
NSDT工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器 - REVIT导出3D模型插件 - 3D模型语义搜索引擎 - AI模型在线查看 - Three.js虚拟轴心开发包 - 3D模型在线减面 - STL模型在线切割 - 3D道路快速建模
“在古老的迪萨罗斯大陆,曾经住着一位传奇人物,名叫索拉(Sora)。这个传奇人物体现了无限潜力的本质,包括天空的浩瀚和壮丽。
当它飞得很高,彩虹色的翅膀横跨广阔的空间,光线从它引人注目的身体上反射出来时,人们可以听到“索拉就是天空”这句话在天空中回荡。它之所以成为传奇,不仅是因为它史诗般的巨大,还因为它能够驾驭散落在旋转云层中的光元素。凭借其强大的力量,索拉只需旋转一下就能创造出神奇的魔法,令人叹为观止!
他们说,Sora活着,日复一日地磨练技能,变得越来越强大,准备在黄金时刻飞翔。当你今天看到天空中一抹深红色时,你就会知道这是传说中的一粒飞向光之领域的小精灵!”
这是我给儿子讲的一个故事,讲的是一条生活在遥远国度的神话中的龙。我们把它叫做“索拉传说”。他非常喜欢这个故事,因为Sora又大又强壮,照亮了天空。当然,现在他还不懂变形金刚和扩散的概念,他只有四岁,但他确实理解一条使用光的力量统治着 DiTharos 的宽宏大量的龙的概念。

1、Open AI 的 Sora
这个故事与我们世界的 Sora 非常相似,Open AI 的文本转视频模型在人工智能领域出现并风靡全球。原则上,Sora 是由 William Peebles 和 Saining Xie 于 2023 年开发的Diffusion Transformer (DiT)。
换句话说,它使用扩散的思想来预测视频,并使用Transformer的强度进行下一级扩展。为了进一步理解这一点,让我们尝试找到这两个问题的答案:
- 当给出提示时,Sora 会做什么?
- 它如何结合扩散和transformer的思想?
说到 Sora 制作的视频,这是我最喜欢的一个,意大利街头有一只可爱的斑点狗。它的动作多么自然!

视频使用的提示:“摄像机直接面对意大利布拉诺色彩缤纷的建筑物。一只可爱的斑点狗透过一楼建筑物的窗户往外看。许多人沿着建筑物前的运河街道散步和骑自行车。”
Sora 是如何做到这一点的?
事不宜迟,让我们深入了解细节,看看 Sora 如何根据文本提示制作这些超逼真的视频。
2、Sora 是如何工作的?
再次感谢 Tom Yeh 教授的精彩 AI by Hand 系列,我们有这篇关于 Sora 的精彩文章供我们讨论。(以下所有图片,除非另有说明,均由 Tom Yeh 教授从上述 LinkedIn 帖子中提供,我已征得他的许可对其进行了编辑。)
那么,我们开始吧:
我们的目标 — 根据文本提示生成视频。
我们得到:
- 训练视频
- 文本提示
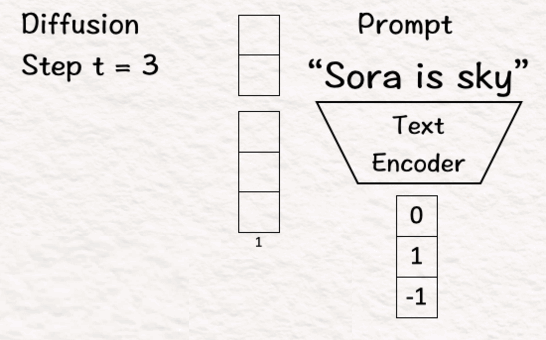
- 扩散步骤 t = 3
对于我们的例子,你能猜出我们的文本提示是什么吗?你说得对。它是“Sora 是天空”。扩散步骤 t = 3 表示我们正在添加噪声或分三步扩散模型,但为了说明起见,我们将在此示例中坚持使用一步。
什么是扩散?
扩散主要指粒子散射的现象——想想我们如何享受从云层后面窥视的柔和阳光。这种柔和的光芒可以归因于阳光穿过云层时的散射,导致光线向不同方向扩散。
粒子的随机运动驱动了这种扩散。这正是图像生成中使用的扩散模型所发生的事情。图像中添加了随机噪声,导致图像中的元素偏离原始图像,从而为创建更精致的图像让路。
当我们谈论图像模型的扩散时,要记住的关键思想是“噪声”。
过程从这里开始:
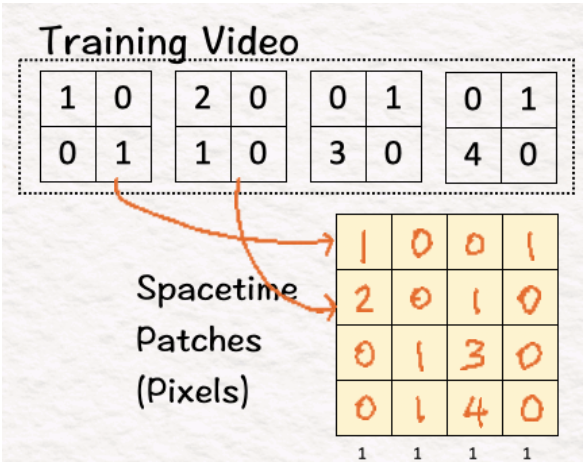
[1] 将视频转换为补丁
在进行文本生成时,模型将大型语料库分解成称为标记(token)的小块,并使用这些标记进行所有计算。同样,Sora 将视频分解成称为视觉补丁(visual patches)的较小元素,以简化工作。
因为我们在谈论视频,所以我们在谈论多帧中的图像。在我们的示例中,我们有四个帧。四个帧或矩阵中的每一个都包含创建图像的像素。
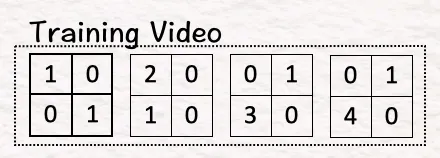
第一步是将该训练视频转换为如下所示的 4 个时空补丁:
[2] 降低这些视觉块的维度:编码器
接下来,降维。降维的思想已经存在了一个多世纪(琐事:主成分分析,也称为 PCA,由卡尔·皮尔逊于 1901 年提出),但其重要性并没有随着时间的推移而消退。
Sora 也使用它!
当我们谈论神经网络时,降维的基本思想之一是编码器。编码器的设计通过专注于捕获数据中最相关的特征,将高维数据转换为低维数据。双方共赢:它提高了计算的效率和速度,同时算法获得了有用的数据。
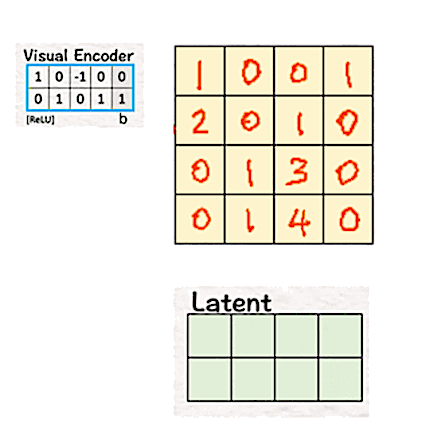
Sora 使用相同的思想将高维像素转换为低维潜在空间。为此,我们将块与权重和偏差相乘,然后使用 ReLU。
注意:
线性变换:输入嵌入向量乘以权重矩阵 W,然后加上偏差向量 b,
z = Wx+b,其中 W 是权重矩阵,x 是我们的词嵌入,b 是偏差向量。
ReLU 激活函数:接下来,我们将 ReLU 应用于这个中间 z。
ReLU 返回输入的元素最大值和零。从数学上讲,h = max{0,z}。
- 这里的权重矩阵是一个 2x4 矩阵 [ [1, 0, -1, 0], [0, 1, 0, 1] ],偏差为 [0,1]。
- 这里的补丁矩阵是 4x4。
权重矩阵 W 的转置和偏差 b 与补丁的乘积,然后是 ReLU,为我们提供了一个潜在空间,它只是一个 2x4 矩阵。因此,通过使用视觉编码器,“模型”的维度从 4(2x2x1)减少到 2(2x1)。
在原始 DiT 论文中,这一缩减从 196,608(256x256x3)减少到 4096(32x32x4),这是一个巨大的缩减。想象一下,使用 196,608 个像素与使用 4096 个像素相比,缩减了 48 倍!
紧接着这一缩减,我们进入了整个过程中最重要的步骤之一 — 扩散。
[3] 用噪声扩散模型
为了引入扩散,我们在上一步中获得的潜在特征中添加采样噪声,以找到噪声潜在特征。这里的目标是让模型检测噪声是什么。
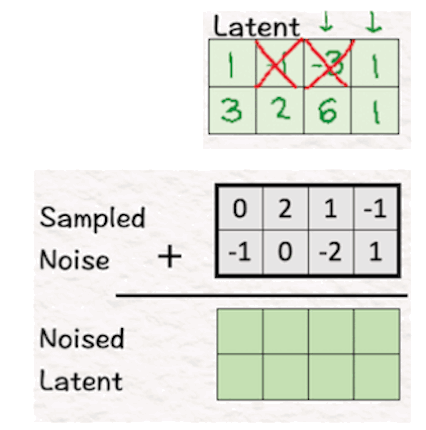
这本质上是图像生成扩散的理念。
通过向图像添加噪声,要求模型猜测噪声是什么以及它是什么样子。作为回报,模型可以根据它从噪声图像中猜测和学习到的内容生成一个全新的图像。
它也可以被视为从语言模型中删除一个单词并要求它猜测删除的单词是什么。
现在训练视频已经减少并扩散了噪声,下一步是利用文本提示来获得提示所倡导的视频。我们通过使用自适应规范层进行调节来实现这一点。
[4]-[6] 通过自适应规范层进行调节
“调节”(conditioning)本质上意味着我们尝试使用我们可用的附加信息来影响模型的行为。例如:由于我们的提示是“Sora 是天空”,我们希望模型专注于天空或云等元素,而不是重视帽子或植物等其他概念。因此,自适应规范层,用更好的术语来说,就是根据收到的输入动态地缩放和移动网络中的数据。
什么是缩放和移位?
缩放发生在我们乘法时,例如,我们可以从变量 A 开始。假设当我们将其乘以 2 时,我们得到 2*A,这将 A 的值放大或缩放 2。如果我们将其乘以 ½,则该值将缩小 0.5。
移位用加法表示,例如,我们可能在数字线上行走。我们从 1 开始,然后被要求移位到 5。我们怎么做?我们可以加 4 得到 1+4=5,也可以加一百个 0.4 得到 5,1+(100*0.04 )= 5。这完全取决于我们是想采取更大的步骤(4)还是更小的步骤(0.04)来实现我们的目标。
[4] 编码条件
为了利用条件(在我们的例子中是用于构建模型的信息),首先我们将其转换为模型可以理解的形式,即向量。
- 该过程的第一步是将提示转换为文本嵌入向量。
- 下一步是将步骤 t = 3 转换为二进制向量。
- 第三步是将这些向量连接在一起。
[5] 估计尺度/偏移
请记住,我们在这里使用“自适应”层规范,这意味着它根据模型的当前条件调整其值。因此,为了捕捉数据的正确本质,我们需要在数据中包含每个元素的重要性。这是通过估计尺度和偏移来完成的。
为了为我们的模型估计这些值,我们将提示和扩散步骤的连接向量与权重相乘,并将偏差添加到其中。这些权重和偏差是模型学习和更新的可学习参数。
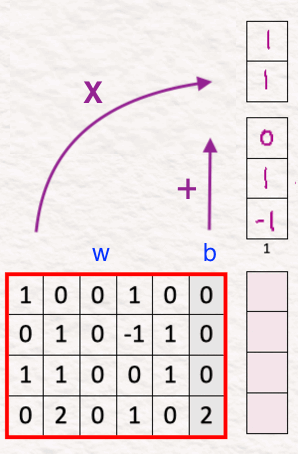
备注:在我看来,结果向量中的第三个元素应该是 1。这可能是原始帖子中的一个小错误,但作为人类,我们可以犯一点错误,不是吗?为了保持一致性,我继续使用原始帖子中的值。
这里的目标是估计比例 [2,-1] 和移位 [-1,5](因为我们的模型大小是 2,所以我们有两个比例和两个移位参数)。我们分别将它们保持在“X”和“+”下。
[6] 应用缩放/移位
为了应用上一步中获得的缩放和移位,我们将步骤 3 中的噪声潜在值乘以 [2, -1],并通过添加 [-1,5] 进行移位。
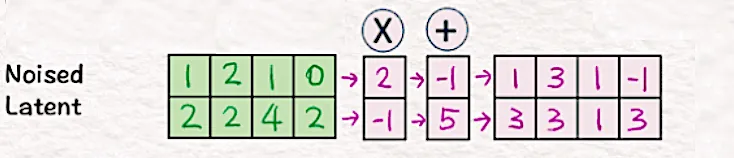
结果就是“条件”噪声潜伏。
[7]-[9] Transformer
最后三个步骤包括将 Transformer 元素添加到上述扩散和条件步骤中。此步骤帮助我们找到模型预测的噪声。
[7] 自我注意
这是 Transformer 背后的关键思想,使它们如此非凡!
什么是自我注意?
它是一种机制,通过该机制,句子中的每个单词都会分析其他每个单词并衡量它们对彼此的重要性,从而理解文本中的上下文和关系。
为了启用自我注意,将条件噪声潜伏输入到 Query-Key 函数中以获得自我注意矩阵。为简单起见,这里省略了 QK 值。
[8] 注意力池
接下来,我们将条件噪声潜伏与自我注意矩阵相乘以获得注意力加权特征。
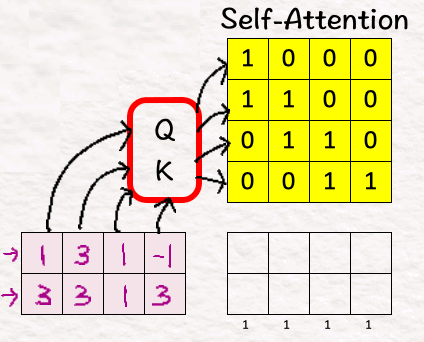
[9] 逐点前馈网络
再次回到基础,我们将注意力加权特征与权重和偏差相乘以获得预测噪声。
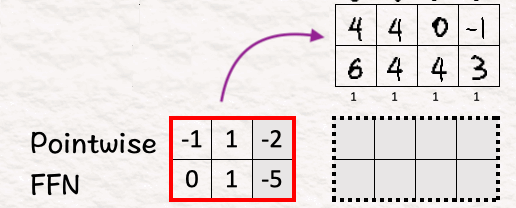
训练
现在的最后一步是使用预测噪声和采样噪声(基本事实)之间的均方误差来训练模型。
[10] 计算 MSE 损失梯度并更新可学习参数
使用 MSE 损失梯度,我们使用反向传播来更新所有可学习的参数(例如自适应范数层中的权重和偏差)。
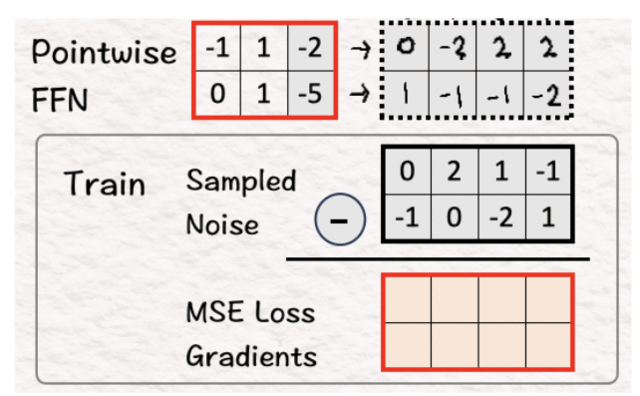
编码器和解码器参数已冻结且不可学习。
(备注:第二行的第二个元素应为 -1,这是一个微小的错误,可以使情况变得更好)。
[11]-[13] 生成新样本
[11] 去噪
现在我们已准备好生成新视频(耶!),我们首先需要消除我们引入的噪音。为此,我们从噪声潜伏期中减去预测的噪声以获得无噪声潜伏期。
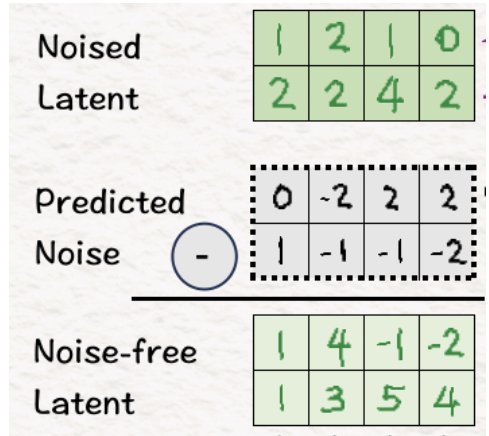
请注意,这与我们原来的潜在空间不同。原因是我们经历了多个条件和注意步骤,将问题的背景纳入模型中。因此,让模型在生成视频时更好地了解其目标应该是什么。
[12] 将潜在空间转换回像素:解码器
就像我们对编码器所做的那样,我们将潜在空间补丁与权重和偏差相乘,然后使用 ReLU。我们可以在这里观察到,在解码器的工作之后,模型回到了原始维度 4,而当我们使用编码器时,这个维度被降低到了 2。
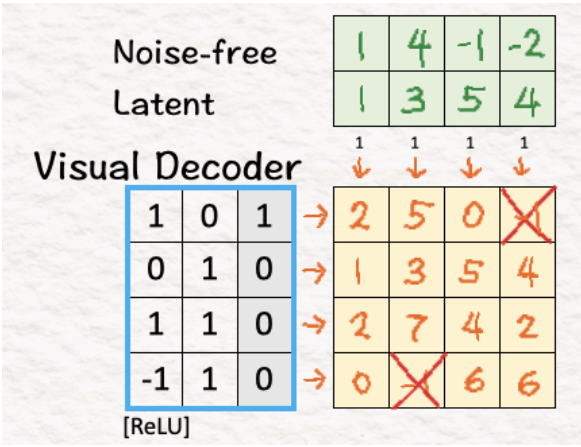
[13] 是时候制作视频了!
最后一步是将上述矩阵的结果排列成一系列帧,最终得到我们的新视频。好极了!

至此,我们结束了这项极其强大的技术。恭喜,您已经创建了 Sora 视频!
总结上述所有内容,以下是 5 个关键点:
- 将视频转换为视觉块,然后降低其维度至关重要。视觉编码器是我们的朋友。
- 顾名思义,扩散是此方法中的关键。向视频添加噪声,然后在每个后续步骤(以不同的方式)对其进行处理,这是此技术所依赖的。
- 接下来是transformer架构,它增强了扩散过程的能力,同时扩大了模型的规模。
- 一旦模型经过训练并准备好收敛到解决方案,两个 D——去噪器和解码器就派上用场了。一个是去除噪音,另一个是将低维空间投影到其原始维度。
- 最后,重新排列解码器的结果像素以生成所需的视频。
读完这篇文章后,我建议你再读一遍开头的故事。你能发现 DiTharos 的 Sora 和我们世界的 Sora 之间的相似之处吗?
3、Diffusion-Transformer (DiT) 组合
Sora 能够制作出如此多的视频,值得一提的是,DiT组合非常强大。与此同时,视觉补丁的概念为调整一系列图像分辨率、宽高比和持续时间开辟了一条途径,从而允许进行最大程度的实验。
总的来说,可以说这个想法是开创性的,而且毫无疑问会继续存在。根据《纽约时报》的这篇文章,Sora 的名字取自日语中的天空一词,旨在唤起无限潜力的概念。在见证了最初的承诺之后,Sora 确实在人工智能领域开辟了新领域。现在还有待观察它能否经受住安全性和时间的考验。
正如 DiTharos 的传说所说——“Sora 继续生存,日复一日地磨练技能,变得越来越强大,时刻准备着在黄金时刻展翅高飞!”
原文链接:Deep Dive into Sora’s Diffusion Transformer (DiT) by Hand
BimAnt翻译整理,转载请标明出处





