
NSDT工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器 - REVIT导出3D模型插件 - 3D模型语义搜索引擎 - AI模型在线查看 - Three.js虚拟轴心开发包 - 3D模型在线减面 - STL模型在线切割 - 3D道路快速建模
Code Llama 是 Llama 2 的一系列最先进的开放访问版本,专门用于代码任务,我们很高兴发布与 Hugging Face 生态系统的集成! Code Llama 已使用与 Llama 2 相同的宽松社区许可证发布,并且可用于商业用途。
今天,我们很高兴发布:
- Hub 上的模型及其模型卡和许可证
- Transformer集成
- 与文本生成推理集成,以实现快速高效的生产就绪推理
- 与推理端点集成
- 代码基准测试
代码大模型对软件工程师来说是一项令人兴奋的发展,因为他们可以通过 IDE 中的代码完成来提高生产力,处理重复或烦人的任务,例如编写文档字符串或创建单元测试。
1、什么是Code Llama?
Code Llama 版本引入了一系列包含 7、13 和 340 亿个参数的模型。 基础模型从 Llama 2 初始化,然后在 5000 亿个代码数据上进行训练。 Meta 对这些基本模型进行了两种不同风格的微调:Python 专家(1000 亿个额外令牌)和指令微调版本,可以理解自然语言指令。
这些模型在 Python、C++、Java、PHP、C#、TypeScript 和 Bash 中展示了最先进的性能。 7B 和 13B 基本和指令变体支持基于周围内容的填充,使它们非常适合用作代码助手。
Code Llama 在 16k 上下文窗口上进行训练。 此外,这三个模型变体还进行了额外的长上下文微调,使它们能够管理最多 100,000 个令牌的上下文窗口。
由于 RoPE 扩展的最新发展,将 Llama 2 的 4k 上下文窗口增加到 Code Llama 的 16k(可以推断到 100k)是可能的。 社区发现 Llama 的位置嵌入可以线性插值或在频域中插值,这可以通过微调轻松过渡到更大的上下文窗口。 在 Code Llama 的情况下,频域缩放是通过松弛完成的:微调长度是缩放的预训练长度的一小部分,从而使模型具有强大的外推能力。
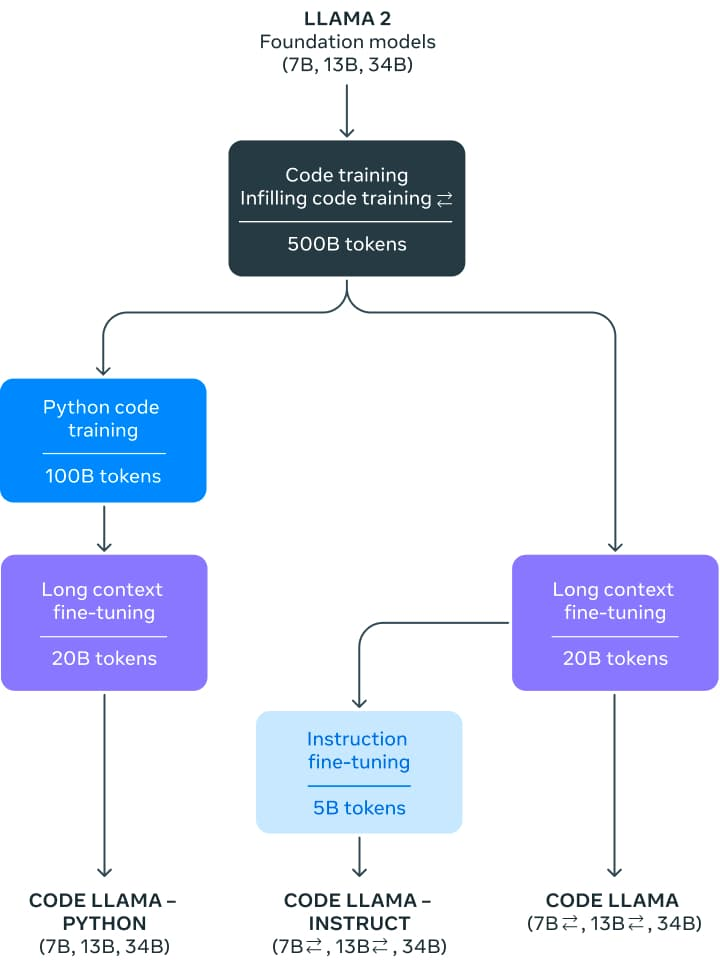
所有模型最初都是在公开可用代码的近乎重复数据删除的数据集上使用 5000 亿个令牌进行训练。 该数据集还包含一些自然语言数据集,例如有关代码和代码片段的讨论。 不幸的是,没有有关该数据集的更多信息。
对于指令模型,他们使用了两个数据集:为 Llama 2 Chat 收集的指令调整数据集和自指令数据集。 自指导数据集是通过使用 Llama 2 创建面试编程问题,然后使用 Code Llama 生成单元测试和解决方案,然后通过执行测试来评估的。
2、如何使用Code Llama?
从 Transformers 4.33 版本开始,Code Llama 已在 Hugging Face 生态系统中可用。 在 Transformers 4.33 发布之前,请从主分支安装它。
可以在此空间轻松尝试 Code Llama 模型(130 亿个参数!):
3、Transformers
随着即将发布的 Transformers 4.33,你可以使用 Code Llama 并利用 HF 生态系统中的所有工具,例如:
- 训练和推理脚本和示例
- 安全文件格式(safetensors)
- 与bitsandbytes(4位量化)和PEFT(参数高效微调)等工具集成
- 使用模型运行生成的实用程序和助手
- 导出模型以进行部署的机制
在 Transformers 4.33 发布之前,请从主分支安装它。
!pip install git+https://github.com/huggingface/transformers.git@main accelerate
4、代码完成
7B 和 13B 模型可用于文本/代码补全或填充。 以下代码片段使用管道接口来演示文本完成。 只要你选择 GPU 运行时,它就可以在 Colab 的免费层上运行。
from transformers import AutoTokenizer
import transformers
import torch
tokenizer = AutoTokenizer.from_pretrained("codellama/CodeLlama-7b-hf")
pipeline = transformers.pipeline(
"text-generation",
model="codellama/CodeLlama-7b-hf",
torch_dtype=torch.float16,
device_map="auto",
)
sequences = pipeline(
'def fibonacci(',
do_sample=True,
temperature=0.2,
top_p=0.9,
num_return_sequences=1,
eos_token_id=tokenizer.eos_token_id,
max_length=100,
)
for seq in sequences:
print(f"Result: {seq['generated_text']}")
这可能会产生如下输出:
Result: def fibonacci(n):
if n == 0:
return 0
elif n == 1:
return 1
else:
return fibonacci(n-1) + fibonacci(n-2)
def fibonacci_memo(n, memo={}):
if n == 0:
return 0
elif n == 1:
return
Code Llama 专门研究代码理解,但它本身就是一种语言模型。 你可以使用相同的生成策略来自动完成注释或一般文本。
5、代码填充
这是特定于代码模型的专门任务。 该模型经过训练,可以生成与现有前缀和后缀最匹配的代码(包括注释)。 这是代码助理通常使用的策略:要求他们填充当前光标位置,并考虑其前后出现的内容。
此任务在 7B 和 13B 型号的基本版本和指令版本中可用。 它不适用于任何 34B 型号或 Python 版本。
要成功使用此功能,你需要密切注意用于训练此任务模型的格式,因为它使用特殊的分隔符来识别提示的不同部分。 让我们看一个例子:
from transformers import AutoTokenizer, AutoModelForCausalLM
import transformers
import torch
model_id = "codellama/CodeLlama-7b-hf"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.float16
).to("cuda")
prefix = 'def remove_non_ascii(s: str) -> str:\n """ '
suffix = "\n return result\n"
prompt = f"<PRE> {prefix} <SUF>{suffix} <MID>"
inputs = tokenizer(prompt, return_tensors="pt").to("cuda")
output = model.generate(
inputs["input_ids"],
max_new_tokens=200,
do_sample=False,
)
output = output[0].to("cpu")
print(tokenizer.decode(output))
<s> <PRE> def remove_non_ascii(s: str) -> str:
""" <SUF>
return result
<MID>
Remove non-ASCII characters from a string.
:param s: The string to remove non-ASCII characters from.
:return: The string with non-ASCII characters removed.
"""
result = ""
for c in s:
if ord(c) < 128:
result += c <EOT></s>
为了使用补全功能,你需要处理输出以剪切 <MID> 和 <EOT> 标记之间的文本 - 这就是我们提供的前缀和后缀之间的内容。
6、对话指令
如上所述,基础模型可用于完成和填充。 Code Llama 版本还包括一个可在对话界面中使用的指令微调模型。
为了准备此任务的输入,我们必须使用一个提示模板,就像我们的 Llama 2 博客文章中描述的那样,我们在这里再次复制该模板:
<s>[INST] <<SYS>>
{{ system_prompt }}
<</SYS>>
{{ user_msg_1 }} [/INST] {{ model_answer_1 }} </s><s>[INST] {{ user_msg_2 }} [/INST]
请注意,系统提示是可选的 - 模型在没有它的情况下也可以工作,但可以使用它来进一步配置其行为或样式。 例如,如果你总是希望获得 JavaScript 中的答案,可以在此处声明。 系统提示后,你需要提供对话中之前的所有交互:用户询问什么以及模型回答什么。 与填充情况一样,需要注意使用的分隔符。 输入的最终组成部分必须始终是新的用户指令,这将是模型提供答案的信号。
以下代码片段演示了该模板在实践中的工作原理。
- 首次用户查询,系统无提示
user = 'In Bash, how do I list all text files in the current directory (excluding subdirectories) that have been modified in the last month?'
prompt = f"<s>[INST] {user.strip()} [/INST]"
inputs = tokenizer(prompt, return_tensors="pt", add_special_tokens=False).to("cuda")
- 系统提示的首次用户查询:
system = "Provide answers in JavaScript"
user = "Write a function that computes the set of sums of all contiguous sublists of a given list."
prompt = f"<s><<SYS>>\\n{system}\\n<</SYS>>\\n\\n{user}"
inputs = tokenizer(prompt, return_tensors="pt", add_special_tokens=False).to("cuda")
- 与先前答案的持续对话
该过程与 Llama 2 中的过程相同。为了最大程度地清晰起见,我们没有使用循环或概括此示例代码:
system = "System prompt"
user_1 = "user_prompt_1"
answer_1 = "answer_1"
user_2 = "user_prompt_2"
answer_2 = "answer_2"
user_3 = "user_prompt_3"
prompt = f"<<SYS>>\\n{system}\\n<</SYS>>\\n\\n{user_1}"
prompt = f"<s>[INST] {prompt.strip()} [/INST] {answer_1.strip()} </s>"
prompt += f"<s>[INST] {user_2.strip()} [/INST] {answer_2.strip()} </s>"
prompt += f"<s>[INST] {user_3.strip()} [/INST]"
inputs = tokenizer(prompt, return_tensors="pt", add_special_tokens=False).to("cuda")
7、4位加载
将 Code Llama 集成到 Transformers 中意味着你可以立即获得对 4 位加载等高级功能的支持。 这使你可以在 nvidia 3090 卡等消费类 GPU 上运行大型 32B 参数模型!
以下是在 4 位模式下运行推理的方法:
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig
import torch
model_id = "codellama/CodeLlama-34b-hf"
quantization_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_compute_dtype=torch.float16
)
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
quantization_config=quantization_config,
device_map="auto",
)
prompt = 'def remove_non_ascii(s: str) -> str:\n """ '
inputs = tokenizer(prompt, return_tensors="pt").to("cuda")
output = model.generate(
inputs["input_ids"],
max_new_tokens=200,
do_sample=True,
top_p=0.9,
temperature=0.1,
)
output = output[0].to("cpu")
print(tokenizer.decode(output))
8、使用文本生成推理和推理端点
文本生成推理是 Hugging Face 开发的生产就绪推理容器,可轻松部署大型语言模型。 它具有连续批处理、令牌流、用于在多个 GPU 上快速推理的张量并行性以及生产就绪的日志记录和跟踪等功能。
你可以在自己的基础设施上尝试文本生成推理,也可以使用 Hugging Face 的推理端点。 要部署 Code llama 2 模型,请转到模型页面并单击部署 -> 推理端点小部件。
- 对于 7B 模型,我们建议你选择“GPU [中] - 1x Nvidia A10G”。
- 对于 13B 模型,我们建议你选择“GPU [xlarge] - 1x Nvidia A100”。
- 对于 34B 模型,我们建议你选择启用了位和字节量化的“GPU [1xlarge] - 1x Nvidia A100”或“GPU [2xlarge] - 2x Nvidia A100”
注意:你可能需要通过电子邮件请求配额升级才能访问 A100
你可以在我们的博客中了解有关如何使用 Hugging Face Inference Endpoints 部署 LLM 的更多信息。 该博客包含有关支持的超参数以及如何使用 Python 和 Javascript 流式传输响应的信息。
9、评估
代码语言模型通常在 HumanEval 等数据集上进行基准测试。 它由编程挑战组成,其中模型带有函数签名和文档字符串,并负责完成函数体。 然后通过运行一组预定义的单元测试来验证所提出的解决方案。 最后,报告通过率,描述有多少解决方案通过了所有测试。 pass@1 率描述了模型在一次尝试时生成通过解决方案的频率,而 pass@10 描述了从 10 个提议的候选方案中至少有一个解决方案通过的频率。
虽然 HumanEval 是一个 Python 基准测试,但我们已经付出了巨大努力将其转换为更多编程语言,从而实现更全面的评估。 其中一种方法是 MultiPL-E,它将 HumanEval 翻译成十多种语言。 我们正在基于它托管一个多语言代码排行榜,以便社区可以比较不同语言的模型,以评估哪种模型最适合他们的用例。
| 模型 | 许可 | 数据集已知 | 商业用途? | 预训练长度 [tokens] | Python | JavaScript | 排行榜平均分数 |
|---|---|---|---|---|---|---|---|
| CodeLlaMa-34B | Llama 2许可证 | ❌ | ✅ | 2,500B | 45.11 | 41.66 | 33.89 |
| CodeLlaMa-13B | Llama 2许可证 | ❌ | ✅ | 2,500B | 35.07 | 38.26 | 28.35 |
| CodeLlaMa-7B | Llama 2许可证 | ❌ | ✅ | 2,500B | 29.98 | 31.8 | 24.36 |
| CodeLlaMa-34B-Python | Llama 2许可证 | ❌ | ✅ | 2,620B | 53.29 | 44.72 | 33.87 |
| CodeLlaMa-13B-Python | Llama 2许可证 | ❌ | ✅ | 2,620B | 42.89 | 40.66 | 28.67 |
| CodeLlaMa-7B-Python | Llama 2许可证 | ❌ | ✅ | 2,620B | 40.48 | 36.34 | 23.5 |
| CodeLlaMa-34B-Instruct | Llama 2许可证 | ❌ | ✅ | 2,620B | 50.79 | 45.85 | 35.09 |
| CodeLlaMa-13B-Instruct | Llama 2许可证 | ❌ | ✅ | 2,620B | 50.6 | 40.91 | 31.29 |
| CodeLlaMa-7B-Instruct | Llama 2许可证 | ❌ | ✅ | 2,620B | 45.65 | 33.11 | 26.45 |
| StarCoder-15B | BigCode-OpenRail-M | ✅ | ✅ | 1,035B | 33.57 | 30.79 | 22.74 |
| StarCoderBase-15B | BigCode-OpenRail-M | ✅ | ✅ | 1,000B | 30.35 | 31.7 | 22.4 |
| WizardCoder-15B | BigCode-OpenRail-M | ❌ | ✅ | 1,035B | 58.12 | 41.91 | 32.07 |
| OctoCoder-15B | BigCode-OpenRail-M | ✅ | ✅ | 1,000B | 45.3 | 32.8 | 24.01 |
| CodeGeeX-2-6B | CodeGeeX许可证 | ❌ | ❌ | 2,000B | 33.49 | 29.9 | 21.23 |
| CodeGen-2.5-7B-Mono | Apache-2.0 | ✅ | ✅ | 1400B | 45.65 | 23.22 | 12.1 |
| CodeGen-2.5-7B-Multi | Apache-2.0 | ✅ | ✅ | 1400B | 28.7 | 26.27 | 20.04 |
注意:上表中显示的分数来自我们的代码排行榜,我们在其中评估具有相同设置的所有模型。 更多详情请参阅排行榜。
BimAnt翻译整理,转载请标明出处





