语言建模、标记分类、序列分类等……它都会输出 logits,然后通过 softmax 层将其转换为概率分布。
对于输入 x,教师输出:

学生输出:
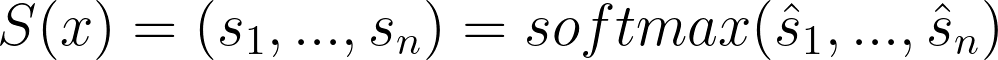
请记住 softmax 及其附带的符号,我们稍后会再讨论它。 无论如何,如果我们希望 T 和 S 接近,我们可以以 T 作为目标对 S 应用交叉熵损失。 这就是我们所说的师生交叉熵损失:
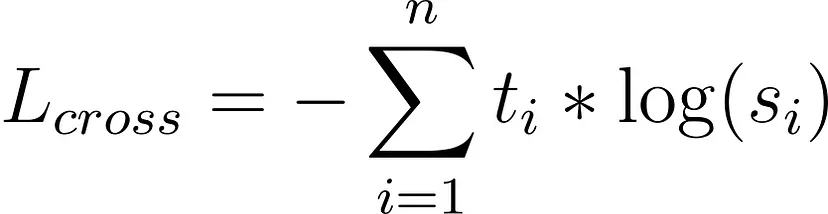
3.3 师生余弦损失

帮助学生成为教师的第二个损失是余弦损失。 余弦损失很有趣,因为它不是试图使向量 x 等于目标 y,而是仅仅尝试将 x 与 y 对齐,而不介意它们各自的范数或空间原点。 我们使用这种损失来使教师和学生模型中的隐藏向量对齐。 使用与之前相同的符号:
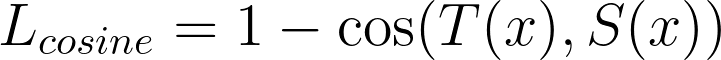
实际上,余弦损失有两种版本,一种用于对齐向量,另一种用于将一个向量拉向另一个向量的相反方向。 在本文中,我们只对第一个感兴趣。
3.4 完全蒸馏损失
完全蒸馏损失是上述三种损失的组合:
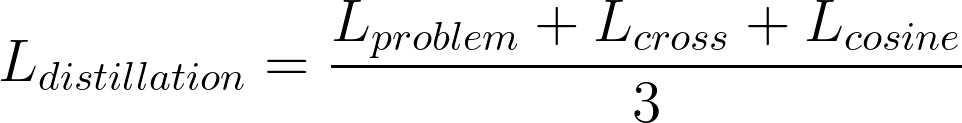
4、额外细节
在解释了损失之后,蒸馏程序的其余部分就非常简单了。 该模型的训练方式与其他模型非常相似,唯一的问题是你必须并行运行两个类似 BERT 的模型。 值得庆幸的是,考虑到 GPU 的健康状况和内存,教师模型不需要梯度,因为反向传播仅在学生身上完成。 当然,仍然需要像蒸馏过程一样实现损失,但我们将在以后的一篇文章中介绍它。
4.1 温度
正如所承诺的,让我们回到 III 中使用的符号。 师生交叉熵损失:
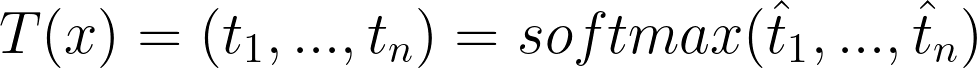
DistilBERT 使用 [7] 中的温度概念,这有助于软化 softmax。 温度是一个变量 θ ≥ 1,随着它的升高,softmax 的“置信度”会降低。 普通的softmax描述如下:

现在,让我们无用地将其重写为:
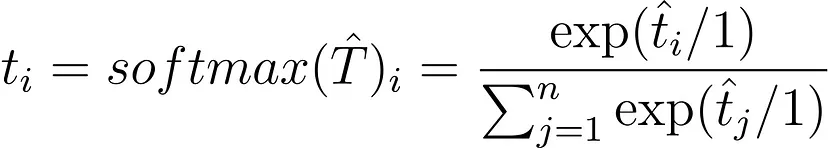
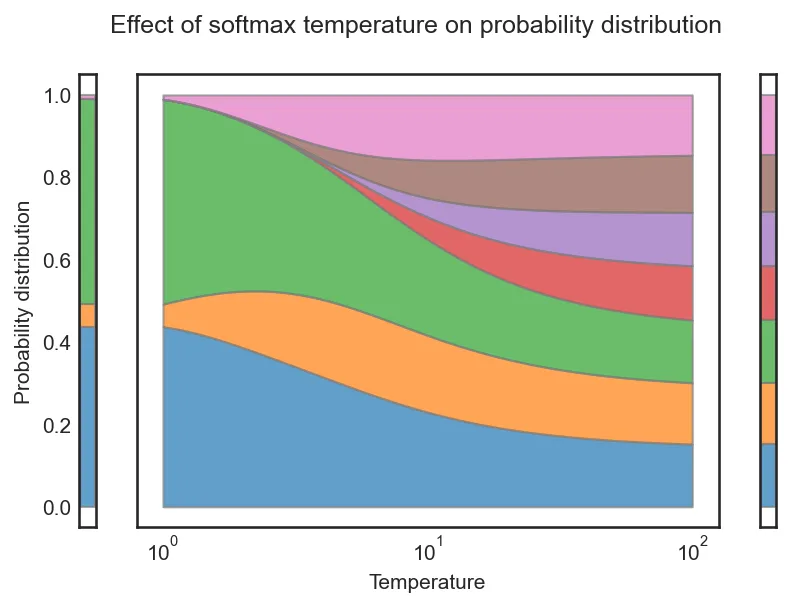
每个人都会同意这是正确的。 1实际上对应于温度θ。 普通的softmax是温度设置为1的softmax,一般温度的softmax的公式为:
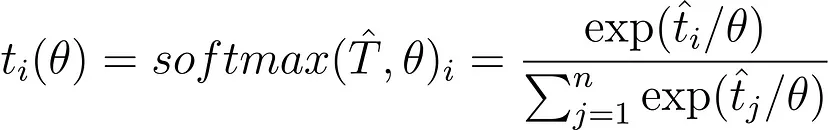
随着 θ 增大,θ 上的商变为零,因此整个商变为 1/n,softmax 概率分布变为均匀分布。 这可以在上图中观察到。
在 DistilBERT 中,学生和教师的 softmax 在训练期间都以相同的温度 θ 为条件,并且在推理期间将温度设置为 1。
5、结束语
现在你已经了解了类似 BERT 模型的蒸馏如何适用于 DistilBERT,唯一要做的就是选择一个模型并对其进行蒸馏!
显然,你仍然需要实施蒸馏过程,但我们很快就会介绍如何做到这一点。
原文链接:Distillation of BERT-Like Models: The Theory
BimAnt翻译整理,转载请标明出处





