
NSDT工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器 - REVIT导出3D模型插件 - 3D模型语义搜索引擎 - AI模型在线查看 - Three.js虚拟轴心开发包 - 3D模型在线减面 - STL模型在线切割 - 3D道路快速建模
在谷歌出现之前,互联网主要是文本。 无论是新闻更新、体育比分、博客文章还是电子邮件,ASCII 和 Unicode 都是正确的选择。
但如今,数据变得越来越复杂和多模式,大多以图像、视频、文本、3D 网格等非结构化形式出现。限制在 26 个字符和 10 个数字(或其他字符集更多)的日子已经一去不复返了 . 现在有更多的事情要处理。
想想你最喜欢的 YouTube 视频、Spotify 歌曲或游戏 NPC。
典型的数据库无法处理这些类型的多模式数据。 它们只能存储和处理结构化数据(如简单的文本字符串或数字)。 这确实限制了我们从 21 世纪的大量数据中提取有价值的商业见解和价值的能力。
幸运的是,机器学习技术和近似最近邻搜索的最新进展使得更好地利用非结构化数据成为可能:
- 深度学习模型和表示学习使用向量嵌入有效表示复杂数据。
- 矢量数据库利用矢量嵌入来存储和分析非结构化数据。
1、矢量数据库?
矢量数据库是一种可以使用矢量索引和检索数据的数据库,类似于传统数据库如何使用键或文本来使用索引搜索项目。
矢量数据库使用矢量索引实现矢量的快速检索和插入,并提供典型的数据库特性,如 CRUD 操作、过滤和可扩展性。
这为我们提供了两全其美的优势——我们获得了传统数据库的 CRUD能力,以及存储复杂的非结构化数据(如图像、视频和 3D 网格)的能力。
那么,矢量数据库很棒,对吧? 更棒的是拥有一个库来使用它们,同时能够同时处理非结构化数据! 一个非结构化数据库来统领一切!
当然,我们正在谈论 DocArray。 让我们看看这个项目是关于什么的。
2、DocArray
正如项目主页上的描述所暗示的那样,DocArray 是一个用于嵌套、非结构化和多模态数据的库。
这意味着如果你想处理非结构化数据并将其表示为向量,DocArray 非常适合你。
DocArray 也是许多矢量数据库的通用入口点。
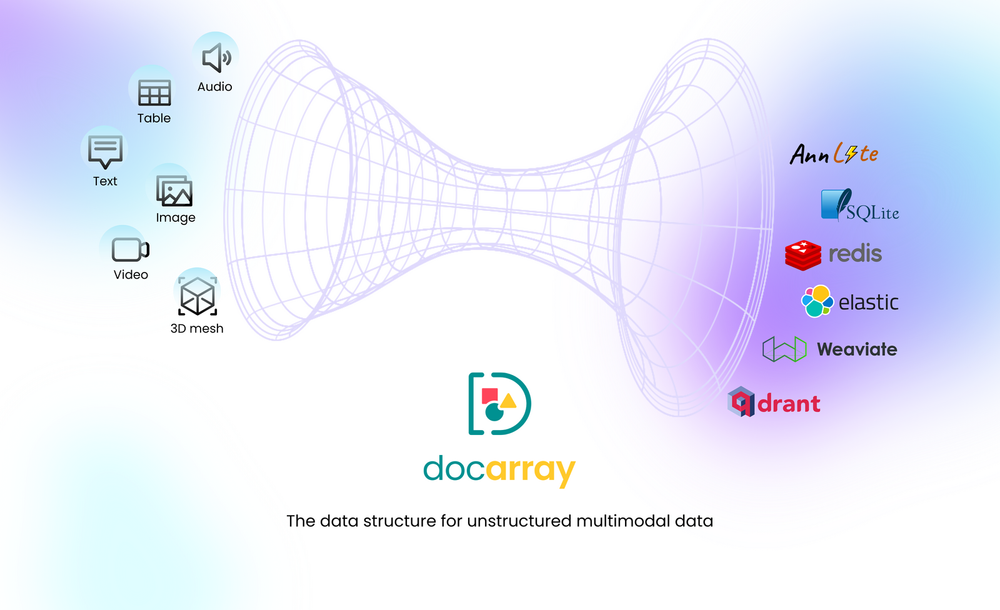
对于本文的其余部分,我们将使用 DocArray 在 Amazon Berkeley Objects 数据集中索引和搜索数据。 此数据集包含带有图像和元数据(例如品牌、国家/地区和颜色)的产品项目,代表电子商务网站的库存。
传统数据库虽然可以对元数据进行过滤,但无法搜索图像数据或其他非结构化数据格式。 这就是我们使用矢量数据库的原因!
我们首先将 CSV 格式的 Amazon Berkeley 对象数据集的一个子集加载到 DocArray 中并计算向量嵌入。

然后,我们将对每个数据库使用 DocArray,以使用向量执行搜索和插入操作。
我们将在 Python 中通过 DocArray 使用以下数据库:
- Milvus - 存储计算分离的云原生矢量数据库
- Weaviate - 存储对象和矢量的矢量搜索引擎,可以通过 REST 或 GraphQL 访问
- Qdrant - 用 Rust 编写的矢量数据库,旨在在高负载下快速可靠
- Redis - 内存键值数据库,支持具有向量搜索功能的不同类型的数据结构
- ElasticSearch - 具有近似最近邻搜索功能的分布式 RESTful 搜索引擎
- OpenSearch - 基于 Apache Lucene 的开源搜索软件,最初是从 ElasticSearch 派生出来的
- AnnLite - 一个具有过滤功能的快速近似最近邻搜索的 Python 库
对于每个数据库,我们将:
- 设置数据库和安装要求
- 索引矢量数据库中的数据
- 执行带过滤的矢量搜索操作
- 显示搜索结果
3、准备数据
首先,我们将安装一些依赖项,即 DocArray、Jina(用于云身份验证)和 CLIP-as-service 客户端(用于生成嵌入):
pip install docarray[common] jina clip-client让我们下载一个示例 CSV 数据集并使用 DocumentArray.from_csv() 将其加载到 DocumentArray 中:
wget https://github.com/jina-ai/product-recommendation-redis-docarray/raw/main/data/dataset.csvfrom docarray import DocumentArray, Document
with open('dataset.csv') as fp:
da = DocumentArray.from_csv(fp)我们使用 summary() 方法得到一个概览:
╭────────────────────── Documents Summary ──────────────────────╮
│ │
│ Type DocumentArrayInMemory │
│ Length 5809 │
│ Homogenous Documents True │
│ Common Attributes ('id', 'mime_type', 'uri', 'tags') │
│ Multimodal dataclass False │
│ │
╰───────────────────────────────────────────────────────────────╯
╭───────────────────── Attributes Summary ─────────────────────╮
│ │
│ Attribute Data type #Unique values Has empty value │
│ ────────────────────────────────────────────────────────── │
│ id ('str',) 5809 False │
│ mime_type ('str',) 1 False │
│ tags ('dict',) 5809 False │
│ uri ('str',) 4848 False │
│ │
╰──────────────────────────────────────────────────────────────╯我们还可以使用 plot_image_sprites() 方法显示前几项的图像:
da[:12].plot_image_sprites()
每个产品都将元数据作为 tags 属性中的字典包含:
da[0].tags{'height': '1926',
'color': 'Blue',
'country': 'CA',
'width': '1650',
'brand': 'Thirty Five Kent'}4、生成嵌入
接下来,我们将使用 Clip-as-service 将文档编码为向量。
首先,我们需要登录 Jina AI云:
jina auth login让我们创建一个身份验证令牌来使用该服务:
jina auth token create abo -e 30然后,我们实际上可以使用该服务来生成嵌入:
from clip_client import Client
c = Client(
'grpcs://api.clip.jina.ai:2096', credential={'Authorization': 'your-auth-token'}
)
encoded_da = c.encode(da, show_progress=True)5、准备搜索文件
如果要搜索我们的数据库,我们需要一些东西。 与 DocArray 中的所有内容一样,基本单位是文档。 因此,让我们准备一个用于搜索的查询文档。 我们将只选择数据集中的第一个产品:
doc = encoded_da[0]
doc.display()6、索引数据
现在数据已准备就绪,我们可以对其进行索引并开始执行搜索查询。 在接下来的部分中,我们将对每个支持的数据库进行索引。
6.1 Milvus
Milvus 是一个开源矢量数据库,旨在为嵌入相似性搜索和 AI 应用程序提供支持。 它是一个云原生数据库,存储和计算在设计上是分离的。
这意味着可以单独缩放每个层。 因此,Milvus 提供了一个可扩展且可靠的架构。
使用以下 YAML 启动 Milvus 服务:
version: '3.5'
services:
etcd:
container_name: milvus-etcd
image: quay.io/coreos/etcd:v3.5.0
environment:
- ETCD_AUTO_COMPACTION_MODE=revision
- ETCD_AUTO_COMPACTION_RETENTION=1000
- ETCD_QUOTA_BACKEND_BYTES=4294967296
- ETCD_SNAPSHOT_COUNT=50000
volumes:
- ${DOCKER_VOLUME_DIRECTORY:-.}/volumes/etcd:/etcd
command: etcd -advertise-client-urls=http://127.0.0.1:2379 -listen-client-urls http://0.0.0.0:2379 --data-dir /etcd
minio:
container_name: milvus-minio
image: minio/minio:RELEASE.2022-03-17T06-34-49Z
environment:
MINIO_ACCESS_KEY: minioadmin
MINIO_SECRET_KEY: minioadmin
volumes:
- ${DOCKER_VOLUME_DIRECTORY:-.}/volumes/minio:/minio_data
command: minio server /minio_data
healthcheck:
test: ["CMD", "curl", "-f", "http://localhost:9000/minio/health/live"]
interval: 30s
timeout: 20s
retries: 3
standalone:
container_name: milvus-standalone
image: milvusdb/milvus:v2.1.4
command: ["milvus", "run", "standalone"]
environment:
ETCD_ENDPOINTS: etcd:2379
MINIO_ADDRESS: minio:9000
volumes:
- ${DOCKER_VOLUME_DIRECTORY:-.}/volumes/milvus:/var/lib/milvus
ports:
- "19530:19530"
- "9091:9091"
depends_on:
- "etcd"
- "minio"
networks:
default:
name: milvusdocker-compose up然后,创建一个连接到 Milvus 的 DocumentArray 实例。 确保使用 milvus 标签安装 DocArray:
pip install "docarray[milvus]"milvus_da = DocumentArray(storage='milvus', config={
'n_dim': 768,
'columns': {
'color': 'str',
'country': 'str',
'width': 'int',
'height': 'int',
'brand': 'str',
}
})
# Index data
with milvus_da:
milvus_da.extend(encoded_da)现在,使用 filter color='Blue' 搜索类似于 doc 的项目:
filter = 'color == "Blue"'
results = milvus_da.find(doc,filter=filter, limit=5)
results[0].plot_image_sprites()
作为 LFAI & Data 的一部分,Milvus 代表了一个生产就绪的云原生矢量数据库。
6.2 Weaviate
Weaviate 是一个开源矢量搜索引擎,它同时存储对象和矢量,允许将矢量搜索与结构化过滤相结合。
它提供容错和可伸缩性等功能,可以通过 REST 或 GraphQL 访问。
使用以下 YAML 启动 Weaviate 服务器:
version: '3.4'
services:
weaviate:
command:
- --host
- 0.0.0.0
- --port
- '8080'
- --scheme
- http
image: semitechnologies/weaviate:1.16.1
ports:
- "8080:8080"
restart: on-failure:0
environment:
QUERY_DEFAULTS_LIMIT: 25
AUTHENTICATION_ANONYMOUS_ACCESS_ENABLED: 'true'
PERSISTENCE_DATA_PATH: '/var/lib/weaviate'
DEFAULT_VECTORIZER_MODULE: 'none'
ENABLE_MODULES: ''
CLUSTER_HOSTNAME: 'node1'docker-compose up然后,创建一个连接到 Weaviate 的 DocumentArray 实例。 确保使用 weaviate 标签安装 DocArray:
pip install "docarray[weaviate]"weaviate_da = DocumentArray(storage='weaviate', config={
'n_dim': 768,
'columns': {
'color': 'str',
'country': 'str',
'product_type': 'str',
'width': 'int',
'height': 'int',
'brand': 'str',
}
})
# Index data
weaviate_da.extend(encoded_da)现在,使用 filter color='Blue' 搜索类似于 doc 的项目:
filter = {'path': 'color', 'operator': 'Equal', 'valueString': 'Blue'}
results = weaviate_da.find(doc,filter=filter, limit=5)
results[0].plot_image_sprites()
因此,Weaviate 提供具有过滤支持和复制、混合搜索、动态批处理等功能的矢量搜索功能。
6.3 Qdrant
Qdrant 是一个开源矢量数据库。 用 Rust 编写,即使在高负载下也能提供快速可靠的搜索体验。 实际上,它在 DocArray 的一百万个基准测试中被列为最快的磁盘矢量数据库(截至用于进行实验的版本)。
Qdrant 带有过滤支持和使用 HTTP 或 gRPC 的便捷 API。
使用以下 YAML 启动 Qdrant 服务器:
version: '3.4'
services:
qdrant:
image: qdrant/qdrant:v0.10.1
ports:
- "6333:6333"
- "6334:6334"
ulimits: # Only required for tests, as there are a lot of collections created
nofile:
soft: 65535
hard: 65535docker-compose up然后,创建一个连接到 Qdrant 的 DocumentArray 实例。 确保使用 qdrant 标签安装 DocArray:
qdrant_da = DocumentArray(storage='qdrant', config={
'n_dim': 768,
'columns': {
'color': 'str',
'country': 'str',
'product_type': 'str',
'width': 'int',
'height': 'int',
'brand': 'str',
}
})
# Index data
qdrant_da.extend(encoded_da)现在,使用 filter color='Blue' 搜索类似于 doc 的项目:
filter = {'must': [{'key': 'color', 'match': {'value': 'Blue'}}]}
results = qdrant_da.find(doc,filter=filter, limit=5)
results[0].plot_image_sprites()
Qdrant 提供快速可靠的搜索服务。 它支持大规模过滤和矢量搜索。
它的 gRPC 支持也使得批量索引变得方便,因为使用 gRPC 索引数据集比使用 HTTP 协议快得多。
6.4 Redis
Redis 是一个开源的内存键值数据库。 Redis 支持不同类型的数据结构,并使用一组使用 TCP 套接字的命令提供访问。
在其 RediSearch 模块 2.4 中,Redis 添加了矢量搜索功能。 这意味着 Redis 可以被视为内存中的矢量数据库。
使用以下 YAML 启动 Redis 服务器:
docker run -d -p 6379:6379 redis/redis-stack:latest然后,创建一个连接到 Redis 的 DocumentArray 实例。 确保使用 redis 标签安装 DocArray:
pip install "docarray[redis]"redis_da = DocumentArray(storage='redis', config={
'n_dim': 768,
'columns': {
'color': 'str',
'country': 'str',
'product_type': 'str',
'width': 'int',
'height': 'int',
'brand': 'str',
}
})
# Index data
redis_da.extend(encoded_da)现在,使用 filter color='Blue' 搜索类似于 doc 的项目:
filter = '@color:Blue'
results = redis_da.find(doc,filter=filter, limit=5)
results[0].plot_image_sprites()
由于 Redis 是内存存储,因此与磁盘数据库相比,它提供更快的搜索查询。 它在 DocArray 的一百万个基准测试中被列为最快的数据库服务器。
如果你需要对矢量数据库进行快速矢量搜索和操作,同时能够索引内存中的数据,请使用它。
6.5 ElasticSearch
ElasticSearch 是一个开源、分布式和 RESTful 搜索引擎。 它可用于搜索、存储和管理数据。ElasticSearch 在 Elasticsearch 8.0 中引入了近似最近邻搜索。这意味着任何版本 > 8.0 的 ElasticSearch Server 都具有矢量搜索功能。
使用以下 YAML 启动 ElasticSearch 服务器:
version: "3.3"
services:
elastic:
image: docker.elastic.co/elasticsearch/elasticsearch:8.2.0
environment:
- xpack.security.enabled=false
- discovery.type=single-node
ports:
- "9200:9200"
networks:
- elastic
networks:
elastic:
name: elasticdocker-compose up然后,创建一个连接到 ElasticSearch 的 DocumentArray 实例。 确保使用 elasticsearch 标签安装 DocArray:
pip install "docarray[elasticsearch]"elasticsearch_da = DocumentArray(storage='elasticsearch', config={
'n_dim': 768,
'columns': {
'color': 'str',
'country': 'str',
'product_type': 'str',
'width': 'int',
'height': 'int',
'brand': 'str',
}
})
# Index data
elasticsearch_da.extend(encoded_da, request_timeout=60)现在,使用 filter color='Blue' 搜索类似于 doc 的项目:
filter = {'match': {'color': 'Blue'}}
results = elasticsearch_da.find(doc,filter=filter, limit=5)
results[0].plot_image_sprites()
ElasticSearch 便于生产用例。 它提供可扩展性、数据分布、过滤、混合搜索等功能。它具有安全性、可观察性和云原生性。
6.6 OpenSearch
OpenSearch 是一个可缩放、灵活且可扩展的开源搜索程序,在 Apache 2.0 下获得许可。
OpenSearch 由 Apache Lucene 提供支持,最初是从 ElasticSearch 派生出来的。 这意味着 OpenSearch 包含 ElasticSearch 的大部分功能。
与 ElasticSearch 一样,OpenSearch 包括近似最近邻搜索,允许它执行向量相似性搜索。
使用以下 YAML 启动 OpenSearch 服务器:
version: "3.3"
services:
opensearch:
image: opensearchproject/opensearch:2.4.0
environment:
- plugins.security.disabled=true
- discovery.type=single-node
ports:
- "9900:9200"
networks:
- os
networks:
os:
name: osdocker-compose up然后,创建一个连接到 ElasticSearch 的 DocumentArray 实例。 确保使用 opensearch 标签安装 DocArray:
pip install "docarray[opensearch]"opensearch_da = DocumentArray(storage='opensearch', config={
'n_dim': 768,
'columns': {
'color': 'str',
'country': 'str',
'product_type': 'str',
'width': 'int',
'height': 'int',
'brand': 'str',
}
})
# Index data
opensearch_da.extend(encoded_da)现在,使用 filter color='Blue' 搜索类似于 doc 的项目:
filter = {'match': {'color': 'Blue'}}
results = opensearch_da.find(doc,filter=filter, limit=5)
results[0].plot_image_sprites()
与 ElasticSearch 一样,OpenSearch 便于生产用例。 它还提供与 AWS 云的更好集成。 OpenSearch 还拥有比 ElasticSearch 更开放的许可证。
6.7 AnnLite
AnnLite 是一个 Python 库,用于具有过滤功能的快速近似最近邻搜索。 由 Jina AI 构建,它作为库(无客户端-服务器架构)提供简单的矢量搜索体验。
要使用 AnnLite,请使用 annlite 标签安装 DocArray:
pip install "docarray[annlite]"annlite_da = DocumentArray(storage='annlite', config={
'n_dim': 768,
'columns': {
'color': 'str',
'country': 'str',
'product_type': 'str',
'width': 'int',
'height': 'int',
'brand': 'str',
}
})
# Index data
annlite_da.extend(encoded_da)现在,使用 filter color='Blue' 搜索类似于 doc 的项目:
filter = {'color': {'$eq': 'Blue'}}
results = annlite_da.find(doc,filter=filter, limit=5)
results[0].plot_image_sprites()
AnnLite 易于安装和使用。 通过 DocArray,它提供了具有过滤功能的出色本地矢量搜索。 由于它不依赖于客户端-服务器架构,因此没有网络开销,但它实现了 HNSW 以进行快速矢量搜索。
7、结束语
矢量数据库使我们能够有效地利用非结构化数据并从中提取有用的见解。 他们可以执行向量搜索,这对相似性匹配、推荐、分析等很有用。
根据你的资源、用例和要求,选择正确的数据库可能具有挑战性。 例如,你会为高速与低内存选择不同的数据库。
为了帮助你做出决定,我们发布了使用 DocArray 的矢量数据库的基准测试。 也就是说,你可能需要测试一些数据库才能找到你的匹配项。
通常情况下,测试意味着在使用之前学习每个数据库,这需要花费大量时间和精力。 但是使用 DocArray 的统一 API,可以以相同的方式与所有这些数据库对话。 只需要更改一两行代码,然后 就可以使用一个新数据库。
原文链接:How to Use Every Vector Database in Python with DocArray
BimAnt翻译整理,转载请标明出处





