
NSDT工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器 - REVIT导出3D模型插件 - 3D模型语义搜索引擎 - AI模型在线查看 - Three.js虚拟轴心开发包 - 3D模型在线减面 - STL模型在线切割 - 3D道路快速建模
Falcon、(Open-)LLaMA、X-Gen、StarCoder 或 RedPajama 等开源 LLM 在最近几个月取得了长足的进步,在某些用例中可以与 ChatGPT 或 GPT4 等闭源模型竞争。 然而,以高效和优化的方式部署这些模型仍然面临挑战。
在这篇博文中,我们将展示如何将开源 LLM 部署到 Hugging Face Inference Endpoints,以及如何流式传输响应并测试端点的性能。 那么让我们开始吧!
在开始之前,让我们回顾一下有关推理端点的知识。
1、什么是推理端点
Hugging Face Inference Endpoints 提供了一种简单、安全的方法来部署机器学习模型以用于生产。 推理端点使开发人员和数据科学家等能够在无需管理基础设施的情况下创建人工智能应用程序:将部署过程简化为几次点击,包括通过自动扩展处理大量请求、通过规模为零来降低基础设施成本以及提供高级安全性。
以下是 LLM 部署的一些最重要的功能:
- 轻松部署:只需点击几下即可将模型部署为生产就绪的 API,无需处理基础设施或 MLOps。
- 成本效率:受益于自动扩展到零容量,通过在端点不使用时缩小基础设施来降低成本,同时根据端点的正常运行时间付费,确保成本效益。
- 企业安全性:在只能通过直接 VPC 连接访问的安全离线端点中部署模型,由 SOC2 类型 2 认证支持,并提供 BAA 和 GDPR 数据处理协议以增强数据安全性和合规性。
- LLM 优化:针对 LLM 进行优化,通过分页注意力实现高吞吐量,通过自定义转换器代码实现低延迟,并通过文本生成推理实现闪存注意力功能
- 全面的任务支持:对🤗 Transformers、Sentence-Transformers 和 Diffusers 任务和模型的开箱即用支持,以及轻松自定义以启用扬声器分类或任何机器学习任务和库等高级任务。
点击这里可以开始使用推理端点。
2、Falcon 40B部署说明
首先,你需要使用设置了付费方式的用户或组织帐户登录(可以在此处添加付款方式),然后通过 这里 访问推理端点。
然后,单击“新端点”。 选择存储库、云和区域,调整实例和安全设置,然后在我们的案例 tiiiuae/falcon-40b-instruct 中进行部署。

推理端点根据模型大小建议实例类型,模型大小应足以运行模型。 这里有 4 个 NVIDIA T4 GPU。 为了获得 LLM 的最佳性能,请将实例更改为 GPU [xlarge] · 1x Nvidia A100。
注意:如果无法选择实例类型,你需要联系我们申请实例配额。
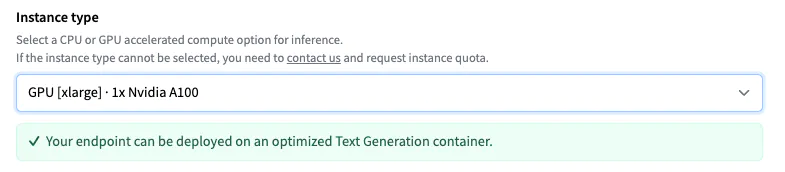
然后,你可以通过单击“创建端点”来部署模型。 10 分钟后,端点应在线并可处理请求。
3、测试 LLM 端点
端点概述提供对推理小部件的访问,该小部件可用于手动发送请求。 这使你可以使用不同的输入快速测试端点并与团队成员共享。 这些小部件不支持参数 - 在这种情况下,这会导致“短”生成。
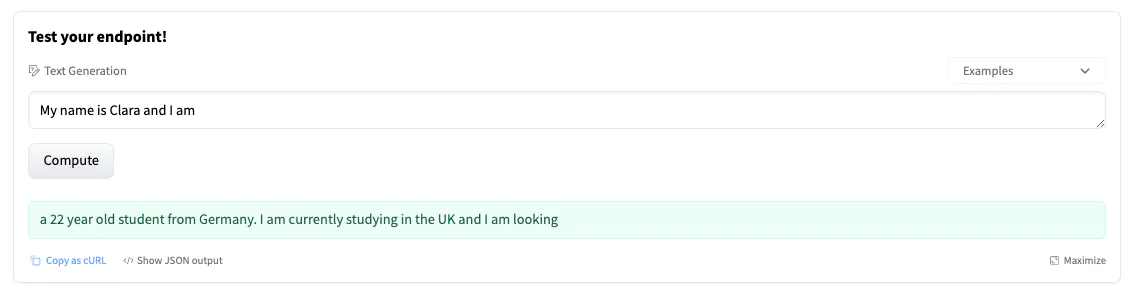
该小部件还生成一个可供你使用的 cURL 命令。 只需添加你的 hf_xxx 并进行测试。
curl https://j4xhm53fxl9ussm8.us-east-1.aws.endpoints.huggingface.cloud \
-X POST \
-d '{"inputs":"Once upon a time,"}' \
-H "Authorization: Bearer <hf_token>" \
-H "Content-Type: application/json"
你可以使用不同的参数来控制生成,在有效负载的参数属性中定义它们。 截至今天,支持以下参数:
- temperature:控制模型中的随机性。 较低的值将使模型更具确定性,较高的值将使模型更加随机。 默认值为 1.0。
- max_new_tokens:要生成的最大令牌数。 默认值为 20,最大值为 512。
- repetition_penalty:控制重复的可能性。 默认为空。
- seed:用于随机生成的种子。 默认为空。
- stop:停止生成的令牌列表。 当生成其中一个token时,生成将停止。
- top_k:为 top-k 过滤保留的最高概率词汇标记的数量。 默认值为 null,这会禁用 top-k-filtering。
- top_p:为核采样保留的参数最高概率词汇标记的累积概率,默认为 null
- do_sample:是否使用采样; 否则使用贪婪解码。 默认值为 false。
- best_of:生成 best_of 序列并返回最高 token logprobs 的那个,默认为 null。
- details:是否返回有关该代的详细信息。 默认值为 false。
- return_full_text:是否返回全文或仅返回生成的部分。 默认值为 false。
- truncate:是否将输入截断至模型的最大长度。 默认值为 true。
- typical_p:令牌的典型概率。 默认值为空。
- watermark:用于生成的水印。 默认值为 false。
4、使用 Javascript 和 Python 传输响应
使用LLM请求和生成文本可能是一个耗时且反复的过程。 改善用户体验的一个好方法是在令牌生成时将其流式传输给用户。 以下是如何使用 Python 和 JavaScript 流式传输令牌的两个示例。 对于 Python,我们将使用 Text Generation Inference 的客户端,对于 JavaScript,我们将使用 HuggingFace.js 库
4.1 使用 Python 传输请求
首先,需要安装文本生成客户端
pip install text-generation
我们可以创建一个客户端,提供我们的端点 URL 和凭证以及我们想要使用的超参数
from text_generation import Client
# HF Inference Endpoints parameter
endpoint_url = "https://YOUR_ENDPOINT.endpoints.huggingface.cloud"
hf_token = "hf_YOUR_TOKEN"
# Streaming Client
client = Client(endpoint_url, headers={"Authorization": f"Bearer {hf_token}"})
# generation parameter
gen_kwargs = dict(
max_new_tokens=512,
top_k=30,
top_p=0.9,
temperature=0.2,
repetition_penalty=1.02,
stop_sequences=["\nUser:", "<|endoftext|>", "</s>"],
)
# prompt
prompt = "What can you do in Nuremberg, Germany? Give me 3 Tips"
stream = client.generate_stream(prompt, **gen_kwargs)
# yield each generated token
for r in stream:
# skip special tokens
if r.token.special:
continue
# stop if we encounter a stop sequence
if r.token.text in gen_kwargs["stop_sequences"]:
break
# yield the generated token
print(r.token.text, end = "")
# yield r.token.text
将 print 命令替换为输出或要将令牌流式传输到的函数。
4.2 使用 JavaScript 传输请求
首先,你需要安装@huggingface/inference 库。
npm install @huggingface/inference
我们可以创建一个 HfInferenceEndpoint,提供端点 URL 和凭据以及我们要使用的超参数。
import { HfInferenceEndpoint } from '@huggingface/inference'
const hf = new HfInferenceEndpoint(
'https://YOUR_ENDPOINT.endpoints.huggingface.cloud',
'hf_YOUR_TOKEN'
)
//generation parameter
const gen_kwargs = {
max_new_tokens: 512,
top_k: 30,
top_p: 0.9,
temperature: 0.2,
repetition_penalty: 1.02,
stop_sequences: ['\nUser:', '<|endoftext|>', '</s>'],
}
// prompt
const prompt = 'What can you do in Nuremberg, Germany? Give me 3 Tips'
const stream = hf.textGenerationStream({ inputs: prompt, parameters: gen_kwargs })
for await (const r of stream) {
// # skip special tokens
if (r.token.special) {
continue
}
// stop if we encounter a stop sequence
if (gen_kwargs['stop_sequences'].includes(r.token.text)) {
break
}
// yield the generated token
process.stdout.write(r.token.text)
}
将 process.stdout 调用替换为yield 或想要将令牌流式传输到的函数。
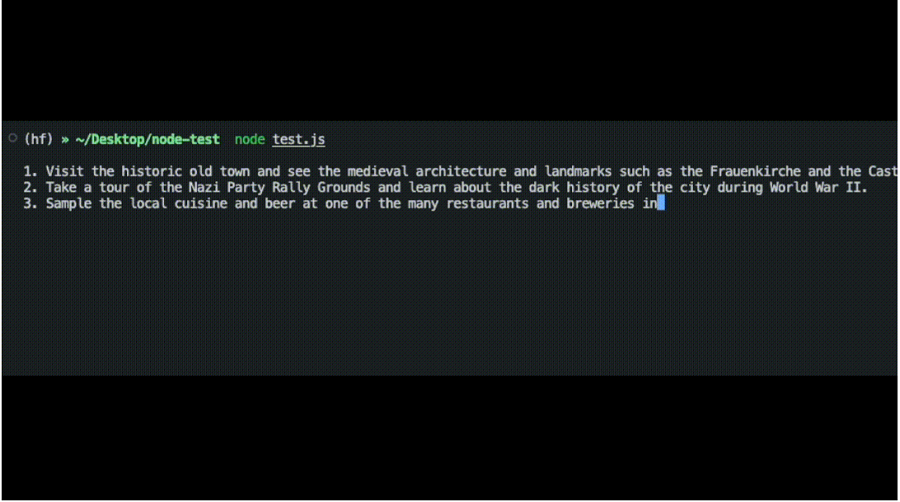
原文链接:Deploy LLMs with Hugging Face Inference Endpoints
BimAnt翻译整理,转载请标明出处





