
NSDT工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器 - REVIT导出3D模型插件 - 3D模型语义搜索引擎 - AI模型在线查看 - Three.js虚拟轴心开发包 - 3D模型在线减面 - STL模型在线切割 - 3D道路快速建模
提示工程很糟糕。
这是使用大型语言模型最乏味的部分。这些模型非常挑剔,对提示进行看似无害的更改可能会导致截然不同的结果。我厌倦了手动调整、不系统的变化以及与手动提示工程相关的头痛……
首先让我们统一认识,提示工程是指对 AI 模型给出的指令(提示)进行精心设计和改进,以引出所需的响应。它需要深入了解模型的行为,并进行大量的反复试验才能获得一致和准确的输出。
但传统的手动改进提示的过程很糟糕。所以我正在制作一个自动提示优化器。
本文将分为多个部分。本文的前半部分将概述我的一般方法。我将讨论我为获得基本事实所做的工作,这是优化过程中的重要部分。
本文的下一部分将介绍优化阶段。它将讨论我计划如何改进我的“AI 股票筛选器”,这是 NexusTrade 平台内由 LLM 提供支持的功能。
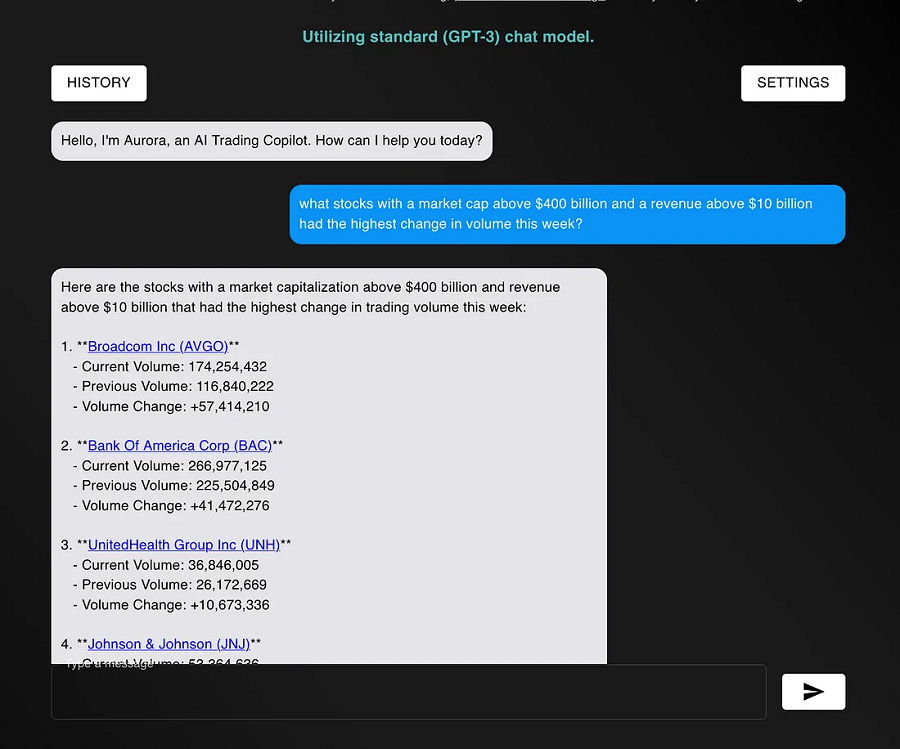
这项工作很重要,因为它可以让我们花更少的时间进行手动提示调整(这并不能保证提高性能),而花更多的时间专注于大型语言模型的实际业务用例。
1、我的方法概述:自动快速优化
我的方法受到一篇名为 EvoPrompt 的论文的启发,这是一个自动快速优化的框架。该框架使用受进化启发的算法,模仿自然选择的过程来迭代改进解决方案。
进化算法是一类受查尔斯·达尔文进化论启发的优化算法。它们有五个阶段:
- 初始化:如何生成初始种群
- 选择:如何“选择”种群中的个体进行繁殖,更适合的个体更有可能被选中
- 交叉(或重组):我们如何选择结合父母的“基因”来创造新的后代(或解决方案)
- 突变:后代的意外变化可能对其适应性产生积极或有害的影响
- 评估:我们如何计算后代的适应性
为了利用此算法进行快速优化,我们需要一个可以在过程中使用的输入/输出对种群。一个部分用于训练模型,另一个部分用于评估模型。
2、获取基本事实
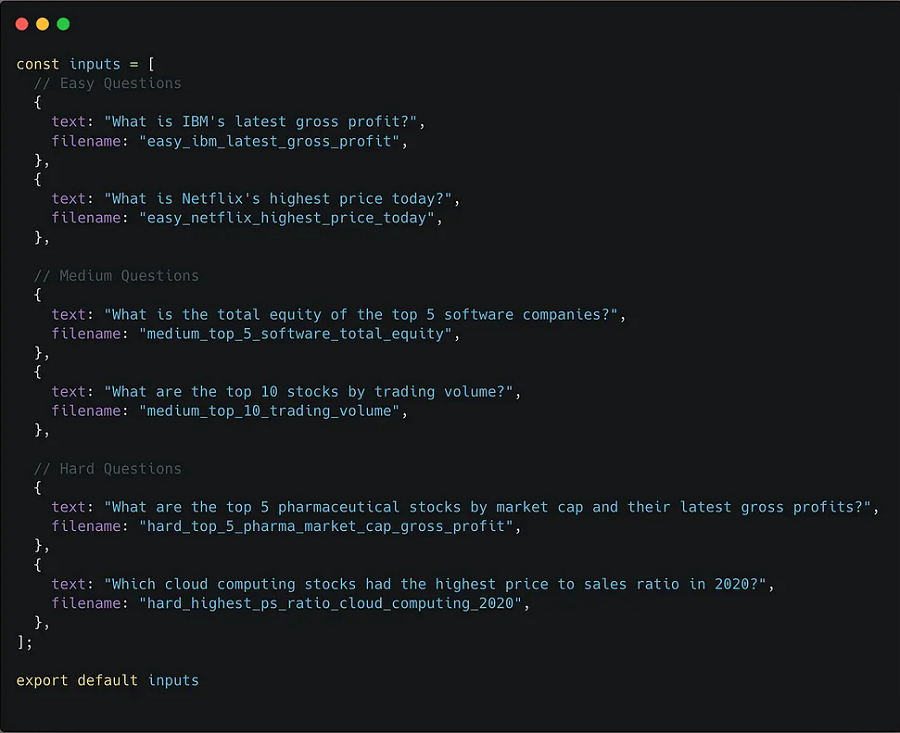
我将优化的提示是我的 AI 驱动的股票筛选器。给定自然语言输入,筛选器将找到符合拟标准的股票。
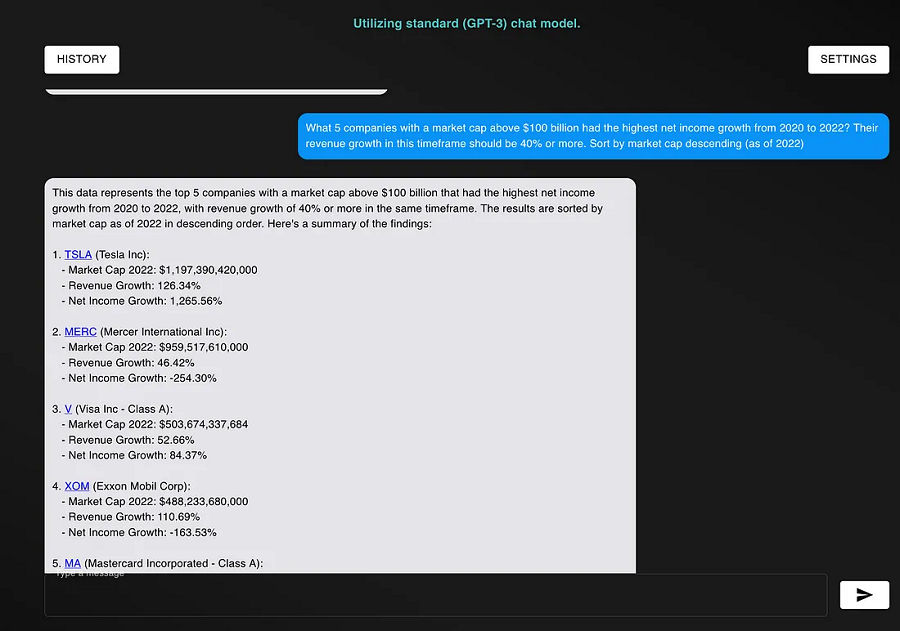
一些示例输入是:
- (简单)IBM 的最新毛利润是多少?
- (中等)前 5 大软件公司的总股本是多少?
- (困难)2021 年 6 月 16 日,市值 1000 亿美元或以上的 10 家公司的价格与自由现金流比率最低?
我的方法相对简单。我收集了 60 个问题的列表并检索了这些问题的答案。我将使用以下目录结构将问题/答案对保存到我的计算机上:
./
├── output/
│ ├── easy_apple_price_today/
│ │ ├── input.txt
│ │ └── output.txt
│ ├── easy_nvidia_latest_revenue/
│ │ ├── input.txt
│ │ └── output.txt
│ ├── medium_top_10_ai_stocks/
│ │ ├── input.txt
│ │ └── output.txt
│ ├── hard_lowest_price_fcf_ratio/
│ │ ├── input.txt
│ │ └── output.txt
│ ├── easy_ford_pe_ratio_ttm/
│ │ ├── input.txt
│ │ └── output.txt
│ ├── hard_ev_stocks_highest_volume/
│ │ ├── input.txt
│ │ └── output.txt
│ ├── medium_semiconductor_stocks_revenue/
│ │ ├── input.txt
│ │ └── output.txt
│ ├── medium_avg_revenue_top_25_biotech/
│ │ ├── input.txt
│ │ └── output.txt
└── main.ts
3、用于填充输入/输出对的脚本
为了从输入生成所有输出,我还使用了 AI 驱动的方法:
import NexusGenAIServiceClient, {
AIModeEnum,
} from '../services/NexusGenAIServiceClient';
import { BigQueryDataManager } from '../../services/BigQueryClient';
import DB from '../../services/db';
import fs from 'fs';
import inputs from './inputs';
import readline from 'readline';
async function evaluateResponse(response: any) {
const result = await new NexusGenAIServiceClient({
process.env.NEXUSGENAI_API_KEY
}).chatWithPrompt({
model: 'AI Stock Screener Output Evaluator',
prompt: 'AI Stock Screener: Content: JSON.stringify(response) }',
AIModeEnum.four0m,
});
console.log('Score:', result[result.length - 1].data.score);
return result;
}
async function run() {
const db = new DB('cloud');
await db.connect();
const rl = readline.createInterface({
input: process.stdin,
output: process.stdout,
});
async function askQuestion(question: string): Promise<string> {
return new Promise((resolve) => {
rl.question(question, (answer) => {
resolve(answer);
});
});
}
function isAffirmative(response: string): boolean {
const affirmatives = ['yes', 'yeah', 'ya', 'yea'];
return affirmatives.includes(response);
}
function isNegative(response: string): boolean {
const negatives = ['no', 'nah', 'nope'];
return negatives.includes(response);
}
async function getUpdatedMessages({
messages,
sql: string,
content: string
}) {
return await new NexusGenAIServiceClient({
process.env.NEXUSGENAI_API_KEY
}).chatWithPrompt({
model: 'AI Stock Screener',
prompt: `User: ${content}`,
AIModeEnum.four0,
});
}
for (const input of inputs) {
const { text, filename } = input;
const outputDir = `./output/${filename}`;
const outputFilePath = `${outputDir}/output.txt`;
if (!fs.existsSync(outputDir)) {
fs.mkdirSync(outputDir, { recursive: true });
}
const sql = `SQL QUERY BASED ON ${text}`;
const messages = await getUpdatedMessages({
messages: [
{
sender: 'user',
content: text,
AIModeEnum.four0,
},
],
sql,
content: text,
});
let isCorrect = false;
let retryCount = 0;
const maxRetries = 5;
console.log('Thought Process:', messages[messages.length - 1].content);
while (!isCorrect) {
const sql = messages[messages.length - 1].data.sql;
console.log('SQL:', sql);
await BigQueryDataManager.createInstance().executeQuery(sql);
console.log('Manual review required for $filename }');
let userResponse = await askQuestion(
'Is this query correct after manual review? (yes/no): '
);
while (!isAffirmative(userResponse) && !isNegative(userResponse)) {
userResponse = await askQuestion(
'Please enter a valid response (yes/no): '
);
}
if (isAffirmative(userResponse)) {
isCorrect = true;
} else {
const issueDescription = await askQuestion(
'Explain in detail what’s wrong with the query: '
);
messages = await getUpdatedMessages({
messages,
sql,
issueDescription,
});
}
if (++retryCount >= maxRetries) {
console.log('Max retries reached. Manual review required.');
break;
}
}
const outputContent = JSON.stringify(messages[messages.length - 1].data, null, 2);
fs.writeFileSync(outputFilePath, outputContent);
}
rl.close();
}
(async () => {
await run();
process.exit(0);
})();
更具体地说,我正在使用脚本来帮助我填充模型的基本事实。它执行以下操作:
- 将请求发送到 OpenAI
- 从 OpenAI 响应执行查询
- 询问用户输出是否正确。如果不正确,他们可以添加有关答案看起来错误的原因的背景信息,并引导模型找到正确答案。
执行脚本时,输出如下所示:
Input: What is the average price to sales ratio of the top 5 cloud computing stocks?
Thought Process: To find the average price to sales ratio of the top 5 cloud computing stocks, we need to:
1. Generate a subquery to get the most recent price to sales ratio for each cloud computing stock.
2. Filter for companies classified under cloud computing.
3. Order the results by market cap in descending order to identify the top 5 companies.
4. Calculate the average price to sales ratio for these top 5 companies.
5. Ensure the query avoids common errors such as division by zero by not performing any division operations.
6. Group the results by company symbol to avoid duplicates.
7. Use appropriate timestamp operations to handle the date filtering.
8. Limit the number of results to 5 to focus on the top companies.
Now I will generate the query:
SQL:
WITH CloudComputingStocks AS (SELECT si.symbol, si.name, pd.date, pd.priceToSalesRatioTTM,
pd.marketCap FROM `nexustrade-io.stockindustries.current` si JOIN `nexustrade-io.universalstockfundamentals.price_data` pd ON si.symbol = pd.symbol WHERE si.cloudComputing = TRUE AND pd.date = (SELECT MAX(date) FROM `nexustrade-io.universalstockfundamentals.price_data` WHERE symbol = si.symbol) ORDER BY pd.marketCap DESC LIMIT 5) SELECT AVG(priceToSalesRatioTTM) AS average_price_to_sales_ratio FROM CloudComputingStocks
Job ef860d9c-cdd3-4313-9b11-c5d54877127f started.
[ { average_price_to_sales_ratio: 14.710944000000001 } ]
Manual review required for medium_avg_ps_ratio_cloud_computing.
What is the average price to sales ratio of the top 5 cloud computing stocks?
Is this query correct after manual review? (yes/no): no
Explain in detail what’s wrong with the query: the stock names are not populated
请注意,这是一种半自动化方法。由于我们还没有基本事实,因此我们必须照看模型并确保它生成正确的输出。这非常重要,因为我们不想针对错误的答案进行优化。
获得输入/输出对列表后,我们可以继续执行第 2 步。
4、数据拆分和优化
在下一节中,我将讨论优化技术的下一阶段。如果拟对训练神经网络或遗传优化很熟悉,那么拟会觉得这很熟悉。我计划执行的程序如下:
准备数据
数据准备对于消除结果中的偏差非常重要。最好的方法是随机化。具体来说:
- 我们将随机化问题/答案对的群体。
- 然后我们将拆分数据:前 80% 将放在训练集中,20% 将放在验证集中。
训练集直接用于改进模型,而验证集仅用于查看我们的优化技术是否能很好地泛化样本。我们的目标是,尽管没有直接对其进行训练,但我们的验证集性能仍会提高。
从数据准备到初始种群生成
就像遗传优化一样,我需要使用训练集创建初始提示种群。
在我的平台中,提示对象不仅仅是您可能习惯的系统提示。它由以下属性组成:
- 系统提示:我们给模型的直接指令
- 模型:GPT-4o mini 和 Claude 3.5 Sonnet 等模型是您可以使用的一些模型。
- 示例:示例听起来就是它们的样子:它们是模型可以预期的对话示例
所有内容的组合构成了一个“提示对象”。在这个实验中,我们不会尝试优化模型——我们将专注于优化系统提示和示例。
以下是我们将如何生成初始种群。
- 原始提示修改:获取原始提示对象并删除现有示例。
- 提示变体生成:使用具有成本效益的模型(如 GPT-4o mini)生成提示的 x 个变体,GPT-4o mini 是最新(且最便宜)的大型语言模型,其性能优于 GPT-3.5 Turbo。首先,我们可以生成 10 个变体
- 示例生成:为每个变体生成 8 个随机示例。
通过适者生存提示进行进化
接下来,我将使用语言模型作为优化器来优化我的提示。这是该过程最酷的部分之一——每个优化组件都是一个语言模型。让我解释一下这个过程。
- 评估:使用 GPT-4o mini 作为我们的事实上的模型,我们将使用来自训练集的示例子集来测试我们的初始种群。获得输出后,我们将使用特殊的“提示评分器”提示将输出与我们今天合成的地面真相进行比较。提示评分器将为每个提示给出 0 到 1 的分数。然后我们将分数相加,因此每个提示都会有一个最终分数。
- 选择:我们将执行所谓的“轮盘选择”来选择父母,其中表现更好的提示更有可能被选为父母。对于每个父母,我们将随机挑选将传递给后代的示例。
- 交叉:取一对父母,我们将使用“提示组合器”提示来合并选定的提示。在创建新的后代时,我们还将组合来自每个父代的随机示例
- 变异:为了保持种群的多样性,我们将随机选择一个提示并对其进行“变异”。虽然我们可以通过多种方式来实现这一点,但我们将首先使用一个简单的“提示变异器”提示,它只是重新表述系统提示。我们还可以有一个“示例重新排列器”,它会影响示例保存到提示对象的顺序。
- 替换:最后,我们将评估每个新提示的性能,根据提示的性能对其进行排名,并剔除性能较差的提示。
如拟所见,这种方法完全由大型语言模型支持。随着 GPT-4o mini 的发布,执行这种类型的优化从未如此便宜。
“提示分级器”、“提示组合器”和“提示变异器”的具体实现将在下一篇文章中详细介绍。总结一下,它们将是自己的提示,并被赋予专门的任务以促进优化过程。
例如,提示评分者将获得模型的输出和基本事实,并被告知输出一个从 0 到 1 的数字,其中 1 表示模型输出了正确的响应(类似于基本事实),而 0 表示模型输出了错误的响应。
提示组合器和提示修改器将根据其角色被赋予类似的任务。
找到最好的提示
最后,在每个循环结束时,我们将运行以下两个步骤:
- 验证:在验证集上测试优化的提示,以评估与基本事实相比的准确性。
- 迭代:重复整个过程一定次数,以迭代方式改进提示。首先,我们只需重复该过程 10 次,然后查看验证集性能随时间的变化
最终结果应该是一组比原始提示更好的提示。我们还将有一个图表来查看训练和验证集性能是否确实随着时间的推移而提高。当然,我的所有结果都将在本系列的下一篇文章中详细记录。
5、结束语
关于如何改进这种方法,我有很多疯狂的想法。例如,我可以执行一种更复杂的优化技术,称为多目标优化,它可以同时改善多个因素。这包括速度和成本等传统因素,但也包括模型的个性或他们使用的语气等不太常见的因素。
但首先,我从一个非常简单的单目标优化问题开始。为什么?因为我讨厌提示工程。
如果我能证明,花 2 个小时的时间开发完整的基本事实可以消除我再次修改这些提示的需要,那么你敢打赌我会珍惜这笔投资。
原文链接:I’m sick and tired of prompt engineering. So I’m making a prompt optimizer (Part 1)
BimAnt翻译整理,转载请标明出处





