
NSDT工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器 - REVIT导出3D模型插件 - 3D模型语义搜索引擎 - AI模型在线查看 - Three.js虚拟轴心开发包 - 3D模型在线减面 - STL模型在线切割 - 3D道路快速建模
这是我们 LLM Makerspace 活动的记录摘要,我们使用经过微调的 LLM 构建了一个支票欺诈检测和解释 AI 系统。
那么,支票到底是什么?它们本质上是一种汇款,你将金额写在一张纸上并将其交给某人。它被视为法定货币和服务付款。作为一名来自爱尔兰的盎格鲁撒克逊人,我对支票很熟悉。美国等其他国家仍在使用它们,但世界许多地方已经向前迈进了一步。然而,仍然有很多人在处理支票,尤其是在金融行业和银行。他们每天都会收到这些实物纸质文件,需要验证它们是否是欺诈性的。这就是 LLM 派上用场的地方,我们将探讨如何将它们用于此目的。
1、问题:支票欺诈检测
银行和金融机构每天都会收到大量的实物支票。每张支票都需要验证以确保其不是欺诈性的。这是 LLM 系统可以提供帮助的地方。当支票被标记为欺诈时,人类员工需要写一份解释,说明为什么它被视为欺诈。这是许多金融机构承担的一项耗时的任务。他们雇人评估支票是否存在欺诈,并为欺诈支票写描述。
目标是使用 LLM 生成这些解释,让员工在其他领域提高工作效率。虽然在许多司法管辖区,AI 可能不被允许写这些描述,但它仍然可以提出一个人类可以接受的描述(如果他们对此感到满意),从而提高他们的工作效率。
2、解决方案:特征训练推理管道
为了构建支票欺诈检测系统,我们将遵循一种称为特征训练推理 (FTI) 管道架构的特定架构。其理念是将 AI 系统分解为更小、易于组合的模块。以下是概述:
- 特征管道:此模块接收数据、解析数据并创建特征。生成的特征表称为特征组。
- 训练管道:在这里,我们使用特征管道中的特征训练一个简单的支票欺诈检测模型。
- 推理管道:最后,我们使用训练后的模型执行欺诈检测推理。
3、流程
我们从支票图像和一些带标签的数据开始,用于监督机器学习。支票经过光学字符识别 (OCR) 系统,从图像中提取文本。
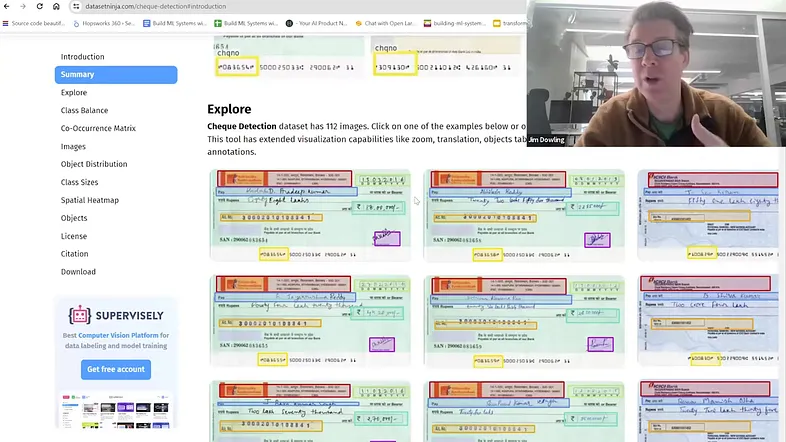
OCR 系统识别支票上的边界框并使用光学字符识别提取书面文本。这是一个传统的深度学习 CNN 式网络问题,许多现有框架都可以处理它。我们假设你的金融机构已经安装了此 OCR 系统。
3.1 特征管道
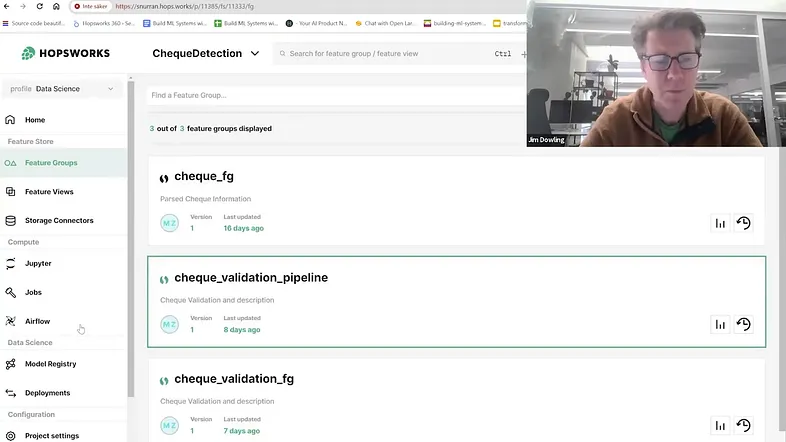
使用从支票中提取的文本,我们创建了一个特征管道。此管道读取数据、解析数据并创建特征,我们将这些特征存储在称为特征组的特征表中。
我们提取的一些特征包括:
- 支票号码
- 用户 ID
- 文本中的金额
- 数字中写的金额
- 文件路径
- 文本中的金额是否与数字中的金额匹配
- 银行名称
- 拼写正确性
- 用户名
我们还有一个标签,指示支票是否有效。以下是数据预览:
3.2 训练管道
准备好特征后,我们开始训练一个简单的模型来预测支票是否为欺诈。为此,我们使用 XGBoost 分类器。在 Hopsworks 中,我们创建一个特征视图,从特征组中选择相关特征。对于此模型,我们不需要大量的特征。
我们使用:
- 拼写是否正确?
- 支票的字母和数字金额是否匹配?
- 有效标签
我们训练模型并将其存储在 Hopsworks 模型注册表中。我们还计算一些模型指标和特征重要性分数。
3.3 推理管道
推理管道是一个每天运行的批处理过程。它获取每天到达的新支票并预测它们是否为欺诈。如果预测支票为欺诈,LLM 会生成一个描述来解释原因。
它的工作原理如下:
a)新的支票图像上传到指定目录。
b)批处理推理程序每天运行,处理该目录中的图像。
c)对于每张支票,程序:
- 使用 OCR 提取文本
- 使用训练模型预测支票是否为欺诈
- 如果预测支票为欺诈,则使用 LLM 生成解释
d)预测和解释存储在特征组中(也是 MySQL 表)。
e)决策支持系统可以连接到此表,读取输出,并在报告中使用生成的解释。
以下是输出示例:
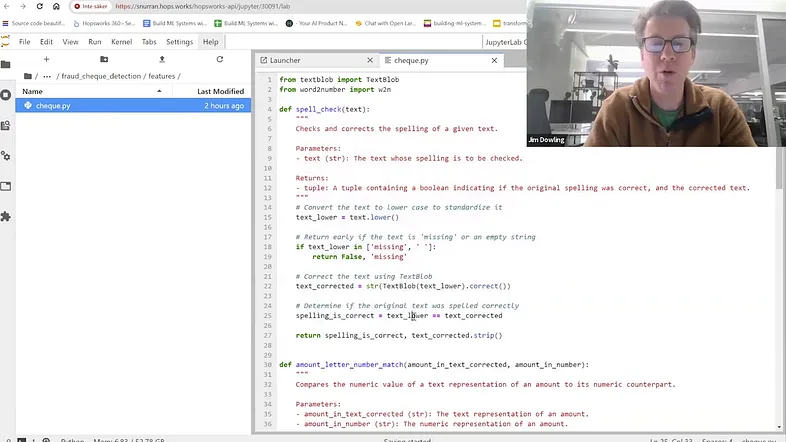
Check ID: 6Status: FraudulentDescription: The check is
considered fraudulent because the amount in words is missing,
which is a crucial detail that should be included in a valid check.4、将所有内容整合在一起
让我们浏览一下代码,看看所有内容是如何整合在一起的。我们将在本示例中使用 Hopsworks 中的 Python 笔记本,但您也可以在本地或 Colab 中运行代码并进行一些修改。
4.1 先决条件
克隆 Hopsworks 教程存储库:
git clone https://github.com/logicalclocks/hopsworks-tutorials.git进入欺诈检查检测目录:
cd hopsworks-tutorials/advanced_tutorials/fraud_check_detection安装所需的库:
pip install -r requirements.txt4.2 特征管道
连接到 Hopsworks 并读取包含检查数据的 CSV 文件:
import hopsworksproject = hopsworks.login()
import pandas as pd
df = pd.read_csv("data/check_data.csv")探索数据并创建特征:
df.head()
df["is_spelling_correct"] = ...
df["amount_matches"] = ...创建特征组并插入数据:
fg = fs.get_or_create_feature_group(
name="check_fg",
version=1,
primary_key=["check_id"],
description="Check details"
)
fg.insert(df)4.3 训练管道
创建特征视图:
fv= fs.create_feature_view(
name="check_fv",
version=1,
query=fg.select_all()
)创建训练数据集,随机训练/测试分成 80/20:
X_train, X_test, y_train, y_test =
fv.train_test_split(test_size=0.2)训练模型:
from xgboost import XGBClassifier
model = XGBClassifier()
model.fit(X_train, y_train)评估模型:
from sklearn.metrics import accuracy_score,
f1_score y_pred = model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
f1 = f1_score(y_test, y_pred)将模型保存在 Hopsworks 模型注册表中:
mr = project.get_model_registry()
model_dir = "check_fraud_detection_model"
model.save_model(model_dir + "/model.json")
model_evaluation = {"accuracy": accuracy, "f1_score": f1}
check_fraud_model = mr.python.create_model(
name="check_fraud_detection_model",
feature_view=fv,
metrics=model_evaluation,
description="Check fraud detection model"
)
check_fraud_model.save(model_dir)4.4 推理管道
加载训练好的模型和 OCR 处理器:
from xgboost import XGBClassifier
mr = project.get_model_registry()
retrieved_model = mr.get_model(
name="check_fraud_detection_model",
version=1
)
saved_model_dir = retrieved_model.download()
model_fraud_detection = XGBClassifier()
model_fraud_detection.load_model(saved_model_dir
+ "/model.json")
ocr_processor, ocr_model = load_check_parser()定义一个函数来使用 LLM 生成解释:
def generate_explanation(check_image_path):
parsed_text =ocr_model(ocr_processor(
Image.open(check_image_path),
return_tensors="pt"))["parsed_text"][0]
is_fraud = model.predict([get_features(parsed_text)])[0]
if is_fraud:
prompt = f"The check with the following parsed
text is
considered fraudulent:\n\n{parsed_text}
\n\nExplain why this check is considered
fraudulent."
explanation = llm(prompt)
else:
explanation = "The check is considered valid."
return is_fraud, explanation每日处理新支票:
import os
check_dir = "path/to/daily/check/images"
results = []
for check_image in os.listdir(check_dir):
check_path = os.path.join(check_dir, check_image)
is_fraud, explanation = generate_explanation(check_path)
results.append({"check_id": check_image.split(".")
[0],"is_fraud": is_fraud,"explanation": explanation})
result_df = pd.DataFrame(results)将结果保存在特征组中:
result_fg = fs.get_or_create_feature_group(
name="check_validation_fg",
version=1,
primary_key=["check_id"],
description="Check validation results"
)
result_fg.insert(result_df)5、结束语
在这篇博文中,我们了解了如何使用 LLM 构建支票欺诈检测系统。我们将流程分为三个主要部分:
- 用于从支票图像中提取特征的特征管道
- 用于训练欺诈检测模型的训练管道
- 用于使用 LLM 预测欺诈并生成解释的推理管道
通过自动化解释生成过程,我们可以为金融机构节省大量时间和资源。LLM 生成的解释可以作为人类员工的起点,然后他们可以根据需要对其进行审查和修改。本示例的目的是让你很好地理解如何在支票欺诈检测等实际应用中使用 LLM。
原文链接:Building a Cheque Fraud Detection and Explanation AI System using a fine-tuned LLM
BimAnt翻译整理,转载请标明出处





