
NSDT工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器 - REVIT导出3D模型插件 - 3D模型语义搜索引擎 - AI模型在线查看 - Three.js虚拟轴心开发包 - 3D模型在线减面 - STL模型在线切割 - 3D道路快速建模
作为人类,我们非常了解具有相同对象或相似环境的两张图像之间的相似性。 我们很容易理解下面的两张图片,但让计算机做同样的事情可能会很棘手。

算法或计算机通常需要数字来工作。 这自然让我们想到应该将图像转换为数字列表。 可以将该列表与其他列表进行比较,以了解该图像与其他图像的相似性。
1、什么是嵌入?
这些图像看起来很相似,但就我们的列表而言,它们有一些微小但重要的差异。 如果我们要制作一个简单的数字列表或以某种方式表示特征的数字向量,它会像这样:
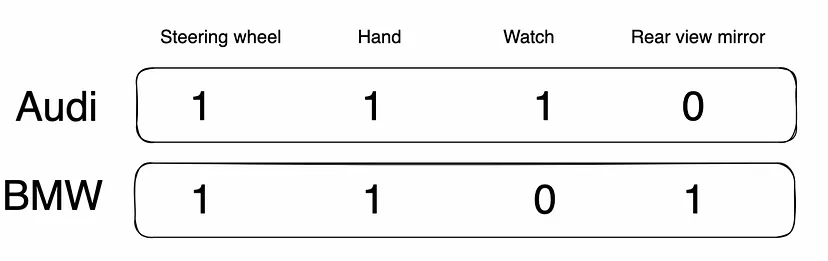
让我们尝试理解上图。 第一张图片的人手上有一块手表。 在第二张图片中,没有手表。 同样,第一张图像有后视镜,而第一张图像没有。 两张图片中都有人的手和方向盘。 上面显示的向量已涵盖了这一点。 这本质上就是我们想要在嵌入或向量表示中捕获的内容。 这种嵌入转化为人类在向量空间中感知的相似性。
当语义相似性可以根据向量空间中嵌入之间的距离来量化时,嵌入被认为是好的。 一旦我们有了这些嵌入,我们就可以尝试找到两个嵌入之间的相似性。 更进一步,我们甚至可以对语义相似的嵌入进行分组。 要形成的组的数量是人为决定的变量。 这个过程称为聚类,常用的方法是K-means聚类或层次聚类。 在这篇文章中,我们将使用 K-means 并探索什么样的图像被分组在一起。
上面所示的 1/0 嵌入可以很容易地从特征方面理解。 我们将探索 CNN 和 Transformers (ViT) 的嵌入创建。 由它们生成的嵌入又大又密集(非零数)。 CNN 通常用于视觉数据,但最近 Transformer 在 CV 领域也受到了广泛关注。 CNN 处理像素阵列,而 Transformer 将图像分割成视觉标记。 Transformers 使用自注意力机制,有助于对跨图像区域的远程多级依赖关系进行建模,这与 CNN 有很大不同。 因此,这些方法的结果可能会有所不同,因此值得尝试这两种方法。
3、使用的数据集
为了这篇博文,我们将使用来自 MovieClips 频道的 300 个随机 YouTube 视频。 这些是来自不同类型和不同电影明星的电影的小片段。
一旦我们将视频分解为帧,我们就会得到大量的帧,因为大多数视频都是 30 fps。 但是,大多数帧都是多余的,因为 0.5 秒内场景没有发生大量变化。 为此,我们开发了一种关键帧提取算法(目前超出了本博文的范围),该算法将视频中所有帧的要处理的帧数减少了约 99%。 这些关键帧是我们接下来用来测试嵌入的关键帧。
4、用CNN提取嵌入向量
卷积神经网络(CNN)是一类通常应用于视觉数据的深度学习架构。 它们可用于将图像转换为嵌入。 在我们的实验中,我们将使用 EfficientNet,这是 Google 的一种 CNN 架构,顾名思义,其目标是在计算资源方面极其高效。 我们可以使用预先训练的 EfficientNet 模型,并使用该模型直到最后一个密集层以获得 1280 维嵌入。 其代码如下:
class FeatureExtractor(nn.Module):
def __init__(self):
super(FeatureExtractor, self).__init__()
efficientnet = torch.hub.load(
'NVIDIA/DeepLearningExamples:torchhub',
f'nvidia_efficientnet_b0',
pretrained=True
)
echildren = list(efficientnet.children())
self.feature_extractor = torch.nn.Sequential(*echildren[:-1])
self.pre_final_stage = torch.nn.Sequential(*echildren[-1][:-1])
def forward(self, data):
feats = self.feature_extractor(data)
feats = self.pre_final_stage(feats)
return feats完成必要的预处理步骤后,此处的前向传递将返回图像的嵌入。 这样我们就可以嵌入剪辑中的所有关键帧。 现在我们将尝试使用 K 均值对它们进行聚类。 情况如下:
from sklearn.cluster import KMeans
from sklearn.preprocessing import StandardScaler
embeddings_standardized = StandardScaler().fit_transform(embeddings)
kmeanModel = KMeans(n_clusters=num_clusters).fit(embeddings_standardized)使用构建的模型,我们可以查看聚类中心,并收集一些最接近中心的嵌入,以查看这些图像在视觉上的相似程度。 这些嵌入的集群在语义上真的与人类相似吗? 以下是 num_clusters 为 100 时 K-means 后的一些示例。






这些结果令人惊讶,因为我们人类也会将它们分组为视觉上相似的。 这证实了我们的想法,即 CNN 创建的嵌入确实有效,可以帮助分组为有用的类别,例如帽子或坐在车内的人。 现在让我们尝试一下基于transformers的嵌入的实验。
5、用transformer提取嵌入向量
如此处所述,ViTMAE 是最近发表的一篇论文,它使用视觉转换器来重建蒙版补丁的像素值。 在仅使用 ImageNet-1K 数据的方法中,Vanilla ViT-Huge 模型实现了最佳准确率 (87.8%)。 Huggingface 链接解释了如何使用预先训练的 ViTMAE 模型从图像中获取嵌入,如下面所附图像中的代码所示:
from transformers import AutoImageProcessor, ViTMAEModel
from PIL import Image
import requests
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
image_processor = AutoImageProcessor.from_pretrained("facebook/vit-mae-base")
model = ViTMAEModel.from_pretrained("facebook/vit-mae-base")
inputs = image_processor(images=image, return_tensors="pt")
outputs = model(**inputs)
last_hidden_states = outputs.last_hidden_state这里的问题是,这不能直接使用,因为transformer有 50 个头,输出的形状为 50x768。 本质上,将 224x224 图像处理成 50x768 矩阵并没有真正减少存储图像表示所需的字节数,并且我们需要较小的嵌入来在合理的时间内对其运行 K 均值聚类以进行此实验。
class FeatureExtractor(nn.Module):
def __init__(self):
super(FeatureExtractor, self).__init__()
self.model = ViTMAEModel.from_pretrained("facebook/vit-mae-base")
def forward(self, inputs):
inputs.pop('image_name', None)
outputs = self.model(**inputs)
return torch.sum(outputs.last_hidden_state, dim=1)为了解决这个问题,一个简单但有效的方法是对 50 个头进行求和,如上面所附的代码所示。 这给了我们一个合理大小的 768 维嵌入,它将用于前面的聚类。 现在继续进行类似于我们上面使用 CNN 方法所做的 Kmeans 聚类过程,这些是一些结果。



ViTMAE 嵌入中有一些有趣的簇,例如爆炸和携带武器的人,但在这种情况下,存在大量簇,当图像在视觉上具有不同性质时,这些簇没有什么意义。 这可能是由于所有transformer头的总和使其不太准确。 一些意想不到的图像在语义上看起来非常不同的集群是:


6、结束语
根据我们上面的实验,图像特征提取器与 K-means 等聚类算法配合使用时效果很好。 嵌入可以在寻找语义相似的图像方面发挥出色的作用。 看来我们需要改变基于 Transformer 的模型的方法,以返回本身较短的嵌入,并且不必进行平均以在性能上与基于 CNN 的嵌入相匹配。 总的来说,这可以成为探索视频语料库中内容的整体方法。
另一方面,我们还可以通过将查询图像投影到语义空间并查找附近的嵌入来翻转该过程。 这有助于我们从大量图像中找到与特定图像相似的图像。 在 GumGum,我们使用这种技术来收集语义相似的图像,以在需要与特定类别相关的图像进行模型训练时减少注释工作。
相同的概念也可以应用于文本和音频。 尽情享受自己的嵌入实验吧。
原文链接:Clustering Image Embeddings
BimAnt翻译整理,转载请标明出处





