
NSDT工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器 - REVIT导出3D模型插件 - 3D模型语义搜索引擎 - AI模型在线查看 - Three.js虚拟轴心开发包 - 3D模型在线减面 - STL模型在线切割 - 3D道路快速建模
文档信息提取涉及使用计算机算法从非结构化或半结构化文档(例如报告、电子邮件和网页)中提取结构化数据(例如员工姓名、地址、职务、电话号码等)。 提取的信息可用于各种目的,例如分析和分类。 DocVQA(文档视觉问答)是一种结合计算机视觉和自然语言处理技术的尖端方法,可以自动回答有关文档内容的问题。 本文将探讨使用 DocVQA 和 Google 的 Pix2Struct 包进行信息提取。
1、DocVQA 用例
文档提取自动从非结构化文档(例如发票、收据、合同和表格)中提取相关信息。 以下行业将因此受益:
- 金融:银行和金融机构使用文档提取来自动执行发票处理、贷款申请处理和开户等任务。 通过自动化这些任务,文档提取可以减少错误和处理时间并提高效率。
- 医疗保健:医院和医疗保健提供者使用文档提取从医疗记录中提取重要的患者数据,例如诊断代码、治疗计划和测试结果。 这有助于简化患者护理并改善患者治疗结果。
- 保险:保险公司使用文档提取来处理索赔、保单申请和承保文件。 文档提取可以通过自动化这些任务来减少处理时间并提高准确性。
- 政府:政府机构使用文档提取来处理大量非结构化数据,例如税表、申请表和法律文档。 通过自动化这些任务,文档提取可以帮助降低成本、提高准确性并提高效率。
- 法律:律师事务所和法律部门使用文档提取从法律文档(例如合同、诉状和证据证明文件)中提取关键信息。 它将提高法律研究和文件审查的效率和准确性。
文档提取在处理大量非结构化数据的行业中有许多应用。 自动化文档处理任务可以帮助组织节省时间、减少错误并提高效率。
2、文档信息提取的挑战
文档信息提取存在一些挑战。 主要挑战是文档格式和结构的可变性。 例如,不同的文档可能具有不同的形式和布局,使得难以一致地提取信息。 另一个挑战是数据中的噪音,例如拼写错误和不相关的信息。 这可能会导致提取结果不准确或不完整。
文档信息提取的过程涉及几个步骤:
- 文档理解
- 预处理文档,包括清理和准备数据以供分析。 预处理可以包括删除不必要的格式(例如页眉和页脚),以及将数据转换为纯文本。
- 使用基于规则和机器学习算法的组合从文档中提取相关信息。 基于规则的算法使用一组预定义的规则来删除特定类型的信息,例如姓名、日期和地址。
- 机器学习算法使用统计模型来识别数据中的模式并提取相关信息。
- 验证并完善提取的信息。 它涉及检查提取的信息的准确性并进行必要的更正。 此步骤对于确保提取的数据准确可靠以供进一步分析至关重要。
研究人员正在开发新的文档信息提取算法和技术来应对这些挑战。 其中包括处理文档结构可变性的技术,例如使用深度学习算法自动学习文档结构。 它们还包括处理噪声数据的技术,例如使用自然语言处理技术来识别和纠正拼写错误。
3、相关工作
DocVQA 代表文档视觉问答,这是计算机视觉和自然语言处理中的一项任务,旨在回答有关给定文档图像内容的问题。 问题可以涉及文档文本的任何方面。 DocVQA 是一项具有挑战性的任务,因为它需要理解文档的视觉内容以及阅读和理解其中文本的能力。 该任务有许多实际应用,例如文档检索、信息提取等。
LayoutLM、Flan-T5 和 Donut 是用于文档视觉问答 (DOCVQA) 的文档布局分析和文本识别的三种方法。
它是一种预先训练的语言模型,融合了文档布局、OCR 文本位置和文本内容等视觉信息。 LayoutLM 可以针对各种 NLP 任务进行微调,包括 DOCVQA。 例如,DOCVQA 中的 LayoutLM 可以帮助准确定位文档的相关文本和其他视觉元素,这对于回答需要上下文特定信息的问题至关重要。
Flan-T5 是一种使用基于变压器的架构来执行文本识别和布局分析的方法。 该模型在文档图像上进行端到端训练,可以处理多语言文档,使其适合各种应用。 例如,在 DOCVQA 中使用 Flan-T5 可以实现准确的文本识别和布局分析,这有助于提高系统的性能。
Donut 是一种深度学习模型,它使用新颖的架构对布局不规则的文档执行文本识别。 在 DOCVQA 中使用 Donut 可以帮助从复杂布局的文档中准确提取文本,这对于回答需要特定信息的问题至关重要。 显着的优点是它无需 OCR。
总体而言,在 DOCVQA 中使用这些模型可以通过从文档图像中准确提取文本和其他相关信息来提高系统的准确性和性能。
4、Pix2Struct
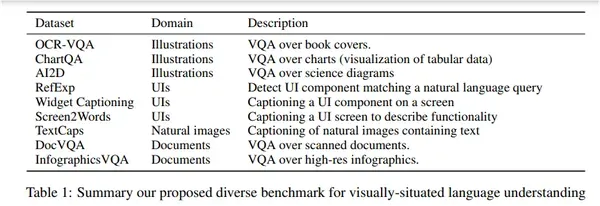
该论文介绍了 Google 的 Pix2Struct,这是一种用于理解视觉情境语言的预训练图像到文本模型。 该模型使用新颖的学习技术进行训练,将网页的屏幕截图解析为简化的 HTML,为一系列下游活动提供非常适合的预训练数据源。 除了新颖的预训练策略之外,本文还引入了更灵活的语言和视觉输入以及可变分辨率输入表示的集成。 结果,该模型在文档、插图、用户界面和自然图像等 4 个领域的九项任务中的六项中取得了最先进的结果。 下图显示了有关所考虑的域的详细信息,图为pix2struct研究论文第5页:
Pix2Struct 是一种预训练模型,它将纯像素级输入的简单性与来自多样化和丰富的网络数据的自监督预训练提供的通用性和可扩展性结合在一起。 该模型通过推荐一个屏幕截图解析目标来实现此目的,该目标需要从已部分屏蔽的网页屏幕截图中预测基于 HTML 的解析。 利用网络上文本和视觉元素的多样性和复杂性,Pix2Struct 学习网页底层结构的丰富表示,这可以有效地转移到各种下游视觉语言理解任务。
Pix2Struct 基于 Vision Transformer (ViT),一种图像编码器文本解码器模型。 然而,Pix2Struct 对输入表示提出了一个小但有影响力的改变,以使模型对各种形式的视觉情境语言更加鲁棒。 标准 ViT 在将输入图像缩放到预定分辨率后提取固定大小的补丁。 这会扭曲图像的正确纵横比,对于文档、移动用户界面和图形来说,该纵横比可能会有很大变化。
此外,将这些模型转移到具有更高分辨率的下游任务具有挑战性,因为该模型在预训练期间仅观察到一种特定分辨率。 Pix2Struct 建议放大或缩小输入图像,以提取适合给定序列长度的最大数量的补丁。 这种方法对于极端纵横比更加稳健,这在 Pix2Struct 实验领域很常见。 此外,该模型可以处理序列长度和分辨率的即时更改。 为了明确地处理可变分辨率,输入补丁使用二维绝对位置嵌入。
Pix2Struct提供两种模型:
- 基本模型:google/pix2struct-docvqa-base(~ 1.3 GB)
- 大模型:google/pix2struct-docvqa-large(~ 5.4 GB)
Pix2Struct-Large 模型在 DocVQA 数据集上的性能优于之前最先进的 Donut 模型。 LayoutLMv3 模型使用三个组件(包括 OCR 系统和预训练编码器)在此任务上实现了高性能。 然而,Pix2Struct 模型在不使用域内预训练数据的情况下表现出竞争力,并且仅依赖于视觉表示。 我们仅考虑 DocVQA 结果。
5、基于Pix2Struct的DocVQA实现
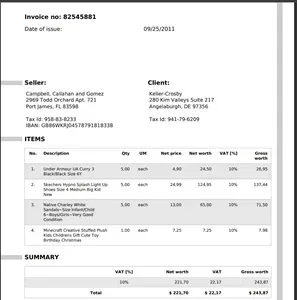
让我们逐步了解 DocVQA 的实现。 出于演示目的,让我们考虑 Mendeley Data 的示例发票。
首先安装开发包:
!pip install git+https://github.com/huggingface/transformers pdf2image
!sudo apt install poppler-utils12diff接下来导入包:
from pdf2image import convert_from_path, convert_from_bytes
import torch
from functools import partial
from PIL import Image
from transformers import Pix2StructForConditionalGeneration as psg
from transformers import Pix2StructProcessor as psp使用预训练权重初始化模型:
DEVICE = "cuda" if torch.cuda.is_available() else "cpu"
model = psg.from_pretrained("google/pix2struct-docvqa-large").to(DEVICE)
processor = psp.from_pretrained("google/pix2struct-docvqa-large")一些处理函数:
def generate(model, processor, img, questions):
inputs = processor(images=[img for _ in range(len(questions))],
text=questions, return_tensors="pt").to(DEVICE)
predictions = model.generate(**inputs, max_new_tokens=256)
return zip(questions, processor.batch_decode(predictions, skip_special_tokens=True))
def convert_pdf_to_image(filename, page_no):
return convert_from_path(filename)[page_no-1]指定PDF文件的路径和要提取信息的页码:
questions = ["what is the seller name?",
"what is the date of issue?",
"What is Delivery address?",
"What is Tax Id of client?"]
FILENAME = "/content/invoice_107_charspace_108.pdf"
PAGE_NO = 1生成答案:
image = convert_pdf_to_image(FILENAME, PAGE_NO)
print("pdf to image conversion complete.")
generator = partial(generate, model, processor)
completions = generator(image, questions)
for completion in completions:
print(f"{completion}") 结果如下:
## answers
('what is the seller name?', 'Campbell, Callahan and Gomez')
('what is the date of issue?', '09/25/2011')
('What is Delivery address?', '2969 Todd Orchard Apt. 721')
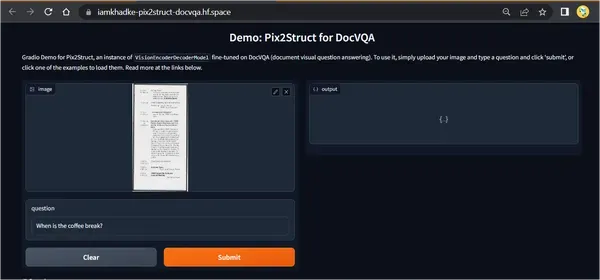
('What is Tax Id of client?', '941-79-6209')你可以在这个HF空间尝试演示,或者点击这里下载notebook:
6、结束语
文档信息提取是一个重要的研究领域,在许多领域都有应用。 它涉及使用计算机算法从基于文本的文档中识别和提取相关信息。 尽管文档信息提取存在一些挑战,但研究人员正在开发新的算法和技术来应对这些挑战并提高所提取信息的准确性和可靠性。
然而,与所有深度学习模型一样,DocVQA 也有一些局限性。 例如,它需要大量训练数据才能表现良好,并且可能需要复杂文档或罕见符号和字体的帮助。 它还可能对输入图像的质量以及用于从文档中提取文本的 OCR(光学字符识别)系统的准确性敏感。
原文链接:Document Information Extraction Using Pix2Struct
BimAnt翻译整理,转载请标明出处





