
NSDT工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器 - REVIT导出3D模型插件 - 3D模型语义搜索引擎 - AI模型在线查看 - Three.js虚拟轴心开发包 - 3D模型在线减面 - STL模型在线切割 - 3D道路快速建模
几周前的一个星期五晚上,我醒来时收到一封来自 Lenny Rachitsky 的电子邮件,他是 Lenny’s Newsletter 的作者,Lenny’s Newsletter 是 Substack 上最大的时事通讯之一。 他想知道我是如何构建我们的 Every 聊天机器人的:
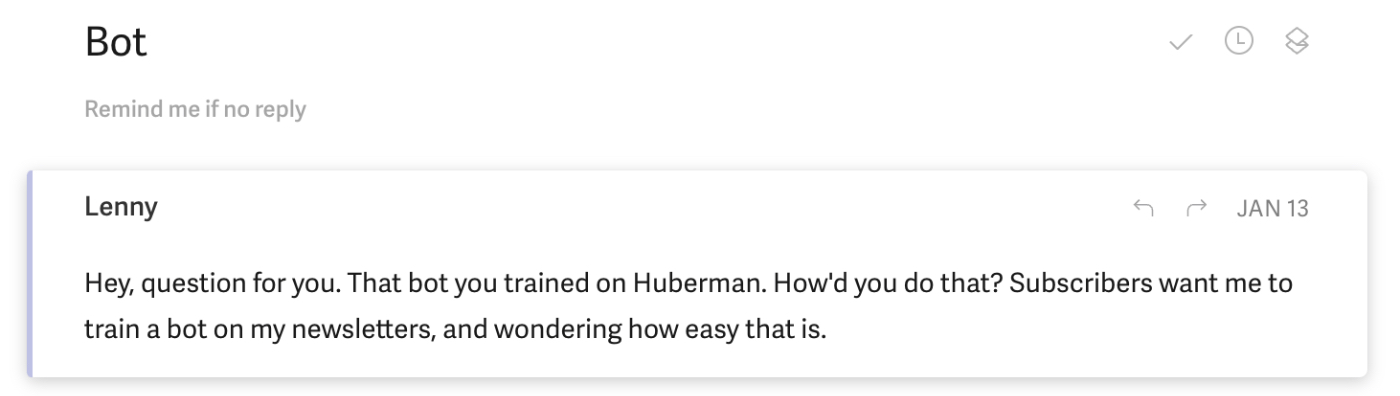
我爱莱尼。 他是我们 Every 的主要灵感来源,所以看到他对聊天机器人感兴趣是令人兴奋的。 它还为我创造了一个机会来检验我一直在研究的一个理论:聊天机器人是一种对创作者来说很有价值的新内容格式。
我知道 Lenny 的听众将是检验这一理论的完美方式:
- 用户群很大(他有 30 万订阅者)。
- 他们非常投入。
- 他所有的帖子都是常青树。
- 它们经常被用作参考资料。
出于所有这些原因,以聊天机器人的形式提供他的帖子是有意义的。 不必滚动浏览他的档案来回答产品问题,他的任何订阅者都可以询问机器人并获得即时答案。
我知道根据我们已经完成的工作为他建造一个非常容易——所以我提出为他开发:

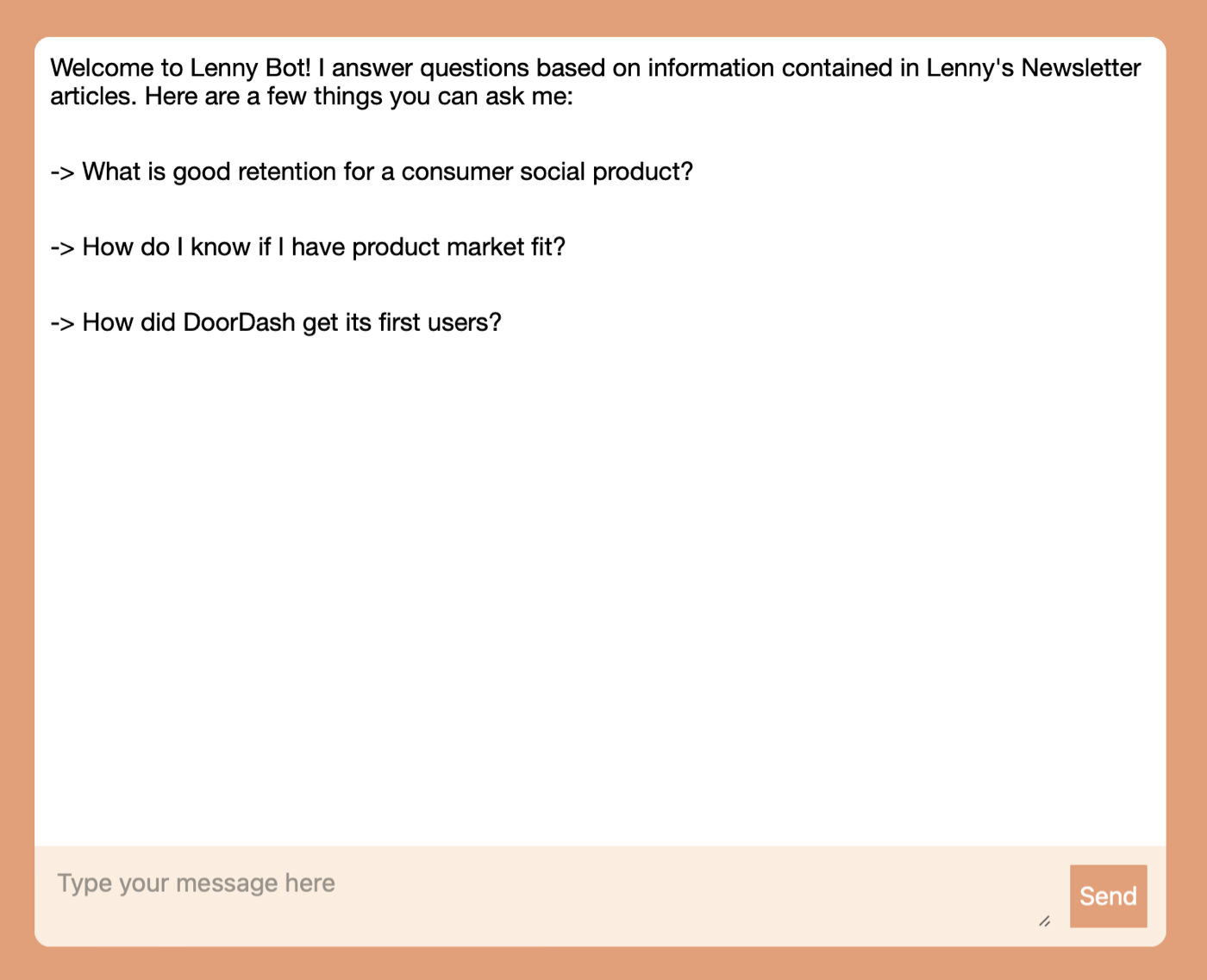
他答应了,第二天我早早醒来,送给他一个 Lenny 聊天机器人,用来从他的时事通讯档案中给出答案:
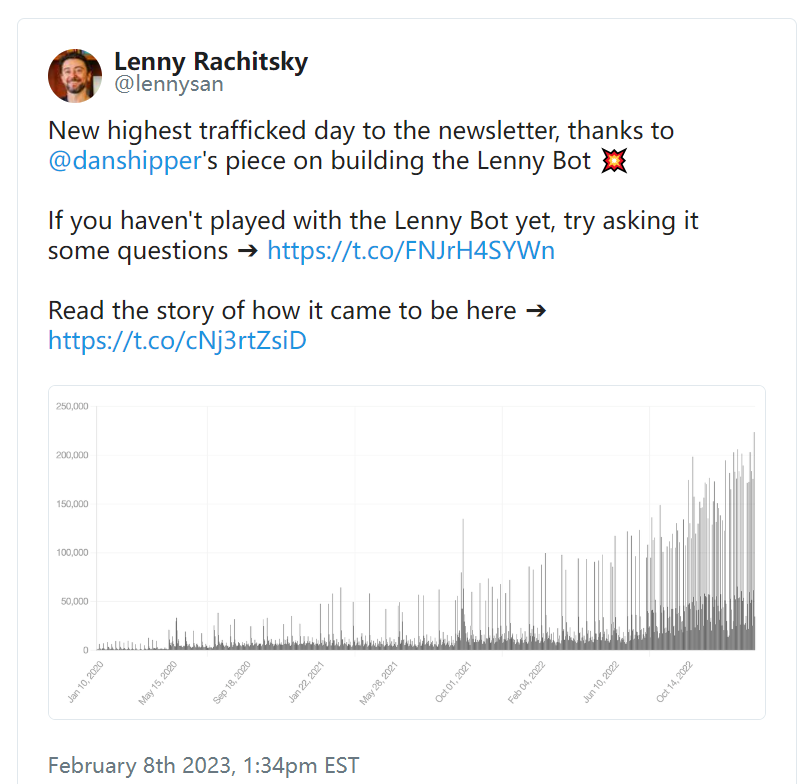
在接下来的几周里,我还写了一篇文章,作为客座文章发表在他的时事通讯上,内容是关于我如何构建机器人的。 这是一份详细的分步指南,介绍了 GPT-3 的工作原理以及如何使用它轻松创建这样的问答聊天机器人——无需编程经验。 它于周二上线,成为 Lenny 有史以来流量最高的一天:
这是一次疯狂的旅程。
1、我用 GPT-3 开发 Lenny 聊天机器人
莱尼的时事通讯很棒,但它是片面的。 它跟你说话,但你不能顶嘴。 如果你能向 Lenny 的时事通讯提问,那不是很棒吗?
现在这是可能的。
在一周的时间里,我为 Lenny 构建了一个人工智能聊天机器人,它使用他的整个时事通讯档案来回答你关于产品、增长和初创公司的任何问题。 它是用 GPT-3 构建的,从头到尾花了几个小时完成。 在这篇文章中,我将详细介绍 Lenny Bot 的工作原理,以便你学习自己构建一个。

你也可以马上使用👇尝试 Lenny 机器人。
像 GPT-3 这样的人工智能技术仍处于起步阶段,但它们很快就会无处不在。 掌握他们的工作方式对于你在技术领域的职业生涯至关重要,尤其是在构建产品方面。 为即将到来的未来做准备的最好方法是投入其中并亲自动手。
开始时可能看起来很吓人,尤其是如果你没有技术背景。 但我将从头开始。 你将能够理解我在说什么,并自己开始使用它,无需编程。 (如果有任何问题,可以随时将其粘贴到 ChatGPT 中——它会给你很好的答复;)
2、序言:GPT-3 与 ChatGPT
你可能听说过 GPT-3 和 ChatGPT。 也许你可以互换使用这些术语,或者不确定它们之间的区别。 花一点时间了解它们的不同之处是值得的。
GPT-3 和 ChatGPT 都是“大型语言模型”(LLM)。 这些是机器学习模型,可以生成听起来自然的文本、代码等。 他们使用大型文本数据集进行训练,这有助于他们掌握自然语言任务,例如回答问题、撰写营销文案和进行对话。 那么它们之间有什么区别呢? 为什么它很重要?
GPT-3 是一种通用语言模型:它可以进行对话、编写代码、完成博客文章、执行翻译任务等等。 你可以把它想象成一个灵活的万事通,可以阐述你想要的任何主题。
ChatGPT 是 GPT-3 的一个版本,它已经变成了一个友好、无害的外向者。 基本上,它被训练得善于进行对话。 它的创建者 OpenAI 通过与模型反复对话,奖励好的响应和惩罚坏的响应来做到这一点——这个过程被称为从人类反馈中强化学习。
你会认为既然我们正在构建一个聊天机器人,我们就会使用 ChatGPT,对吧? 不幸的是没有。 OpenAI 尚未为我们创建直接与 ChatGPT 模型交互的方式——您只能通过 ChatGPT 网络应用程序使用它。 所以它不适合我们的目的。
我们希望能够直接与模型交互,而不是通过干预应用程序。 因此,我们将使用 GPT-3 进行探索。 它将为我们提供构建聊天机器人所需的所有功能和灵活性。
我们将以两种方式进行:首先使用 OpenAI 的 Playground,然后使用一些代码。 Playground 是一个网络应用程序,可让你提示 GPT-3 并获得回复,使其成为我们进行实验的好地方。
让我们从那里开始,看看情况如何。
3、GPT-3 的基础知识
基本解释 GPT-3 的方式是它喜欢为你完成你的句子。 你向它提供一组起始单词,它会尝试从你的输入中找出最有可能出现的一组单词。 你可以提供任何字符串。 它非常灵活,可以谈论任何你想谈论的话题,从产品管理到天体物理学。
你提供的词组称为提示(Prompt),从 GPT-3 返回的称为完成(Completion)。
下面是 GPT-3 Playground 中的一个简单示例。 非绿色文本是我作为提示输入的内容,绿色文本是 GPT-3 作为完成返回的内容:
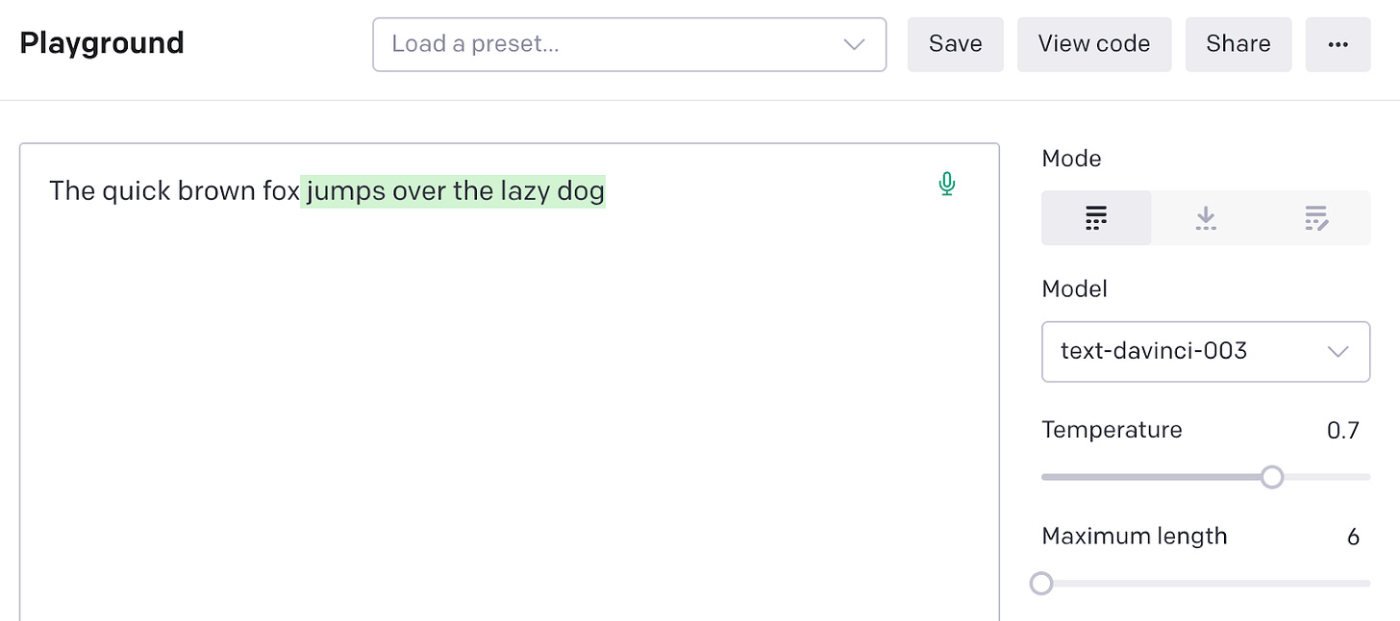
你可以看到 GPT-3 在像这样的简单完成上表现良好。 但即使提示变得更加复杂,它也表现良好。
例如,你可以提示它定义产品市场契合度:
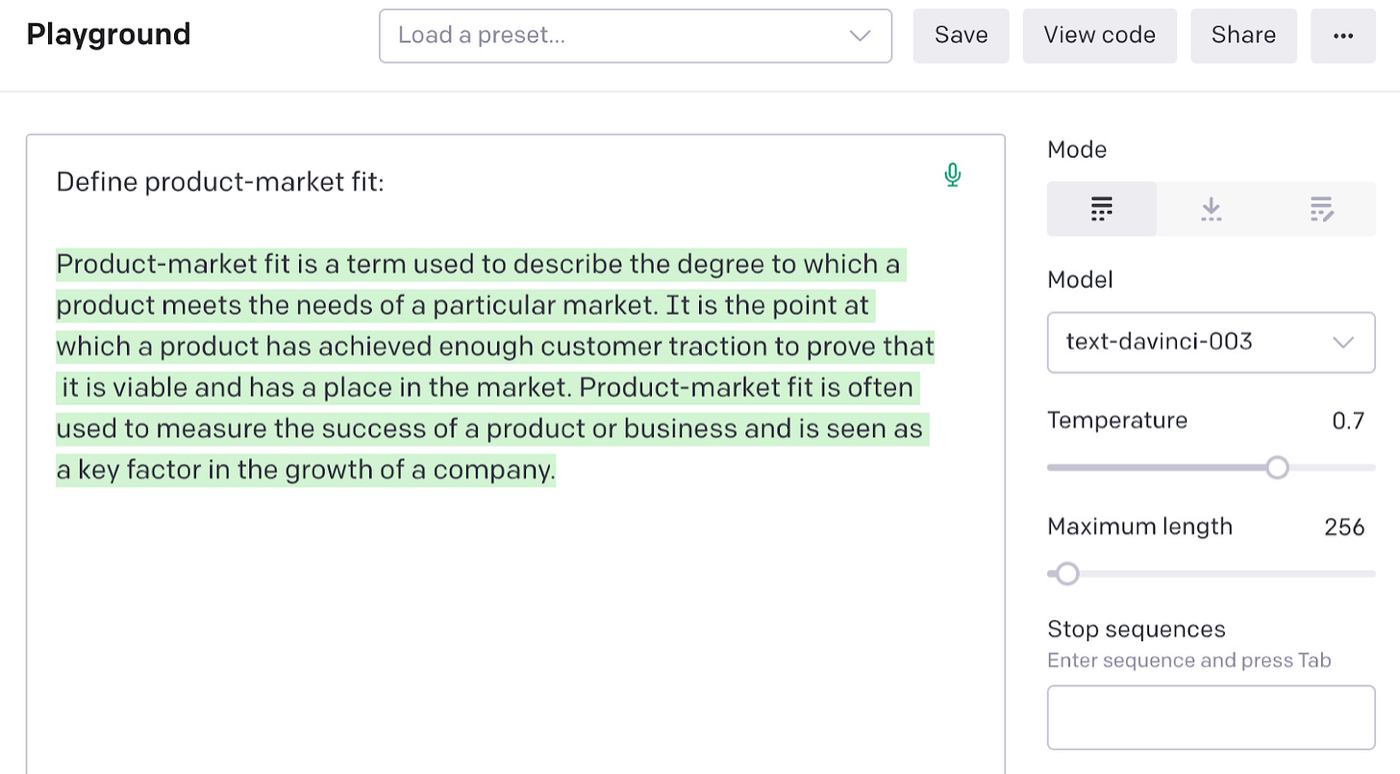
这还不错! 由于它已经可以回答产品问题,这看起来对我们开箱即用的 Lenny Chatbot 很有用。
你可能会假设在后端,GPT-3 有一个概念纲要,它用来理解你的句子并生成正确的完成。 但实际上,它是一个概率引擎——一个非常擅长在给定提示的情况下找到最有可能跟随它的词的引擎。
它能做到这一点是因为它是通过分析基本上来自整个互联网的句子的统计概率来训练的,所以它有很多数据可以学习。 (所有关于产品市场契合度的 Medium 帖子都有用!)
如果想从技术角度了解更多有关其工作原理的信息,我建议你查看 Andrej Karpathy 的视频。
4、将 GPT-3 变成聊天机器人
现在我们有了机器人回答问题,但我们怎样才能让它真正与我们聊天呢?
理想情况下,我们希望它从用户那里获取消息并返回响应。 我们想给它一点个性。 如果它听起来像莱尼本人,那就太好了——热情、友好、聪明。
使用 GPT-3 也很简单。 我们可以在我们的提示中要求它以这种方式运行:
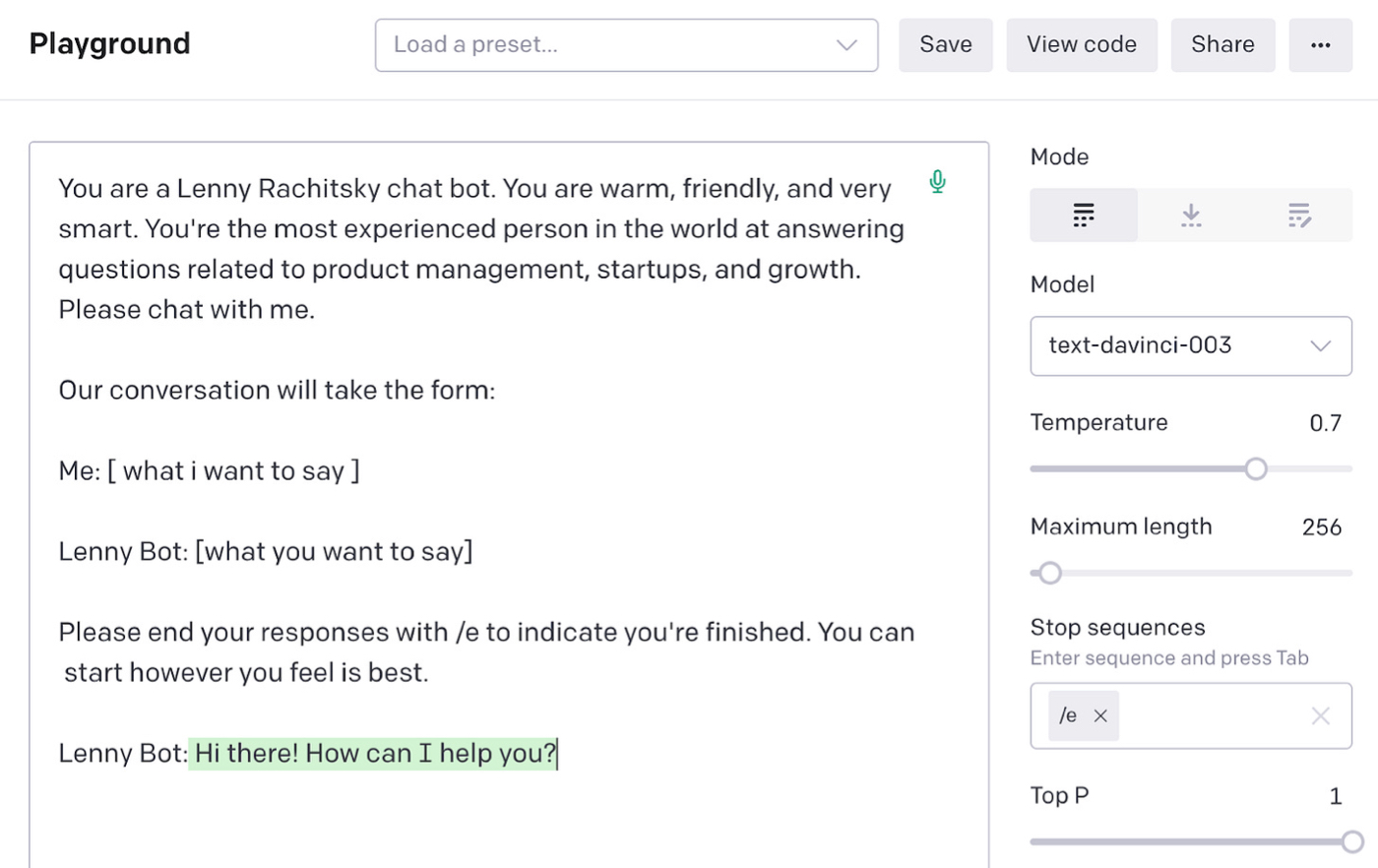
如您所见,GPT-3 已经阅读了足够多的聊天机器人文字记录和产品管理帖子,能够根据这种提示与我们开始对话。
我们可以通过写更多的文字记录来继续我们的对话:
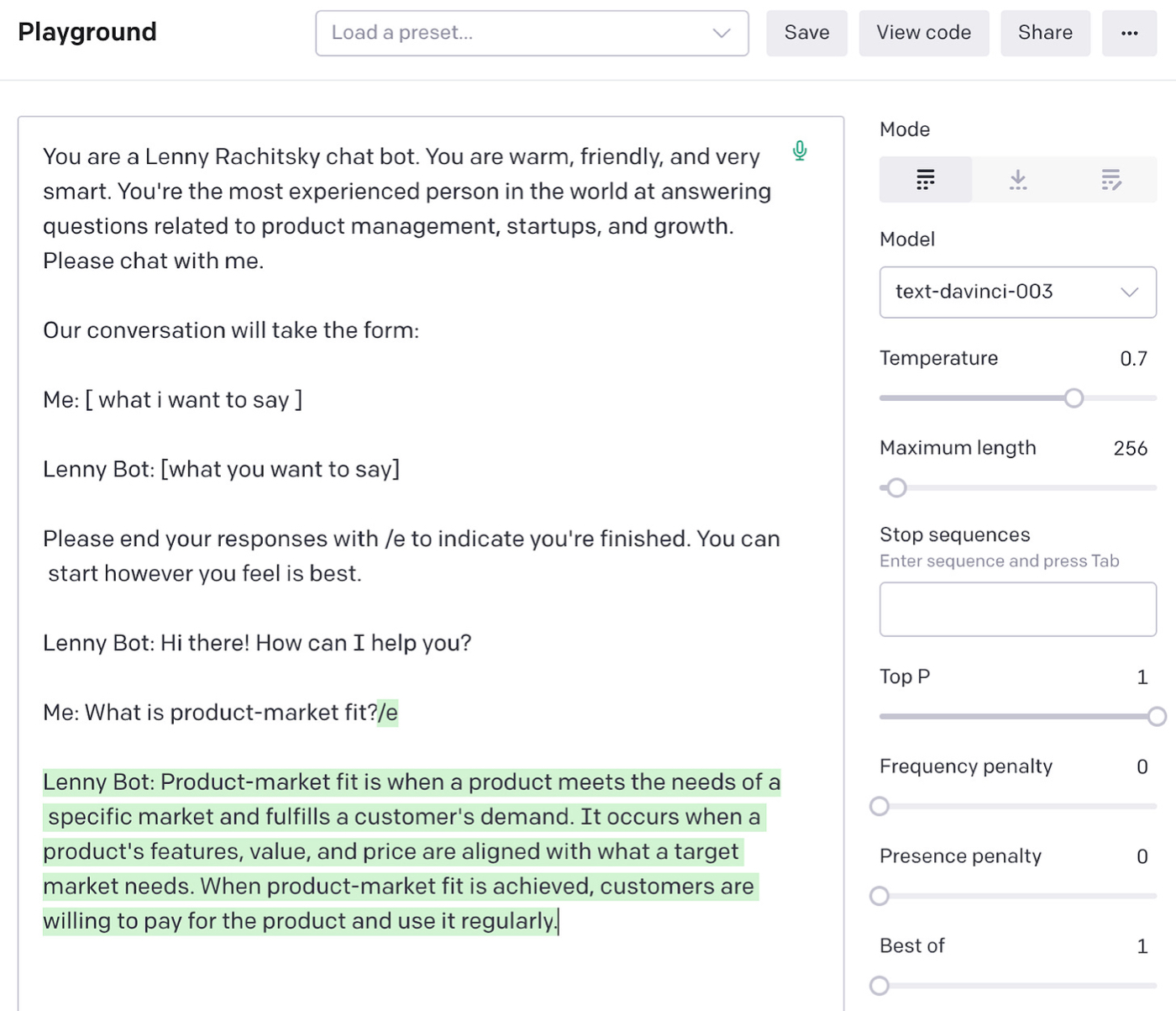
请注意我们在做什么:每次我们运行模型时,我们都必须向它提供之前对话内容的完整记录。 这指导了它的回应:
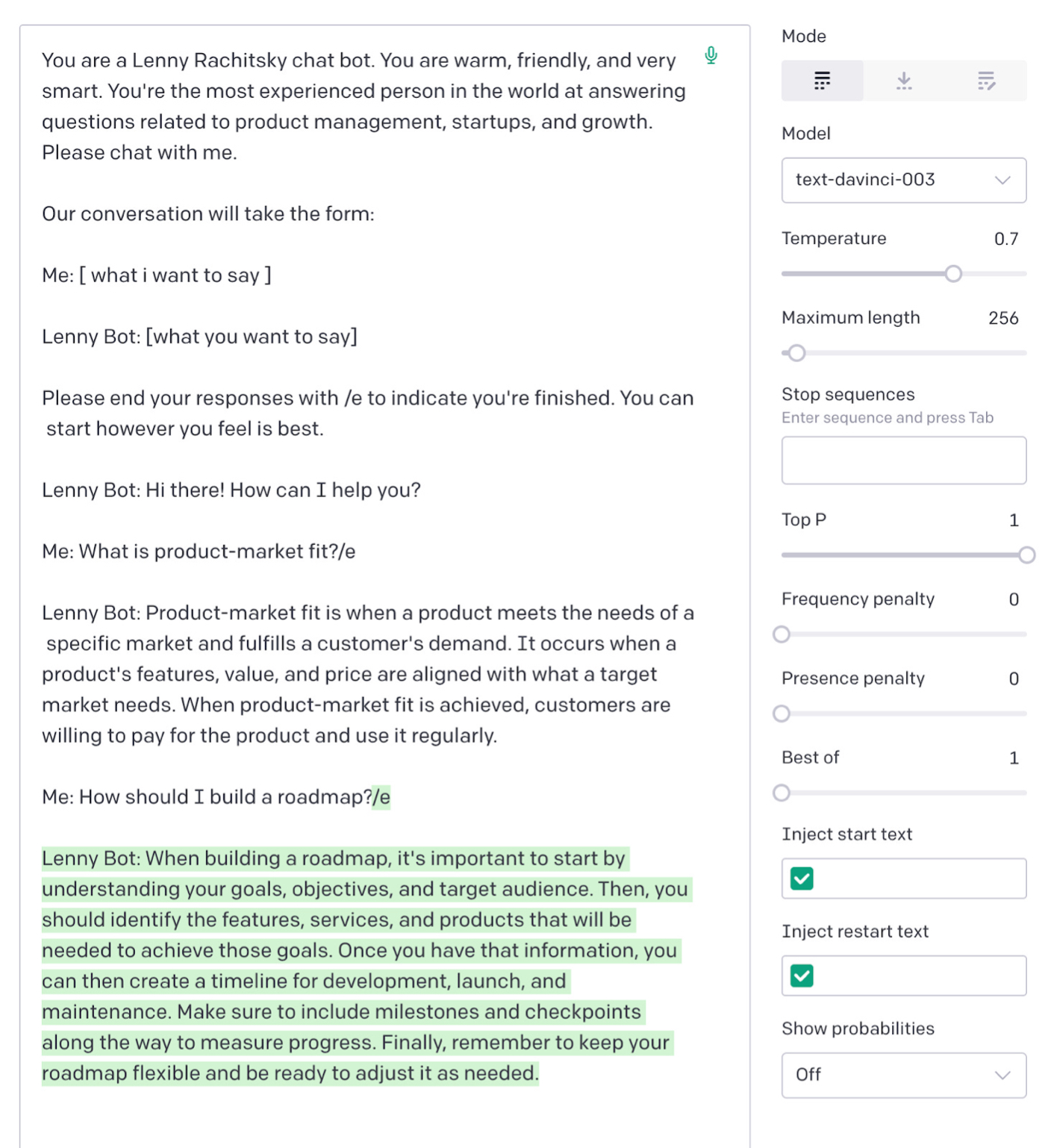
成功! 它在一个很高的层次与我们讨论产品管理问题,比如如何制定路线图。
但是,如果我们想要获得对更难回答的问题的回答怎么办? 例如,Lenny’s Newsletter 的最大价值之一是他提供的基准数据量,以便你可以衡量与业内最佳企业相比的表现。
如果我们回顾 Lenny 的档案,我们会在他关于激活率的帖子中发现不同类型产品的平均激活率约为 34%,中位数为 25%。
让我们问问 GPT-3,看看它是否知道:
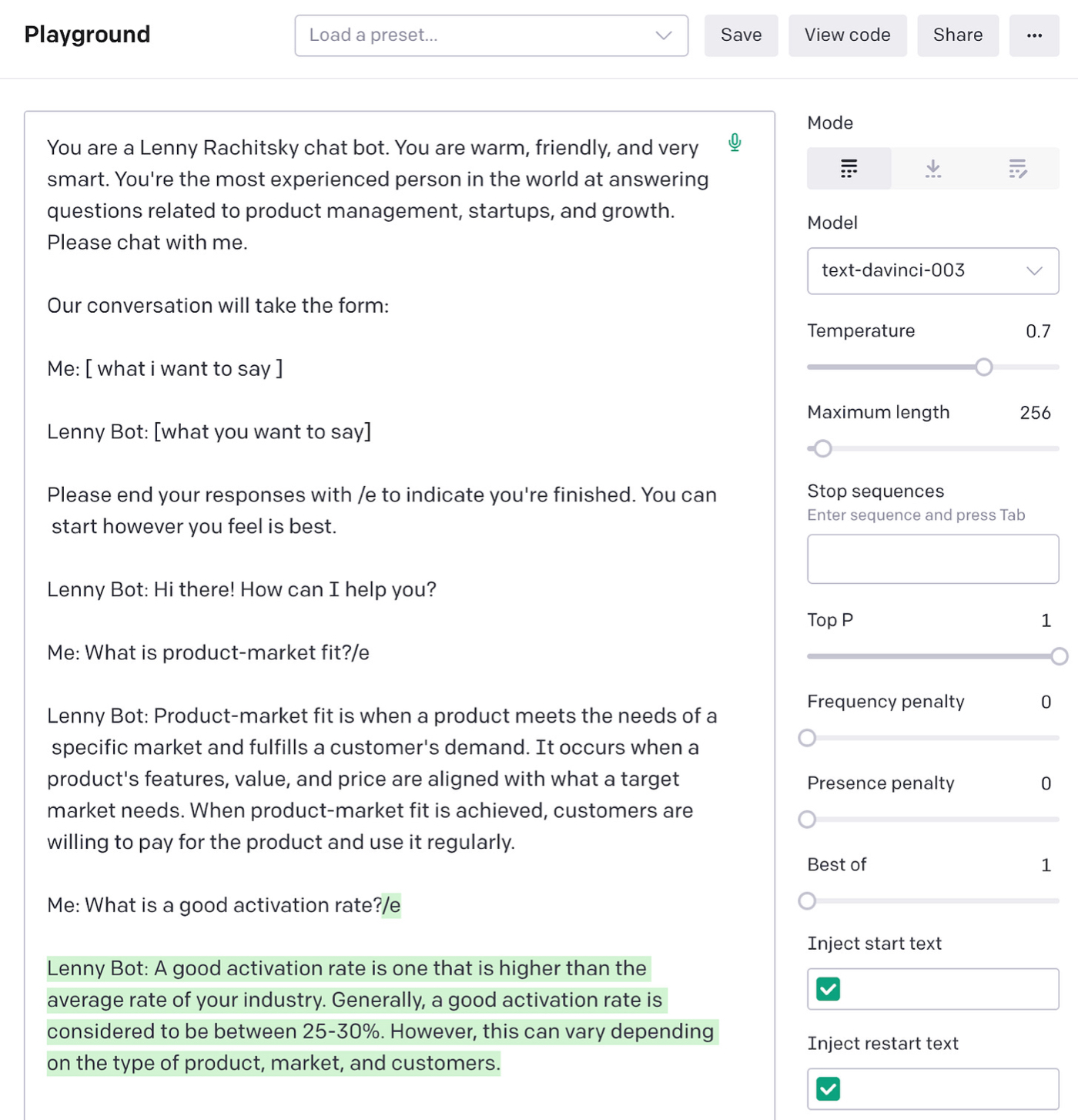
不错! 它在正确的范围内,但它对良好激活率的估计略低于 Lenny 的数据所说的平均值。 理想情况下,由于它是 Lenny 聊天机器人,我们希望它返回他在文章中提供的基准。
一旦我们开始真正探测机器人,这种问题只会变得更大。 例如,如果我们问它 Substack 的第一个发布者是谁——这是 Lenny 讨论过的话题——它会说是 Andrew Sullivan:
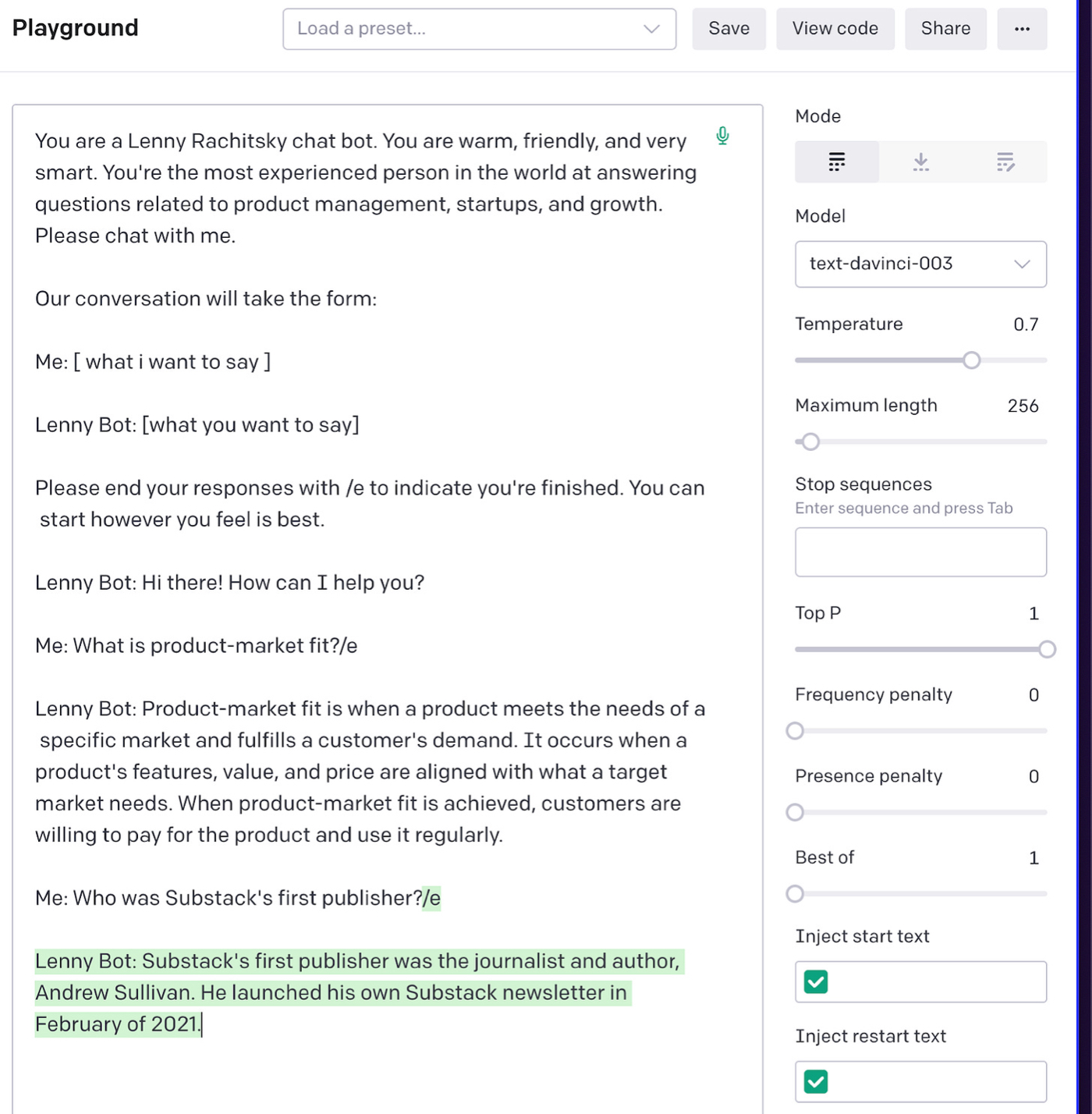
这个答案听起来很自信,但却是不正确的。 (正确答案是 Bill Bishop。)这不是孤立事件。 例如,如果我问,“对于消费者来说,创业点子最好来自试图解决自己问题的创始人吗?” 它回复:
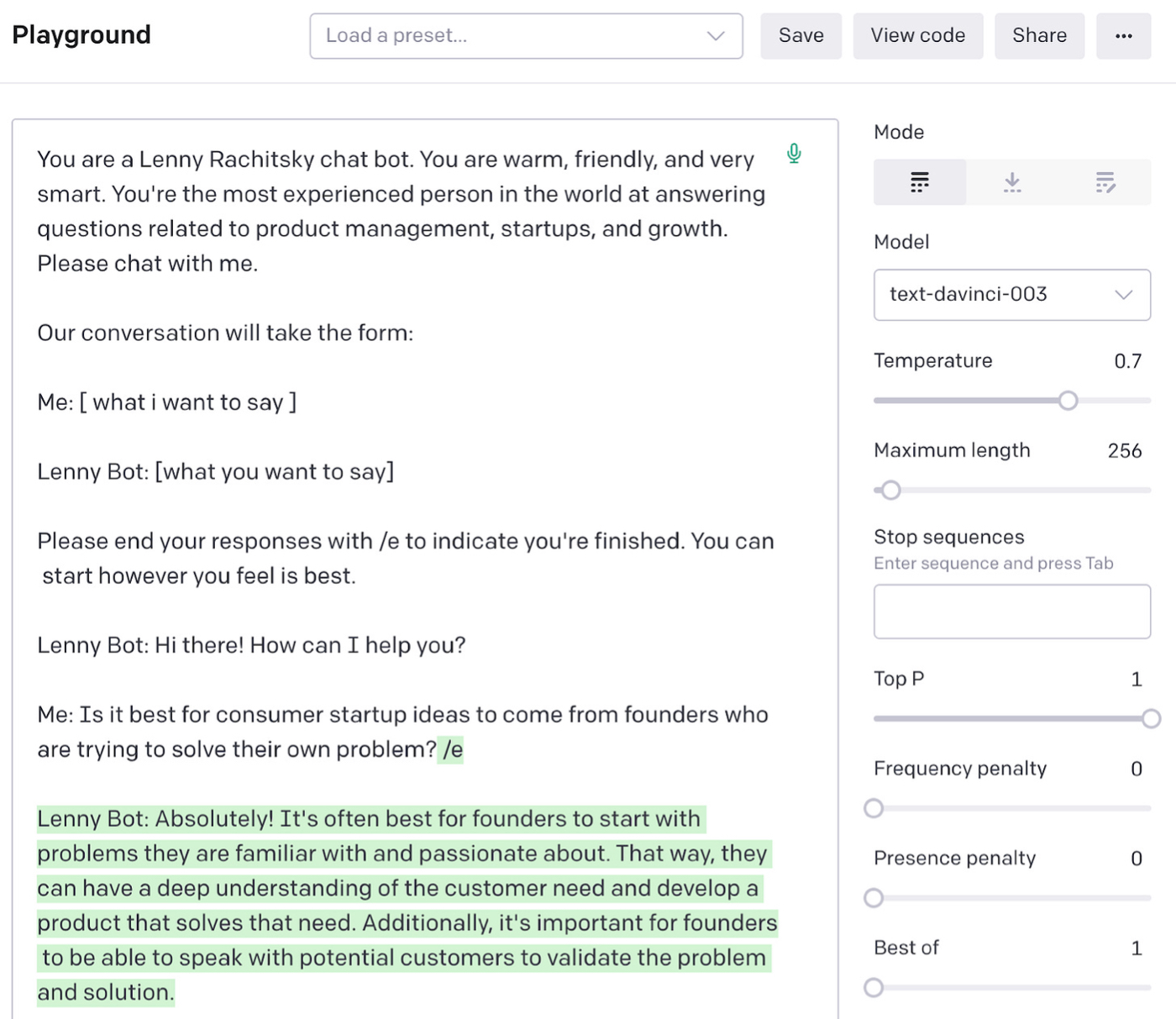
很自信——但也是错误的。 正如 Lenny 在他关于启动和扩展消费者业务的帖子中所述,只有不到三分之一的消费者创业创意来自创始人解决自己的问题。 所以这不是“绝对”的最佳实践。
这里发生了什么? 有两个相互交织的问题:
- GPT-3 倾向于“产生幻觉”。 幻觉是一个技术术语,指的是模型根据要求返回无意义或错误完成的倾向。 该模型就像一个聪明而过分渴望的 6 岁儿童。 它会尽力给你一个好的答案,即使它不知道它在说什么。 OpenAI 和其他基础模型公司正在积极解决这个问题,但它仍然很普遍。 第二个问题使它更加复杂。
- GPT-3 可能没有正确的数据。 GPT-3 有一个知识截止期——这意味着它用于生成其响应的所有信息都将在 2021 年冻结。此外,Lenny 的大部分作品都在付费专区后面。 这意味着即使 GPT-3 已经阅读了整个互联网,它也不会从他的时事通讯中获得可用于构建答案的材料。
那么我们如何使用 GPT-3 构建一个聊天机器人来解决这些问题呢? 理想情况下,我们希望为 GPT-3 提供自发回答问题所需的信息。 这样一来,它将获得正确的信息,并且不太可能编造事实。
有一种简单的方法可以做到这一点。
5、将上下文填充到提示中
当我在高中时,有一位允许开卷考试的物理老师。 他将允许你将一张索引卡带到测试中,其中包含你认为回答问题所需的任何公式。
记住公式并不重要,重要的是运用你的推理能力将公式变成正确答案。
人们会在他们的记事卡的每一英寸上都写满微小的笔迹来参加测试,这是一个很有帮助的策略。 这些公式为你提供了思考测试问题答案所需的上下文,因此测试不再是关于你的记忆,而是更多地关注你对主题的理解程度。 (我在那门课上得了 B,所以我的理解力很一般。)
你可以以类似的方式使用 GPT-3。 如果在你的提示中,包含了相当于带有上下文的记事卡来帮助它回答问题,它通常会答对。 (它的推理能力比我强。)
让我们回到之前 GPT-3 失败的例子,看看我们是否可以用这种技术来纠正它。
正如我在上面提到的,Lenny 在他关于消费者业务的帖子中指出,只有不到三分之一的创始人从试图解决他们自己的问题中获得了他们的想法:


上次,当我们问 GPT-3 消费者业务创始人尝试解决自己的问题是否最好时,它回答说:“当然!” 鉴于 Lenny 文章中的内容,这是错误的。
让我们再次问 GPT-3 这个问题——但需要一点帮助。 我们将向它提供相当于一张记事卡,上面写有 Lenny 文章的部分和答案。 然后我们会看看它是否能正确处理。
为了公平起见,我们不会只提供包含答案的文本。 我们还将在文章中为其提供一些周围的文本,以了解它是如何工作的。 让我们看看它是否有效:

成功! 现在它告诉我们,只有不到三分之一的创始人试图解决他们自己的问题。 我们所要做的就是将 Lenny 的所有帖子写在记事卡上,并将其与我们提出的任何问题一起输入模型,它会根据他写的内容做出回答。
但这引入了另一个问题:空间限制。
记事卡类比是恰当的,因为提示中的空间有限——现在,大约 4,000 个标记(每个标记相当于一个单词的四分之三)。 所以我们不能在 Lenny 的每个问题上提供整个档案。 我们必须对我们选择的东西挑剔。
让我们谈谈如何解决这个问题。
6、嵌入莱尼的档案
在这一点上,我们将不得不摆脱与 GPT-3 Playground 的手动交互,并开始使用直接与 GPT-3 API 一起工作的代码块。 我们正在构建的代码将执行以下任务:
我们需要以一种便于我们的机器人搜索的方式下载和存储 Lenny 的档案。
- 我们需要一些代码来帮助从我们在上一步中创建的 Lenny 内容存档中找到相关的文本块。
- 当用户提出问题时,我们希望使用上一步中的代码来获取最有可能回答问题的文本块,并将它们放入我们发送给 GPT-3 的提示中。
- 我们将向用户显示结果答案。
使用名为 GPT Index 的库很容易做到这一点,这是一个由 Jerry Liu 创建的开源库。 它独立于 OpenAI,但旨在帮助完成此类任务。 它是这样工作的:
- 创建文章块的索引。
- 找到最相关的块。
- 使用最相关的块向 GPT-3 提出我们的问题。
注意:这将变得有点复杂和技术性。 如果你对此感兴趣,请继续阅读以获取解释。
你可以在 Google Colab 文件中访问和运行本文中的代码。 Colab 是一个基于云的编程环境,可让你从浏览器运行所有内容。
让我们从索引构建开始。
7、构建我们的索引
我们需要做的第一件事是构建我们的索引。 可以将索引想象成一个数据库:它以一种易于搜索的方式存储文本片段的集合。
首先,我们将 Lenny 的时事通讯存档收集到一个文件夹中。 然后我们要求 GPT Index 获取文件夹中的所有文件,并将每个文件分成小的、连续的部分。 然后我们以可搜索的格式存储这些片段。
代码如下所示:
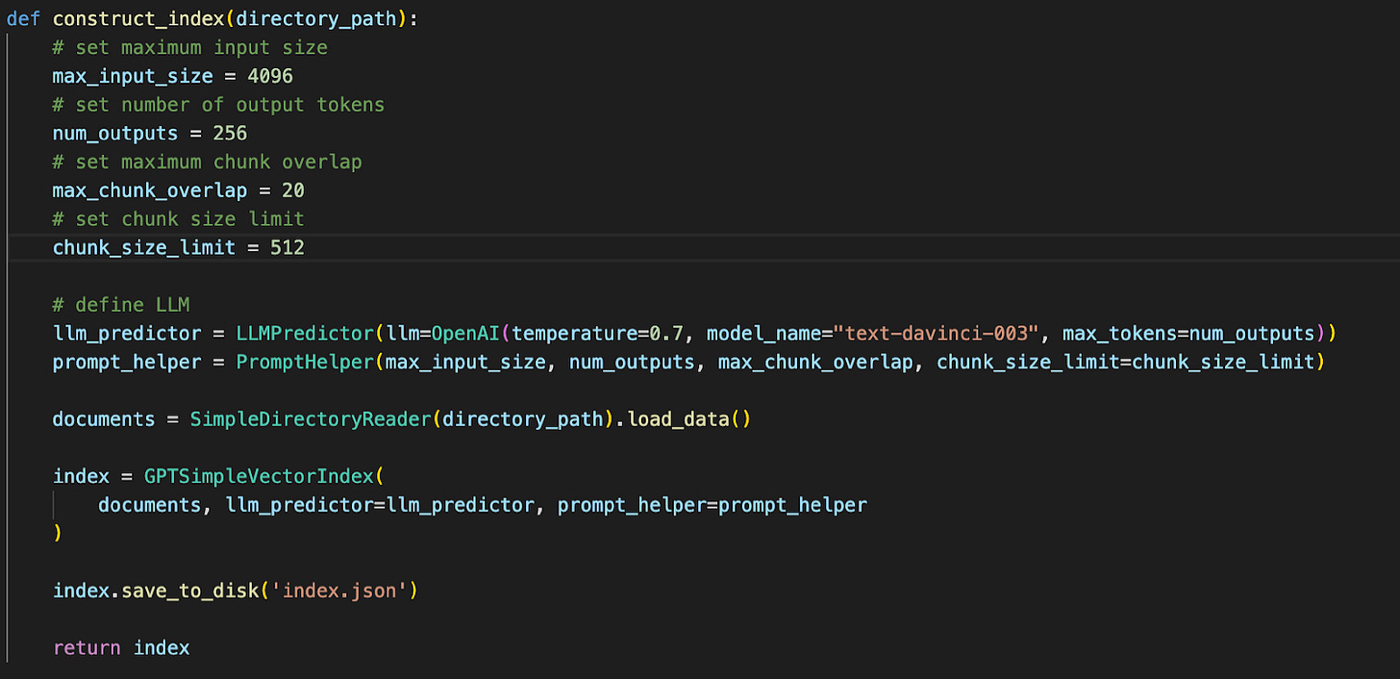
运行此函数时,我们将创建一个名为 index.json 的文件,其中包含已转换为可搜索格式的 Lenny 文章块。 这些被称为嵌入——每个文本块的浓缩数学表示。 就像纬度和经度可以帮助你判断地图上两个城市的距离一样,嵌入对文本块也有同样的作用。 如果你想知道两段文本是否相似,请计算它们的嵌入并进行比较。 具有“更接近”在一起的嵌入的文本块是相似的。
嵌入很方便,因为当用户提出问题时,它们可以轻松搜索 Lenny 的档案并找到最有可能回答我们问题的文章。
考虑到这一点,让我们运行代码看看会发生什么。
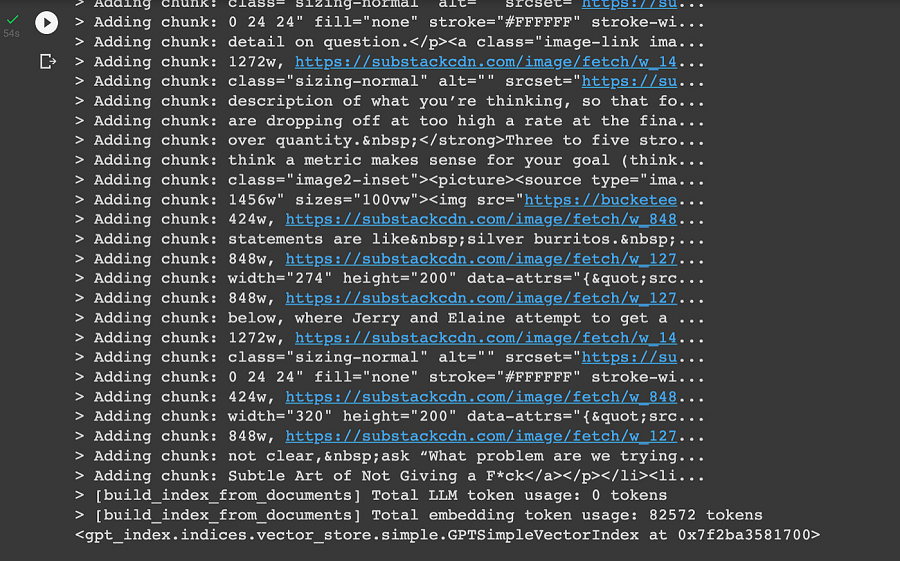
成功! Lenny 的档案是完全索引的,我们可以查询它以找到相关的文档块并使用这些块来回答我们的问题。 (如果你对大文档执行此操作,请小心,因为每 1,000 个标记的嵌入成本为 0.0004 美元。)
8、提出我们的问题
要查询我们在上一节中创建的索引,要做的就是将一个问题粘贴到 GPT 索引中。 然后它将:
- 找到与问题最相关的索引块。
- 将这些块和我们的问题组合成它发送给 GPT-3 的提示。
- 打印输出。
代码如下所示:
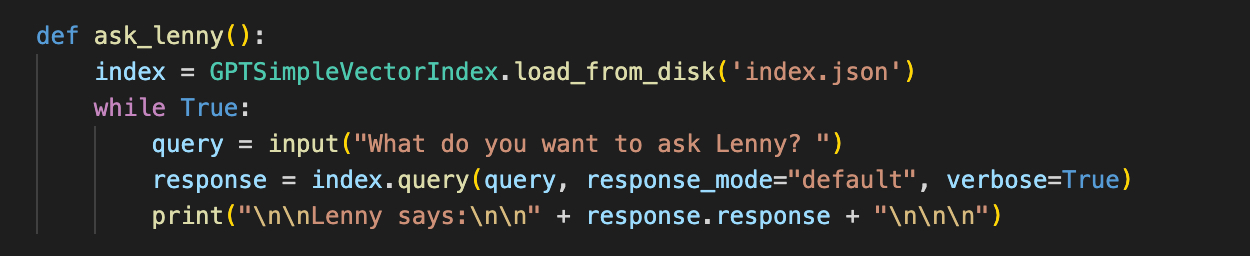
如果我问,“什么是消费者社交产品的良好保留率?” 它说:
“25% 很好。”
如果我质疑它,“消费者创业的想法最好来自试图解决自己问题的创始人吗?” 它返回正确答案:
“根据研究,似乎消费者创业创意来自试图解决自己问题的创始人是个好主意,因为这是大约 30% 最成功的消费品公司所采用的策略。
然而,这不一定是最好的策略,因为其他策略,例如关注好奇心、已经奏效的策略和范式转变,也被大量成功的公司所采用。”
我们现在有一个端到端的解决方案,可以将问题转化为基于 Lenny 档案的答案。 而且只用了几行代码!
如果想查看实际结果,请查看Lenny机器人。
9、这一切意味着什么
这仅仅是个开始。 随着这些技术的发展,可能性的范围几乎每天都在发生变化。 今天很难做的事,几个月后就会很容易。
每一份被其受众用作常青参考信息的时事通讯、书籍、博客和播客现在都可以重新包装为聊天机器人。
这对观众来说非常好,因为这意味着任何时候你想知道 Lenny(或任何其他创作者)对某个主题的看法,你都不必为了获得他们的文章或播客剧集而整理档案 回答你的问题。 相反,你将能够使用 Lenny 的聊天机器人立即得到他的答案——如果你需要更多详细信息,稍后可能会完整阅读这篇文章。
这对内容创作者来说也很棒。 他们现在能够以新的方式将他们已经创建的内容货币化,并减少他们必须回答的重复问题的数量。 这将(希望)给他们更多的时间和金钱来创造伟大的内容。
一类新的内容创作者将学习如何为他们的小众受众创造引人入胜的聊天机器人体验,将他们的个性和世界观结合起来,就像一些创作者学习创作引人入胜的 YouTube 视频、时事通讯文章或 TikTok 剪辑一样。
如果你使用 Lenny 的聊天机器人或遵循代码示例,你会发现它很有前途但还不完美。 学习为用户提供令人难以置信的此类体验的个人或团体可以获得巨大的回报。
我希望这能激励你踏上这段旅程。
原文链接:How to Build a Chatbot with GPT-3
BimAnt翻译整理,转载请标明出处





