
NSDT工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器 - REVIT导出3D模型插件 - 3D模型语义搜索引擎 - AI模型在线查看 - Three.js虚拟轴心开发包 - 3D模型在线减面 - STL模型在线切割 - 3D道路快速建模
我们经常使用 scikit-learn 对监督学习和无监督学习任务的数据进行建模。 我们熟悉面向对象的设计,例如启动类并从类中调用子函数。 然而,当我个人使用 PyTorch 时,我发现与 scikit-learn 类似但又不一样的设计模式。
1、PyTorch和transformers
要使用 PyTorch 训练模型,你必须为数据集和模型创建一个类,并添加每个类的继承。 例如,你需要创建一个名为 TextDataset(Dataset) 的类,并且该 Dataset 是 torch.utils.Dataset 中的一个类。 要创建模型,也必须创建一个类例如 Classifier(nn.Module) ,与scikit-learn 相比,PyTorch 允许你构建自己的类并在类中执行一些操作。
我们来谈谈Hugging Face开发的 transformers。 当我看到一位在LinkedIn上和我有联系的研究科学家发布的有关添加的新功能的帖子时,我注意到了这个库。 但是,当时我并没有考虑立即尝试。 然后,就到了我对 BERT 架构感到好奇并想要实现它的时候。
如果你是 PyTorch 的新手。 尝试使用它构建一些模型,例如构建用于文本分类或图像分类的模型以开始。 PyTorch 有一个很棒的文档。 在你熟悉使用 PyTorch 来训练和评估模型后。 可以轻松使用 transformers。
我开始仅从 Transformers 的文档中探索它们。 我关注 Hugging Face 推特帐户,该帐户经常发布有关库和开发的最新更新的推文。 这让我更容易了解他们的更新。 查看 Transformers 文档中的使用页面。 它解释了如何在自然语言处理中使用各种应用程序,从序列分类到神经机器翻译。
在深度学习社区中,我们经常强调预训练模型。 一个经过预先训练的模型,可以将其用于另一个类似的任务,也称为迁移学习。 Hugging Face 托管来自各个开发人员的预训练模型。 他们创建了一个共享预训练模型的平台,你也可以将其用于自己的任务。
之后,我想知道,如果我想使用 BERT 架构训练自己的模型而不使用预训练模型(这意味着从头开始训练模型)怎么办? 因为大多数人从博客文章或研究论文中以 BERT-base-uncased 为例讨论预训练模型。 然后我想起来,PyTorch 与 Keras 相比有很大不同,Keras 具有 fit 和 Predict 函数。
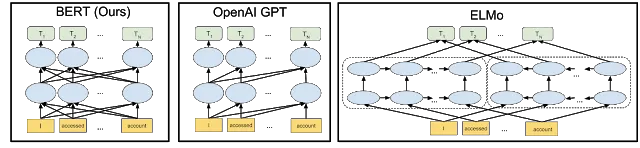
2、使用transformers训练文本分类BERT模型
我开始使用 PyTorch 从 Kaggle 竞赛数据集训练文本分类, Real or Not? NLP with Disaster Tweets 是一个不错的开始选择。 我使用了 XGBoost 和 CatBoost,并在数据清理和特征提取方面做了一些神奇的事情,但分数上不去。 然后,我认为 BERT 会将分数添加到排行榜中。 事实证明,使用 bert-base-uncased 后,平均 F 分数提高到了 83%,并进入排行榜前 12%!
为了从头开始训练模型,我创建了一个函数来生成管线:
def generate_model(args, num_labels):
config = AutoConfig.from_pretrained(
args.model_name_or_path,
num_labels=num_labels,
finetuning_task=args.task_name,
)
tokenizer = AutoTokenizer.from_pretrained(
args.model_name_or_path,
do_lower_case=args.do_lower_case
)
model = AutoModelForSequenceClassification.from_config(
config
)
return config, tokenizer, model如你所知, Transformers 需要三个组件来推断或训练你的模型。 AutoConfig 用于设置模型和分词器配置。 可以将 AutoConfig 更改为 BertConfig 或 Transformers 中可用的任何其他架构。 AutoTokenizer 的应用与配置相同。 但这里的分词器使用预先训练的,这意味着我使用来自 bert-base-uncased 的分词器。 它已经加载了自己的词汇表,你可以查看 vocab.txt 中的每个token, 所以我没有建立自己的词汇表。 最后一个组件 AutoModelForSequenceClassification 是从配置加载的,因为我想从头开始训练。 AutoModel 可以更改为 BertForSequenceClassification 。
第二步,我创建 DisasterDataset 类来加载数据集:
class DisasterDataset():
def __init__(self, data_path, eval_path, tokenizer):
d_data = pd.read_table(data_path, sep=',')
d_eval = pd.read_table(eval_path, sep=',')
row, col = d_data.shape
d_train = d_data[:int(row * 0.8)]
d_test = d_data[int(row*0.8):]
d_train.reset_index(drop=True, inplace=True)
d_test.reset_index(drop=True, inplace=True)
self.tokenizer = tokenizer
self.dataset = {'train': (d_train, len(d_train)),
'test': (d_test, len(d_test)),
'eval': (d_eval, len(d_eval))}
self.num_labels = len(d_train.target.unique().tolist())
self.set_split('train')
def get_vocab(self):
text = " ".join(self.data.text.tolist())
text = text.lower()
vocab = text.split(" ")
with open('vocab.txt', 'w') as file:
for word in vocab:
file.write(word)
file.write('\n')
file.close()
return 'vocab.txt'
def set_split(self, split = 'train'):
self.split = split
self.data, self.length = self.dataset[split]
def __getitem__(self, idx):
x = self.data.loc[idx, "text"].lower()
x = self.tokenizer.encode(x, return_tensors="pt")[0]
if self.split != 'eval':
y = self.data.loc[idx, "target"]
return {'id': idx, 'x': x, 'y': y}
else:
id_ = self.data.loc[idx, "id"]
return {'id': id_, 'x': x}
def __len__(self):
return self.length上面的脚本用于构建类数据集。 我没有使用任何预处理,任何清洁。 只需使用纯文本并使用 Tokenizers 库中的 BertWordPiece 进行标记化:
for epoch in range(1, 101):
running_loss = 0
running_accuracy = 0
running_loss_val = 0
running_accuracy_val = 0
start_time = time.time()
# dataset class is assigned to dd variable
dd.set_split('train')
dataset = DataLoader(dd, batch_size=64, shuffle=True, collate_fn=padded)
model.train()
for batch_index, batch_dict in enumerate(dataset, 1):
optimizer.zero_grad()
x = batch_dict['x'].permute(1, 0)
x = x.to(device)
y = batch_dict['y'].to(device)
output = model(x)[0]
output = torch.softmax(output.squeeze(), dim=1)
loss = criterion(output, y.type(torch.LongTensor).to(device))
running_loss += (loss.item() - running_loss) / batch_index
accuracy = compute_accuracy(y, output)
running_accuracy += (accuracy - running_accuracy) / batch_index
loss.backward()
optimizer.step()
dd.set_split('test')
dataset = DataLoader(dd, batch_size=64, shuffle=True, collate_fn=padded)
model.eval()
for batch_index, batch_dict in enumerate(dataset, 1):
x = batch_dict['x'].permute(1, 0)
x = x.to(device)
y = batch_dict['y'].to(device)
output = model(x)[0]
output = torch.softmax(output.squeeze(), dim=1)
loss = criterion(output, y.type(torch.LongTensor).to(device))
running_loss_val += (loss.item() - running_loss_val) / batch_index
accuracy = compute_accuracy(y, output)
running_accuracy_val += (accuracy - running_accuracy_val) / batch_index最后,上面的脚本是训练模型的。 我使用 Adam 优化器,学习率为 0.0001,并使用 PyTorch 的调度程序 StepLR(), step_size 为 20, gamma 为 0.01。 对于标准,我使用 CrossEntropyLoss() 。 即使任务是二进制的,假设使用二进制交叉熵。 但模型返回类别的概率,使用softmax 作为激活函数。
我使用 GPU Nvidia K-80 在计算引擎上运行脚本,得到结果的速度相当快,因为我设置 running_accuracy > 90 并且 running_accuracy_val > 90 将被停止。 该脚本不会运行 100 个周期才能完成。
3、结束语
最后,BERT 架构比 Transformers 库更加有用且易于使用。 在雅加达人工智能研究中心,一个位于雅加达的人工智能研究社区,主要使用 PyTorch 和 Transformers 来开发和运行项目实验。 我们还尝试构建自己的编码器来超越现有的编码器,例如 GPT 和 BERT 架构。
原文链接:Modeling using Hugging Face Transformers
BimAnt翻译整理,转载请标明出处





