
NSDT工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器 - REVIT导出3D模型插件 - 3D模型语义搜索引擎 - AI模型在线查看 - Three.js虚拟轴心开发包 - 3D模型在线减面 - STL模型在线切割 - 3D道路快速建模
我要飞往印度进行短暂旅行,因此花了一个小时的时间处理在线签证申请流程。完成后,由于我现在知道涉及的内容,我向 ChatGPT 4o 询问了相关问题。这些观点中的大多数都是部分或完全错误的。

这是一个“不公平”的测试。这是使用 LLM 的“糟糕”方式的一个很好的例子。这些不是数据库。它们不会对问题产生精确的事实答案,它们是概率系统,而不是确定性系统。今天的 LLM 无法给我一个完全准确的答案。答案可能是正确的,但你不能保证这一点。
人们有一种趋势,认为这意味着这些LLM是无用的。这是一种误解。相反,思考生成式 AI 模型的一个有用方法是,它们非常擅长告诉你对这样的问题的良好答案可能是什么样子。在一些用例中,“看起来是个不错的答案”正是你想要的,而在一些用例中,“大致正确”就是“完全错误”。
事实上,进一步推论,可以认为完全相同的提示和完全相同的输出可能是好结果,也可能是坏结果,这取决于你想要它的原因。
不管怎样,在这种情况下,我确实需要一个精确的答案,而 ChatGPT 原则上不能依赖它给我一个答案,相反,它给了我一个错误的答案。我要求它做一些它做不到的事情,所以这是一个不公平的测试,但它是一个相关的测试。答案仍然是错误的。
有两种方法可以尝试解决这个问题。一种是将其视为科学问题 - 现在还为时过早,模型会变得更好。你可以经常说“RAG”和“多智能体”。模型肯定会变得更好,但会好多少呢?你可以花上几周时间在 YouTube 上观看机器学习科学家争论这个问题的视频,结果却发现他们其实并不知道。实际上,这是“大模型会产生通用人工智能吗?”争论的一个版本,因为在我看来,一个能够完全正确回答“任何”问题的模型听起来至少是一种通用人工智能的良好定义(不过,同样,没有人知道)。
但另一种方法是将其视为产品问题。我们如何围绕我们应该假设会“出错”的模型构建有用的大众市场产品?
AI人员对我这样的例子的常见反应是说“你用错了” :
- 我问了错误的问题类型
- 我以错误的方式提问
我应该做大量提示工程设计!但过去 50 年消费者计算的发展告诉我们,你不能通过让用户学习命令行来推动技术的应用 - 你必须走向用户:
我认为我们可以进一步将其分解为两种产品问题。
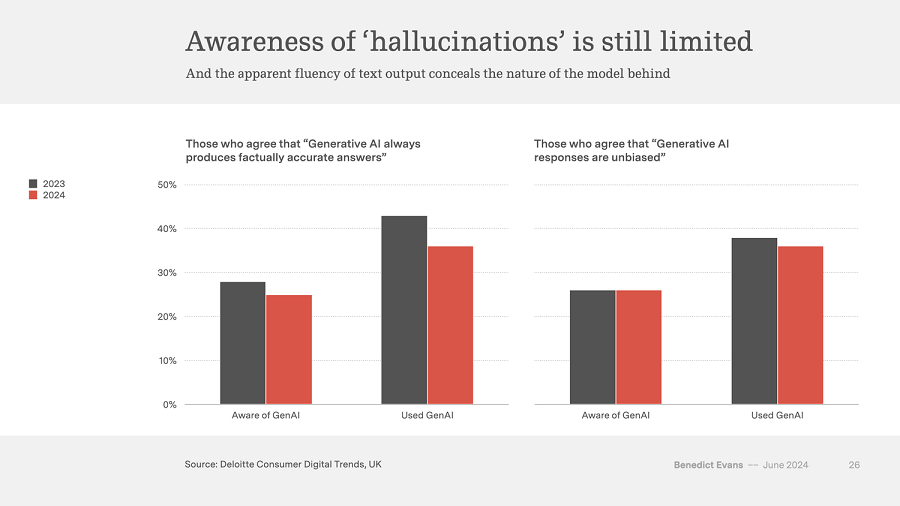
一方面,屏幕截图中的产品设计传达了确定性,而模型本身本质上是不确定的。谷歌给你(大部分)十个蓝色链接,传达“它可能是其中之一”的信息,但这里我们只得到了一个“正确”的答案。这误导了很多人,尤其是因为文本生成(与实际答案不同)几乎是完美的。事实上,德勤的这项有趣的调查表明,一旦人们使用了这些系统,他们更容易被这种明显的确定性误导:
但问题的另一半是,在我得到“答案”之前,产品并没有告诉我可以问什么。我给了它一个“坏”查询(它实际上不能很好地回答),但产品中没有任何内容告诉我。相反,它被呈现给我作为一个通用工具。如果产品必须尝试回答任何问题,那么模型就很难正确,但这也使得界面很难传达哪些是好问题。
我制作了下面的幻灯片,用于我将在印度进行的演讲,试图捕捉由此提出的替代方案:

最激进的方法是完全通用的聊天机器人作为产品,我刚刚讨论了其中的挑战。但至少还有另外两种方法。
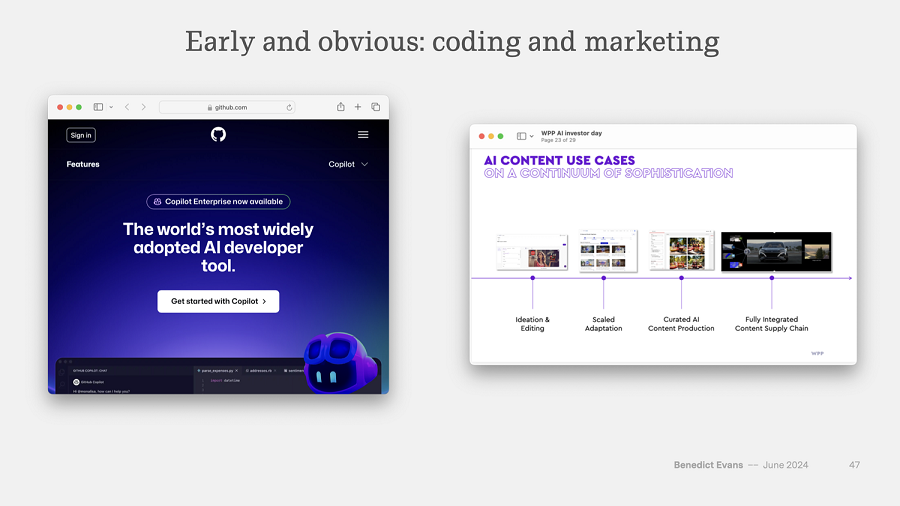
第一种方法是将产品限制在一个狭窄的领域,这样你就可以围绕输入和输出创建一个自定义 UI,传达它能做什么、不能做什么以及你可以问什么,也许还可以关注模型本身(因此有了 RAG)。这为我们带来了过去 12 个月中爆发式增长的编码助手和营销工具,以及知识管理工具的首次尝试。WPP 已经建立了一个内部仪表板,让其员工将模型引导到特定的品牌语调或目标人群。因此,“让这个工具为品牌 Y 的演示 Z 提出 50 个产品 X 的想法 - 不要问它你是否患有阑尾炎。”你将提示包装在按钮和 UI 中 - 在产品中:
但另一种方法是,用户永远看不到提示或输出,或者根本不知道这是生成式人工智能,输入和输出都被抽象为其他事物中的函数。该模型启用了某些功能,或者使构建该功能变得更快、更容易,即使你以前可以做到这一点。这就是上一波机器学习的大部分内容被吸收到软件中的方式:有新功能,或者功能效果更好,或者可以更快、更便宜地构建,但用户永远不知道它们是“人工智能”——它们不是紫色的,也没有小星星群。因此,有一个老笑话说,AI是任何还没有起作用的东西,因为一旦它起作用,它就只是软件。
从另一个角度来看:对于任何新技术,我们首先尝试让它适应我们已经存在的问题,而目前的市场领导者则试图让它成为一项功能(因此谷歌和微软在去年将LLM喷洒到他们的所有产品上)。然后,初创公司使用它来拆分现有产品(拆分搜索、Oracle 或电子邮件),但与此同时,其他初创公司试图找出我们可以构建的真正原生于新技术的产品。这分阶段进行。首先,Flickr 有一个 iPhone 应用程序,但后来 Instagram 使用智能手机摄像头,并使用本地计算添加过滤器,再后来,Snap 和 TikTok 使用触摸屏、视频和位置来打造真正原生于平台的产品。那么,我们用它构建了什么样的原生体验,不是聊天机器人本身,也不是“错误率”无关紧要,而是以某种方式抽象了这种新功能?
这当然提出了一个悖论,我之前已经谈到过:我们拥有一项通用技术,但部署方式是将其分解为单一用途的工具和体验。然而,将其视为悖论可能只是错位了正确的抽象层次。电动机是一种通用技术,但你不会从家得宝 (Home Depot) 购买一箱电动机 - 你会购买钻头、洗衣机和搅拌机。通用技术被实例化为用例。个人电脑和智能手机是取代单一用途工具的通用工具 - 它们取代了打字机、计算器、录音机和音乐播放器 - 但这些功能都是通过一个单一用途软件实现的:大多数人不会将 Excel 用作文字处理器。有些人对 LLM 如此兴奋的一个原因是他们可能不会遵循这种模式:他们可能会通过所有这些抽象级别上升到顶部。这将没有空间容纳“薄 GPT 包装器”。然而,我认为他们还不能真正做到这一点,因此,我刚才所写的一切实际上只是在思考,即使这种情况从未发生,你又能建立什么来改变世界。
原文链接:Building AI products
BimAnt翻译整理,转载请标明出处





