
NSDT工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器 - REVIT导出3D模型插件 - 3D模型语义搜索引擎 - AI模型在线查看 - Three.js虚拟轴心开发包 - 3D模型在线减面 - STL模型在线切割 - 3D道路快速建模
作为 AI 智能体(AI Agent)和智能体系统的创造者,我深入研究了智能体在一切事物中的应用。我让Agent做所有事情,从创建 PowerPoint 到从图像制作视频动画、从视频制作 gif、Word 和 Excel 文档等等。我甚至让Agent研究主题、重新组织和总结研究、创建帖子并将其发布在 Twitter 和 Reddit 上。
有了合适的工具,智能体可以自动执行许多复杂的任务。虽然我承认他们并不总是能做到,但他们是能干的帮手。我想通过创建一个可以根据我的写作自动创建博客的智能体来证明这一点,所以我制作了一个博客助手Agent,它可以执行以下操作:
- 从源 Word 文档中提取所有图像、文本和代码。在大多数情况下,这是我的一本书中的一章。
- 根据固定模板撰写博客文章。
- 为帖子生成 Word 文档,包括图像和代码。
然后,我获取 Word 文档的内容,对其进行查看,并将其发布在 Medium 或任何地方。为了演示此代理的输出,我在下面提交了一篇从我的书《AI Agents In Action》第 8 章生成的博客文章。这篇文章采用欧内斯特·海明威的风格撰写,经过深思熟虑,这可能不是技术文章的好风格。
1、博客中的博客(从源生成的 AI)
人工智能正在突飞猛进地成长,就像一棵向着太阳努力生长的幼树。它最令人兴奋的分支之一是代理系统的开发——注入记忆和知识的代理可以更自然、更有效地与我们互动。让我们深入研究检索如何在使这些系统运转中发挥关键作用。
2、简介
在我们不断发展的 AI 世界中,检索信息的能力是基础。无论是从庞大的数据库中提取信息,还是提取过去交互的片段,检索都会塑造背景并增强 AI 系统的能力。此旅程将涵盖语义搜索、文档索引和检索增强生成 (RAG) 工作流的复杂性。
检索不仅仅是获取数据;它还涉及理解和情境化信息。记忆和检索机制之间的协同作用使 AI 能够模拟类似人类的理解和响应模式。通过深入研究检索的工作原理,我们可以更好地理解我们正在构建的人工智能。
在此博客中,我们将探讨 AI 应用中检索的关键方面。从文档索引到矢量数据库,流程中的每一步都对使这些系统更智能、更高效起着至关重要的作用。通过示例和代码片段,我们将介绍这些概念的实际应用,让你全面了解其重要性。

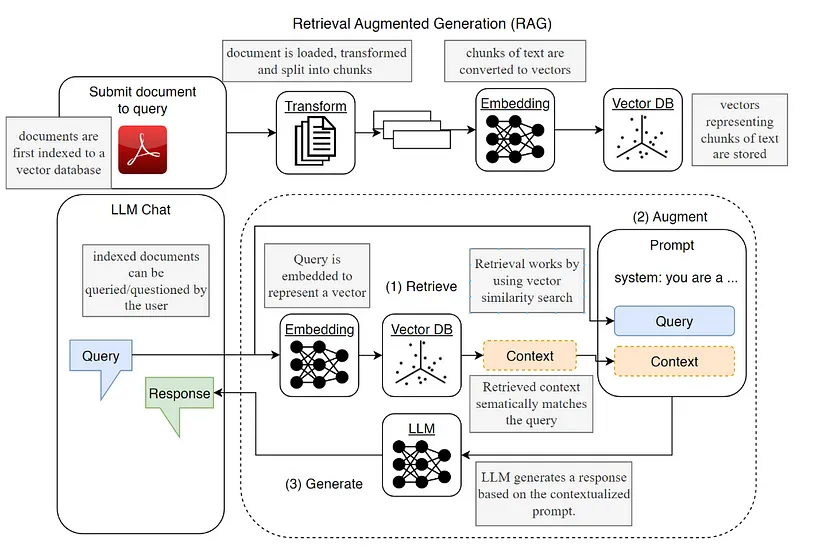
3、检索增强生成 (RAG) 基础知识
当你询问有关复杂 AI 系统的问题时,RAG 机制就会开始发挥作用。它会获取你的查询并深入研究预加载的文档,将它们转换为上下文块,将它们嵌入到向量中,并将它们存储在向量数据库中。当你再次查询时,它会将查询与这些存储的向量进行比较,并提取最相关的块以形成答案。
RAG 或检索增强生成将检索系统与生成模型的优势结合起来。这里的关键是上下文。它可以通过向语言模型提供更相关和更详细的上下文来生成更准确和更有意义的响应。此过程涉及多个步骤,从文档加载到查询嵌入式向量数据库。
RAG 的有效性在于它能够处理大量非结构化数据并提供连贯且上下文准确的答案。这使得它特别适用于文档聊天系统和问答系统等应用程序,在这些应用程序中,精确和相关的响应至关重要。
import plotly.graph_objects as go
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity
documents = [
"The sky is blue and beautiful.",
"Love this blue and beautiful sky!",
"The quick brown fox jumps over the lazy dog.",
"A king's breakfast has sausages, ham, bacon, eggs, toast, and beans",
"I love green eggs, ham, sausages and bacon!",
"The brown fox is quick and the blue dog is lazy!",
"The sky is very blue and the sky is very beautiful today",
"The dog is lazy but the brown fox is quick!"
]
vectorizer = TfidfVectorizer()
X = vectorizer.fit_transform(documents)4、深入研究语义搜索和文档索引
文档索引就像创建崎岖地形的详细地图。它将信息转换为结构化格式,使其更易于检索。另一方面,语义搜索超越了单词来掌握含义,使你的搜索更加直观和准确。
语义搜索依赖于理解文档中单词的上下文和语义,而不仅仅是匹配关键字。这使得它非常有效,特别是在复杂查询中,其中含义先于精确的单词匹配。向量相似性搜索等技术可以比较文档的语义内容,从而获得更准确和相关的结果。
该过程从将文档转换为语义向量开始,语义向量是一种捕捉文本含义的数字表示。各种算法(例如 TF-IDF)都用于创建这些向量。了解这些向量的工作原理以及如何搜索它们对于构建高效的检索系统至关重要。
cosine_similarities = cosine_similarity(X)
while True:
selected_document_index = input(f"Enter a document number (0-{len(documents)-1}) or 'exit' to quit: ").strip()
if selected_document_index.lower() == 'exit':
break
if not selected_document_index.isdigit() or not 0 <= int(selected_document_index) < len(documents):
print("Invalid input. Please enter a valid document number.")
continue
selected_document_index = int(selected_document_index)
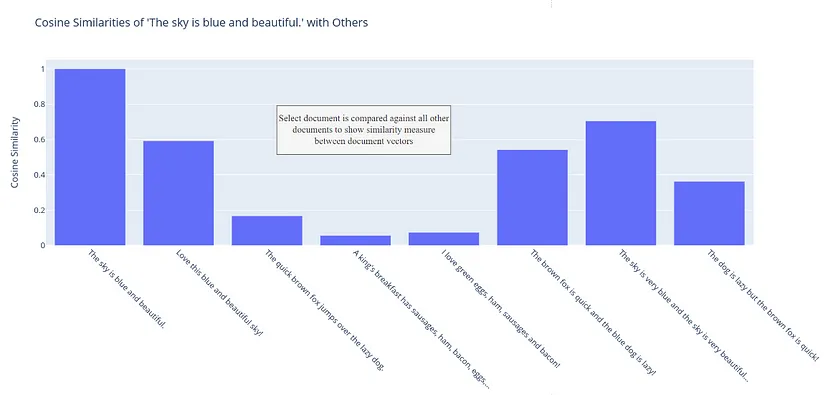
selected_document_similarities = cosine_similarities[selected_document_index]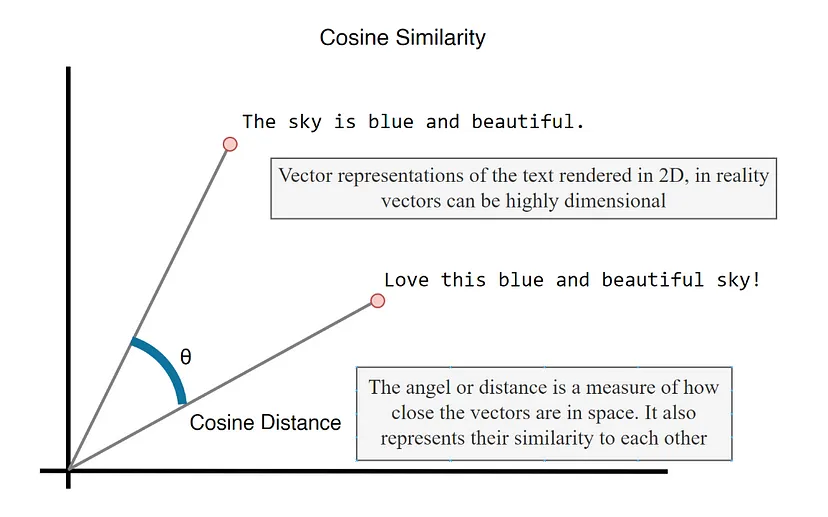
5、向量数据库和相似性搜索
向量化后,这些文档向量将存储在向量数据库中。此存储允许快速进行相似性搜索,使 AI 能够快速获取相关上下文。执行高效相似性搜索的能力可确保 AI 保持响应能力和相关性。
向量数据库在管理和查询大量向量化数据方面至关重要。它们使用各种相似性度量(例如余弦相似性)实现对相似向量的高效检索。这种效率对于实时应用至关重要,因为及时准确的数据检索至关重要。
此过程涉及多个层次,从加载数据开始,将其转换为向量,然后将这些向量存储在针对相似性搜索优化的数据库中。该过程中的每个步骤对于保持检索系统的保真度和速度都至关重要。
6、使用 LangChain 构建 RAG
LangChain 提供强大的工具来实现 RAG 工作流。它抽象了检索过程,使其变得可访问且高效。使用 LangChain,我们可以构建强大、可扩展的检索系统,以增强 AI 的知识和记忆能力。
LangChain 的关键方面之一是它能够无缝处理各种数据源和向量存储。它提供了全面的数据加载、向量化和查询工具,使开发过程变得简单高效。这种灵活性对于开发可扩展且多功能的 AI 系统至关重要。
使用 LangChain 创建 RAG 工作流涉及几个步骤。首先,加载文档并将其拆分为可管理的块。然后将这些块转换为向量,通常使用 OpenAI 嵌入等模型。最后,将这些向量存储在数据库中,以便在需要时进行相似性搜索查询。
from langchain.document_loaders import UnstructuredHTMLLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
loader = UnstructuredHTMLLoader("sample_documents/mother_goose.html")
data = loader.load()
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=100,
chunk_overlap=25,
length_function=len,
add_start_index=True,
)
documents = text_splitter.split_documents(data)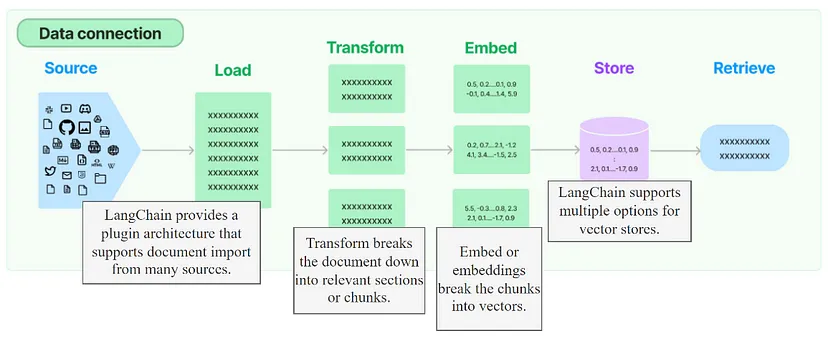
7、在Agent系统中实现记忆
智能体记忆包含各种形式——感官记忆、短期记忆和长期记忆——以丰富互动。每种类型的记忆都增强了人工智能根据过去的互动将响应情境化的能力,使对话更加自然和有意义。
人工智能中的感觉记忆处理文本、图像和音频等即时输入,提供快速但临时的情境信息。短期或工作记忆保存有限量的近期输入,使系统能够在交互过程中保持情境。长期记忆存储更持久、相关的语义和情景记忆,可以在较长时间内回忆起来。
人工智能系统中的记忆检索遵循与 RAG 类似的模式,但更侧重于累积信息的动态和演变性质。通过有效地对这些不同形式的记忆进行分类和管理,人工智能系统可以模拟更细致入微的理解,类似于人类的认知过程。

8、结束语
在智能体系统中检索的旅程揭示了记忆和知识交织在一起的丰富景观。从语义搜索到高级记忆实现,每一步都增强了人工智能交互的能力和深度。随着我们继续探索这些领域,更智能、更直观的系统的潜力正在蓬勃发展,预示着人工智能不仅能响应,还能理解的未来。
使用 GPT Assistants Playground 开发博客代理大约需要一天时间,其中大部分时间都用于生成代码以正确从 Word 文档中提取内容。智能体需要更多工作,但总的来说,我对结果总体上感到满意。
用于创建内部博客的所有工具都可以从我的项目 GPT Assistants Playground 中获得。我一直在不断向 Playground 添加新工具/操作。
BimAnt翻译整理,转载请标明出处





