
NSDT工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器 - REVIT导出3D模型插件 - 3D模型语义搜索引擎 - AI模型在线查看 - Three.js虚拟轴心开发包 - 3D模型在线减面 - STL模型在线切割 - 3D道路快速建模
很难说人工智能是否会取代我们的工作或成为我们的老板。然而,在这种情况发生之前,值得了解它作为一种工具。
在本教程中,我们将学习如何使用AI模型生成代码。我们将安装 llama.cpp 和 Ollama,提供 CodeLlama 和 Deepseek Coder 模型,并通过扩展(Continue、Twinny、Cody Ai 和 CodeGPT)在 IDE(VS Code / VS Codium、IntelliJ)中使用它们。
注意:我使用的是 AMD 5600G APU,但你在此处看到的大部分内容也适用于独立 GPU。每当某些东西是 APU 特定的,我都会将其标记为特定。我使用带有 ROCm 的容器,但 Nvidia CUDA 用户也应该会发现本指南很有帮助。
1、代码生成模型
广义上讲,选择模型时,我们必须考虑其类型、大小和量化 2:
- 指令类型模型旨在回答聊天窗口中提出的问题
- 基本类型模型用于自动完成代码,它们建议后续代码行
- 模型大小是 LLM 中的参数数量,例如 70 亿,尺寸越大意味着需要的内存越多,模型越慢
- 量化从 2、3、4、5、6 到 8 位,位数越大意味着需要的内存越多,模型越慢
代码完成模型在后台运行,因此我们希望它们非常快。我使用小型 deepseek-coder-1.3b-base-GGUF 4 来完成这项任务。聊天模型更具按需性,因此它们可以和 VRAM 一样大,例如CodeLlama-7B-Instruct-GGUF 2.
2、访问容器中的服务
默认情况下,llama.cpp 和 Ollama 服务器监听本地主机 IP 127.0.0.1。由于我们想从外部连接到它们,因此在本教程的所有示例中,我们将该 IP 更改为 0.0.0.0。通过此设置,我们有两个选项可以连接到容器内的 llama.cpp 和 Ollama 服务器。
我们可以使用容器的 IP 访问服务器。这很简单,适用于主机和同一主机上的其他容器。我们可以使用 incus list 命令获取容器的 IP。
但是,如果我们想将这些服务器公开给我们网络上的其他计算机,我们可以使用代理网络设备。对于每个服务的模型,例如一个 instruct 和一个 base,需要一个具有不同端口的代理设备。监听地址可以是你的机器的 IP,你可以使用 hostname -I | awk '{print $1}' 命令获取。相应地更改 X.X.X.X,端口取决于你使用的是 llama.cpp 还是 Ollama:
incus config device add <container_name> localhost8080 proxy listen=tcp:X.X.X.X:8080 connect=tcp:0.0.0.0:8080
incus config device add <container_name> localhost8081 proxy listen=tcp:X.X.X.X:8081 connect=tcp:0.0.0.0:8081此选项有一个缺点。当我们断开主机与路由器的连接(拔掉以太网电缆、切换到飞行模式等)时,该主机上带有代理设备的容器将无法启动并会产生错误:
Error: Error occurred when starting proxy device: Error: Failed to listen on 192.168.1.185:8080: listen tcp 192.168.1.185:8080: bind: cannot assign requested address
Try `incus info --show-log test` for more info
$ incus info --show-log test
Name: test
Status: STOPPED
Type: container
Architecture: x86_64
Created: 2024/04/14 18:46 CEST
Last Used: 2024/04/14 18:49 CEST
Log:
lxc test 20240414164901.173 WARN idmap_utils - ../src/lxc/idmap_utils.c:lxc_map_ids:165 - newuidmap binary is missing
lxc test 20240414164901.173 WARN idmap_utils - ../src/lxc/idmap_utils.c:lxc_map_ids:171 - newgidmap binary is missing
lxc test 20240414164901.174 WARN idmap_utils - ../src/lxc/idmap_utils.c:lxc_map_ids:165 - newuidmap binary is missing
lxc test 20240414164901.174 WARN idmap_utils - ../src/lxc/idmap_utils.c:lxc_map_ids:171 - newgidmap binary is missing如果你只想在主机上使用 llama.cpp 和 Ollama,只需使用容器的 IP 地址访问它们并跳过代理设备即可。
3、llama.cpp
对于 llama.cpp,我们需要一个安装了 ROCm 的容器(不需要 PyTorch)。相关教程在这里。它的大小约为 30 GB,所以不要感到惊讶。如果你打算在同一个容器中运行 IDE,请在创建它时使用 GUI 配置文件 。
让我们使用默认的 ubuntu 用户登录容器:
incus exec <container_name> -- sudo --login --user ubuntu获取 llama.cpp 源代码很简单,我们可以使用带有最新版本标签的 git clone 命令:
sudo apt install git ccache make
git clone --depth 1 --branch b2953 https://github.com/ggerganov/llama.cppllama.cpp 支持 UMA,有关更多信息,请参阅之前链接的 ROCm 教程,因此我将使用必要的标志对其进行编译(构建标志取决于您的系统,因此请访问官方网站了解更多信息)。对于我的 AMD 5600G APU,我使用:
- LLAMA_HIPBLAS=1,它在支持 HIP 的 AMD GPU 上提供 BLAS 加速
- LLAMA_HIP_UMA=1 是 APU 专用的,如果您有常规 GPU 或在 UEFI/BIOS 中为 APU 分配了固定数量的 VRAM,请跳过它
- AMDGPU_TARGETS=gfx900 取决于您的 GPU 架构,有关更多信息,请参阅之前链接的 ROCm 教程
有了所有这些,我的编译命令如下所示:
cd llama.cpp
make LLAMA_HIPBLAS=1 LLAMA_HIP_UMA=1 AMDGPU_TARGETS=gfx900使用 llama.cpp 时,我们必须手动下载模型。找到它们的最佳地点是 huggingface.co。例如:
- 你可以从 TheBloke 帐户中搜索所有 GUFF 模型
- 或所有用户提交的 starcoder2 指令模型
让我们将 deepseek-coder-1.3b-base-GGUF 和 CodeLlama-7B-Instruct-GGUF 下载到 ~/llama.cpp/models/ 文件夹中:
wget https://huggingface.co/TheBloke/deepseek-coder-1.3b-base-GGUF/resolve/main/deepseek-coder-1.3b-base.Q6_K.gguf -P ~/llama.cpp/models/
wget https://huggingface.co/TheBloke/CodeLlama-7B-Instruct-GGUF/resolve/main/codellama-7b-instruct.Q6_K.gguf -P ~/llama.cpp/models/你还可以使用 Ollama 下载模型并将其复制到 llama.cpp。请参阅 ollama库列表 。 我们将在 Ollama 部分讨论此选项。
现在我们可以提供这些模型了。我想同时为它们提供服务,因此在两个单独的终端窗口中我使用命令:
~/llama.cpp/./server -c 4096 -ngl 999 --host 0.0.0.0 -m ~/llama.cpp/models/codellama-7b-instruct.Q6_K.gguf
~/llama.cpp/./server -c 4096 -ngl 999 --host 0.0.0.0 --port 8081 -m ~/llama.cpp/models/deepseek-coder-1.3b-base.Q6_K.gguf其中:
- -c N 是提示上下文的大小(默认值:512)
- -ngl N 是要存储在 VRAM 中的层数(增加直到您几乎使用了所有 VRAM,或者使用值 999 尝试将所有层移动到内存中)
- --host IP 是要监听的 IP 地址(默认值:127.0.0.1)
- --port PORT 是要监听的端口(默认值:8080)
- -m 是模型路径
- 运行 ~/llama.cpp/./server --help 获取更多选项
现在可以使用容器 IP 地址或代理设备的 IP 地址(如果您使用了代理设备)访问模型:
http://X.X.X.X:8080
http://X.X.X.X:80814、Ollama
注意:在 APU 上运行的开箱即用的 Ollama 需要在 UEFI/BIOS 中为 GPU 分配固定数量的 VRAM(有关详细信息,请参阅之前链接的 ROCm 教程)。但我们可以通过仅更改两行代码来编译它,从而启用 UMA 支持。请参阅下面的编译 Ollama 部分。普通 GPU 的用户不必担心这一点。
我们需要一个安装了 ROCm 的容器(不需要 PyTorch),就像 llama.cpp 的情况一样。如果您打算在同一个容器中运行 IDE,请在创建它时使用 GUI 配置文件。
安装 Ollama 时,脚本将尝试下载其自己的 ROCm 版本,因此我们有 4 个选项:
- 容器内已经有 ROCm 6.0+,则脚本将跳过此步骤
- 容器内已经有 ROCm 5.7,则脚本将安装其自己的 ROCm,并且运行正常,Ollama 将使用版本 5.7
- 我们有一个没有 ROCm 的容器,则脚本将安装其自己的 ROCm,但这不起作用
- 不要使用脚本并手动安装 Ollama
对于我的 5600G APU,我使用最新的 ROCm 6.1。
让我们使用默认的 ubuntu 用户登录容器:
incus exec <container_name> -- sudo --login --user ubuntu在下载并运行安装脚本之前,我们需要安装一些所需的软件包:
sudo apt install curl nano
curl -fsSL https://ollama.com/install.sh | sh脚本完成后,默认的 ubuntu 用户将添加到 ollama 组,并启动新的 ollama 服务。此服务仅运行命令 ollama serve,但作为用户 ollama,因此我们需要设置一些环境变量。对于我的 APU,我需要:
- HSA_OVERRIDE_GFX_VERSION=9.0.0 和 HSA_ENABLE_SDMA=0(用于 ROCm),如之前链接的教程中所述
- OLLAMA_HOST=0.0.0.0:11434 将 Ollama 使用的 IP 地址更改为 0.0.0.0
- OLLAMA_MAX_LOADED_MODELS=2 同时为两个模型提供服务,根据需要调整此值
我们需要使用命令将它们添加到服务中:
sudo systemctl edit ollama在空白处添加以下几行:
[Service]
Environment="HSA_OVERRIDE_GFX_VERSION=9.0.0"
Environment="HSA_ENABLE_SDMA=0"
Environment="OLLAMA_HOST=0.0.0.0:11434"
Environment="OLLAMA_MAX_LOADED_MODELS=2"重新加载守护进程,然后重新启动容器并再次登录:
sudo systemctl daemon-reload现在我们可以使用命令访问 Ollama:
ollama --help
ollama list使用默认 ollama 服务下载的模型将存储在 /usr/share/ollama/.ollama/models/.
所有可用模型均列在ollama库列表。 选择所需模型后,单击它,然后在其页面上,从标有“最新”的下拉菜单中选择最后一个选项“查看所有标签”以查看所有变体。事实上,最新意味着最受欢迎,因此请查找具有相同哈希值的模型以解密其背后的内容。下拉菜单右侧有一个框,其中包含运行所选模型变体的命令,但我们不会使用它。
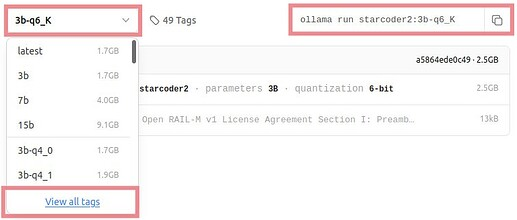
让我们下载与 llama.cpp 相同的模型,但更方便:
ollama pull codellama:7b-instruct-q6_K
ollama pull deepseek-coder:1.3b-base-q6_K现在可以使用容器 IP 地址或代理设备的 IP 地址(如果使用过)访问这两种模型:
http://X.X.X.X:11434请注意,在使用命令 ollama serve 启动 Ollama 时,我们没有指定模型名称,就像使用 llama.cpp 时必须指定的那样。客户端将向服务器询问他们需要的特定模型。
5、编译 Ollama(可选,仅适用于 APU)
编译 Ollama 需要比 Ubuntu 22.04 中可用的版本更新的 cmake 和 go 版本:
- cmake 版本 3.24 或更高版本
- go 版本 1.22 或更高版本
- gcc 版本 11.4.0 或更高版本
- 适用于 AMD ROCm 的 libclblast
让我们在我们的 ROCm 容器中安装来自官方来源的最新软件包:
sudo apt install nano git ccache libclblast-dev make
wget https://go.dev/dl/go1.22.3.linux-amd64.tar.gz
tar -xzf go1.22.3.linux-amd64.tar.gz
wget https://github.com/Kitware/CMake/releases/download/v3.29.3/cmake-3.29.3-linux-x86_64.tar.gz
tar -xzf cmake-3.29.3-linux-x86_64.tar.gz我们需要将解压的目录添加到 PATH。使用 nano .profile 打开 .profile 文件并在末尾添加以下行:
export PATH=$PATH:/home/ubuntu/go/bin:/home/ubuntu/cmake-3.29.3-linux-x86_64/bin使用 source ~/.profile命令确保环境变量已设置。
获取 Ollama 源代码很简单,我们可以使用带有最新版本标签的 git clone 命令:
git clone --depth 1 --branch v0.1.38 https://github.com/ollama/ollamaOllama 在底层使用 llama.cpp,因此我们需要传递一些编译时所需的环境变量。有一个未记录的 OLLAMA_CUSTOM_ROCM_DEFS 环境变量,我们可以在其中设置 CMAKE_DEFS(请注意,这些参数与我在编译 llama.cpp 时使用的参数相同,但在你的情况下可能会有所不同,因此请查看前面的 llama.cpp 部分以获取更多信息):
echo 'export OLLAMA_CUSTOM_ROCM_DEFS="-DLLAMA_HIP_UMA=on -DHSA_ENABLE_SDMA=off -DAMDGPU_TARGETS=gfx900 -DHSA_OVERRIDE_GFX_VERSION=9.0.0"' >> .profile
source .profile我们必须更改的第二件事是在 ollama/gpu/amd_linux.go 文件中。找到以 if totalMemory < IGPUMemLimit {开头的行。在它之前添加 totalMemory = 24 * format.GibiByte,其中值 24 是 Ollama 可以为模型使用多少 VRAM。我不会超出 your_RAM_in_GB - 8。此代码应如下所示:
totalMemory = 24 * format.GibiByte
if totalMemory < IGPUMemLimit {
slog.Info...现在 Ollama 认为我的 iGPU 已分配 24 GB 的 VRAM,并且不会抱怨。Ollama 运行并加载模型时将使用最多 24 GB,但当我们停止容器时,我们的 RAM 将再次释放。
编译很简单,大约需要 10 分钟:
cd ollama
go generate ./...
go build .现在可以使用以下命令运行 Ollama:
~/ollama/./ollama serve设置 systemd 服务很简单(粘贴此多行命令,根据需要更改环境变量):
sudo tee /etc/systemd/system/ollama.service > /dev/null <<EOF
[Unit]
Description=Ollama Service
After=network-online.target
Requires=multi-user.target
[Service]
ExecStart=/home/ubuntu/ollama/ollama serve
User=ubuntu
Group=ubuntu
Restart=always
RestartSec=3
Environment="HSA_OVERRIDE_GFX_VERSION=9.0.0"
Environment="HSA_ENABLE_SDMA=0"
Environment="OLLAMA_HOST=0.0.0.0:11434"
Environment="OLLAMA_MAX_LOADED_MODELS=2"
Environment="PATH=$(printenv PATH)"
[Install]
WantedBy=default.target
EOF重新加载守护进程并启用服务,然后重新启动容器:
sudo systemctl daemon-reload
sudo systemctl enable ollama检查一切是否正常:
systemctl status ollama6、Ollama 模型的其他用途
使用 Ollama 下载的模型采用通常的 GUFF 格式,可以在其他地方使用。但它们的文件名由 sha256 哈希组成。为了获得人性化的名称,我们可以使用基于 Matt Williams 作品的脚本。只需运行此脚本,你将看到真实的模型名称,然后可以复制文件并相应地重命名它们。脚本需要 jq 包,你可以使用 sudo apt install jq 命令安装它。
#!/bin/bash
# Based on Matt Williams' script https://github.com/technovangelist/matts-shell-scripts/blob/main/syncmodels
# Prints human-readable Ollama model names
# Requires `jq` package
# sudo apt install jq
base_dir_1=/usr/share/ollama/.ollama/models
base_dir_2=~/.ollama/models
# Use find to get all files under the 'model' directories
function print_models() {
manifest_dir=${base_dir}/manifests/registry.ollama.ai
blob_dir=${base_dir}/blobs
find "${manifest_dir}" -mindepth 3 -maxdepth 3 -type f | while IFS= read -r file; do
model=$( basename "$( dirname "${file}" )" )
tag=$( basename "${file}" )
digest=$( jq -r '.layers[] | select(.mediaType == "application/vnd.ollama.image.model") | .digest' "${file}" )
# Print model paths and human-readable names
echo "${blob_dir}/${digest/:/-}"
echo "${model}:${tag}"
done
}
[[ -d ${base_dir_1} ]] && base_dir="${base_dir_1}" && print_models
[[ -d ${base_dir_2} ]] && base_dir="${base_dir_2}" && print_models7、VS Code / VS Codium
为了让 VS Code / VS Codium 在容器中运行,我们需要使用 GUI 配置文件创建容器后,使用默认的 ubuntu 用户登录:
incus exec <container_name> -- sudo --login --user ubuntu对于 VS Code / VS Codium,我们需要安装一些必需的软件包:
- 如果我们想使用 IDE 的 snap 版本,则需要安装 snapd
- 对于缺少的字体,则需要安装 fonts-noto
- 在IDE 窗口中获取与桌面相同的鼠标光标主题,则需要安装 yaru-theme-icon
sudo apt install snapd fonts-noto yaru-theme-icon
sudo snap install code --classic
# sudo snap install codium --classicIncus 容器中的 Snap 需要一种解决方法,否则重启后我们会看到错误:
snap-confine has elevated permissions and is not confined but should be. Refusing to continue to avoid permission escalation attacks
Please make sure that the snapd.apparmor service is enabled and started.解决方案来自@stgraber的 帖子:
sudo sed -i "s/lxd/incus/g" /lib/apparmor/rc.apparmor.functions
sudo mkdir -p /etc/systemd/system/snapd.apparmor.service.d/最后,运行此多行代码片段,创建 override.conf 文件并向其中添加两行:
sudo tee /etc/systemd/system/snapd.apparmor.service.d/override.conf > /dev/null <<EOF
[Service]
ExecStartPre=/usr/bin/mkdir -p /run/WSL
EOF7.1 扩展
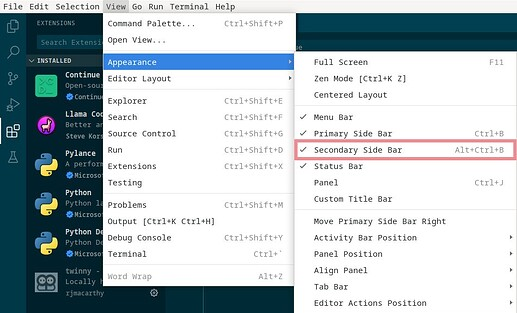
VS Code/VS Codium 的 Continue 和 Twinny 扩展使用右侧边栏。单击“视图”→“外观”→“辅助侧边栏”以将其打开,或按 Alt+Ctrl+B。如果侧边栏无法正确呈现(如果您使用其他扩展,则可能会发生这种情况),只需将其关闭并重新打开即可。
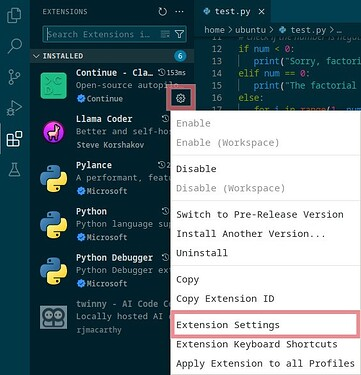
可以通过单击扩展名称旁边的齿轮图标并选择启用/禁用来启用/禁用扩展。
7.2 Continue
第一个可以与 llama.cpp 和 Ollama 服务器交互的 VS Code / VS Codium 扩展是 Continue(VS Code 市场 ,VS Codium 市场)。它有一个聊天窗口和代码自动完成功能。
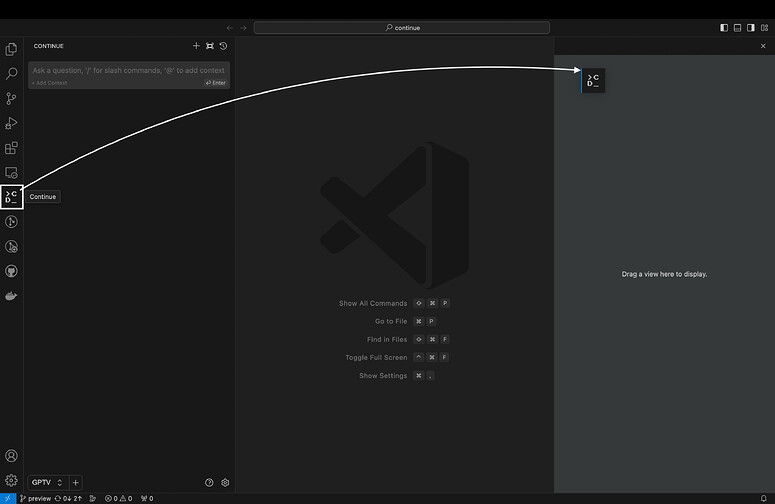
我们可以在 IDE 左侧的扩展选项卡中搜索 Continue(Ctrl+Shift+X)来安装它。安装后,你 将看到 Continue 徽标出现在左侧栏中。强烈建议将此徽标移至 VS Code 的右侧栏。
单击扩展选项卡中 Continue 旁边的齿轮图标并选择扩展设置时,有更多选项可用。这些都是完全可选的,我没有在那里更改任何内容。如果你决定使用代码自动完成,你可以在那里或在侧栏底部切换该功能。
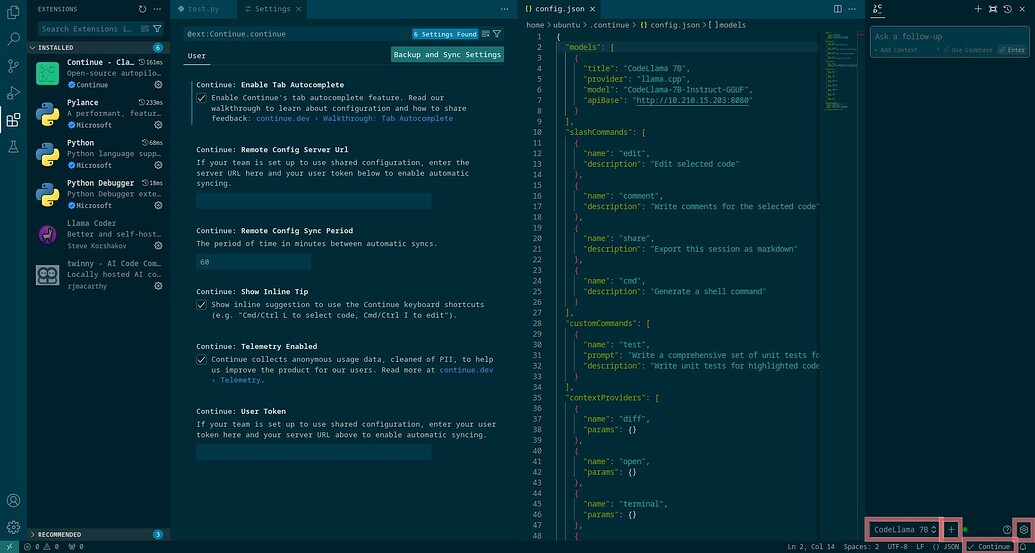
我们可以通过两种方式添加模型提供程序。一种是使用侧边栏底部活动提供程序名称旁边的加号图标。这值得探索,因为您可以在那里设置一些高级(可选)选项。
我使用另一种方法,即单击加号图标旁边的齿轮图标。这将打开 config.json 文件。这些是我对 llama.cpp 和 Ollama 聊天模型的设置(我删除了默认提供程序,X.X.X.X 是容器的 IP 地址,还要注意逗号,在一些行和括号之后,模型名称仅对 Ollama 很重要,完成后按 Ctrl+S 保存):
"models": [
{
"title": "CodeLlama 7B",
"provider": "llama.cpp",
"model": "CodeLlama-7B-Instruct-GGUF",
"apiBase": "http://X.X.X.X:8080"
},
{
"title": "ollama CodeLlama 7B",
"provider": "ollama",
"model": "codellama:7b-instruct-q6_K",
"apiBase": "http://X.X.X.X:11434"
}
],添加提供商后,在侧边栏底部,我们应该可以看到活动的提供商,我们可以通过单击其名称在它们之间切换。
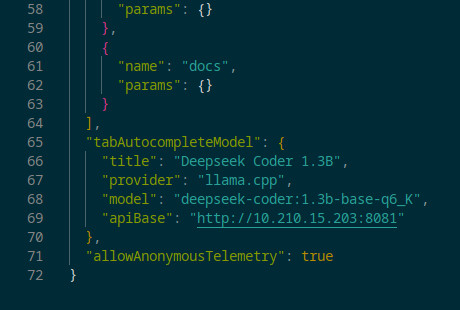
代码自动完成模型(一次只能一个)可以在同一个 config.json 文件中的底部,就在“allowAnonymousTelemetry”行之前设置:true。对于 llama.cpp:
"tabAutocompleteModel": {
"title": "Deepseek Coder 1.3B",
"provider": "llama.cpp",
"model": "deepseek-coder:1.3b-base-q6_K",
"apiBase": "http://X.X.X.X:8081"
},或者对于 Ollama:
"tabAutocompleteModel": {
"title": "Deepseek Coder 1.3B",
"provider": "ollama",
"model": "deepseek-coder:1.3b-base-q6_K",
"apiBase": "http://X.X.X.X:11434"
},
要了解有关 Continue 及其众多功能的更多信息,请查看其主页和 YouTube。
7.3 Twinny
第二个可以与 llama.cpp 和 Ollama 服务器交互的 VS Code / VS Codium 扩展是 Twinny (VS Code 市场、VS Codium 市场)。它有一个聊天窗口和代码自动完成功能。
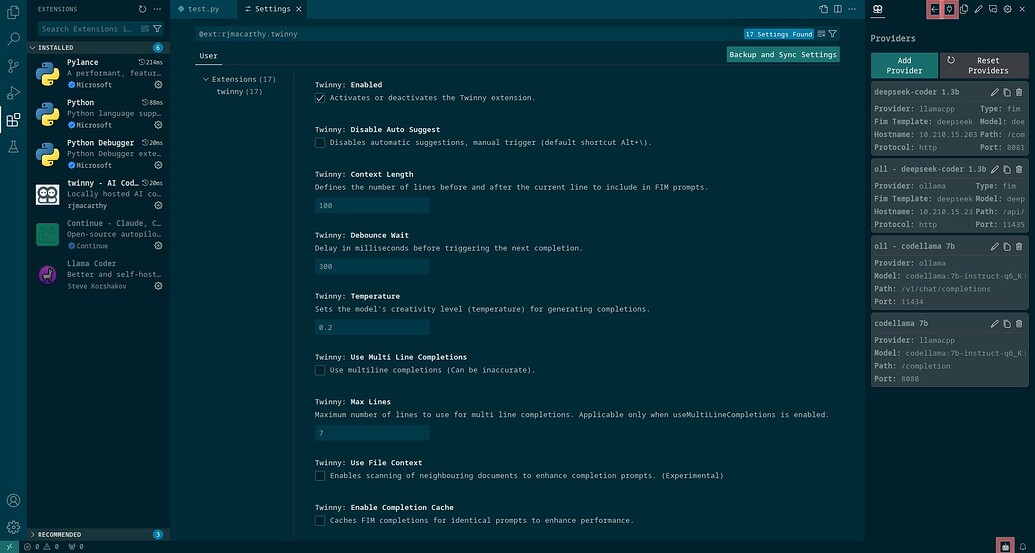
我们可以在 IDE 左侧的扩展选项卡中搜索 Twinny 来安装它(Ctrl+Shift+X)。现在按 Alt+Ctrl+B 打开侧边栏并单击其顶部的插件图标,以便我们可以添加模型提供程序。我正在为 llama.cpp 聊天模型使用这些设置:
- 标签:CodeLlama 7B(可以是任何内容)
- 类型:聊天
- 提供商:llamacpp
- 协议:http
- 模型名称:codellama:7b-instruct-q6_K(仅对 Ollama 重要)
- 主机名:X.X.X.X(容器的 IP)
- 端口:8080
- API 路径:/completion
- API 密钥:空
和基本模型:
- 标签:Deepseek Coder 1.3B(可以是任何内容)
- 类型:FIM
- Fim 模板:deepseek
- 提供商:llamacpp
- 协议:http
- 模型名称:deepseek-coder:1.3b-base-q6_K(仅对 Ollama 重要)
- 主机名:X.X.X.X(容器的 IP)
- 端口:8081
- API 路径:/completion
- API 密钥:空
用于 Ollama 聊天模型:
- 标签:ollama CodeLlama 7B(可以是任何内容)
- 类型:聊天
- 提供商:ollama
- 协议:http
- 模型名称:codellama:7b-instruct-q6_K(仅对 Ollama 重要)
- 主机名:X.X.X.X(容器的 IP)
- 端口:11434
- API 路径:/v1/chat/completions
- API 密钥:空
和基本模型:
- 标签:ollama Deepseek Coder 1.3B(可以是任何内容)
- 类型:FIM
- Fim 模板:deepseek
- 提供商:ollama
- 协议:http
- 模型名称:deepseek-coder:1.3b-base-q6_K(仅对 Ollama 重要)
- 主机名:X.X.X.X(容器的 IP)
- 端口:11434
- API 路径:/api/generate
- API 密钥:空

现在单击侧边栏顶部插头图标旁边的箭头图标。聊天输入字段上方有一个机器人头的图标。单击它时,您将看到两个下拉菜单,用于选择刚刚配置的聊天和中间填充提供商。
单击扩展选项卡中 Twinny 旁边的齿轮图标并选择扩展设置时,有更多选项可用,但这些选项完全是可选的,我没有在那里更改任何内容。
要了解有关 Twinny 及其众多功能的更多信息,请查看其主页和 YouTube。
7.4 Cody Ai
可以与 Ollama 服务器交互(但不是 llama.cpp)的第三个 VS Code / VS Codium 扩展是 Cody Ai (VS Code 市场,VS Codium 市场)。它有一个聊天窗口和代码自动完成功能,但将 Ollama 设置为聊天提供商对我来说不起作用。
Cody Ai 不寻常的事情:
- 这是最先进的代码生成扩展。
- 尽管扩展是开源的,但它需要使用 GitHub、GitLab 或 Google 帐户登录。
- 因此,每次启动 IDE 时都需要互联网访问
- 对于代码自动完成,Cody Ai 可以使用两种类型的模型,即指导和基础。
我们需要安装一些必要的软件包以使 Cody Ai 正常工作:
- chromium 或任何其他浏览器
- gnome-keyring 用于存储登录凭据
- XDG_CURRENT_DESKTOP=ubuntu:GNOME 需要设置一个环境变量,表示容器具有桌面环境(不必是 ubuntu:GNOME,否则您会看到错误“因为无法识别 OS 密钥环来存储当前桌面环境中的加密相关数据。
sudo snap install chromiumsudo apt install gnome-keyringecho "export XDG_CURRENT_DESKTOP=ubuntu:GNOME" >> .profilesudo snap install chromium
sudo apt install gnome-keyring
echo "export XDG_CURRENT_DESKTOP=ubuntu:GNOME" >> .profile重新启动容器并首次运行 VS Code / VS Codium 后,系统将要求我们输入密钥环的新密码。从现在开始,每次启动 IDE 时,系统都会要求您输入此密码。
现在我们可以通过在 IDE 左侧的扩展选项卡中搜索 Cody Ai 来安装它(Ctrl+Shift+X)。安装后,您将看到 Cody Ai 徽标出现在左侧栏上。强烈建议将此徽标移至 VS Code 的右侧栏。
单击 Cody Ai 图标时,您将看到三个登录选项:使用您的 GitHub、GitLab 或 Google 帐户。单击您喜欢的方法,将出现一个带有链接的弹出窗口。使用弹出窗口下方的复制按钮,打开容器中安装的 Chromium,粘贴链接并登录。单击授权并关闭浏览器。您的凭据现在应该存储在您的密钥环中。要检查这一点,您可以重新启动 VS Code/VS Codium。
要添加提供程序,我们需要打开设置。单击扩展选项卡中 Cody Ai 旁边的齿轮图标,然后选择扩展设置。在底部附近,您会找到 Cody Autocoplete 高级提供程序(注意它用于代码自动完成,而不是聊天)。将其设置为experimental-ollama。接下来在 IDE 中或使用任何其他编辑器打开 ~/.config/Code/User/settings.json 文件。添加这些行并保存(X.X.X.X 是容器的 IP 地址):
"cody.autocomplete.experimental.ollamaOptions": {
"url": "http://X.X.X.X:11434",
"model": "deepseek-coder:1.3b-base-q6_K"
}为了实现更慢但更准确的推理,请将模型更改为 codellama:7b-instruct-q6_K,并将 url 更改为 http://X.X.X.X:11434。编辑后,我的 settings.json 文件如下所示(某些行后面的逗号 , 很重要):
{
"workbench.colorTheme": "Solarized Dark",
"editor.inlineSuggest.suppressSuggestions": true,
"cody.autocomplete.advanced.provider": "experimental-ollama",
"cody.autocomplete.experimental.ollamaOptions": {
"url": "http://X.X.X.X:11434",
"model": "deepseek-coder:1.3b-base-q6_K"
}
}将 Ollama 设置为聊天提供商对我来说不起作用。你可以在官方 Cody Ai 博客上阅读更多相关信息,或在 YouTube 频道上观看说明。
8、IntelliJ
为了让 IntelliJ 在容器中运行,我们需要使用 GUI 配置文件 创建容器后,使用默认 ubuntu 用户登录:
incus exec <container_name> -- sudo --login --user ubuntu对于 IntelliJ,我们需要安装一些必需的软件包:
- snapd 如果我们想使用 IDE 的 snap 版本
- default-jdk 某个版本的 java,例如默认版本
- yaru-theme-icon 和 libxcursor1 以便在 IDE 窗口中获得与桌面相同的鼠标光标主题
sudo apt install snapd default-jdk yaru-theme-icon libxcursor1
sudo snap install intellij-idea-community --classicincus 容器中的 Snap 需要 VS Code / VS Codium 部分中提到的解决方法。
8.1 插件
我们可以通过在内置插件市场中搜索插件来安装插件,您可以通过单击主窗口中的插件来访问它。或者,如果您打开了一个项目,请单击左上角的汉堡菜单,然后单击文件 → 设置(或按 Ctrl+Alt+S)并从左侧列表中选择插件。
可以在汉堡菜单 → 文件 → 设置 → 工具(或按 Ctrl+Alt+S)中找到已安装插件的其他设置。

8.2 Continue
第一个可以与 llama.cpp 和 Ollama 服务器交互的 IntelliJ 扩展是 Continue。是的,这个扩展是为两个 IDE(IntelliJ 市场 )开发的。它有一个聊天窗口和代码自动完成功能。
我们可以通过在插件部分提到的内置插件市场中搜索 Continue 来安装它。安装后,只有当您打开项目时才能访问它,图标将显示在窗口的右侧。但您会注意到它的选项卡没有任何按钮。这是因为 JCEF 嵌入式浏览器缺少一些依赖项。我们可以在容器的终端中使用此命令查看缺少哪些库:
ldd /snap/intellij-idea-community/current/jbr/lib/libcef.so | grep "not found"对我来说输出是:
libXdamage.so.1 => not found
libgbm.so.1 => not found
libxkbcommon.so.0 => not found
libpango-1.0.so.0 => not found
libcairo.so.2 => not found安装缺少的库:
sudo apt install libxdamage1 libgbm1 libxkbcommon0 libpango-1.0-0 libcairo2如果你仍然没有在“继续”侧栏中看到聊天提示,请尝试更改 IDE 的启动 Java 运行时:
- 打开汉堡菜单 → 帮助 → 查找操作(或按 Ctrl+Shift+A)
- 输入选择 IDE 的启动 Java 运行时并从建议列表中选择它
- 选择新建:并选择最新的 21 版本,例如 21.0.2b375.1 JerBrains Runtime JBR 和 JCEF(默认捆绑)
- 单击确定并重新启动 IDE
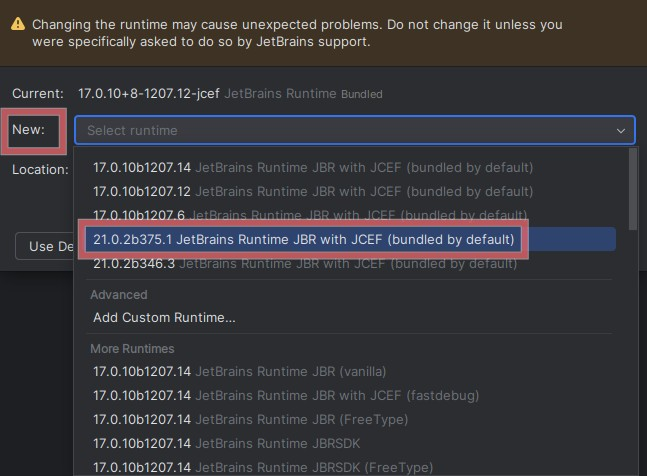
重新启动 IntelliJ 后,一切都应该正常。将提供程序添加到 Continue 看起来与在 VS Code/VS Codium 中完全相同,因此请返回该部分以获取更多信息。可以在汉堡菜单 → 文件 → 设置 → 工具(或按 Ctrl+Alt+S)中找到其他设置,您可以在其中启用代码自动完成。
要了解有关 Continue 及其众多功能的更多信息,请查看其主页和 YouTube。
8.3 CodeGPT
可以与 llama.cpp 服务器(但不是 Ollama)交互的第二个 IntelliJ 扩展是 CodeGPT (IntelliJ 市场)。它有一个聊天窗口和代码自动完成功能,但不能单独配置它们。这意味着你应该使用其中一个。不过,CodeGPT 可以与 Continue 同时使用。
我们可以通过在插件部分中提到的内置插件市场中搜索来安装 CodeGPT,但首先我们需要安装一个必需的库:
sudo apt install libsecret-1-0仅当你打开项目时才可以访问 CodeGPT,图标将显示在窗口右侧。可以在汉堡菜单 → 文件 → 设置 → 工具 → CodeGPT(按 Ctrl+Alt+S)中找到设置,也可以通过单击窗口右下角的插件图标来访问它们。
我们可以在那里添加提供程序(参见插件部分中的屏幕截图):
- 服务:LLaMA C/C++
- 启用代码完成:否,除非您想要此功能而不是聊天
- 使用远程服务器:是
- 基本主机:http://X.X.X.X:8080,或 http://X.X.X.X:8081(如果您启用了代码完成),X.X.X.X 是容器的 IP 地址
- 提示模板:Llama
- 填充模板:DeepSeek Coder(如果您启用了代码完成)
必须在 CodeGPT 侧栏中聊天提示上方的切换菜单中选择此新提供程序。
要了解有关 CodeGPT 及其众多功能的更多信息,请查看其主页和 YouTube。
8.4 Cody Ai
遗憾的是,IntelliJ 的 Cody Ai (IntelliJ 市场)不支持本地 Ollama 和 llama.cpp 服务器。目前此功能仅适用于 VS Code/VS Codium 版本。
原文链接:Ai tutorial: llama.cpp and Ollama servers + plugins for VS Code / VS Codium and IntelliJ
BimAnt翻译整理,转载请标明出处





