
NSDT工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器 - REVIT导出3D模型插件 - 3D模型语义搜索引擎 - AI模型在线查看 - Three.js虚拟轴心开发包 - 3D模型在线减面 - STL模型在线切割 - 3D道路快速建模
GPT-SoVITS 是一种语音合成模型,于 2024 年 2 月 18 日发布。它支持使用参考音频进行零样本语音合成,并且可以进行微调以提高性能。
GPT-SoVITS 的功能特性包括:
- Zero-Shot TTS:零样本语音合成,输入 5 秒音频样本即可立即合成语音。
- Few-Shot TTS:小样本语音合成,仅使用 1 分钟的训练数据对模型进行微调,以增强语音相似度和真实感。
- 跨语言支持:支持从训练数据中推断不同语言,目前支持英语、日语和中文。
- WebUI 工具:提供语音和伴奏分离、自动训练集分割、中文 ASR(自动语音识别)和文本标记的集成工具,支持创建训练数据集和构建 GPT/SoVITS 模型。
2、先前的研究
GPT-SoVITS 基于语音合成和语音转换器模型的最新研究。
VITS 是 2021 年 1 月发布的端到端语音合成模型。与将文本转换为中间表示的两阶段 TTS 系统相比,传统的端到端语音合成模型性能较低。VITS 通过引入 Flow 模型、结合规范化流以消除说话者特征以及使用对抗性训练过程来提高语音合成性能。
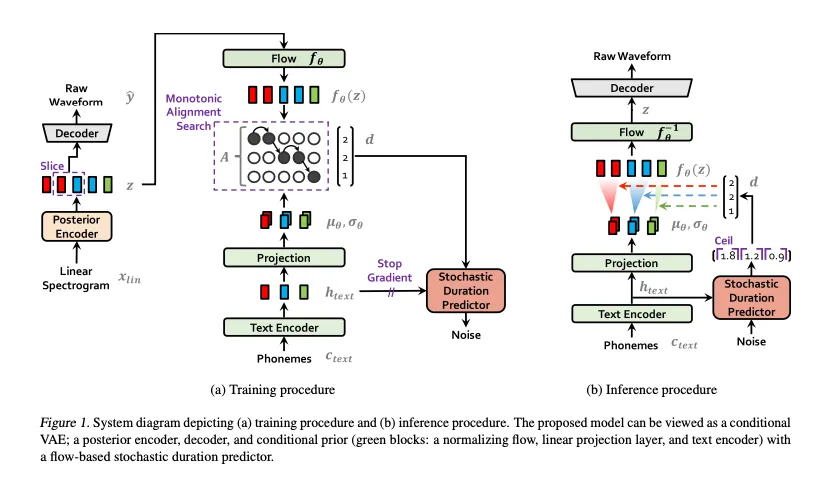
VITS2 是一个端到端语音合成模型,于 2023 年 7 月发布,VITS 的开发者之一 Jungil Kong 是第二作者。它用 Transformer Flow 取代了 VITS 中的 Flow 模型。传统的端到端语音合成模型面临着不自然、计算效率和对音素转换的依赖等问题。VITS2 提出了比 VITS 更好的架构和训练机制,减少了对音素转换的强烈依赖。
Bert-VITS2 是 2023 年 9 月发布的端到端语音合成模型,它用多语言 BERT 取代了 VITS2 中的文本编码器。
SoVITS(SoftVC VITS)是 2023 年 7 月发布的模型,它用 SoftVC 的内容编码器取代 VITS 中的文本编码器,实现类似于 RVC 的 Speech2Speech 合成,而不是 Text2Speech。
GPT-SoVITS 基于这些连续的改进,将 VITS 的高质量语音合成与 SoVITS 的零样本语音自适应功能相结合。
3、GPT-SoVITS架构
GPT-SoVITS 是一种基于 token 的现代语音合成模型。它使用 seq2seq 模型生成声学 token,然后将这些声学 token 转换回波形以获得合成的语音波形。
GPT-SoVITS 由以下模型组成:
- cnhubert:将输入波形转换为特征向量。
- t2s_encoder:从输入文本、参考文本和特征向量生成声学 token。
- t2s_decoder:从生成的声学 token 合成声学 token。
- vits:将声学 token 转换为波形。
GPT-SoVITS 的输入如下:
- text_seq:要合成语音的文本。
- ref_seq:来自参考音频文件的文本。
- ref_audio:参考音频文件的波形。
使用 g2p 将 text_seq 和 ref_seq 转换为音素后,它们将在 symbol.py 中转换为 token 序列。对于日语,g2p 转换不带重音符号。对于中文,还使用了 BERT 嵌入(ref_bert 和 text_bert),但对于日语和英语,这些嵌入是用零填充的。
ref_audio 末尾附加了 0.3 秒的静音,然后使用 cnhubert 将其转换为名为 ssl_content 的特征向量。
t2s_encoder 将 ref_seq、text_seq 和 ssl_content 作为输入并生成声学 token。
t2s_decoder 将这些声学 token 作为输入,并使用 seq2seq 模型输出后续声学 token。此输出对应于合成文本的声学 token。 token 有 1025 种,其中 1024 种表示 EOS(End of Sequence)。使用 top-k 和 top-p 采样方法逐个输出 token,当出现 EOS token 时停止。
最后将声学 token 输入 vits,生成语音波形。
4、音素转换
在 GPT-SoVITS 中,日语文本使用 pyopenjtalk 中的 g2p 转换为音素,英语文本使用 g2p_en 转换。
对于日语,文本“ax株式会社ではAIの実用化のための技术を开発しています。”会产生音素“e i e cl k U s u k a b u sh I k i g a i sh a d e w a e e a in o j i ts u y o o k a no t a me n o g i j u ts u o aihatsusush iteimas U .”。与典型的 g2p 不同,它包含标点符号。
对于英语,输入“Hello world.我们正在测试语音合成。”结果为音素“HH AH0 L OW1 W ER1 L D . W IY1 AA1 R T EH1 S T IH0 NG S P IY1 CH S IH1 N TH AH0 S AH0 S 。”在 g2p_en 中,使用 cmudict 词典将单词转换为音素,对于单词如果在字典中找不到该词,则使用神经网络进行音素转换。
5、零样本推理
要执行零样本推理,请在 WebUI 中选择 1-GPT-SoVITS-TTS,选项卡 1C-inference。选中“打开 TTS 推理 WEBUI”复选框,片刻之后,将打开一个新窗口。
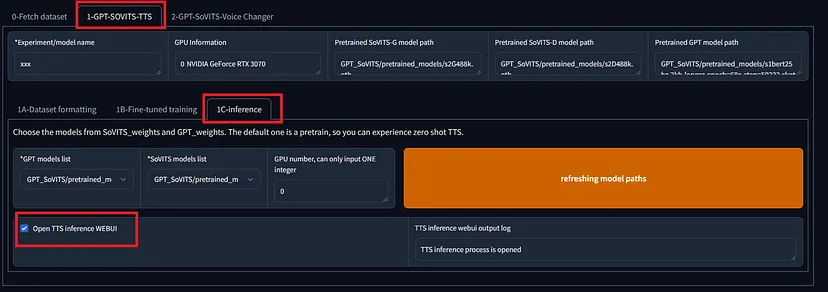
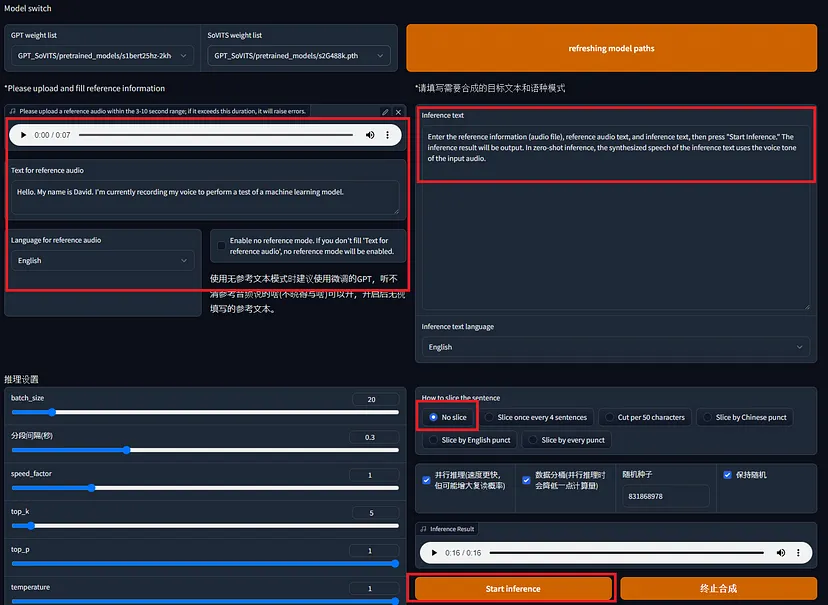
输入参考音频文件、参考音频文本和推理文本,然后按“开始推理”。在零样本推理中,推理文本的合成语音使用输入音频的语音音调。
6、自定义训练
如果语音具有鲜明的特征,即使使用零样本推理,也可以获得相当好的语音。为了获得更高的准确率,需要进行微调。
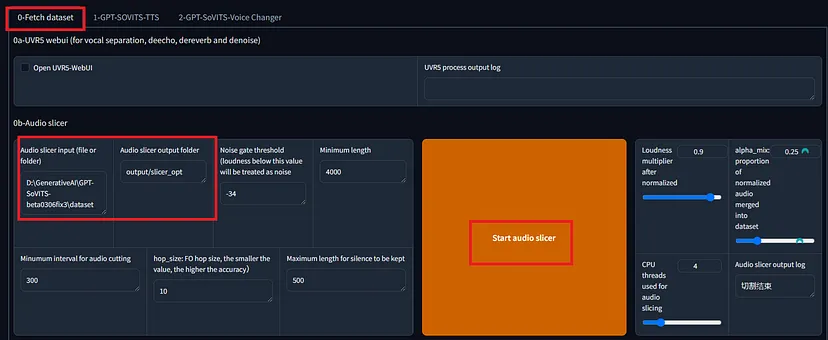
首先,创建一个数据集。使用预处理部分中的“0-Fetch Dataset”中的工具指定音频文件的路径并分割音频。
接下来,使用 ASR 工具进行语音识别以生成参考文本。通过选择 Faster Whisper,您可以指定语音识别的语言。
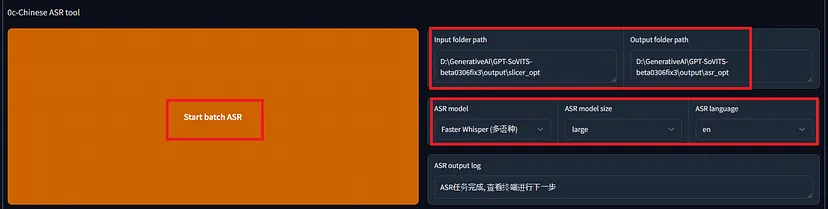
输出列表文件的格式如下:
The TTS annotation .list file format:
```
vocal_path|speaker_name|language|text
```
Language dictionary:
- 'zh': Chinese
- 'ja': Japanese
- 'en': English
Example:
```
D:\GPT-SoVITS\xxx/xxx.wav|xxx|en|I like playing Genshin.
```创建数据集后,在选项卡 1-GPT-SOVITS-TTS 的子选项卡 1A-数据集格式化中格式化训练数据。指定文本注释文件和训练数据音频文件的目录,然后单击“开始一键格式化”
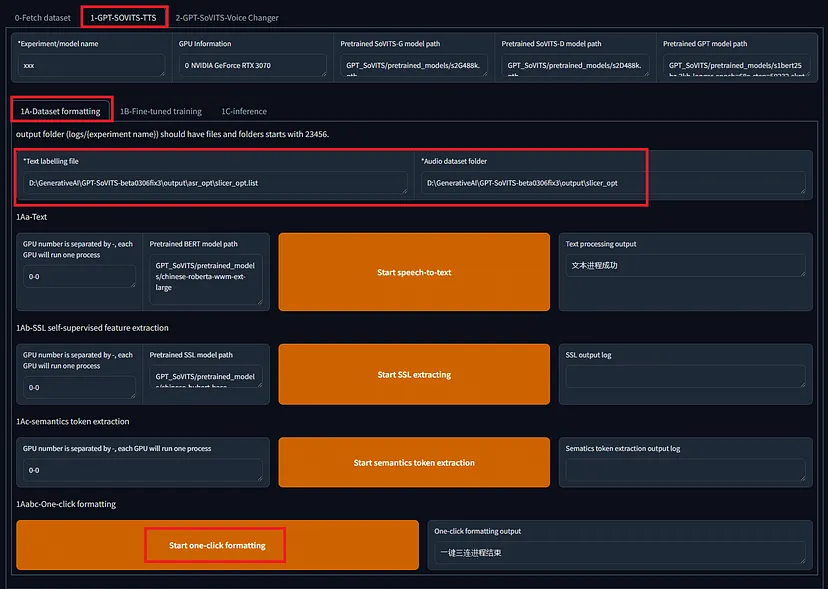
在下一个选项卡 1B-微调训练中,训练 SoVITS 和 GPT 模型。
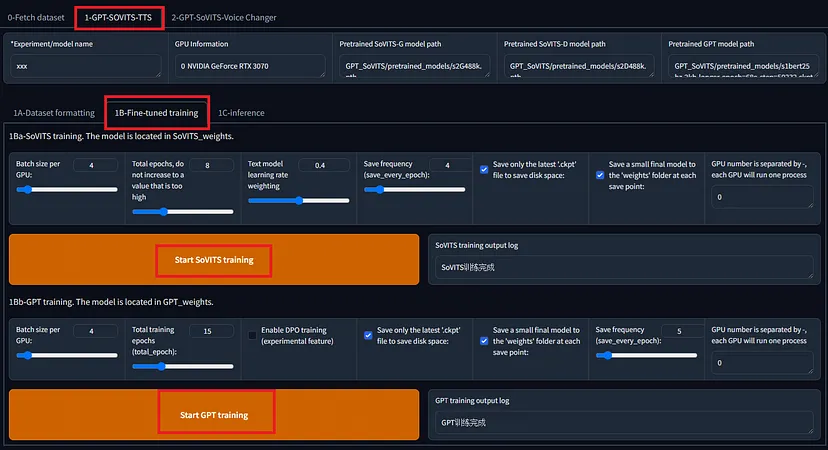
在 RTX 3080 上训练大约 1 分钟的音频,对于 SoVITS 在 8 个 epoch 时大约需要 78 秒,对于 GPT 在 15 个 epoch 时大约需要 60 秒。训练后的模型大小为 GPT 151,453 KB,SoVITS 82,942 KB。
训练后,像之前一样打开推理 WebUI,选择新训练的模型,然后执行语音合成。默认温度为 1.0,但将其降低到 0.5 左右似乎可以提供更高的稳定性。
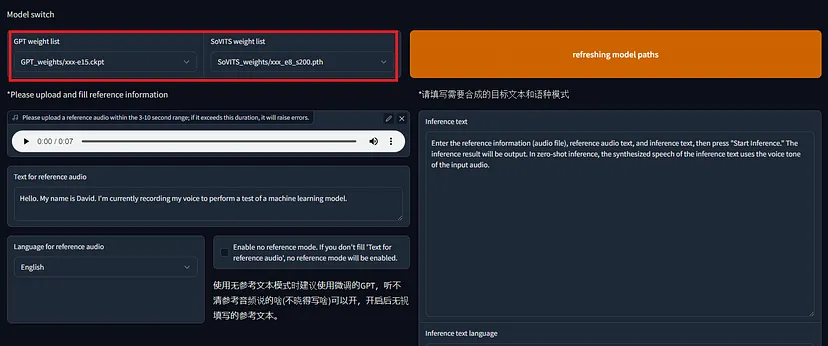
7、转换为 ONNX
导出到 ONNX 的代码包含在官方存储库中。但是,此代码不包含导出到 cnhubert 和推理代码,因此需要自行实现。
此外,与 torch 版本相比,ONNX 版本的输出音频精度较低。经过调查,发现 ONNX 和 torch 版本之间存在以下差异,需要实施:
- 在采样中将 exp 引入 multinomial_sample_one_no_sync。
- 更正 SinePositionalEmbedding 中的 pe。
- 在 vq_decode 中引入 noise_scale。
- 删除 first_stage_decode 中的 EOS。
此外,由于 topK 和 topP 嵌入在模型中并且无法从外部控制,因此将它们添加到输入中会很方便。
包含这些调整的存储库可在这个链接中找到。
8、结束语
通过使用 GPT-SoVITS,我们确认它可以比我们在此描述的 VALLE-X 执行更高质量的语音合成。微调时间比预期的要短,因此非常实用。此外,推理时间短,可以进行 CPU 推理,这表明它将来会得到广泛应用。
原文链接:GPT-SoVITS: A Zero-Shot Speech Synthesis Model with Customizable Fine-Tuning
BimAnt翻译整理,转载请标明出处





