
NSDT工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器 - REVIT导出3D模型插件 - 3D模型语义搜索引擎 - AI模型在线查看 - Three.js虚拟轴心开发包 - 3D模型在线减面 - STL模型在线切割 - 3D道路快速建模
Meta AI 今天宣布发布 ImageBind,这是一种新的 AI 模型,能够从六种类型的数据中学习和连接信息:文本、图像/视频、音频、深度、热和运动传感器。 ImageBind 为这些模式创建了一个共享的表示空间,而不需要包含所有可能组合的配对数据样本。
ImageBind 利用大型视觉语言模型,并将其零样本学习能力扩展到使用自然配对数据的新模式。 例如,视频-音频对教会模型视觉和听觉数据之间的关系。
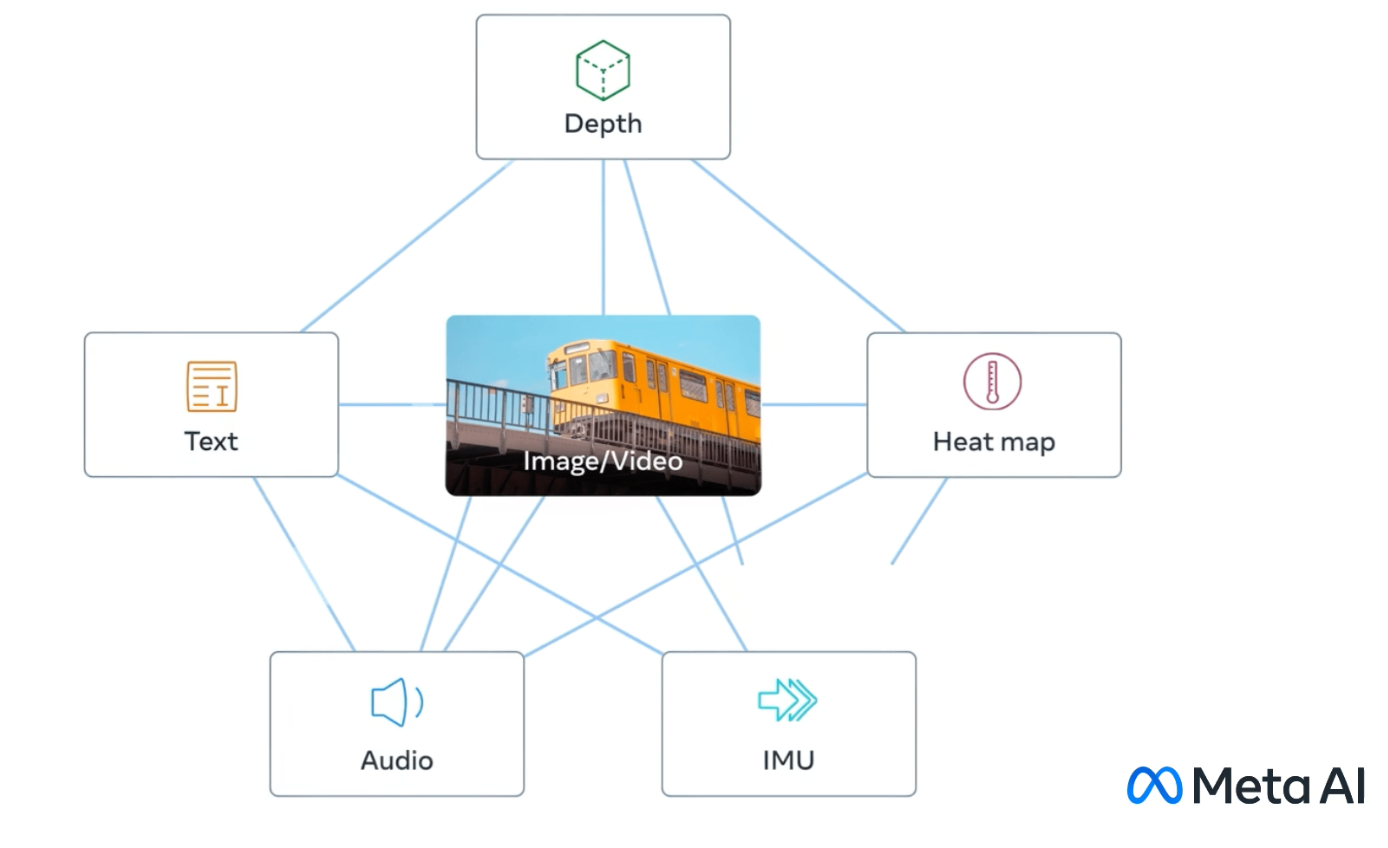
在他们的论文中,研究人员表明,仅图像配对数据就足以对齐六种模态,从而使模型能够跨模态链接内容,而无需直接将它们一起观察。 这使其他 AI 模型无需强化训练即可掌握新模式。
ImageBind 表现出强大的可伸缩性,在较大的版本中能力显着提高。 涌现的能力包括预测哪个音频与图像匹配或估计照片的深度。 ImageBind 优于以前专门从事单一模态(如音频或深度)的模型,用于分类和零镜头检索等任务。 在一些实验中收益达到了 40%。
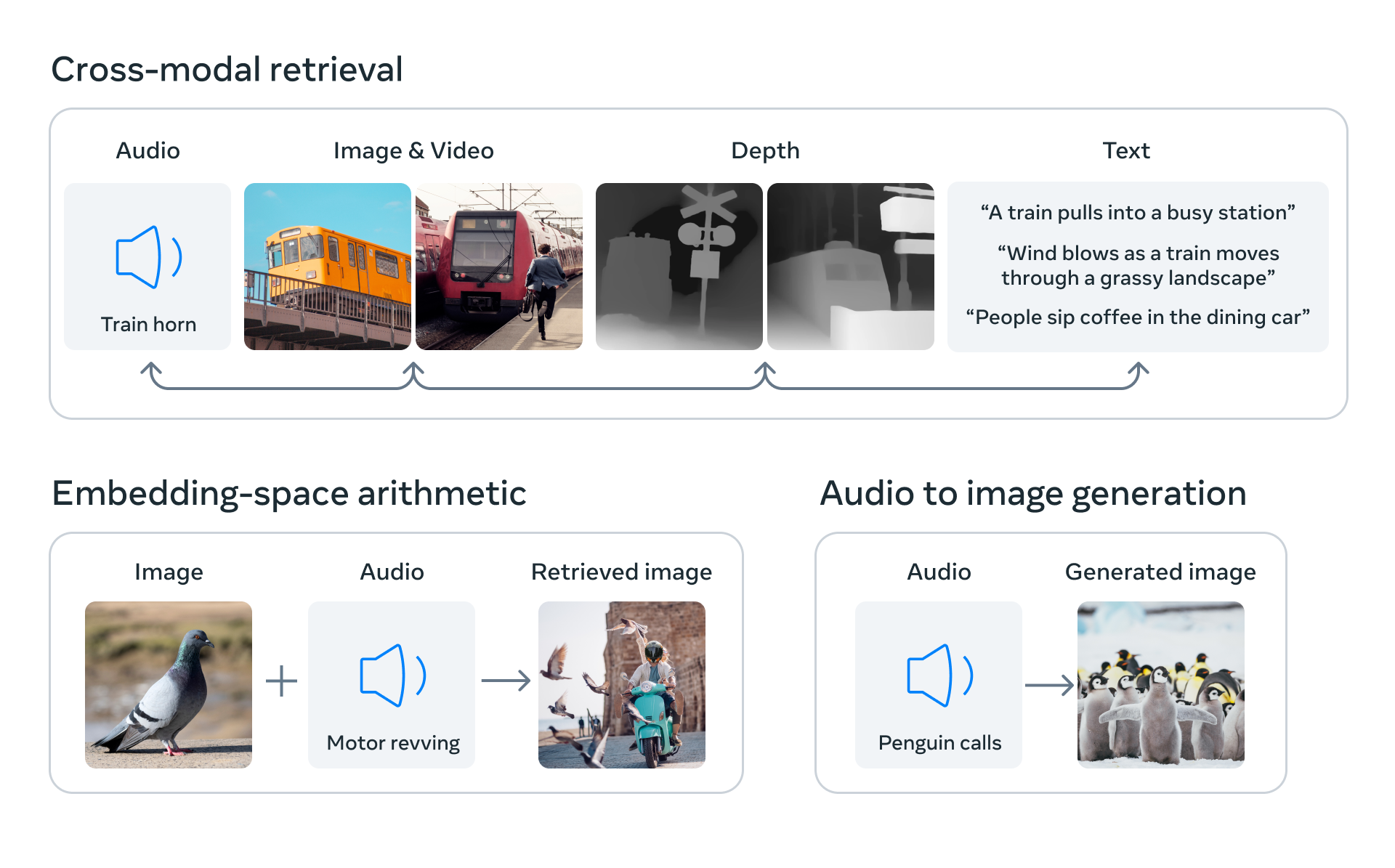
该研究开辟了创造性的机会,例如向视频/图像添加声音、从图像/音频生成视频以及根据音频分割图像。 额外的模态可以产生更丰富的多模态 AI。 然而,该领域需要更好地了解大型模型中的缩放行为、如何评估它们并启用应用程序。
今天的发布标志着 Meta 在追求从所有可用数据中学习的多模式 AI 方面取得了进展。 Meta AI 在与视觉相关的模型上投入了大量资金,ImageBind、DINOv2 和 SAM 等创新使 AR/VR 中的应用成为可能,Meta 的雄心是构建元宇宙。 ImageBind 的演示站点可供研究人员探索其功能。
像 ImageBind 这样的模型让我们更接近人类智能。 他们证明,只要有足够的数据和计算能力,机器就可以发展出与人类认知中相互交织的多感官理解相近的能力。 虽然范围仍然狭窄,但 ImageBind 和 Meta 的相关工作指出了人工智能未来的可能性——无论好坏。 如果进展迅速,全世界的研究人员必须努力管理先进人工智能带来的风险。 目前,Meta 的发布为明天最强大的技术可能实现的难题做出了贡献。
原文链接:Meta Introduces ImageBind: An AI Model that Learns Across Six Modalities
BimAnt翻译整理,转载请标明出处





