
NSDT工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器 - REVIT导出3D模型插件 - 3D模型语义搜索引擎 - AI模型在线查看 - Three.js虚拟轴心开发包 - 3D模型在线减面 - STL模型在线切割 - 3D道路快速建模
ControlNet 是一种稳定扩散模型,可让你从参考图像中复制构图或人体姿势。
经验丰富的稳定扩散用户知道生成想要的确切成分有多难。图像有点随机。你所能做的就是玩数字游戏:生成大量图像并选择你喜欢的图片。
借助 ControlNet,稳定扩散用户终于有了一种精确控制拍摄对象位置和外观的方法!
在这篇文章中,我们将介绍有关ControlNet的所有信息。
1、什么是ControlNet?
ControlNet是用于控制稳定扩散模型的神经网络模型。你可以将 ControlNet 与任何稳定扩散模型一起使用。
使用稳定扩散模型的最基本形式是文本到图像。它使用文本提示作为条件来引导图像生成,以便生成与文本提示匹配的图像。
ControlNet 除了文本提示之外,还增加了一个条件。额外的调节可以在ControlNet中采取多种形式。
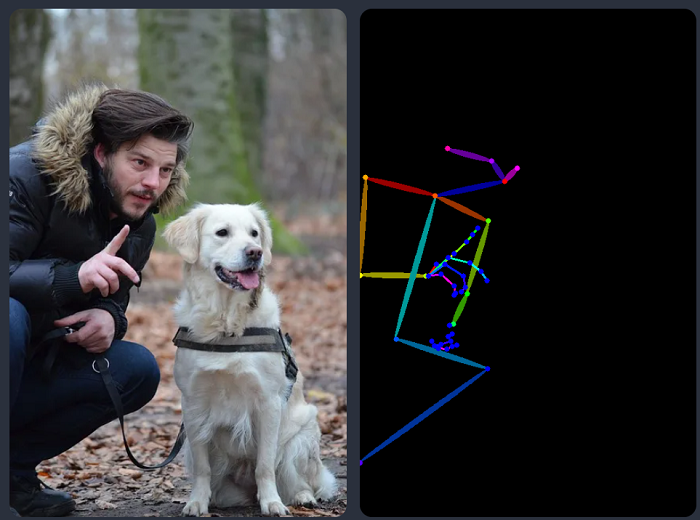
让我向你展示ControlNet可以执行的操作的两个示例:使用(1)边缘检测和(2)人体姿势检测来控制图像生成。
1.1 ControlNet边缘检测示例
如下图所示,ControlNet 获取额外的输入图像并使用 Canny 边缘检测器检测其轮廓。然后,包含检测到的边缘的图像将另存为控制图。它作为文本提示的额外条件馈送到 ControlNet 模型中。
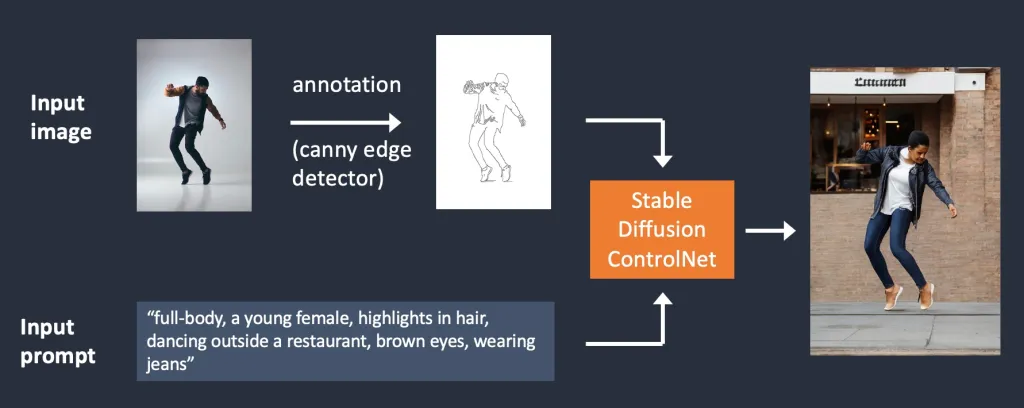
从输入图像中提取特定信息(在本例中为边缘)的过程称为注解(在这篇研究文章中)或预处理(在ControlNet扩展中)。
1.2 ControlNet人体姿势检测示例
边缘检测不是预处理图像的唯一方法。Openpose 是一种快速的人类关键点检测模型,可以提取人类姿势,如手、腿和头部的位置。请参阅下面的示例。

下面是使用 OpenPose 的 ControlNet 工作流程。使用OpenPose从输入图像中提取关键点,并将其保存为包含关键点位置的控制图。然后,它与文本提示一起作为额外的条件被馈送到稳定扩散。图像是基于这两个条件生成的。
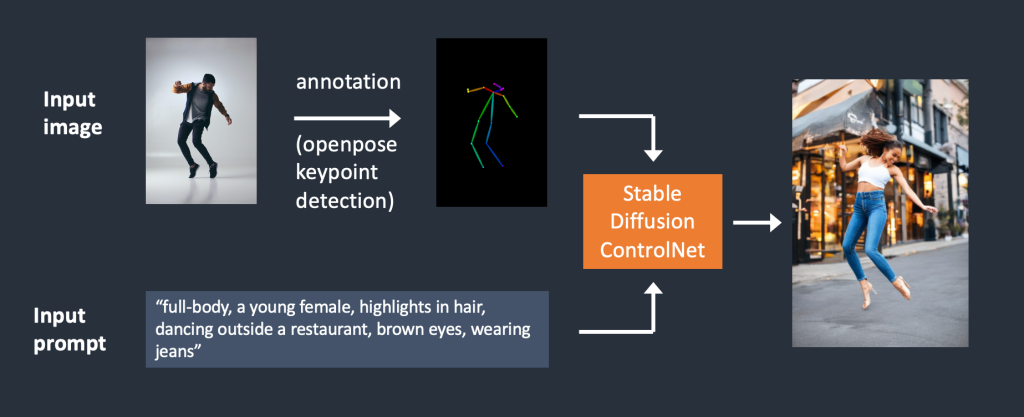
使用Canny边缘检测和Openpose有什么区别?Canny边缘检测器可以提取主体和背景的边缘。它倾向于更忠实地翻译场景。你可以看到跳舞的男人变成了女人,但轮廓和发型被保留了下来。
OpenPose仅检测人类的关键点,例如头部,手臂等的位置。图像生成更加自由,但遵循原始姿势。
上面的示例生成了一个女人跳起来,左脚指向侧面,与原始图像和 Canny Edge 示例中的图像不同。原因是OpenPose的关键点检测没有指定脚的方向。
2、安装稳定扩散ControlNet
让我们来看看如何在 AUTOMATIC1111 中安装 ControlNet,这是一款流行且功能齐全(且免费!稳定的扩散图形用户界面。我们将使用此扩展(事实上的标准)来使用 ControlNet。
如果你已经安装了 ControlNet,则可以跳到下一部分以了解如何使用它。
2.1 在Colab中安装ControlNet
在我们的快速入门指南中,将 ControlNet 与一键式稳定扩散 Colab 笔记本一起使用很容易。
在 Colab 笔记本的“扩展”部分中,选中“ControlNet”。

按Play按钮启动AUTOMATIC1111。就是这样!
2.2 安装 ControlNet 扩展 (Windows/Mac)
你也可以在 Windows PC 或 Mac 上将 ControlNet 与 AUTOMATIC1111 配合使用。按照这些文章中的说明安装 AUTOMATIC1111(如果尚未这样做)。
如果已经安装了 AUTOMATIC1111,请确保你的副本是最新的。
- 导航到“扩展”页面。
- 选择“从 URL 安装”选项卡。
- 将以下 URL 放在扩展的存储库字段的 URL 中:
https://github.com/Mikubill/sd-webui-controlnet- 单击安装按钮。
- 等待确认消息,说明扩展已安装。
- 重新启动AUTOMATIC1111。
- 访问ControlNet模型页面。
- 下载所有模型文件(文件名以 .pth 结尾)。如果不想全部下载,可以立即下载最常用的openpose和canny模型。
- 将模型文件放入 ControlNet 扩展的模型目录中:
stable-diffusion-webui\extensionssd-webui-controlnet\models- 重新启动AUTOMATIC1111 webui。
如果扩展成功安装,你将在 txt2img 选项卡中看到一个名为 ControlNet 的新可折叠部分。它应该在脚本下拉菜单的正上方。
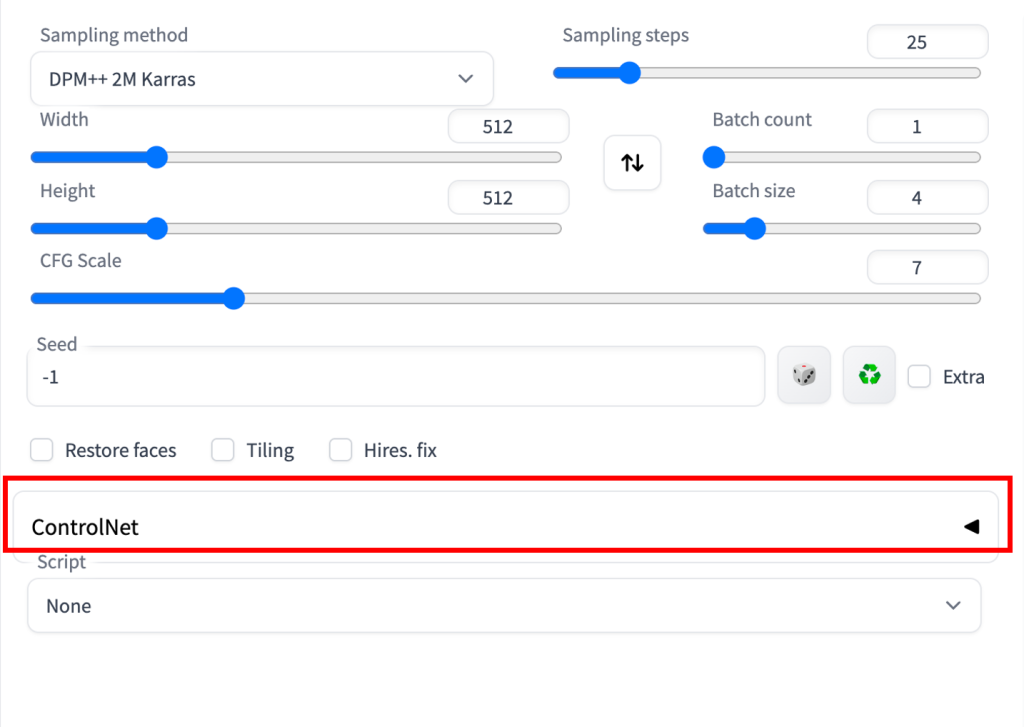
这表示扩展安装成功。
3、安装 T2I 适配器
T2I 适配器是神经网络模型,用于为扩散模型的图像生成提供额外的控制。它们在概念上类似于ControlNet,但设计不同。
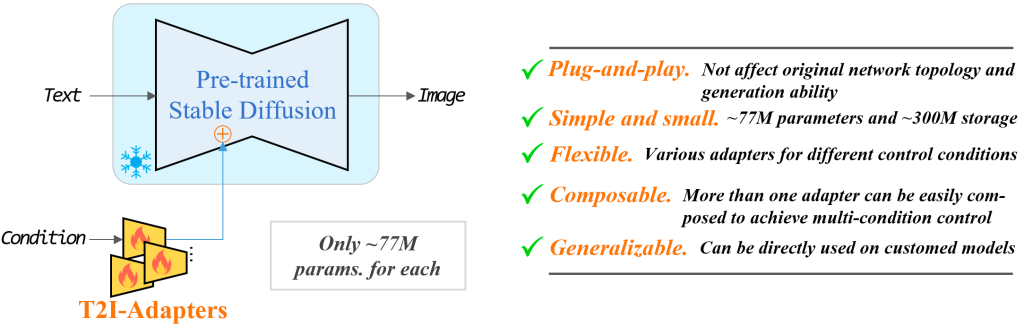
A1111 控制网扩展可以使用 T2I 适配器。你需要在此处下载模型。获取文件名读起来像 t2iadapter_XXXXX.pth 的那些
许多 T2I 适配器的功能与 ControlNet 型号重叠。我只介绍以下两个。
将它们放在 ControlNet 的模型文件夹中。
stable-diffusion-webui\extensions\sd-webui-controlnet\models4、更新 ControlNet 扩展
ControlNet是一个经历了快速发展的扩展。发现你的 ControlNet 副本已过时的情况并不少见。
仅当你在 Windows 或 Mac 上本地运行 AUTOMATIC1111 时,才需要更新。网站的Colab笔记本始终运行最新的ControlNet扩展。
要确定你的 ControlNet 版本是否为最新版本,请将 txt2img 页面上“ControlNet”部分中的版本号与最新版本号进行比较。
4.1 选项 1:从 Web UI 更新
更新 ControlNet 扩展的最简单方法是使用 AUTOMATIC1111 GUI。
- 转到“扩展”页面。
- 在“已安装”选项卡中,单击“检查更新”。
- 等待确认消息。
- 完全关闭并重新启动AUTOMATIC1111 Web UI。
4.2 选项 2:命令行
如果你熟悉命令行,则可以使用此选项更新 ControlNet,这样你就可以放心,Web-UI 不会执行其他操作。
步骤1:打开终端应用程序(Mac)或PowerShell应用程序(Windows)。
第 2 步:导航到 ControlNet 扩展的文件夹。(如果安装在其他地方,请相应地调整)
cd stable-diffusion-webui/extensions/sd-webui-controlnet步骤 3:通过运行以下命令更新扩展。
git pull5、使用 ControlNet的简单例子
现在你已经安装了 ControlNet,让我们通过一个简单的使用它的示例!稍后你将看到每个设置的详细说明。
你应该安装ControlNet扩展以跟上本节的内容。可以通过查看下面的控制网络部分进行验证。
按右侧的插入符号展开“ControlNet”面板。它显示了控制旋钮的完整部分和图像上传画布。
我将使用下图展示如何使用 ControlNet。你可以点击这里下载按钮下载图像以按照教程进行操作。

5.1 文本到图像设置
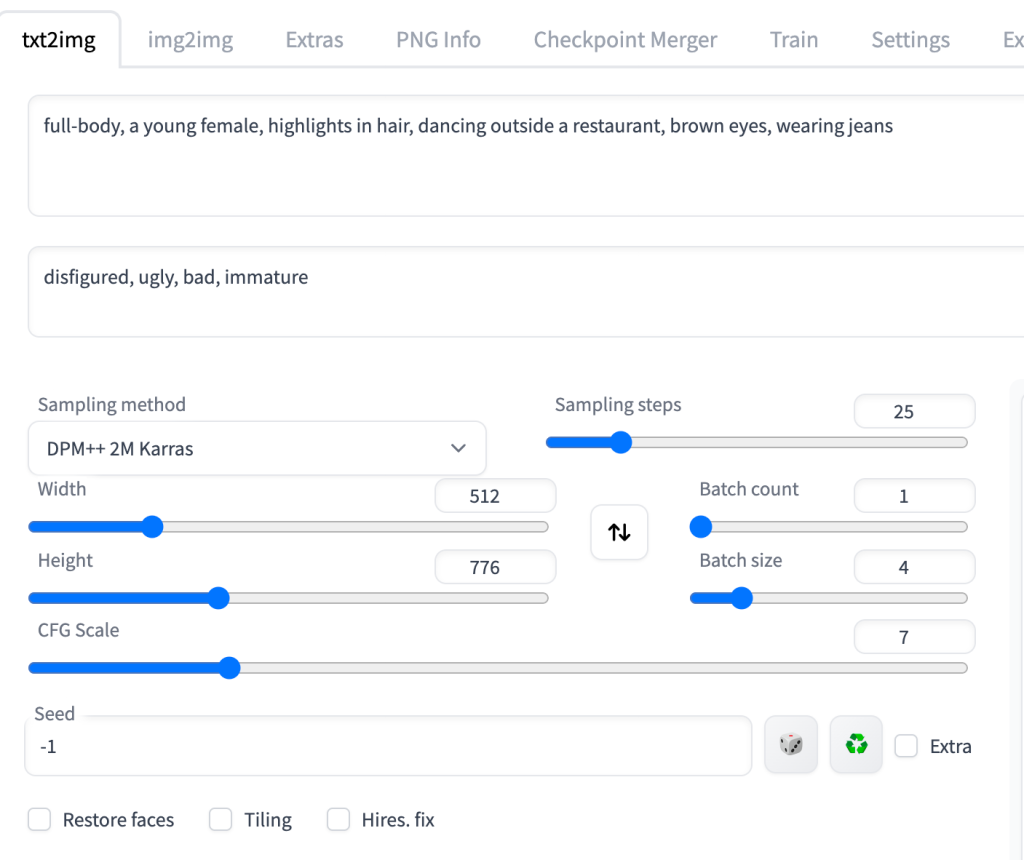
ControlNet需要与稳定扩散模型一起使用。在稳定扩散检查点下拉菜单中,选择要与 ControlNet 一起使用的模型。选择 v1-5-pruned-emaonly.ckpt 以使用 v1.5 基本模型。
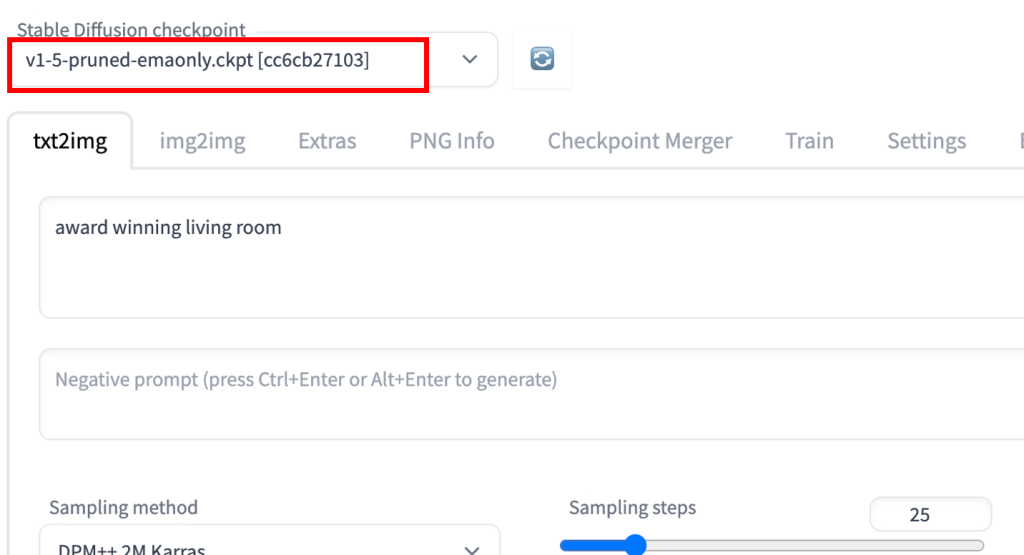
在 txt2image 选项卡中,编写提示和(可选)供 ControlNet 使用的否定提示。我将使用以下提示。
提示:
full-body, a young female, highlights in hair, dancing outside a restaurant, brown eyes, wearing jeans
负面提示:
disfigured, ugly, bad, immature
设置图像生成的图像大小。我将使用宽度 512 和高度 776 作为我的演示图像。请注意,图像大小是在 txt2img 部分中设置的,而不是在 ControlNet 部分中设置的。
GUI 应如下所示。
5.2 ControlNet设置
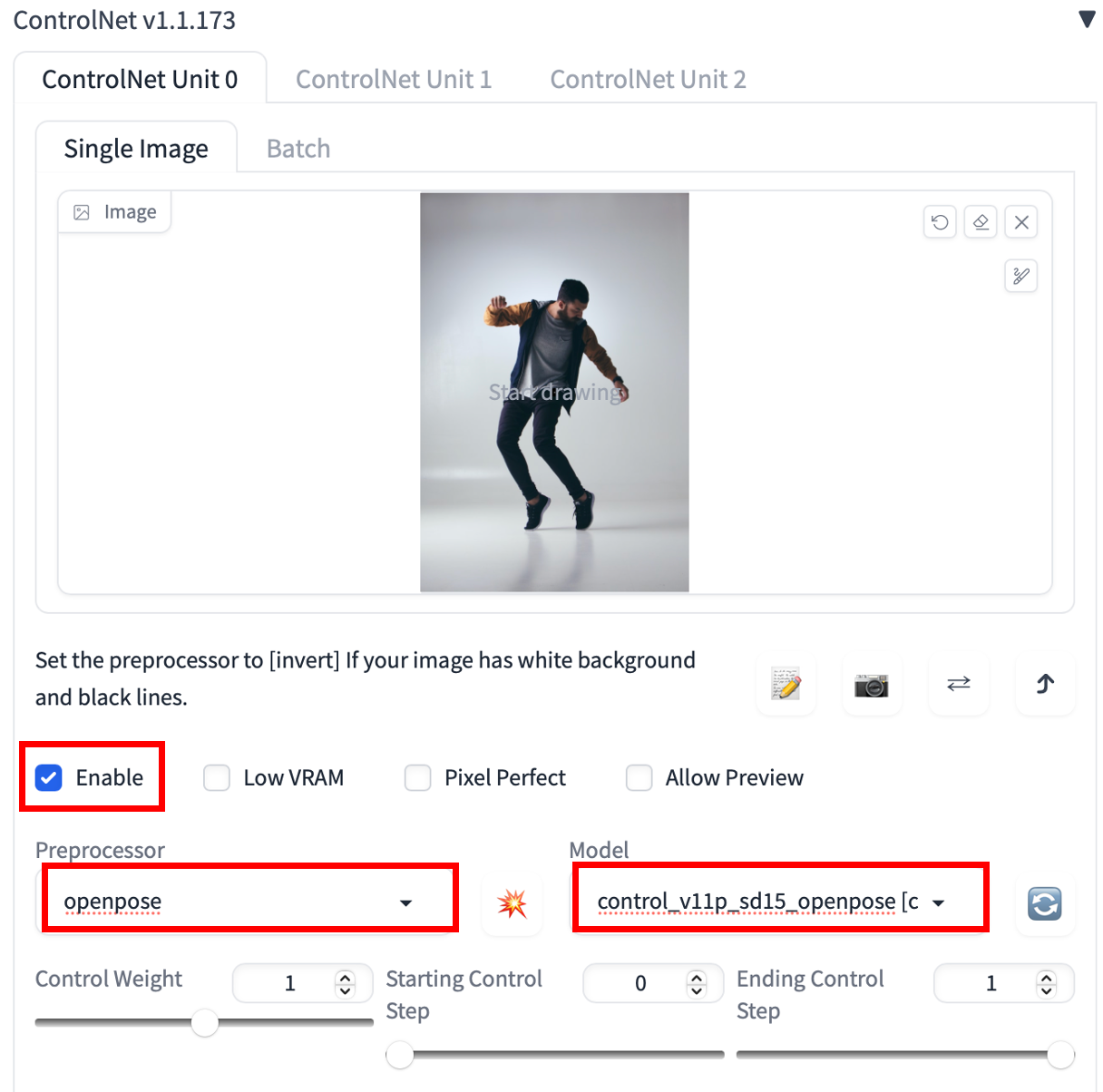
现在让我们转到“ControlNet”面板。
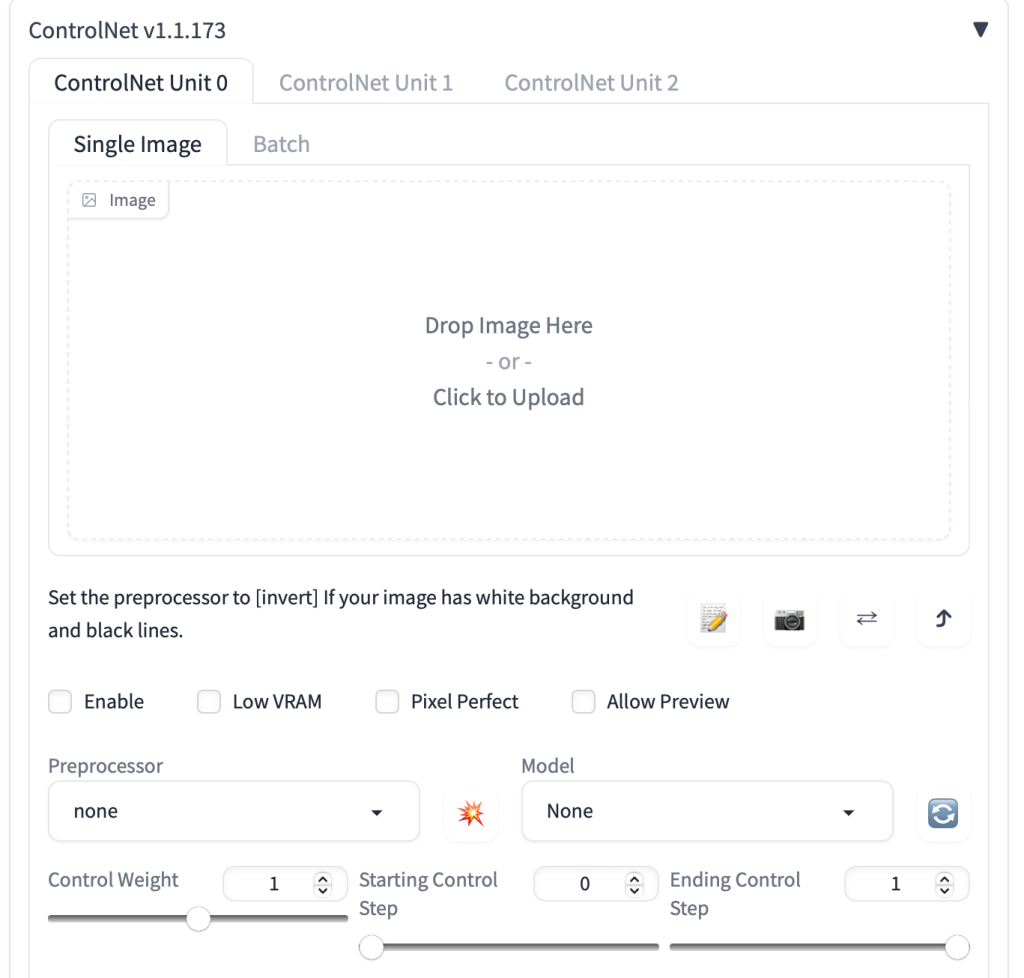
首先,将图像上传到图像画布。
选中启用复选框。
你需要选择预处理器和模型。预处理器只是前面提到的注释器的不同名称,例如 OpenPose 关键点检测器。让我们选择 openpose 作为预处理器。
选定的 ControlNet 模型必须与预处理器一致。对于OpenPose,应该选择control_openpose-fp16作为模型。
“ControlNet”面板应如下所示。
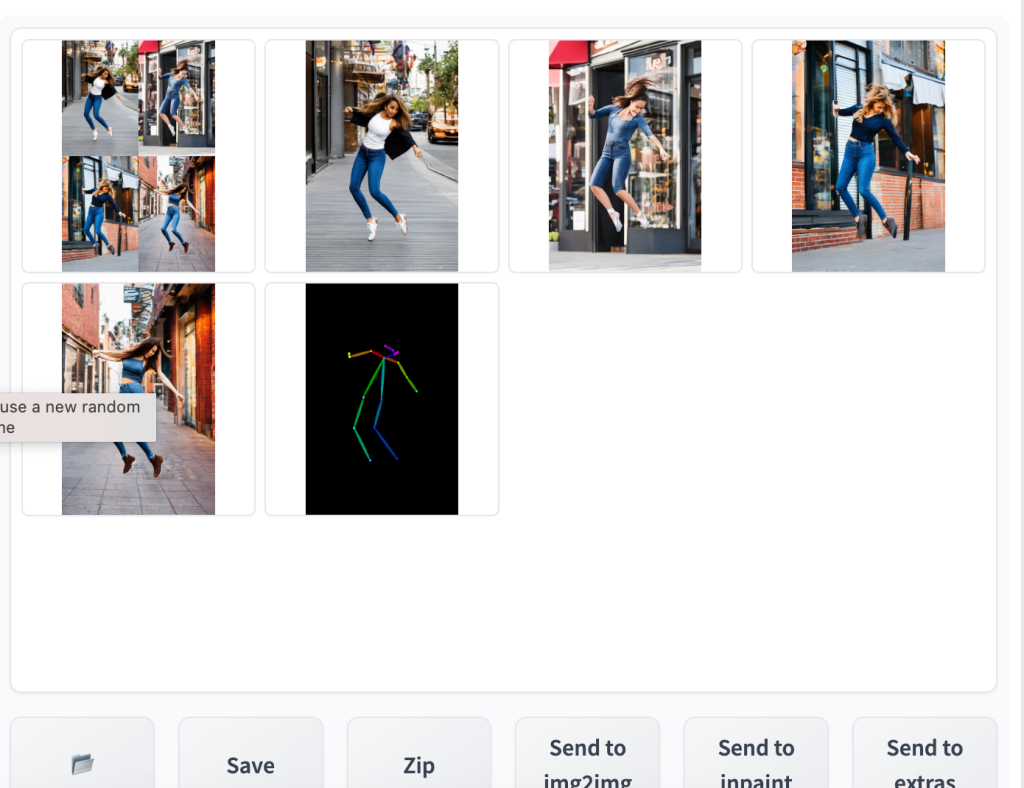
就这样。现在按生成开始使用控制网络生成图像。
你应该会看到生成的图像以遵循输入图像的姿势。最后一个图像直接来自预处理步骤。在这种情况下,它是检测到的关键点。
完成后,取消选中启用复选框以禁用 ControlNet 扩展。
这是使用ControlNet的基础知识!
剩下的就是要理解:
- 有哪些预处理器可用(有很多!)
- 控制网设置
6、预处理器和模型
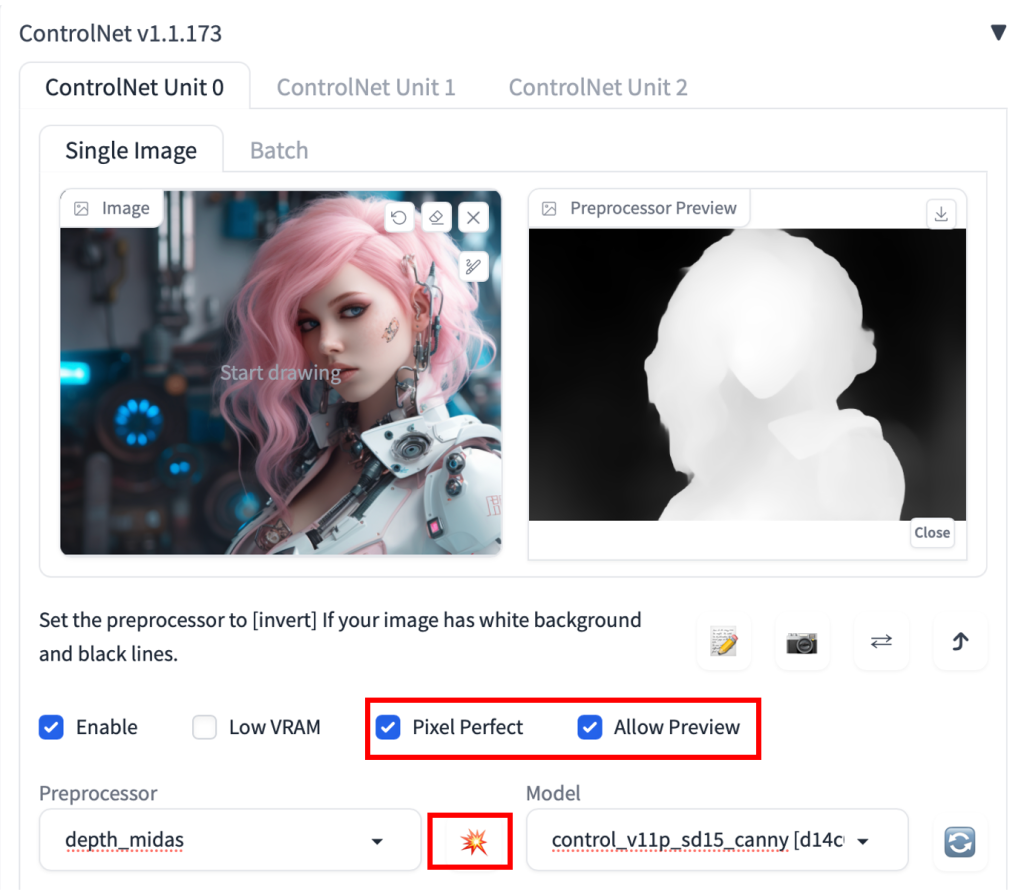
使用 ControlNet 的第一步是选择预处理器。打开预览很有帮助,以便你知道预处理器正在做什么。预处理完成后,原始图像将被丢弃,只有预处理后的图像将用于 ControlNet。
要打开预览:
- 选择允许预览。
- (可选)选择像素完美。ControlNet 将使用你在文本到图像中指定的图像高度和宽度来生成预处理的图像。
- 单击预处理器下拉菜单旁边的爆炸图标。
某些控制模型可能会对图像产生太大影响。如果看到颜色问题或其他伪影,请减小控制权重。
6.1 选择正确的模型
选择预处理器后,必须选择正确的模型。
很容易判断哪个模型是在 v1.1 中使用的正确模型。你需要做的就是选择与预处理器具有相同起始关键字的模型。
例如:
| 预处理器 | 模型 |
|---|---|
| depth_xxxx | control_xxxx_depth |
| lineart_xxxx | control_xxxx_lineart |
| openpose_xxxx | control_xxxx_openpose |
6.2 OpenPose预处理器
有多个 OpenPose 预处理器。
OpenPose检测人类的关键点,例如头部,肩膀,手的位置等。它可用于复制人类姿势而无需复制服装、发型和背景等其他细节。
所有 openpose 预处理器都需要与 ControlNet 的 Model 下拉菜单中的 openpose 模型一起使用。
OpenPose 预处理器包括:
- OpenPose:眼睛、鼻子、眼睛、颈部、肩膀、肘部、手腕、膝盖和脚踝。
- OpenPose_face:OpenPose+面部细节
- OpenPose_hand:OpenPose+手和手指
- OpenPose_faceonly:仅面部细节
- OpenPose_full:以上所有内容
- dw_openPose_full:OpenPose_full的增强版本
OpenPose是基本的OpenPose预处理器,可检测眼睛,鼻子,眼睛,颈部,肩部,肘部,手腕,膝盖和脚踝的位置。

OpenPose_face执行OpenPose处理器所做的一切,但会检测到其他面部细节。
它对于复制面部表情很有用。

OpenPose 人脸仅检测人脸,而不检测其他关键点。这对于仅复制人脸而不适用于其他关键点。

OpenPose_hand检测关键点为 OpenPose 以及手和手指。
OpenPose full检测所有openPose面部和openPose手所做的一切。

DWPose是一种基于研究文章两阶段蒸馏的有效全身姿势估计的新姿势检测算法。它完成了与OpenPose Full相同的任务,但做得更好。应该使用dw_openpose_full而不是openpose_full。
如果在预处理器菜单中看不到dw_openpose_full,请更新 ControlNet。

6.3 切片重采样
切片重采样(tile resample)模型用于向图像添加细节。它通常与升频器一起使用以同时放大图像。
6.4 引用预处理器
引用(reference)是一组新的预处理器,可用于生成与引用图像类似的图像。图像仍将受到稳定扩散模型和提示的影响。
引用预处理器不使用控制模型。你只需要选择预处理器,而不需要选择模型。实际上,选择参考预处理器后,模型下拉菜单将被隐藏。
有 3 个引用预处理器。
- reference adain:通过自适应实例规范化进行样式迁移。论文
- reference only:将引用图像直接链接到注意层。
- reference adain+attn:上述组合。
选择其中一个要使用的预处理器。
下面是一个示例。

使用 CLIP 询问器猜测提示。
a woman with pink hair and a robot suit on, with a sci – fi, Artgerm, cyberpunk style, cyberpunk art, retrofuturism
负向提示:
disfigured, ugly, bad, immature
模型:Protogen v2.2
Reference adain:

Reference only:

Reference adain + attn:

我会说,Reference only的效果最好。
以上图片均来自平衡模式。我认为改变样式保真度没有太大区别。
6.5 Canny边缘检测器
Canny的边缘检测器是一种通用的老式边缘检测器。它提取图像的轮廓。它对于保留原始图像的构图很有用。
在预处理器和模型下拉菜单中选择canny。

生成的图像将遵循轮廓。

6.6 深度预处理器
深度预处理器从参考图像中猜测深度信息。
- Depth Midas:经典的深度估算器。也用于官方 v2 图像深度模型。
- Depth:更多细节,但也倾向于渲染背景。
- Depth Leres++:更多细节。
- Zoe:细节水平介于迈达斯和莱雷斯之间。
参考图片:

深度图:

提示:
a woman retrofuturism
否定提示:
disfigured, ugly, bad, immature
可以看到生成的图像遵循深度图(Zoe)。

与更详细的 Leres++ 进行比较:

6.7 线条艺术
艺术线条(Line Art)渲染图像的轮廓。它尝试将其转换为简单的绘图。
有一些线条艺术预处理器。
- 线条艺术动漫:动漫风格的线条
- 线条艺术动漫降噪:细节较少的动漫风格线条。
- 线条艺术逼真:写实风格的线条。
- 线条艺术粗糙:具有较重重量的逼真风格的线条。
与艺术线条控制模型一起使用。
下面的图像是在控制权重设置为 0.7 的情况下生成的。
线条艺术动漫

线条艺术动漫降噪

线条艺术逼真:

线条艺术粗糙:

6.8 MLSD
M-LSD(移动线段检测)是一种直线检测器。它可用于提取具有直边的轮廓,如室内设计、建筑物、街景、相框和纸边。
曲线将被忽略。

6.9 法线贴图
法线贴图指定曲面的方向。对于 ControlNet,它是一个图像,用于指定每个像素所在的表面的方向。图像像素表示表面朝向的方向,而不是颜色值。
法线贴图的使用与深度贴图类似。它们用于传输参考图像的 3D 构图。
法线贴图预处理器:
- Normal Midas:根据迈达斯深度图估计法线贴图。
- Normal Bae:使用裴等人提出的正态不确定性方法估计法态图。
与迈达斯深度贴图一样,迈达斯法线贴图也非常适合将主体与背景隔离开来。

Bae 法线贴图倾向于在背景和前景中渲染细节。

6.10 涂鸦
涂鸦(Scribble)预处理器将图片变成涂鸦,就像手绘一样。
- Scribble HED:整体嵌套边缘检测 (HED) 是一种边缘检测器,擅长像真人一样生成轮廓。根据ControlNet的作者的说法,HED适用于重新着色和重新设计图像。
- Scribble Pidinet:像素差分网络(Pidinet)检测曲线和直边。它的结果类似于HED,但通常会导致线条更清晰,细节更少。
- Scribble xdog:高斯差异(XDoG)是一种边缘检测方法技术。调整 xDoG 阈值并观察预处理器输出非常重要。
所有这些预处理器都应与scribble控制模型一起使用。
Scribble HED产生粗略的涂鸦线。

Scribble Pidinet倾向于产生几乎没有细节的粗线条。它适用于复制没有精细细节的电路板轮廓。

通过调整 Scribble XDoG 阈值可以控制细节级别,使 xDoG 成为创建涂鸦的多功能预处理器。

6.11 分割预处理器
分割(segment)预处理器标记参考图像中的对象类型。
下面是一个正在运行的分割处理器。

建筑物、天空、树木、人物和人行道都标有不同的预定义颜色。
可以在这里的 ufade20k 和 ofade20k 的颜色图中找到对象类别和颜色。
有几个细分选项
- ufade20k:在ADE20K数据集上训练的UniFormer (uf)分割。
- ofade20k:在ADE20k数据集上训练的OneFormer (of)分割。
- ofcoco:在COCO数据集上训练的前者分割。
请注意,ADE20k和COCO分割的色彩图是不同的。
可以使用分割预处理器来传输对象的位置和形状。
下面使用这些预处理器具有相同的提示和种子。
Futuristic city, tree, buildings, cyberpunk
UniFormer ADE20k (ufade20k)在此示例中 准确标记所有内容。

OneFormer ADE20k (ofade20k)在这种情况下噪点更大一些,但不会影响最终图像。

OneFormer COCO (ofcoco)的表现类似,但有一些标签错误。

分割是一种强大的技术。你可以进一步操作分割贴图以将对象放置在精确位置。使用 ADE20k 的色彩图。
6.12 随机播放
随机播放(Shuffle)预处理器搅动输入图像。让我们看看实际效果。
与随机播放控制模型一起,随机播放预处理器可用于传输参考图像的配色方案。
输入图像:

随机播放预处理器:

与其他预处理器不同,随机预处理器是随机的。它将受到你的种子值的影响。
将随机预处理器与随机播放控制模型一起使用。随机控制模型可以与随机预处理器一起使用,也可以不使用随机播放预处理器。
下图是 ControlNet Shuffle 预处理器和 Shuffle 模型(与上一节的提示相同)。配色方案大致遵循参考图像。

下图仅包含 ControlNet Shuffle 模型(预处理器:无)。图像构图更接近原始图像。配色方案类似于洗牌。

下图具有相同的提示,没有 ControlNet。配色方案截然不同。

6.13 颜色栅格T2I 适配器
颜色栅格 T2i 适配器预处理器将参考图像缩小到 64 倍,然后将其扩展回原始大小。净效果是局部平均颜色的网格状斑块。
原始参考图像:

使用t2ia_color_grid进行预处理:
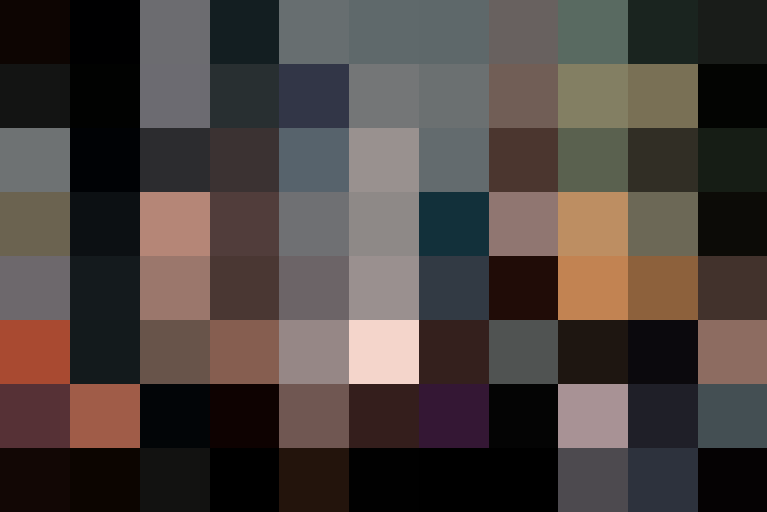
然后,可以将预处理的图像与 T2I 颜色适配器 (t2iadapter_color) 控制模型一起使用。
图像生成将在空间上松散地遵循配色方案。
A modern living room

增加 ControlNet 权重以使其更紧密地跟踪。
还可以对此 T2I 颜色模型使用预处理器 None 。
在我看来,它与图像到图像非常相似。
6.14 Clip vision style T2I 适配器
t2ia_style_clipvision将参考图像转换为 CLIP 视觉嵌入。此嵌入包含有关图像内容和样式的丰富信息。
你将需要使用控制模型t2iadapter_style_XXXX。
看看这个惊人的风格转换的效果:
参考图片:

T2I adapter – CLIP vision:
sci-fi girl

以下是关闭控制网时此提示将生成的内容。

该功能与参考控制网非常相似,但我认为T2IA CLIP Vision更强大。
6.15 ControlNet InPainting
ControlNet InPainting允许在Inpainting中使用高降噪强度来生成较大的变化,而不会牺牲与整个图像的一致性。
例如,我对现实的人使用了提示。
模型: HenmixReal v4
photo of young woman, highlight hair, sitting outside restaurant, wearing dress, rim lighting, studio lighting, looking at the camera, dslr, ultra quality, sharp focus, tack sharp, dof, film grain, Fujifilm XT3, crystal clear, 8K UHD, highly detailed glossy eyes, high detailed skin, skin pores
否定提示:
disfigured, ugly, bad, immature, cartoon, anime, 3d, painting, b&w
我有这个图像,想用InPainting来重新生成面部。

如果我用高去噪强度(> 0.4)在脸上涂漆,结果可能会在全局范围内不一致。以下是具有去噪强度1的未上色图像:

ControlNet Inpainting是解决方案。
要使用 ControlNet 修复,请执行以下操作:
1、最好使用生成图像的同一模型。在 txt2img 页面上生成图像后,单击“发送到 Inpaint”,将图像发送到 Img2img 页面上的 Inpaint 选项卡。
2、使用画笔工具在要再生的区域上创建蒙版。如果不熟悉,请参阅有关Inpainting的初学者教程。

3、将“上色区域”设置为“仅蒙版”。(整个图片也有效)
4、将降噪强度设置为 1。如果没有 ControlNet,你通常不会将其设置得这么高。
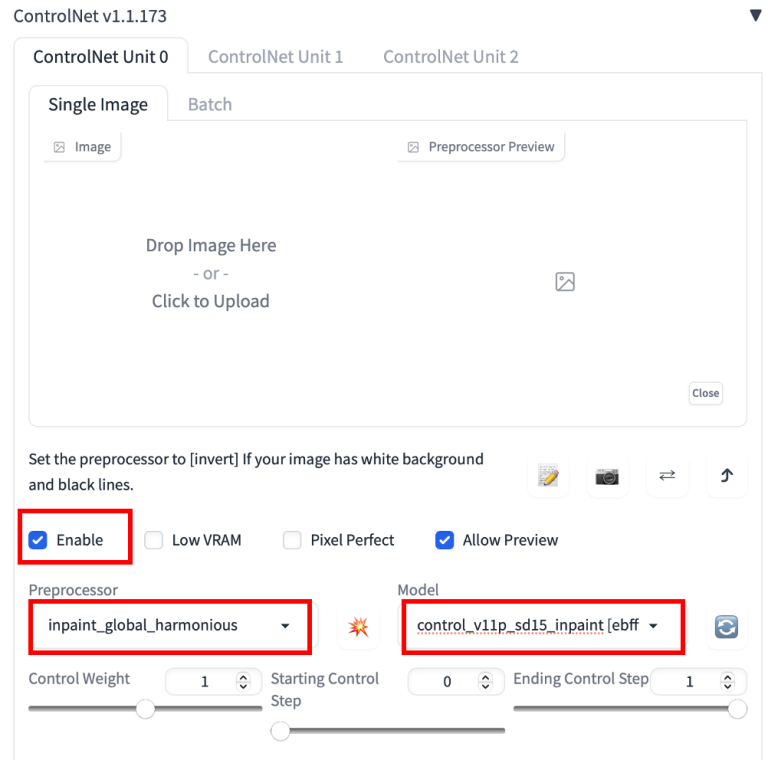
5、在“ControlNet”部分中设置以下参数。无需上传参考图片。
- 启用:是
- 预处理器:Inpaint_global_harmonious
- 模型: ControlNet
6、按生成开始修复。
现在,即使在最大降噪强度(1)下,我也能获得与全局形象一致的新面孔!

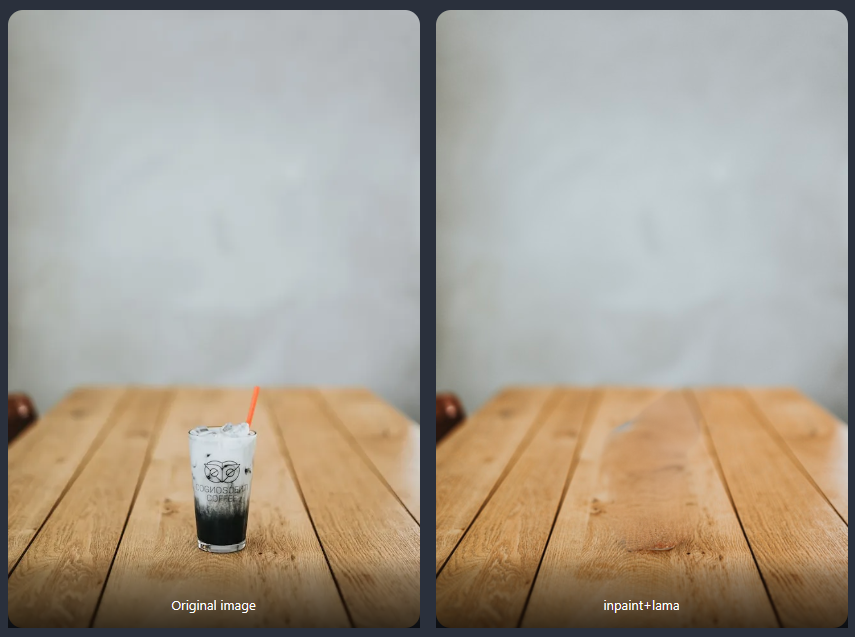
目前,有3个inpainting预处理器
- Inpaint_global_harmonious:提高全局一致性,并允许你使用高降噪强度。
- Inpaint_only:不会更改未遮罩的区域。它与 AUTOMATIC1111 中
- Inpaint_global_harmonious相同。
- Inpaint_only+lama:用lama模型处理图像。它往往会产生更干净的结果,并且有利于对象删除。
7、ControlNet设置完整说明
你在 ControlNet 扩展中看到了很多设置!当第一次使用它时,它可能有点吓人,但让我们一一介绍它们。
这将是一次深入的潜水。休息一下,如果需要的话去洗手间...
7.1 输入控制
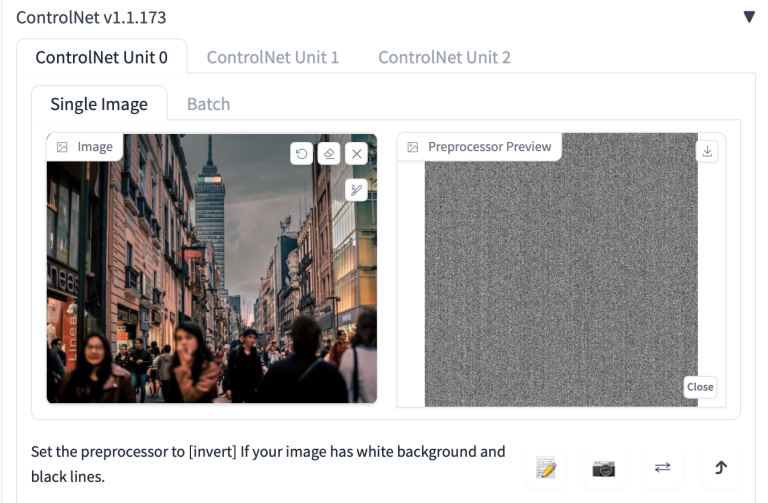
- 图像画布:你可以将输入图像拖放到此处。也可以单击画布并使用文件浏览器选择一个文件。输入图像将由预处理器下拉菜单中的选定预处理器进行处理。将创建一个控制图。
- 写入图标:使用白色图像创建新画布,而不是上传参考图像。它用于直接创建涂鸦。
- 相机图标:使用设备的相机拍照并将其用作输入图像。你需要向浏览器授予访问相机的权限。
7.2 模型选择

- 启用:是否启用 ControlNet。
- 低 VRAM:适用于 VRAM 小于 8GB 的 GPU。这是一个实验性功能。检查 GPU 内存是否不足,或者是否要增加处理的图像数量。
- 允许预览:选中此选项以启用参考图像旁边的预览窗口。我建议您选择此选项。使用预处理器下拉菜单旁边的分解图标预览预处理器的效果。
- 预处理器:预处理器(在研究文章中称为注释器),用于预处理输入图像,例如检测边缘、深度和法线贴图。均不使用输入图像作为控制图。
- 模型:要使用的控制网络模型。如果选择了预处理器,通常会选择相应的模型。ControlNet 模型与在 AUTOMATIC1111 GUI 顶部选择的稳定扩散模型一起使用。
7.3 控制权重
在预处理器和模型下拉菜单下方,你将看到三个滑动条,可用于控制效果:控制权重、开始和结束控制步骤。
我将使用以下图像来说明控制权重的效果。这是一个女孩坐下来的形象。

但是在提示中,我会要求生成一个站起来的女人。
full body, a young female, highlights in hair, standing outside restaurant, blue eyes, wearing a dress, side light
权重:相对于提示给予控件映射的强调程度。它类似于提示中的关键字权重,但适用于控件映射。
以下图像是使用 ControlNet OpenPose 预处理器和 OpenPose 模型生成的。

如你所见,Controlnet 权重控制相对于提示遵循的控制映射的程度。权重越低,ControlNet 对图像遵循控制图的要求就越少。
启动 ControlNet 步骤:首先应用步骤 ControlNet。0 表示第一步。
结束控制网步骤:步骤控制网结束。1 表示最后一步。
让我们修复固定为 0 的起始步骤,并更改结束 ControlNet 步骤以查看会发生什么。

由于初始步骤设置了全局组合(采样器在每个步骤中去除了最大数量的噪声,并且它从潜在空间中的随机张量开始),因此即使你仅将 ControlNet 应用于前采样步骤的 20%,也会设置姿势。
相反,更改结束 ControlNet 步骤的效果较小,因为全局组合是在开始步骤中设置的。
7.4 控制模式

- 平衡:控制网适用于采样步骤中的调节和非调节。这是标准操作模式。
- 我的提示更重要:ControlNet 的效果在 U-Net 注入实例中逐渐降低(一个采样步骤中有 13 个)。最终效果是你的提示比控制网络具有更大的影响力。
- ControlNet 更重要:在解除调节时关闭 ControlNet。实际上,CFG量表还可以作为控制网效果的乘数。
如果你不完全了解它们的实际工作原理,请不要担心。选项标签准确说明效果。
7.5 调整大小模式

调整大小模式控制当输入图像或控制图的大小与要生成的图像的大小不同时要执行的操作。如果这些选项具有相同的纵横比,则无需担心它们。
我将通过设置文本到图像来生成横向图像来演示调整大小模式的效果,而输入图像/控制地图是纵向图像。
- 只需调整大小:独立缩放控件映射的宽度和高度以适合图像画布。这将更改控件映射的纵横比。
女孩现在需要向前倾,这样她才能仍然在画布内。你可以使用此模式创建一些有趣的效果。

- 裁剪和调整大小:使图像画布适合控制图。裁剪控件映射,使其与画布大小相同。
因为控制地图在顶部和底部被裁剪,所以我们的女孩也是如此。

- 调整大小和填充:使整个控件映射适合图像画布。使用空值扩展控件映射,使其与图像画布的大小相同。
与原始输入图像相比,侧面有更多的空间。

现在(希望)你知道所有设置。让我们探讨一些使用 ControlNet 的想法。
8、 多个ControlNet
你可以多次使用 ControlNet 来生成图像。让我们来看一个例子。
模型: Protogen v2.2
提示:
An astronaut sitting, alien planet
否定提示:
disfigured, deformed, ugly
此提示会生成具有各种构图的图像。

假设我想独立控制宇航员和背景的构图。为此,我们可以使用多个(在本例中为 2 个)控制网。
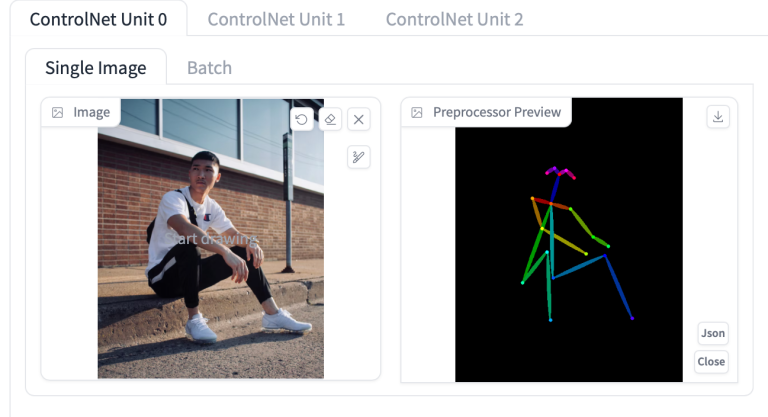
我将使用此参考图像来固定宇航员的姿势。

ControlNet 0 的设置:
- 启用:是
- 预处理器:OpenPose
- 模型: control_xxxx_openpose
- 调整大小模式:调整大小和重新填充(因为我的原始参考图像是纵向的)
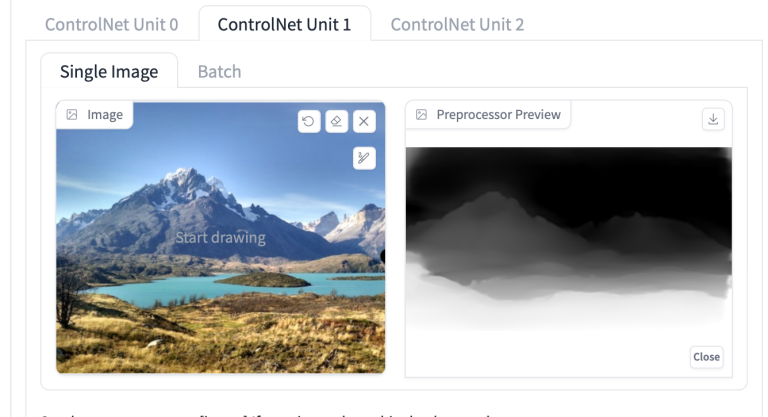
我将使用以下参考图像作为背景。

深度模型非常适合此目的。
ControlNet 1 的設定:
- 启用:是
- 控制权重:0.45
- 预处理器:depth_zeo
- 模型: control_XXXX_depth
- 调整大小模式:裁剪和调整大小
现在我可以独立控制主体和背景的构图:

技巧:
- 调整 ControlNet 权重,如果其中一个没有完成其工作。
- 如果有最终图像不同大小的参考图像,请注意调整大小模式。
9、模仿人体姿势
也许ControlNet最常见的应用是复制人类的姿势。这是因为通常很难控制姿势...直到现在!输入图像可以是稳定扩散生成的图像,也可以是从真实相机拍摄的图像。
要使用 ControlNet 传输人体姿势,请按照说明在 AUTOMATIC1111 中启用 ControlNet。使用以下设置。
- 预处理器:openpose
- 模型: control_...._openpose
- 确保已选中启用。
以下是一些示例。
9.1 示例 1:从图像复制姿势
作为基本示例,让我们复制以下欣赏树叶的女人图像的姿势。

使用各种模型和提示,你可以显著地更改内容,但保持姿势。

9.2 示例 2:重新混合影片场景
你可以将Pulp Fiction中的标志性舞蹈场景重新塑造为公园中的一些瑜伽练习。

这使用带有DreamShaper模型的ControlNet。

这是相同的提示,但使用墨水朋克扩散模型。你需要在提示中添加激活关键字 nvinkpunk:

10、使用 ControlNet 对图像进行风格化处理
下面是v1.5模型,但各种提示实现不同的风格。使用了具有各种预处理的ControlNet。最好进行实验,看看哪一个效果最好。

你还可以使用模型对图像进行样式化。下面是使用提示“贝多芬的绘画”与Anythingv3,DreamShaper和OpenJourney模型生成的。

11、使用魔术姿势控制姿势
有时,你可能无法找到具有所需确切姿势的图像。可以使用魔术姿势等软件工具创建自定义姿势。
第 1 步:转到魔术姿势网站。

第2步:移动模型的关键点以自定义姿势。
第 3 步:按预览。截取模型的屏幕截图。应该得到如下所示的图像。

第 4 步:使用 OpenPose ControlNet 模型。选择你选择的模型和提示以生成图像。
以下是使用1.5模型和DreamShaper模型生成的一些图像。在所有情况下,姿势都复制得很好。

12、室内设计思路
可以使用稳定扩散控制网的直线探测器MLSD模型来生成室内设计思路。以下是ControlNet设置。
- 预处理器:mlsd
- 模型: MLSD
从任何室内设计照片开始。让我们以下面的一个为例。

提示:
award winning living room
模型:Stable Diffusion v1.5
以下是一些产生的设计思路。

或者,你可以使用深度模型。它将强调保留深度信息,而不是直线。
- 预处理器:Depth Midas
- 模型:Depth
生成的图像:

13、稳定扩散深度模型与ControlNet的区别
稳定扩散的创建者Stability AI发布了一个深度图像模型。它与ControlNet有很多相似之处,但存在重要差异。
让我们先谈谈相似之处。
- 它们都是稳定扩散模型...
- 它们都使用两种条件(预处理的图像和文本提示)。
- 他们都使用MiDAS来估计深度图。
区别在于:
- 图像深度模型是 v2 模型。ControlNet 可用于任何 v1 或 v2 模型。这一点很重要,因为 v2 模型是出了名的难以使用。人们很难产生好的形象。ControlNet 可以使用任何 v1 模型的事实不仅为 v1.5 基础模型开放了深度调节,而且还为社区发布的数千种特殊模型开放了条件反射。
- ControlNet更加通用。除了深度之外,它还可以通过边缘检测、姿势检测等进行调节。
- ControlNet的深度图具有比图像深度更高的分辨率。
14、ControlNet如何工作?
如果不解释 ControlNet 在后台的工作原理,本教程将是不完整的。
ControlNet 的工作原理是将可训练的网络模块附加到稳定扩散模型的 U-Net(噪声预测器)的各个部分。稳定扩散模型的权重被锁定,以便在训练期间保持不变。在训练期间仅修改附加的模块。
研究论文中的模型图很好地总结了这一点。最初,附加网络模块的权重全部为零,使新模型能够利用经过训练和锁定的模型。
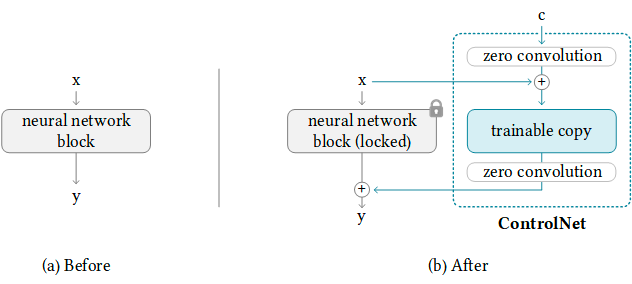
在训练期间,每个训练图像一起提供两个条件:(1) 文本提示,以及 (2) 控制映射,例如 OpenPose 关键点或 Canny 边缘。ControlNet 模型学习基于这两个输入生成图像。
每个控制方法都是独立训练的。
原文链接:ControlNet v1.1: A complete guide
BimAnt翻译整理,转载请标明出处






{kind=link}