
NSDT工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器 - REVIT导出3D模型插件 - 3D模型语义搜索引擎 - AI模型在线查看 - Three.js虚拟轴心开发包 - 3D模型在线减面 - STL模型在线切割 - 3D道路快速建模
深度学习在 2D 视觉识别任务上取得了巨大成功。十年前被认为极其困难的图像分类和分割等任务,现在可以通过具有类似人类性能的神经网络来解决。这一成功归功于卷积神经网络 (CNN),它取代了手工制作的描述符。
受 CNN 在 2D 图像上取得成功的推动,研究人员已将 CNN 扩展到不规则图数据,例如 3D 网格。将卷积运算扩展到非结构化图数据并非易事,因为相对位置的概念已经丢失。因此,我们专门撰写了这篇博文和一个 Colab笔记本 来回答如何将 CNN 推广到不规则图。特别是,我们讨论了如何修改 CNN 以预测 3D 网格上的分割蒙版。
1、为什么 CNN 不适用?
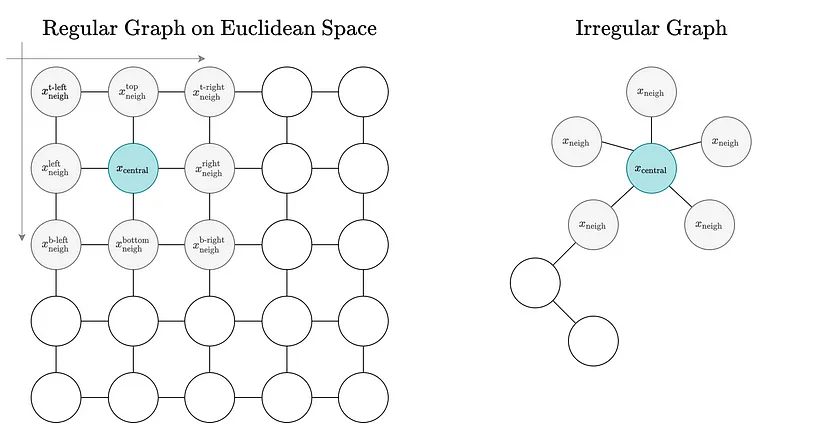
在欧几里得空间中定义的规则图具有固定的节点排序和邻域大小。通用图没有邻居节点排序,并且其邻居数量是可变的。
不幸的是,CNN 不能直接转换为不规则图。CNN 在欧几里得空间和规则图上工作,其中相邻节点可以通过它们与中心节点的相对位置相互区分,并且相邻节点的数量是恒定的。卷积运算利用这两个属性来得出信息节点嵌入。对于不规则和非结构化图,这些属性不满足。非结构化图没有相对位置的概念—没有顶部、底部、右侧或左侧。此外,邻域连接/大小可能因节点而异。因此,不可能在不规则图上执行卷积运算。
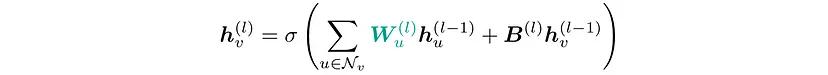
使用 3x3 CNN 层计算节点嵌入 h 的更新公式。请注意,为每个邻居学习唯一的权重矩阵 W。这是可能的,因为可以使用邻居与中心节点的相对位置来区分邻居。
2、图卷积网络
由于普通卷积运算不适用于不规则图,因此需要重新制定该运算。图卷积网络 (GCN) 和图卷积运算就是这样的重新制定。与传统 CNN 类似,GCN 对局部邻域进行推理。与 CNN 一样,GCN 通过聚合来自直接邻居的信息来计算嵌入。然而,GCN 确保此信息聚合操作不依赖于节点的相对位置,也不依赖于节点排序,并且与节点的邻域大小无关 - CNN 不会强制执行不变性。
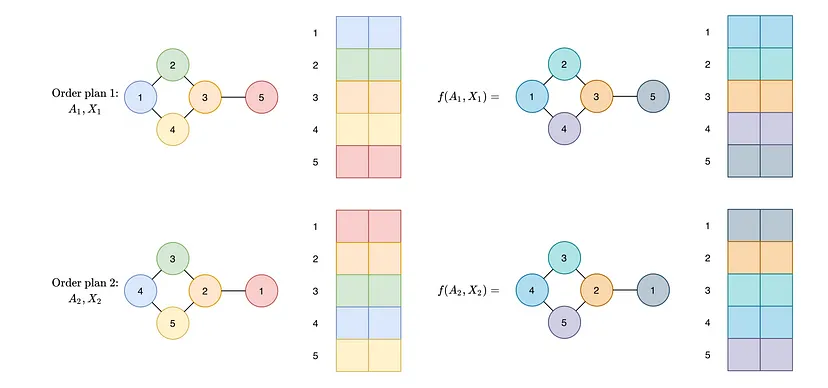
- 不规则图有节点顺序不变性,因此 GCN 的输出必须与图的节点排序无关。具体而言,无论节点排序如何,神经网络的输出都必须相同。如果输入了两个不同的图节点排序,我们不希望神经网络输出两个不同的值。此属性称为置换不变性。我们在下面进行说明。
- 节点的连接性在整个图中可能有所不同。因此,图卷积运算必须与邻域大小无关。
单个 GCN 层由三个操作定义:消息计算、聚合和更新。执行这些操作是为了导出节点嵌入。
- 消息计算:消息计算相当于转换图中每个节点的特征向量。应用的学习转换对所有节点都是通用的,以强制置换不变性。
- 聚合:导出所有消息后,每个节点都会通过置换等变函数(例如均值、最大值或总和函数)聚合其邻居的消息。这种消息聚合使信息能够在整个图中传播。
- 更新:最后,更新函数将聚合消息和当前节点的先前节点嵌入结合起来。从而更新节点的嵌入。通过结合来自节点邻域和节点本身的信息,导出的节点描述符对结构和节点级信息进行编码。
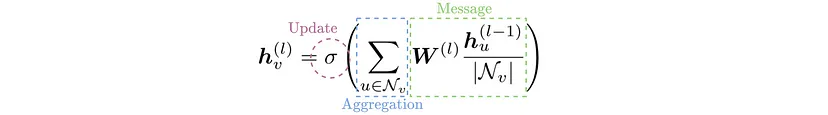
如需更详细的解释,请参阅斯坦福大学关于图形机器学习的课程 CS224W 的第 6 和第 7 讲。
3、图卷积网络的应用
为了探索引入的图卷积操作,我们转向图分割任务。与图像分割类似,其中像素被分配给语义类别,图分割相当于找到图节点和一组类别之间的映射。我们专注于将身体部位标签分配给人形 3D 网格节点的问题。
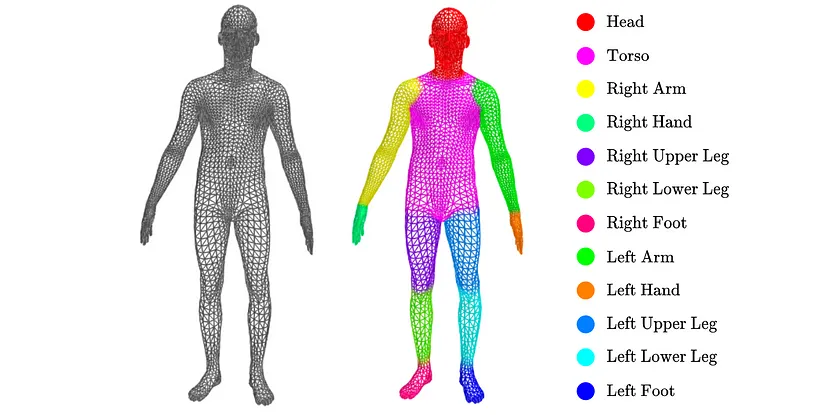
4、3D 网格数据
为了解决所提出的分割任务,我们利用了 3D 网格中编码的所有数据。3D 网格通过顶点和三角面的集合来定义表面。它由两个矩阵表示:
- 一个维度为 (n, 3) 的顶点矩阵,其中每行指定 3D 空间中顶点的空间位置 [x, y, z]。
- 一个维度为 (m, 3) 的面整数矩阵,其中每行包含定义三角面的顶点矩阵的三个索引。
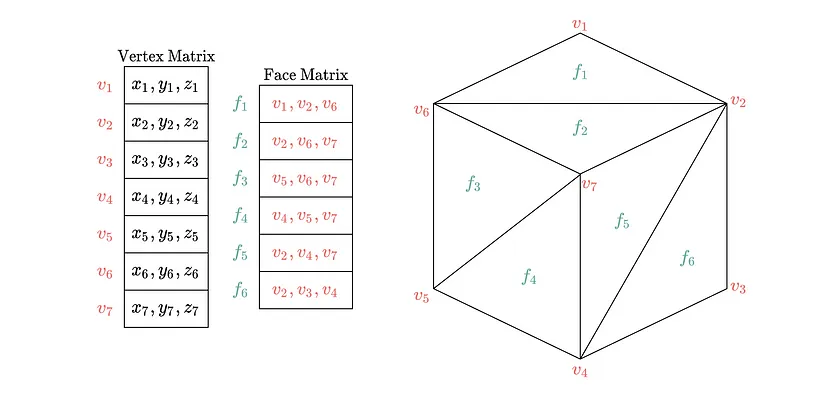
请注意,顶点矩阵捕获节点级特征信息,而面矩阵描述节点连通性。正式地,每个网格可以转换为具有顶点 V 的图 G = (X, A),其中 X 具有维度 (|V|, 3) 并定义 V 中每个节点 u 的空间 xyz 特征,而邻接矩阵 A 具有维度 (|V|, |V|) 并定义每个节点的连通邻域。我们使用这个推导出的网格图。
5、人体3D网格分割GCN实现
我们依靠特征引导图卷积从上述推到网格图中得出节点级身体部位分配。这个 GCN 层是由 Verma 等人提出的。
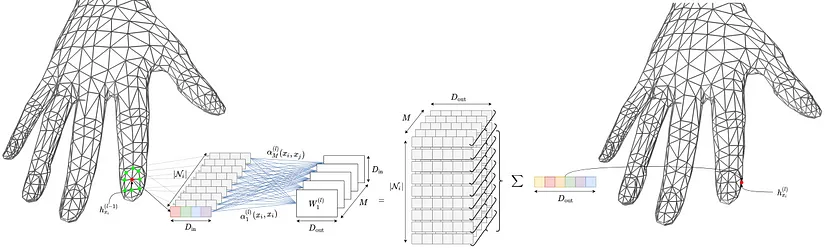
特征引导图卷积的工作原理如下。通过聚合相邻节点(绿色)的变换嵌入以及其自身的变换嵌入来更新中心节点(红色)的嵌入。具体来说,通过将其嵌入传递到 M 个权重矩阵,为每个节点创建 M 条不同的消息。因此,总共创建了 M x Ni 条消息。这些 M x Ni 通过可调加权平均值进行聚合。这可以表示为:
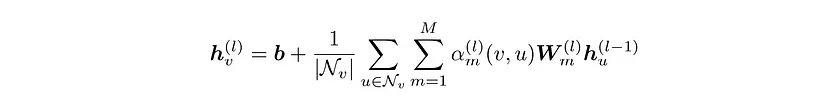
其中 Nv 是顶点 v 的相邻顶点(邻居)集(包括 v 本身)。
M 条消息通过可学习的注意力机制加权。这些消息按以下方式针对每一层进行计算:
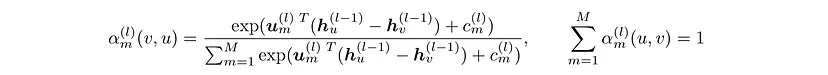
其中 u 和 c 是可学习的参数,特定于每个层。请注意,此注意力权重函数是平移不变的,这在使用空间输入特征时是可取的。它确保输入网格的平移不会影响计算出的注意力权重。
6、在 PyG 中实现
此图卷积操作可以使用 PyTorch geometric(PyG) 消息传递类来实现。三种类方法定义了一个 PyG 消息传递类。它们是 forward(执行前向传递)、 message(构造节点级消息)和 aggregate (聚合)。 message和 forward函数定义如下:
class FeatureSteeredConvolution(MessagePassing):
"""Implementation of FeatureSteeredConvolution
References
----------
.. [1] Verma, Nitika, Edmond Boyer, and Jakob Verbeek.
"Feastnet: Feature-steered graph convolutions for 3d shape analysis."
Proceedings of the IEEE conference on computer vision and pattern recognition. 2018.
"""
...
def forward(self, x, edge_index):
"""Forward pass through a feature steered convolution layer.
Parameters
----------
x: torch.tensor [|V|, in_features]
Input feature matrix, where each row describes
the input feature descriptor of a node in the graph.
edge_index: torch.tensor [2, E]
Edge matrix capturing the graph's
edge structure, where each row describes an edge
between two nodes in the graph.
Returns
-------
torch.tensor [|V|, out_features]
Output feature matrix, where each row corresponds
to the updated feature descriptor of a node in the graph.
"""
if self.with_self_loops:
edge_index, _ = remove_self_loops(edge_index)
edge_index, _ = add_self_loops(edge_index=edge_index, num_nodes=x.shape[0])
out = self.propagate(edge_index, x=x)
return out if self.bias is None else out + self.bias
def _compute_attention_weights(self, x_i, x_j):
"""Computation of attention weights.
Parameters
----------
x_i: torch.tensor [|E|, in_feature]
Matrix of feature embeddings for all central nodes,
collecting neighboring information to update its embedding.
x_j: torch.tensor [|E|, in_features]
Matrix of feature embeddings for all neighboring nodes
passing their messages to the central node along
their respective edge.
Returns
-------
torch.tensor [|E|, M]
Matrix of attention scores, where each row captures
the attention weights of transformed node in the graph.
"""
if x_j.shape[-1] != self.in_channels:
raise ValueError(
f"Expected input features with {self.in_channels} channels."
f" Instead received features with {x_j.shape[-1]} channels."
)
if self.v is None:
attention_logits = self.u(x_i - x_j) + self.c
else:
attention_logits = self.u(x_i) + self.b(x_j) + self.c
return F.softmax(attention_logits, dim=1)
def message(self, x_i, x_j):
"""Message computation for all nodes in the graph.
Parameters
----------
x_i: torch.tensor [|E|, in_feature]
Matrix of feature embeddings for all central nodes,
collecting neighboring information to update its embedding.
x_j: torch.tensor [|E|, in_features]
Matrix of feature embeddings for all neighboring nodes
passing their messages to the central node along
their respective edge.
Returns
-------
torch.tensor [|E|, out_features]
Matrix of updated feature embeddings for
all nodes in the graph.
"""
attention_weights = self._compute_attention_weights(x_i, x_j)
x_j = self.linear(x_j).view(-1, self.num_heads, self.out_channels)
return (attention_weights.view(-1, self.num_heads, 1) * x_j).sum(dim=1)完整实现可在我们的 Colab 中找到。
7、网络架构
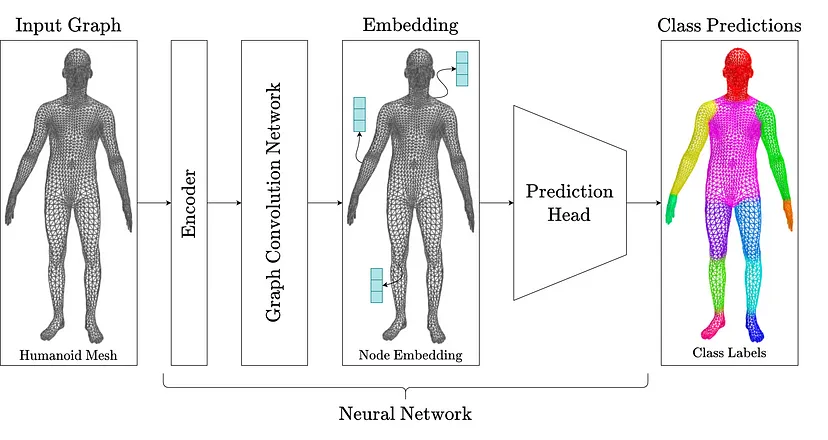
特征引导图卷积构成了我们身体部位标记网络的主干。我们的一般网络架构如下:
- 首先使用多层感知器编码器嵌入节点级输入特征向量(xyz 坐标)。
- 然后,编码后的节点级特征依次通过四个特征引导卷积层。这些层各自聚合来自 12 个注意头(身体部位输出标签的数量)的消息。
- 最后,精炼后的节点级特征通过预测头,即多感知器预测。它为每个节点输出一个类对应关系。
我们训练神经网络以最小化预测和真实分割标签之间的交叉熵损失。该损失通过整个网络反向传播以更新参数。由此产生的训练循环定义如下:
def train(net, train_data, optimizer, loss_fn, device):
net.train()
cumulative_loss = 0.0
for data in train_data:
data = data.to(device)
optimizer.zero_grad()
out = net(data)
loss = loss_fn(out, data.segmentation_labels.squeeze())
loss.backward()
cumulative_loss += loss.item()
optimizer.step()
return cumulative_loss / len(train_data)最后,我们通过计算预测分割标签与真实分割标签之间的准确度来评估网络的性能。计算结果如下所示:
def accuracy(predictions, gt_seg_labels):
"""Compute accuracy of predicted segmentation labels.
Parameters
----------
predictions: [|V|, num_classes]
Soft predictions of segmentation labels.
gt_seg_labels: [|V|]
Ground truth segmentations labels.
Returns
-------
float
Accuracy of predicted segmentation labels.
"""
predicted_seg_labels = predictions.argmax(dim=-1, keepdim=True)
if predicted_seg_labels.shape != gt_seg_labels.shape:
raise ValueError("Expected Shapes to be equivalent")
correct_assignments = (predicted_seg_labels == gt_seg_labels).sum()
num_assignemnts = predicted_seg_labels.shape[0]
return float(correct_assignments / num_assignemnts)8、数据集
我们在 MPI FAUST 数据集 [2] 上训练我们的网络。它包含 100 个严密的人形网格。我们通过标记单个网格来生成分割标签。这些标签通过数据集中包含的地面真实顶点对应关系转移到所有其他网格。我们使用 80 个网格来训练我们的神经网络,并对 20 个网格进行评估。
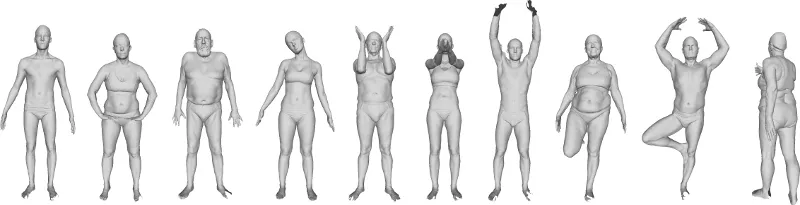
网络在此数据集上的学习过程如下所示。我们看到类别预测收敛到正确的身体部位标签。经过训练的网络在测试数据集上的准确率达到 95%。

9、结束语
在本文中,我们展示了如何将卷积运算从欧几里得空间中定义的规则图推广到具有任意连通性的不规则图。这种推广使我们定义了 GCN,即 CNN 的扩展。与传统 CNN 不同,GCN 可以在不规则图上运行。因此,GCN 可以应用于各种数据——我们所示的网格、分子、社交网络,甚至 2D 图像。
原文链接:Deep Learning on 3D Meshes
BimAnt翻译整理,转载请标明出处





