
NSDT工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器 - REVIT导出3D模型插件 - 3D模型语义搜索引擎 - AI模型在线查看 - Three.js虚拟轴心开发包 - 3D模型在线减面 - STL模型在线切割 - 3D道路快速建模
EVA 旨在支持使用深度学习模型对结构化数据(表格、特征向量)和非结构化数据(视频、播客、PDF 等)进行操作的数据库应用程序。 它使用一系列受久经考验的关系数据库系统启发的优化,包括函数缓存、采样和基于成本的谓词重新排序,将 AI 管道加速 10-100 倍。 EVA 支持面向 AI 的类 SQL 查询语言,专为分析非结构化数据而量身定制。 它带有用于分析非结构化数据的广泛模型,包括用于图像分类、对象检测、OCR、文本情感分类、人脸检测等的模型。它完全用 Python 实现并在 Apache 许可下获得许可。
EAV的主要特性如下:
- 🔮 使用类似 SQL 的简短查询构建更简单的 AI 驱动的应用程序
- ⚡️ 使用以 AI 为中心的查询优化,AI 管道速度提高 10-100 倍
- 💰 节省花在 GPU 驱动推理上的钱
- 🚀 通过用户定义的函数为您的自定义深度学习模型提供一流的支持
- 📦 内置缓存以消除跨查询的冗余模型调用
- ⌨️ 对 PyTorch 和 HuggingFace 模型的一流支持
- 🐍 可通过 pip 安装并完全在 Python 中实现
以下是一些说明性的 EVA 支持的应用程序(它们都是可以在 Google Colab 中打开的 Jupyter 笔记本):
- 🔮 分析十字路口的交通流量
- 🔮 检查电影中演员的情感调色板
- 🔮 根据内容对图像进行分类
- 🔮 使用拥抱面进行图像分割
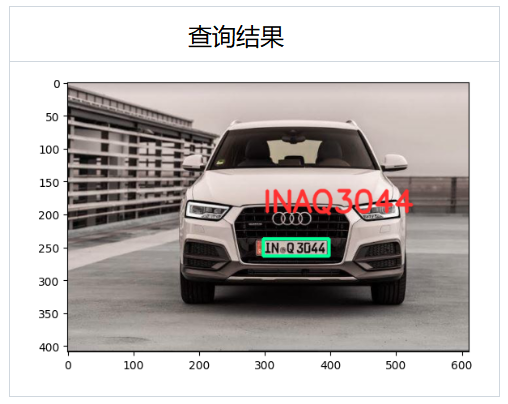
- 🔮 识别车牌
- 🔮 分析社交媒体模因的毒性
1、快速开始
使用 pip 包管理器安装 EVA。 EVA 支持 Python 版本 >= 3.7。
pip install evadb要在 Jupyter notebook 中启动并连接到 EVA 服务器,请查看这个介绍性的情绪分析 notebook:
cursor = connect_to_server()将视频加载到 EVA 服务器上(我们使用 ua_detrac.mp4 进行说明):
LOAD VIDEO "data/ua_detrac/ua_detrac.mp4" INTO TrafficVideo;就是这样! 现在可以对加载的视频运行查询:
SELECT id, data FROM TrafficVideo WHERE id < 5;在视频中搜索包含汽车的帧:
SELECT id, data FROM TrafficVideo WHERE ['car'] <@ Yolo(data).labels;
在视频中搜索包含行人和汽车的帧:
SELECT id, data FROM TrafficVideo WHERE ['pedestrian', 'car'] <@ Yolo(data).labels;搜索超过三辆汽车的帧:
SELECT id, data FROM TrafficVideo WHERE ArrayCount(Yolo(data).labels, 'car') > 3;在具有用户定义函数 (UDF) 的查询中使用自定义深度学习模型:
CREATE UDF IF NOT EXISTS MyUDF
INPUT (frame NDARRAY UINT8(3, ANYDIM, ANYDIM))
OUTPUT (labels NDARRAY STR(ANYDIM), bboxes NDARRAY FLOAT32(ANYDIM, 4),
scores NDARRAY FLOAT32(ANYDIM))
TYPE Classification
IMPL 'eva/udfs/fastrcnn_object_detector.py';在单个查询中组合多个模型以设置有用的 AI 管道。
-- Analyse emotions of faces in a video
SELECT id, bbox, EmotionDetector(Crop(data, bbox))
FROM MovieVideo JOIN LATERAL UNNEST(FaceDetector(data)) AS Face(bbox, conf)
WHERE id < 15;EVA 使用其以 AI 为中心的查询优化器更快地运行查询。 两个关键的优化是:
- 💾 缓存:EVA自动缓存并复用之前的查询结果(尤其是模型推理结果),消除冗余计算,减少查询处理时间。
- 🎯 谓词重新排序:EVA 优化了查询谓词的评估顺序(例如,首先运行速度更快、更具选择性的模型),从而加快查询速度并降低推理成本。
考虑对 🐕 图像数据集的这两个探索性查询:
-- Query 1: Find all images of black-colored dogs
SELECT id, bbox FROM dogs
JOIN LATERAL UNNEST(Yolo(data)) AS Obj(label, bbox, score)
WHERE Obj.label = 'dog'
AND Color(Crop(data, bbox)) = 'black';
-- Query 2: Find all Great Danes that are black-colored
SELECT id, bbox FROM dogs
JOIN LATERAL UNNEST(Yolo(data)) AS Obj(label, bbox, score)
WHERE Obj.label = 'dog'
AND DogBreedClassifier(Crop(data, bbox)) = 'great dane'
AND Color(Crop(data, bbox)) = 'black';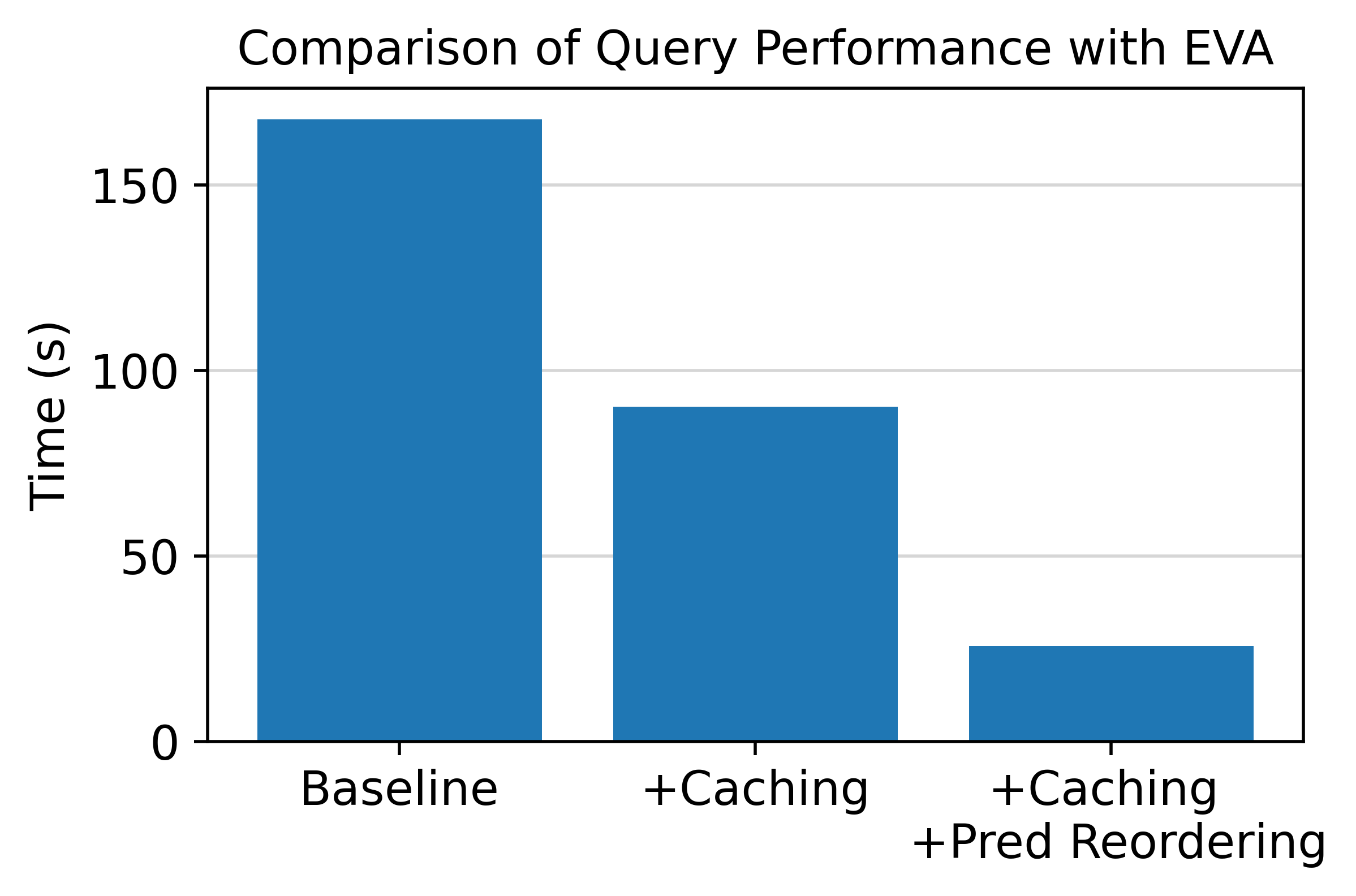
通过重用第一个查询的结果并根据可用的缓存推理结果对谓词重新排序,EVA 运行第二个查询的速度提高了 10 倍!
2、示例应用
🔮 流量分析(目标检测模型)

🔮 MNIST 数字识别(图像分类模型)

🔮 电影情感分析(人脸检测+情感分类模型)

🔮 车牌识别(车牌检测 + OCR 提取模型)
🔮 Meme 有害性分类(OCR 提取 + 毒性分类模型)

原文链接:EVA AI-Relational Database System
BimAnt翻译整理,转载请标明出处





