
NSDT工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器 - REVIT导出3D模型插件 - 3D模型语义搜索引擎 - AI模型在线查看 - Three.js虚拟轴心开发包 - 3D模型在线减面 - STL模型在线切割 - 3D道路快速建模
ChatGPT能为我总结一下这篇文章吗?
当然可以! 本文讨论了解析非结构化数据的问题及其对数据分析提出的挑战。 Dan 提出了一种使用自然语言处理 (NLP) 尤其是 ChatGPT API 的解决方案,将部分文本分类为不同的类别,并从每个类别中提取文本。
Dan 通过一个实际示例展示了 ChatGPT API 的有效性,展示了其从非结构化文本字段中提取特定信息的能力,最终为解析问题提供了可行的解决方案。
1、问题
非结构化数据是不符合特定结构或格式的信息。 它通常是来自用户的原始输入或在野外收集的数据的结果。 非结构化数据会使分析变得困难,因为大多数工具都设计用于处理行和列形式的结构化数据。
以我目前正在处理的当前项目为例,我们使用一个项目管理系统来跟踪客户及其项目。 对于客户,系统仅提供客户姓名字段和地址字段。 但是,地址字段如果经常用作存储地址以外的内容。 例如,该字段可能包含有关主要联系人的信息、他们的联系信息和一些其他详细信息。
这是一个问题,因为我们希望能够从该字段中提取地址,但我们也希望能够提取联系信息。 我们可以使用正则表达式来提取地址,但这将很难维护,因为数据格式因客户端而异。 正则表达式实际上只有在处理常规数据时才实用,毕竟它在名称中。
2、一个可能的解决方案
在考虑解决这个问题时,我知道必须有一个解决方案,这必须是一个常见问题。
那么让我们分解一下我们需要做的事情:
- 我们需要将文本的各个部分归类到不同的类别中
- 然后我们需要能够从每个类别中提取文本
这听起来像什么? 当然,这听起来像是一个自然语言处理问题。
我的第一次尝试是使用 Alteryx 智能套件的内置 NLP 功能来进行命名实体识别 (NER)。 这在大多数情况下都有效,但并不完美。 它还需要一些争论和逻辑来获得我想要的结果。
一时兴起,我想尝试一下 ChatGPT,因为我已经能够实现一些解决其他问题的魔法。 经过一些修补后,我能够使用类似于此的提示让它工作:
2、ChatGPT提示词

下面是我写的提示词:
You are a helpful data quality assistant that is tasked with extracting contact information from unstructured data provided by the sales team in our CRM. From the JSON Object below, please extract any of the following fields that you find.
Desired Fields:
- Account ID
- Full Name
- Position
- Company
- Address Parts (Lines, Street Address, City, State, Postcode and Country.)
- Phone Numbers (E164 Formatted, with phone number type)
- Email Address
- Website
- Social Media Profiles (Full URL for the Platform)
- Other Information
JSON with Unstructured Text Field:
{
"account_id": 270270270,
"text": "Daniel Lawson, Data Analytics Consultant (The Data School Down Under) \nLevel 12, 500 Collins Street,
Melbourne, VIC 3000, Australia. Main: (02)92600750.\nExt. 1234 M: 0499 555 555 Free Call: 1800 737 126 E: applications@thedataschool.com.au.\nW: thedataschool.com.au
LinkedIn: www.linkedin.com/in/danlsn Twitter: @_danlsn Insta: @_danlsn ABN: 36 625 088 726"
}
Valid JSON Object with Snake Case Field Names:让我们分解一下。 第一部分有助于为其所扮演的角色提供模型上下文,第二部分包含我们想要提取的不同列,基于我知道某些记录中存在的数据类型。 在字段定义中,我们还可以包含有关我们希望如何格式化输出的信息。
例如,我希望将地址分解成其组成部分,我想要一个包含电话号码类型的电话号码数组,我希望将社交媒体配置文件作为 url 包含在内。 对于电话号码,我希望它们采用 E164 格式,这是国际电话号码的标准,可以广泛用于其他系统。
最后,最后两部分包括一个包含我们要解析的记录的 JSON 对象,并以提示模型输出带有 snake case 字段名称的有效 JSON 对象作为结尾。 这很重要,因为这意味着稍后可以轻松地将输出转换为 Python 字典。
3、ChatGPT响应结构
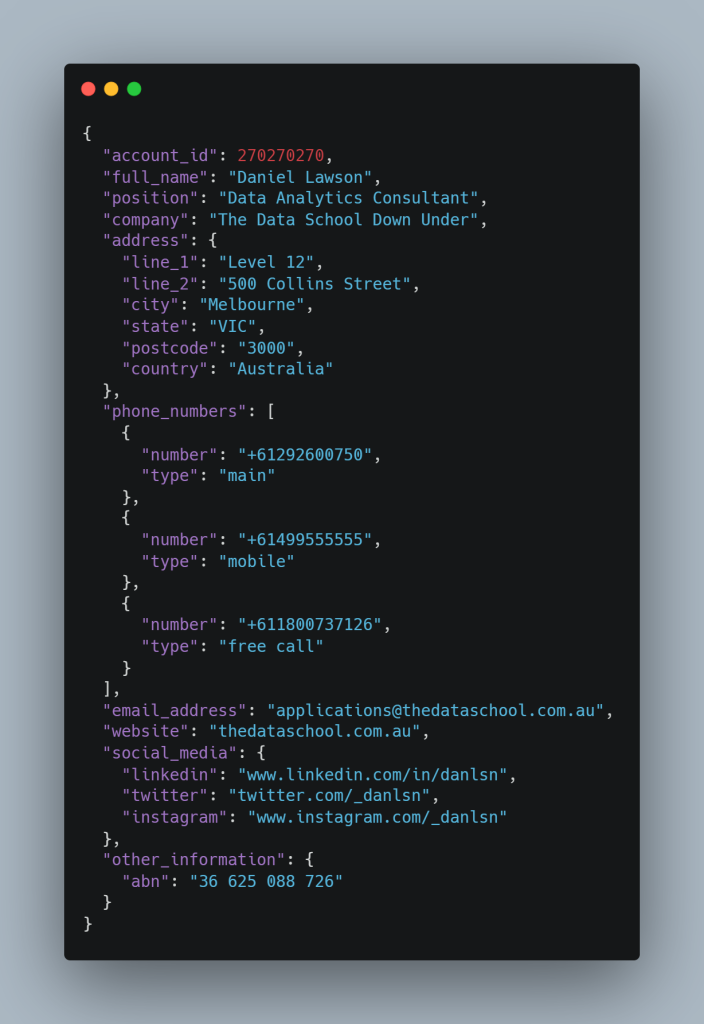
让我们更仔细地看一下输出。 首先要注意的是,该模型能够从 JSON 对象中提取帐户 ID。 这包含在提示中,可以让你稍后更轻松地将记录重新加入我们的系统。
接下来要注意的是,该模型能够从文本中提取全名、职位和公司。 它能够在提示中没有任何附加信息的情况下推断出此信息。 这是因为该模型经过训练可以在各种上下文中识别这些类型的实体。 该模型还能够准确地解析和准确地分离地址字段,这在以后更新 CRM 时非常有帮助。
令我惊讶的是电话号码解析。 它能够正确识别电话号码和电话号码的类型。 尽管没有在提示中明确提供国家代码,它也能够将电话号码正确格式化为 E164 格式。 我希望它能够实现这一点,因为澳大利亚地址以及电话号码的结构,但我仍然对此感到非常兴奋。
电子邮件提取可能是输出中最不有趣的部分,但它仍然有用。 网站提取也是如此,它不是输出中最令人兴奋的部分,但它仍然有用。 该模型避免了编写正则表达式解析器的需要,并且你必须编写的正则表达式越少越好(尽管我仍然喜欢正则表达式)。
社交媒体句柄提取也非常酷! 它能够从文本中正确识别社交媒体平台,并且凭借其对互联网的了解,它能够为每个平台正确格式化 url。
最后,因为我为模型可能能够提取的任何其他信息添加了一个包罗万象的字段,所以它能够正确识别 ABN 号码并正确格式化。 这非常有用,因为这意味着我们不会错过任何我们没有明确要求但模型能够提取的信息。
4、后续计划
我已经写了一篇博文了,但还有很多东西要分享。 因为我需要在 Python 中以编程方式更大规模地执行此操作,所以我需要一个 API 来与之交互。 当我开始探索这个 OpenAI 时,它没有 ChatGPT API,但他们有 GPT-3 API。 在微调提示后,我能够使用 GPT-3 API 获得类似的结果。
然而,在 3 月 1 日,OpenAI 使用增强的 GPT-3.5 语言模型发布了他们的 ChatGPT API。 我能够使用此 API 获得更好的结果。 更好的是,尽管该模型功能更强大,但每个令牌的成本是 GPT-3 API 成本的 1/10。
我将写一篇后续文章来分享我使用 ChatGPT API 的经验,其中将包含一些代码片段,因此你也可以在自己的项目中使用它。 我对这项技术的潜力感到非常兴奋,迫不及待地想看看它能实现什么。
原文链接:Using ChatGPT To Parse Unstructured Text
BimAnt翻译整理,转载请标明出处





