
NSDT工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器 - REVIT导出3D模型插件 - 3D模型语义搜索引擎 - AI模型在线查看 - Three.js虚拟轴心开发包 - 3D模型在线减面 - STL模型在线切割 - 3D道路快速建模
大型语言模型 (LLM),尤其是像 Mixtral 8x7b(467 亿个参数)这样的大型模型,对内存的要求非常高。当你尝试降低推理成本、提高推理速度或在边缘设备上进行推理时,这种内存需求就会变得明显。解决此问题的一个潜在方法是量化。在本文中,我们将使用易于理解的类比来简化量化的概念,并提供在 LLM 中实现它的实用指南。
LLM 虽然功能强大,但由于模型规模较大,因此会消耗大量资源。这对资源受限的设备上部署带来了挑战,并且会阻碍推理速度和效率。量化提供了一种解决方案,即在保持性能的同时降低模型参数的精度。
在本文中,我们将探讨各种量化技术,包括简单量化、k 均值量化,并简要提到一种称为 qLORA 的方法。
1、理解量化
想象一下乡村中的每栋房屋都代表 LLM 中的一个参数。在密集的模型中,房屋无处不在,就像一个繁华的城市。量化通过仅保留最重要的房屋(参数)并用较小的房屋(较低精度的表示)替换其他房屋,或者移除非常“不重要”的房屋并在其间创建开放空间(零),将这个城市转变为更易于管理的乡村。由于有空间,我们可以说模型“更稀疏”或“密度更低”。当模型稀疏且具有许多零值参数时,这使得模型的计算效率更高且处理速度更快,因为可以轻松跳过或压缩零值,而无需进行昂贵的计算。保留参数之间的开放空间(零)减少了整体模型的大小和复杂性,从而进一步提高了效率。

1.1 量化的好处
量化有几个好处:
- 减少内存占用:通过降低参数精度,量化显著降低了模型的内存需求,这对于在内存有限的设备上部署至关重要。
- 提高速度:较低精度的计算执行速度更快,从而加快模型推理速度,这对实时应用尤其有益。
- 保持性能:量化旨在简化模型,同时保持其性能,确保乡村在缩小规模后仍拥有所有必要的设施。
1.2 量化的类型
量化方法有几种,本文简要提到了其中两种:
- 简单量化:简单量化统一降低所有参数的精度,类似于将乡村划分为相等的正方形区域而不考虑房屋的位置。这可能导致某些地区有很多房子,而其他地区没有房子。
- K 均值量化:K 均值量化根据数据点(房屋)的实际位置创建聚类,从而实现更准确、更高效的表示。它涉及选择代表点(质心)并将每个数据点分配给最近的质心。k 均值量化的某些实现可能包括额外的修剪步骤,其中值低于某个阈值的参数被设置为精确为零(即移除房屋)。这可以进一步增加模型的稀疏性。
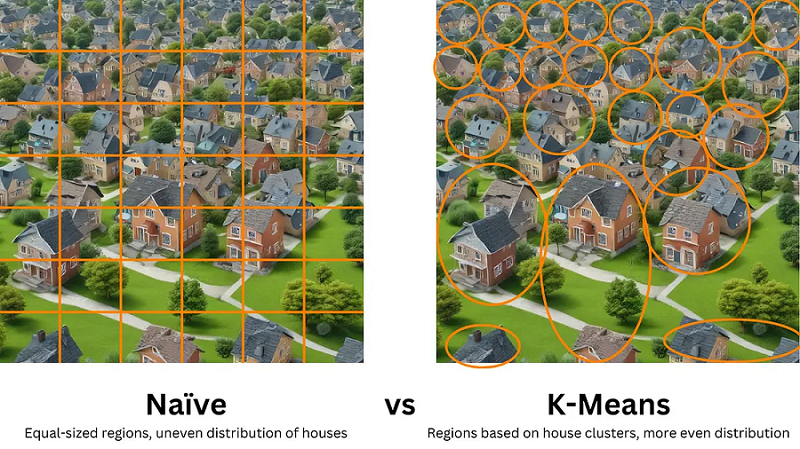
1.3 稀疏性和密度
稀疏性是指模型中只有少数参数(房屋)很重要,其余参数(空白空间)可以忽略而不影响性能。通过量化降低分辨率时,参数重要性的不均匀性变得更加明显。
这可以通过称为稀疏性的指标来衡量。它是模型中 0 值参数的百分比。
稀疏性 =(零值参数的数量)/(参数总数)
高稀疏性意味着 0 值参数(房屋之间的空间)的百分比高
你还可以根据密度来表示模型:
密度 =(非零参数的数量)/(参数总数)
高密度意味着非 0 值参数(房屋)的百分比高
1.4 量化模型中的 Q#_K_M 是什么意思?
在 llama.cpp 的上下文中,Q4_K_M 指的是一种特定类型的量化方法。命名约定如下:
- Q 代表量化。
- 4 表示量化过程中使用的位数。
- K 表示在量化中使用 k 均值聚类。
- M 表示量化后的模型大小。S = 小,M = 中,L = 大。
1.5 量化何时有用?
边缘计算是一种在数据生成点附近处理数据的方式,而不是将其发送到遥远的服务器进行处理。边缘推理很有用,因为它可以加快速度、保护数据隐私并减少带宽使用。
例如,假设你正在使用一款智能手机应用程序,该应用程序使用机器学习来识别照片中的物体。如果该应用程序使用传统的云计算,它必须将照片一直发送到服务器,等待服务器处理,然后将结果发送回你的手机。使用边缘计算,处理就发生在你的手机上,因此速度更快、更隐私,并且使用的数据更少。
虽然量化通常与边缘计算相关,但它在其他情况下也很有用。例如,企业可以使用量化来减少企业数据中心中机器学习模型的计算和存储要求。这可以显著节省硬件和电力使用方面的成本。
对于企业数据中心来说,运行和维护小型量化模型比运行更大、更精确的模型要便宜得多。这是因为量化减少了运行模型所需的内存和计算能力,从而可以降低硬件成本并减少能耗。此外,量化还可以帮助提高机器学习模型的可扩展性,使企业能够处理更大量的数据并更快地做出预测。
在任何需要特定要求或以客户为中心的调整的领域,微调某些参数以准确反映这些需求都很有用。使用 QLoRA(量化和低秩自适应),你可以实现一个既量化又微调以满足您的特定需求的模型。这种方法允许优化模型,而无需更新大量权重,使其成为一种低成本且高效的解决方案,可将大型语言模型适应各种领域(即客户服务、医疗保健、教育)或任何其他更个性化和精确的模型可以提高性能和用户体验的领域。
2、量化模型实战
好的……理论讲得够多了 :D 让我们用 llama.cpp 试试。
使用 Llama.cpp 进行量化
本文的这一部分将介绍如何下载和制作 llama.cpp。然后,我们将从 HuggingFace 下载一个模型并对其进行量化,同时运行一些性能测试。
非常感谢 Peter 通过 llama.cpp 提供的有用指南 。
第1步:启用 Git 下载大文件
#Allow git download of very large files; lfs is for git clone of very large files, such as the models themselves
brew install git-lfs
git lfs install第 2 步:克隆 llama.cpp 项目并运行 make
git clone https://github.com/ggerganov/llama.cpp
cd llama.cpp
make第3步:从 HuggingFace 下载模型
我会从 NousResearch 下载一个。请注意,你需要一个良好的互联网连接,因为模型可能非常大!
#Get model from huggingface, rename it locally to nous-hermes-2-mistral-7B-DPO, and move it to the models directory
#Models generally are in https://huggingface.co/NousResearch
git clone https://huggingface.co/NousResearch/Nous-Hermes-2-Mistral-7B-DPO nous-hermes-2-mistral-7B-DPO现在,我们可以使用终端将其移动到模型文件夹:
mv nous-hermes-2-mistral-7B-DPO models/第4步:将模型转换为标准格式 (GGML FP16)
我说的“标准”是指 GGML FP16 格式。GGML 是由 Georgi Gerganov 为机器学习开发的张量库,可在商用硬件上实现大型模型和高性能。FP16 被认为是“半精度”(FP32 是全精度)。精度是指模型权重的浮点数。有关更多解释,请参阅此清晰解释。
# convert the model to FP16 .gguf format
python3 convert.py models/nous-hermes-2-mistral-7B-DPO/运行 convert.py 后,应该会看到这个 ggml-model-f16.gguf 出现在你的模型目录中:

第 5 步:将模型量化为 n 位
现在,我们可以将 ggml-model-f16.gguf 文件作为进一步量化的起点。
4 位量化:
# quantize the model to 4-bits (using Q4_K_M method)
./quantize ./models/nous-hermes-2-mistral-7B-DPO/ggml-model-f16.gguf ./models/nous-hermes-2-mistral-7B-DPO/ggml-model-Q4_K_M.gguf Q4_K_M创建 Q4_K_M.gguf:

3、其他量化方案
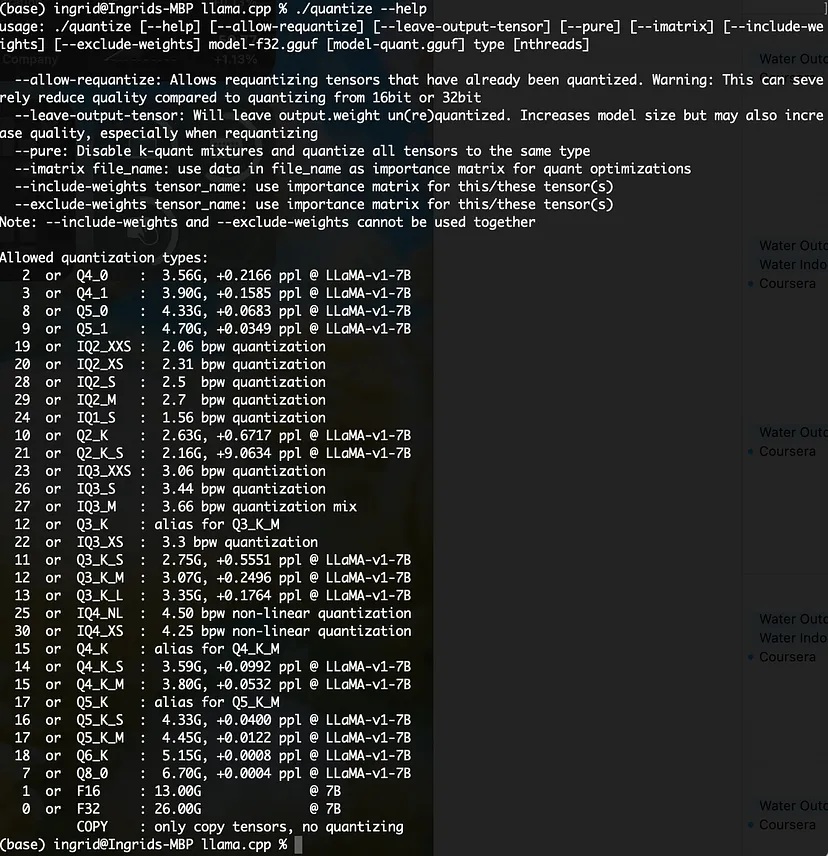
我们可以进行多种不同的量化。详情请参见屏幕截图。
如果你运行 ./quantize --help,那么你将看到量化类型的所有选项:
3比特量化:
# quantize the model to 3-bits (using Q3_K_M method)
./quantize ./models/nous-hermes-2-mistral-7B-DPO/ggml-model-f16.gguf ./models/nous-hermes-2-mistral-7B-DPO/ggml-model-Q3_K_M.gguf Q3_K_M
5比特量化:
# quantize the model to 5-bits (using Q5_K_M method)
./quantize ./models/nous-hermes-2-mistral-7B-DPO/ggml-model-f16.gguf ./models/nous-hermes-2-mistral-7B-DPO/ggml-model-Q5_K_M.gguf Q5_K_M
2比特量化:
# quantize the model to 2-bits (using Q2_K method)
./quantize ./models/nous-hermes-2-mistral-7B-DPO/ggml-model-f16.gguf ./models/nous-hermes-2-mistral-7B-DPO/ggml-model-Q2_K.gguf Q2_K
4、批处理基准测试
什么是批处理基准测试?批处理基准测试对 llama.cpp 库的批处理解码性能进行基准测试。
运行 ./batched-bench — help :

让我们在 f16 版本上尝试批量测试:
./batched-bench ./models/nous-hermes-2-mistral-7B-DPO/ggml-model-f16.gguf 2048 0 999 128,256,512 128,256 1,2,4,8,16,32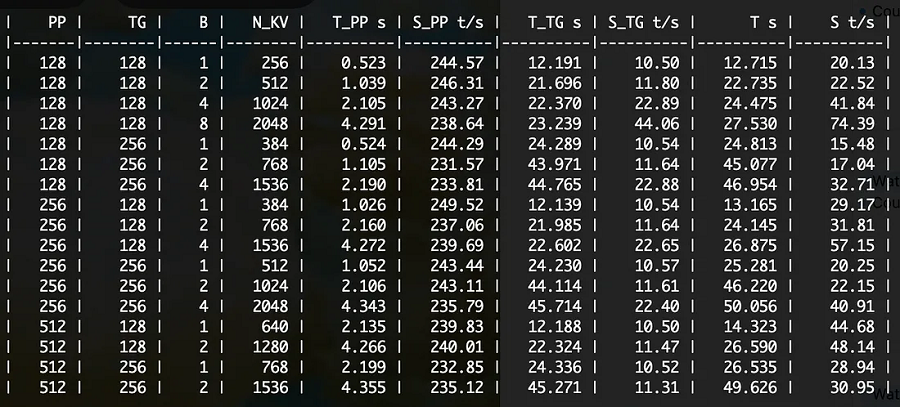
对于 Q4_K_M 量化也是如此:
./batched-bench ./models/nous-hermes-2-mistral-7B-DPO/ggml-model-Q4_K_M.gguf 2048 0 999 128,256,512 128,256 1,2,4,8,16,32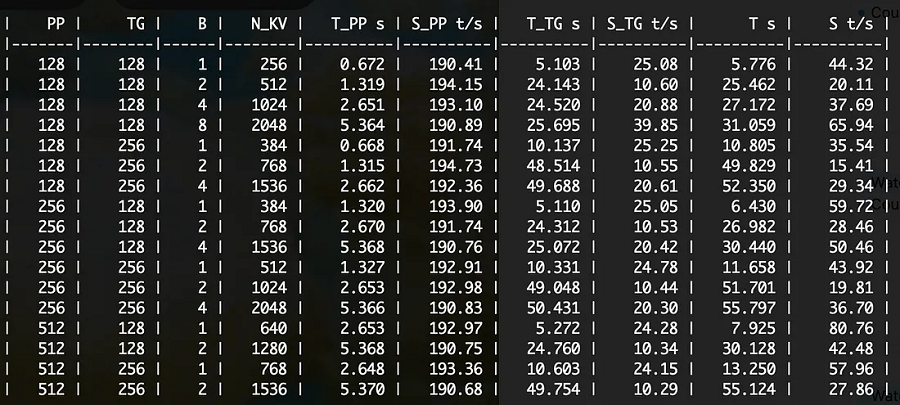
如何解码批处理工作台?

对于我们的评估,我们可以使用 T_PP(第一个标记的时间)、S_PP(快速处理速度)和 S_TG(文本生成速度)。通过比较两者,我们可以看到(例如)Q4 的快速处理速度比 f16 快约 50 个标记/秒。
还有其他方法可以评估量化模型。其中之一是困惑度。
困惑度(perplexity)是用于评估语言模型的常用指标。它衡量模型对数据样本的预测能力。困惑度分数越低,表示语言模型在预测下一个单词方面表现越好,而困惑度分数越高,则表示模型对下一个单词的预测能力越不确定或“困惑”。
在模型上运行困惑度评估。如果你选择这样做,这将花费大约 1 小时:
# Calculate the perplexity of ggml-model-Q2_K.gguf
./perplexity -m ./models/nous-hermes-2-mistral-7B-DPO/ggml-model-Q2_K.gguf -f /Users/ingrid/Downloads/test-00000-of-00001.parquet5、运行量化后的模型
# start inference on a gguf model
./main -m ./models/nous-hermes-2-mistral-7B-DPO/ggml-model-Q4_K_M.gguf -n 128那么其他(较小)量化呢?
事情会变得更加棘手和耗时。例如,如果我们想进行 XXS 量化:
# XXS Quantization
./quantize ./models/nous-hermes-2-mistral-7B-DPO/ggml-model-f16.gguf ./models/nous-hermes-2-mistral-7B-DPO/ggml-model-IQ2_XXS.gguf IQ2_XXS...然后我们需要创建一个重要性矩阵(imatrix),如你在下面的屏幕截图中的消息中所看到的那样。

什么是重要性矩阵?
重要性矩阵 (imatrix) 为神经网络中的每个权重或激活分配一个重要性分数。此重要性分数通常根据模型输出对该特定权重或激活变化的敏感度计算得出。重要性矩阵允许有针对性的量化,其中最关键的组件以更高的精度保留,而不太重要的组件则被量化以节省内存和计算资源。这种有针对性的方法在量化到非常低的精度(即 2 位或更低)时尤其重要,因为它有助于保持模型的实用性。
如何构建重要性矩阵?
因此,我研究了如何从此 README 中创建 imatrix,并下载了 wiki 原始数据集,并尝试使用这个 bash 命令来创建 imatrix(如果你有 8 小时或比我更强大的计算机,请尝试一下):
# see for documentation: https://github.com/ggerganov/llama.cpp/blob/master/examples/imatrix/README.md
./imatrix -m <some_fp_model> -f <some_training_data>
# This is the code I ran to start generating a imatrix (take 8 hours)
./imatrix -m ./models/nous-hermes-2-mistral-7B-DPO/ggml-model-f16.gguf -f /Users/ingrid/Downloads/test-00000-of-00001.parquet在我的 32GB M1 Mac 上,这会花费很长时间(对于 imatrix 估计大约需要 8 个小时),所以我没有这样做。

6、结束语
量化是一种强大的技术,可以减少大型语言模型 (LLM) 的内存占用和计算需求,而不会显著影响性能。本文深入探讨了量化,包括用于微调量化模型的朴素量化、k 均值量化和 QLoRA 等方法。
通过使用相关的类比和示例,我们展示了量化如何将 LLM 的密集参数空间转换为更易于管理的形式,从而提高效率和速度。我们还介绍了量化 LLM 的实际应用,从边缘计算到企业用例。
实践指南演示了使用 llama.cpp 量化 LLM,并介绍了下载模型、转换、量化技术和困惑度等评估指标。
随着 LLM 不断突破界限,量化将在使这些强大的模型更易于访问和部署在不同环境中方面发挥重要作用。无论你是研究人员、从业者还是 NLP 爱好者,掌握量化都是你使用大型语言模型的重要一步。
原文链接:Quantization of LLMs with llama.cpp
BimAnt翻译整理,转载请标明出处





