
NSDT工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器 - REVIT导出3D模型插件 - 3D模型语义搜索引擎 - AI模型在线查看 - Three.js虚拟轴心开发包 - 3D模型在线减面 - STL模型在线切割 - 3D道路快速建模
生成式人工智能席卷了科技行业。 2023 年第一季度,随着数亿用户采用 ChatGPT 和 GitHub CoPilot 等应用程序,对新一代 AI 初创公司的投资高达 1.7B 美元。 技术领先的公司正在争先恐后地制定自己的生成式AI策略,许多公司都在努力将应用程序投入生产。 即使是最前沿的工程团队也面临着以安全、可靠和经济高效的方式培训、部署和保护生成式 AI 模型的挑战。
用于生成式人工智能的新基础设施技术栈正在出现。 我们看到了这一领域的新初创公司的巨大机遇,特别是那些解决与将模型部署到生产、数据管理和模型评估相关的高成本的公司。
1、生成式AI的新基础设施
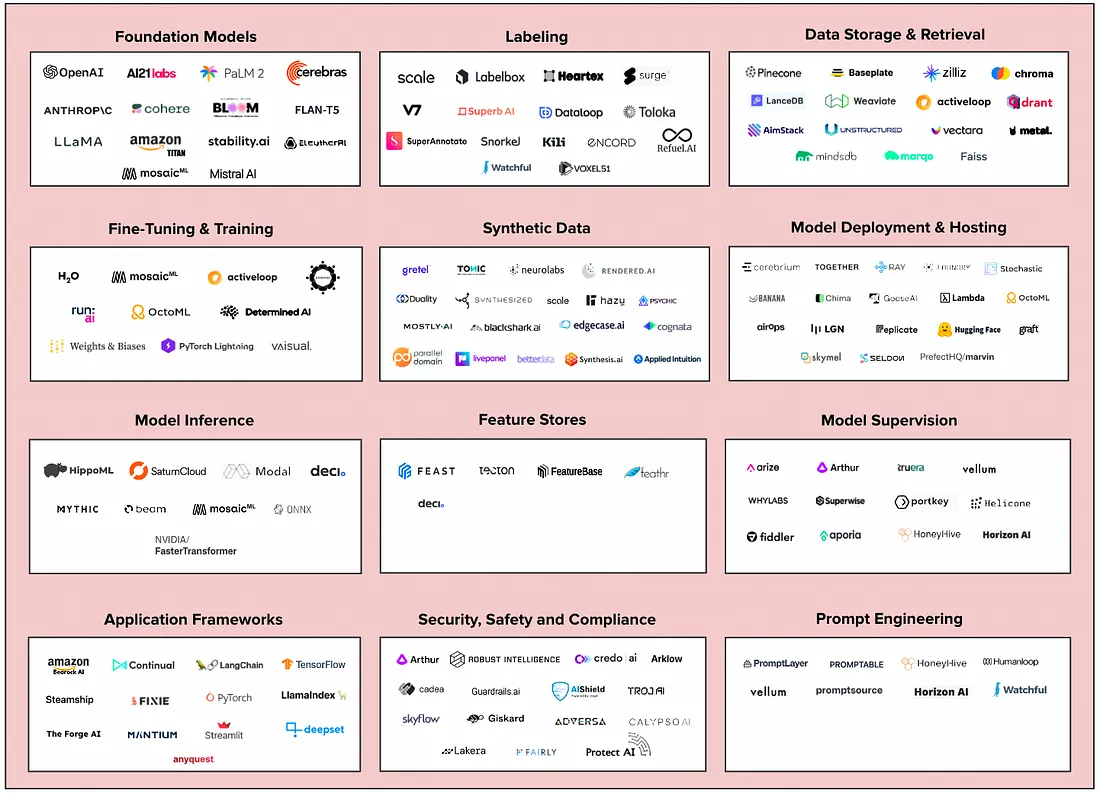
2、基础模型
基础模型(Foundation Models)在海量数据集上进行训练并执行广泛的任务。 开发人员使用基础模型作为强大的生成式 AI 应用程序(例如 ChatGPT)的基础。

选择基础模型时的一个关键考虑因素是开源与闭源,下面是每种模式的优缺点。
开源:
- 优点:开源模型更容易定制,为训练数据提供更高的透明度,并让用户更好地控制成本、输出、隐私和安全。
- 缺点:开源模型可能需要更多的工作来准备部署,并且还需要更多的微调和培训。 虽然开源模型的设置成本可能更高,但从规模上看,与闭源模型相比,公司对成本有更多的控制力,闭源模型的使用情况很难预测,成本可能会失控。
闭源:
- 优点:闭源模型通常提供托管基础设施和计算环境(例如 GPT-4)。 他们还可能提供生态系统扩展来扩展模型功能,例如 OpenAI 的 ChatGPT 插件。 闭源模型还可以提供更多“开箱即用”的功能和价值,因为它们是预先训练的并且通常可以通过 API 访问。
- 缺点:闭源模型是黑匣子,因此用户对其训练数据了解甚少,从而难以解释和调整输出。 供应商锁定还会导致成本难以控制——例如,GPT-4 的使用按提示和完成收费。
我们认为开源对于构建生成式AO应用程序的企业团队来说将是更具吸引力的选择。 正如两位谷歌研究人员所指出的那样,开源模型在社区驱动的创新、成本管理和信任方面具有优势。
3、微调及训练
微调(Fine Tuning)是通过在精选数据集上进行训练来调整现有模型参数的过程,从而为特定用例构建“专业知识”。
通过允许开发人员利用预先训练的大型模型,微调可以提高性能、减少训练时间和成本。
有多种选项可用于微调预训练模型,包括 TensorFlow 和 Pytorch 等开源框架以及 MosiacML 等安全的端到端解决方案。 我们想要强调用于微调的标签工具的重要性—干净、精心策划的数据集可以加快训练过程并提高准确性!
最近,我们看到了很多围绕特定领域的生成式AI模型的活动。 彭博社推出了 BloombergGPT,这是其专有的LLM,用金融行业特定数据进行训练。 Hippocratic 是一家初创公司,建立了自己的LLM,用医疗保健数据训练,为面向消费者的应用程序提供支持,该公司从 Andreessen Horowitz 和 General Catalyst 秘密筹集了 5000 万美元。 Synteny AI 正在构建一个针对蛋白质之间的结合亲和力进行训练的模型,以推动更好的药物发现。 我们认为现有企业处于有利位置,可以根据自己的专有数据微调强大的模型并建立自己的人工智能优势。
4、数据存储和检索
用于长期内存和数据检索的存储是复杂且成本高昂的基础设施挑战,为初创公司提供了构建更有效解决方案的机会。 矢量数据库已成为模型训练以及随后的检索和推荐系统的强大解决方案。 这使得矢量数据库成为最热门的生成式AI基础之一:
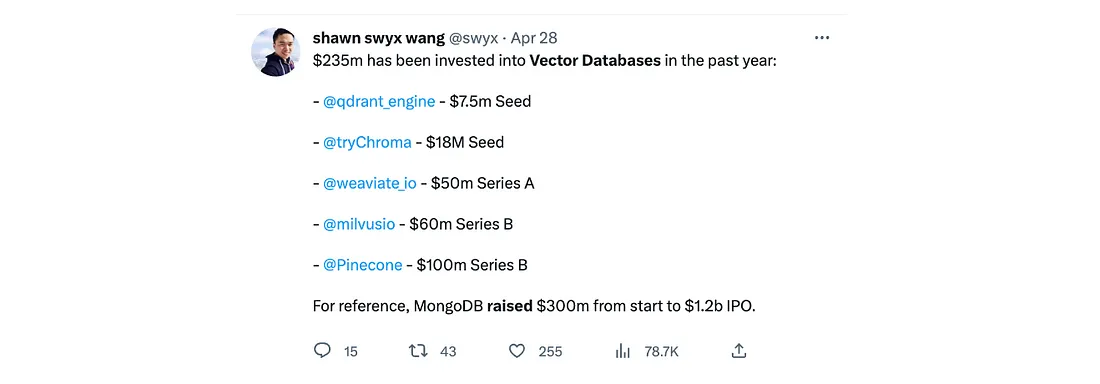
矢量数据库可用于支持各种应用程序,包括语义搜索(一种数据搜索技术)、相似性搜索(使用共享特征查找相似数据)和推荐系统。 它们还赋予模型长期记忆,这有助于减少幻觉(人工智能做出的自信反应,但训练数据无法证明其合理性)。
我们在这里看到了很多创新机会。 无法保证当前从数据库进行语义搜索和检索的方法将继续是最高效(速度和成本)和最有效(覆盖范围)的方法; Cohere 最近发布了其 Rerank 端点—一种无需迁移到矢量数据库的搜索和检索系统。 我们还看到团队使用LLM作为附加到向量数据库的推理引擎。 我们很高兴看到数据存储和检索类别的发展以及更多初创公司的出现。
5、模型监督:监控、可观察性和可解释性
监督相关的三个术语经常互换使用,但是,它们描述了在生产期间和之后评估模型的不同步骤。 监控涉及跟踪性能,包括识别故障、中断和停机时间。 可观察性是理解性能好坏或评估系统健康状况的过程。 最后,可解释性是关于解读输出—例如,解释模型为何做出某个决定。
监督是更传统的 MLOps 堆栈的主要内容,现有企业(例如 Arize)已经开始为部署生成式 AI 模型的团队构建产品。 然而,黑盒、闭源模型可能很难监督,并且在无法访问训练数据的情况下很难解释幻觉。 最近的 YC 批次催生了多家公司来应对这些挑战,包括 Helicone 和 Vellum,这凸显了该领域的早期发展。 值得注意的是,两者都将信息重点放在跟踪延迟和使用情况上,这表明成本仍然是生成式AI团队建设的最大痛点。
6、模型安全、安保和合规性
随着公司将生成式AI模型投入生产,模型的安全性和合规性将变得越来越重要。 为了让企业信任生成式AI模型,他们需要一套工具来准确评估模型的公平性、偏见和毒性(生成不安全或仇恨内容)。 我们还相信,部署模型的团队将需要帮助他们实现自己的护栏的工具。
企业客户还深切关注敏感数据提取、训练数据中毒、训练数据(尤其是第三方敏感数据)泄露等威胁。 值得注意的是,Arthur AI 最近发布了其新产品 Arthur Shield,这是第一个针对 LLM 的防火墙,可防止即时注入(使用恶意输入操纵输出)、数据泄露和有毒语言生成等功能。
我们看到了合规中间件的巨大机遇。 公司需要确保其生成式AI应用程序不会违反合规标准(版权、SOC-2、GDPR 等)。 这对于金融和医疗保健等严格监管行业的团队建设尤其重要。 我们很高兴看到初创公司以及现有企业的创新—例如,我们的牛仔公司 Drata 处于有利地位,可以集成或构建生成式 AI 模型合规性的功能。
7、结束语
我们相信,生成式AI将为公司带来巨大的效率提升,并在基础设施领域创造巨大的新公司机会。 采用的两个最大瓶颈是成本和安全性。 拥有这些核心价值支柱的基础设施初创公司将处于成功的有利地位。
我们还看到开源在生成式AI基础设施中发挥着重要作用。 使用这种模式的初创公司将更容易获得用户的信任,并从开源社区的创新和支持中受益。
原文链接:The New Generative AI Infra Stack
BimAnt翻译整理,转载请标明出处





