
NSDT工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器 - REVIT导出3D模型插件 - 3D模型语义搜索引擎 - AI模型在线查看 - Three.js虚拟轴心开发包 - 3D模型在线减面 - STL模型在线切割 - 3D道路快速建模
CLIP 等多模态模型通过将图像等复杂对象与易于理解、生成和解析的文本描述联系起来,开辟了新的 AI 用例。但是,像 CLIP 这样的现成模型可能无法代表特定领域中常见的数据,在这种情况下,可能需要进行微调以使模型适应该领域。
这篇文章展示了如何根据《纽约客》杂志的卡通图像和这些卡通的笑话标题微调 CLIP 模型。它基于 capcon,这是一个与《纽约客》卡通比赛相关的各种任务的数据集。其中一项任务是拍摄一张卡通图像并从可能的标题列表中预测合适的标题。让我们看看如何为这项任务微调 CLIP。
1、数据
数据托管在 gs://datachain-demo/newyorker_caption_contest 上并公开提供,它包含两个部分:
images:图像,一个 JPEG 文件文件夹,每个文件代表一张卡通图像。new_yorker_meta.parquet:包含图像元数据的 parquet 文件,包括图像的多种标题选择和正确的标题选择。
为了处理这些数据,我们将使用开源库 datachain,它有助于将此类非结构化数据整理成更结构化的格式(免责声明:我帮助开发了 datachain)。本文中使用的所有代码都可以在 GitHub 上的 Jupyter Notebook 中找到,或者你可以在 Colab 中运行它。
首先,我们从源中读取图像和元数据,然后根据文件名(在元数据中作为一列提供)将它们连接起来:
from datachain import C, DataChain
from datachain.sql.functions import path
img_dc = DataChain.from_storage("gs://datachain-demo/newyorker_caption_contest/images", type="image", anon=True)
meta_dc = DataChain.from_parquet("gs://datachain-demo/newyorker_caption_contest/new_yorker_meta.parquet")
dc = img_dc.mutate(filename=path.name(C("file.path"))).merge(meta_dc, on="filename")代码首先从目录中的图像创建一个数据集 img_dc,存储每个文件的基本信息,稍后我们将使用这些信息读取图像。然后,它从元数据的 parquet 文件中创建数据集 meta_dc。最后,它根据图像文件名合并这两个数据集。
img_dc 包含一个 file.path 列,其中包含文件的完整路径,而 img_dc.mutate(filename=path.name(C("file.path"))) 仅提取该路径的最后一部分,该部分与 meta_dc 中 filename 列的内容相匹配。合并后的 dc 数据集包含每个图像的文件信息和元数据。
我们可以通过像这样过滤和收集数据来查看数据样本:
sample = dc.filter(C("file.path").endswith("/371.jpeg")).limit(1)
sample_results = list(sample.collect("file", "caption_choices", "label"))这会将数据限制为以 /371.jpeg 结尾的图像,并仅收集“file”、“caption_choices”、“label”列。结果输出包括一个 ImageFile(见下文)、一个可能的标题列表和一个正确标题字母选择的标签。由于每个图像有多行,并且标题选择不同,因此您最终可能会得到略有不同的结果。
[(ImageFile(source='gs://datachain-demo', path='newyorker_caption_contest/images/371.jpeg', size=25555, version='1719848719616822', etag='CLaWgOCXhocDEAE=', is_latest=True, last_modified=datetime.datetime(2024, 7, 1, 15, 45, 19, 669000, tzinfo=datetime.timezone.utc), location=None, vtype=''),
["I feel like we've gotten a little soft, Lex.",
"Hold on, the Senate Committee on Women's Health is getting out.",
"I know a specialist, but he's in prison.",
'Six rounds. Nine lives. You do the math.',
'Growth has exceeded our projections.'],
'D')]我们可以使用 ImageFile 对象的 read() 方法从中获取图像本身,如果你按照笔记本中的说明操作,您可以亲眼看到。在这个示例中,我们有一幅老鼠用枪指着猫的卡通画,正确的标题是选项 D,上面写着“六发子弹。九条命。你算算吧。”
2、应用基础 CLIP 模型
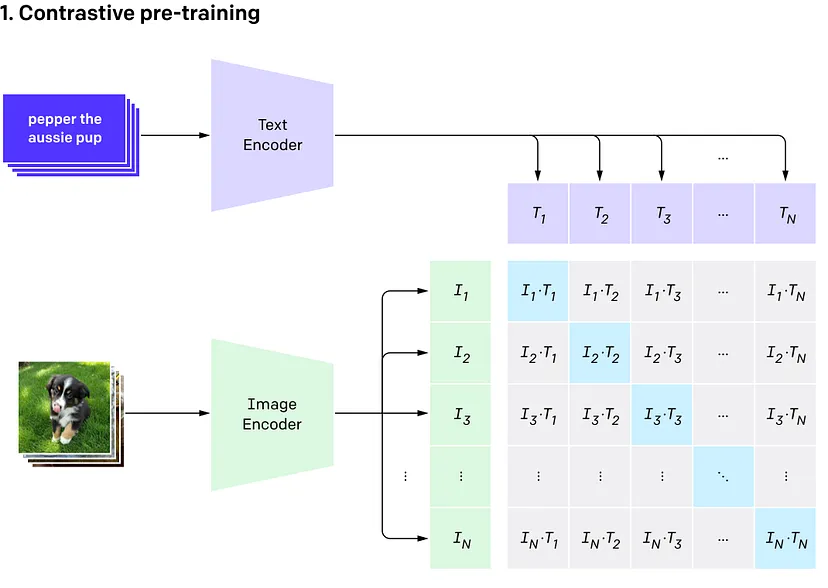
我们可以将 CLIP 应用于这些数据,以预测每个标题的可能性。这类似于 CLIP 的基本架构,它使用对比学习来获取图像并从一批文本标题中辨别出最可能的标题(反之亦然)。
在训练期间,CLIP 将批量图像-文本对作为输入,每个图像都映射到其文本标题。对于每个批次,CLIP 计算每个图像与批次中每个文本的余弦相似度,这样它不仅具有匹配的相似度,还具有每个不匹配的图像-文本对的相似度(见下图)。
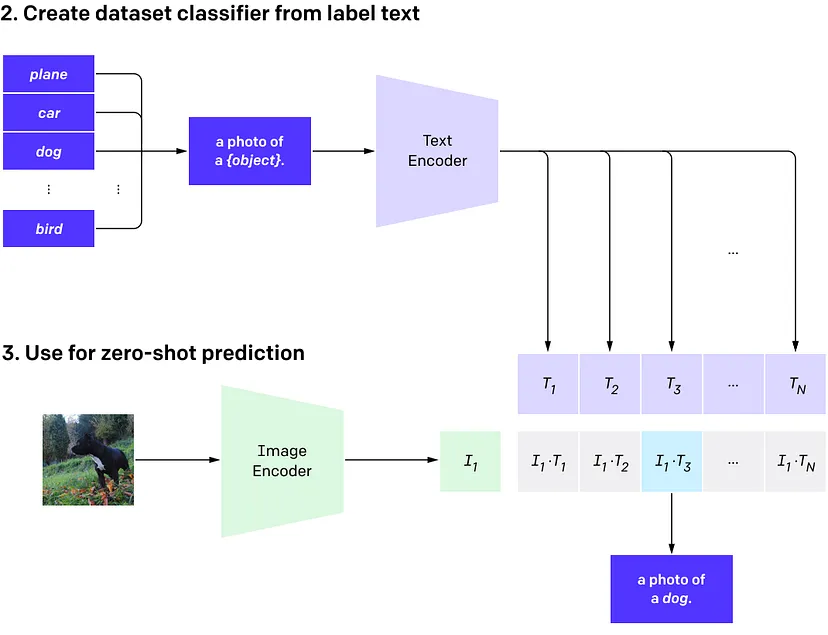
然后,它将其视为分类问题,其中匹配被视为正确标签,不匹配被视为不正确的标签。在推理过程中,这可以用作零样本预测器,方法是输入图像和一批标题,CLIP 将为此返回每个标题的概率。
要深入了解 CLIP,请参阅 OpenAI 原始帖子,或者 Chip Huyen 在此处对其工作原理进行了很好的总结。
对于卡通数据集,我们可以输入样本图像和标题选项,以返回每个选项正确匹配的概率。代码如下:
import clip
import torch
device = "cuda" if torch.cuda.is_available() else "cpu"
model, preprocess = clip.load("ViT-B/32", device=device)
image = example[0].read()
image = preprocess(image).unsqueeze(0).to(device)
text = clip.tokenize(example[1]).to(device)
logits_per_image, logits_per_text = model(image, text)
logits_per_image.softmax(dim=1)[0]首先,我们将 ViT-B/32 预训练模型和图像预处理器加载到设备上。然后,我们将图像转换为预期的张量输入,并对文本标题进行标记以执行相同操作。接下来,我们在这些转换后的输入上运行模型,以获取图像与每个文本的 logit 相似度分数,最后运行 softmax 函数以获取每个文本标题的相对概率。
输出显示 CLIP 已经可以自信地预测此示例的正确标题,因为标题 D(第四个标题)的概率为 0.9844(如果您自己尝试,您的示例中可能会有不同的标题选择,这可能会导致不同的结果):
tensor([0.0047, 0.0013, 0.0029, 0.9844, 0.0067], grad_fn=<SelectBackward0>)3、创建训练数据集
现在我们知道如何应用 CLIP 来预测字幕,我们可以构建一个训练数据集来微调模型。让我们获取随机 10 幅图像的相似度分数(您可以将其增加到更大的尺寸,但在这里我们将保持较小尺寸,以便于在笔记本电脑 CPU 上快速跟进)。以下是执行此操作的代码:
from datachain.torch import clip_similarity_scores
train_dc = dc.shuffle().limit(10).save("newyorker_caption_contest_train")
train_dc = train_dc.map(
func=lambda img_file, txt: clip_similarity_scores(img_file.read(), txt, model, preprocess, clip.tokenize, prob=True)[0],
params=["file", "caption_choices"],
output={"scores": list[float]}
)首先,我们从数据集中随机抽取并保存 10 张图像。然后,我们使用 map() 方法将函数应用于每条记录,并将结果保存为新列。我们使用实用函数 clip_similarity_scores,该函数在一行中执行上一节中的步骤以获取字幕概率。`map()` 函数的输入由 params=["file", "caption_choices"] 定义,输出列由 output={"scores": list[float]} 定义。
对于训练,我们还需要正确字幕的基本事实,因此我们再次使用 map() 计算每条记录的正确字幕的索引,以及该字幕的 CLIP 概率,以便我们了解基线 CLIP 的表现如何:
import string
def label_ind(label):
return string.ascii_uppercase.index(label)
def label_prob(scores, label_ind):
return scores[label_ind]
train_dc = (
train_dc.map(label_ind, params=["label"], output={"label_ind": int})
.map(label_prob, params=["scores", "label_ind"], output={"label_prob": float})
)
train_dc = train_dc.save()我们可以运行 train_dc.avg("label_prob") 来获取训练样本正确标题的平均概率。平均值将取决于训练数据集中的随机样本,但您应该看到比上面的样本图像低得多的值,因此其他图像似乎不太容易让基线 CLIP 正确预测。
4、微调
要微调 CLIP,我们需要创建一个 train() 函数来循环训练数据并更新模型:
def train(loader, model, optimizer, epochs=5):
if device == "cuda":
model = model.float()
loss_func = torch.nn.CrossEntropyLoss()
for epoch in range(epochs):
total_loss = 0
for images, texts, labels in loader:
optimizer.zero_grad()
batch_loss = 0
for image, text, label in zip(images, texts, labels):
image = image.to(device).unsqueeze(0)
text = text.to(device)
label = label.to(device).unsqueeze(0)
logits_per_image, logits_per_text = model(image, text)
batch_loss += loss_func(logits_per_image, label)
batch_loss.backward()
optimizer.step()
batch_loss = batch_loss.item()
total_loss += batch_loss
print(f"loss for epoch {epoch}: {total_loss}") 对于每对图像与文本标题的配对,该函数都会计算 logit 相似度得分,使用正确的标签索引应用损失函数,并执行反向传递以更新模型。
这与基本 CLIP 的工作方式非常相似,除了一个区别。基本 CLIP 期望每个批次都包含图像-文本对,其中每幅图像都有一个对应的文本,并且 CLIP 必须从批次中的其他样本中获取不正确的文本以进行对比学习(参见上图)。对于卡通数据集,每幅图像不仅已经具有相应的正确文本标题,而且还具有多个不正确的文本标题。因此,上面的函数不依赖批次中的其他样本进行对比学习,而是仅依赖于为该图像提供的文本标题选择。
要将训练数据输入此函数,我们需要生成一个 PyTorch 数据集和数据加载器,并将加载器与优化器一起传递给 train() 函数:
from torch.utils.data import DataLoader
ds = train_dc.select("file", "caption_choices", "label_ind").to_pytorch(
transform=preprocess,
tokenizer=clip.tokenize,
)
loader = DataLoader(ds, batch_size=2)
optimizer = torch.optim.Adam(model.parameters(), lr=1e-4)
train(loader, model, optimizer)上面的代码选择了训练所需的列“file”、“caption_choices”、“label_ind”,然后使用 CLIP 预处理器和标记器调用 to_pytorch(),这将返回一个包含预处理后的图像张量、标记化文本和标签索引的 PyTorch IterableDataset。接下来,代码创建一个 PyTorch DataLoader 和优化器,并将它们传递给 train() 以开始训练。
由于我们使用了一个很小的数据集,我们可以很快看到模型适合样本,并且损失显著减少:
loss for epoch 0: 5.243085099384018
loss for epoch 1: 6.937912189641793e-05
loss for epoch 2: 0.0006402461804100312
loss for epoch 3: 0.0009484810252615716
loss for epoch 4: 0.00019728825191123178这应该引起人们对过度拟合的警惕,但对于本练习来说,看到 train() 正在做我们期望的事情很有用:从训练数据集中学习正确的标题。我们可以通过使用微调模型计算训练数据中每张图片正确标题的预测概率来确认:
train_dc = train_dc.map(
func=lambda img_file, txt: clip_similarity_scores(img_file.read(), txt, model, preprocess, clip.tokenize, prob=True)[0],
params=["file", "caption_choices"],
output={"scores_fine_tune": list[float]}
)
train_dc = train_dc.map(label_prob, params=["scores_fine_tune", "label_ind"], output={"label_prob_fine_tune": float})上述代码与微调之前用于计算概率的代码相同。运行 train_dc.avg("label_prob_fine_tune") 输出平均预测概率 >0.99,因此看起来微调按预期工作。
5、结束语
这是一个人工示例,但希望可以让你了解如何微调 CLIP。为了以更稳健的方式解决预测正确标题的任务,你需要获取更大的样本,并根据训练期间未见过的图像和文本的保留样本进行评估。
尝试这样做时,你可能会发现 CLIP 在推广到标题预测问题方面表现不佳,这并不奇怪,因为 CLIP 是为了理解图像内容而不是理解笑话而构建的。CLIP 依赖于相对简单的文本编码器,可能值得探索用于该任务的不同文本编码器。
这超出了微调和这篇文章的范围,但现在你已经知道如何训练 CLIP,您可以尝试这个想法,或者提出自己的想法,了解如何将 CLIP 应用于你的多模态用例。
原文链接:You Do the Math: Fine Tuning Multimodal Models (CLIP) to Match Cartoon Images to Joke Captions
BimAnt翻译整理,转载请标明出处





