
NSDT工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器 - REVIT导出3D模型插件 - 3D模型语义搜索引擎 - AI模型在线查看 - Three.js虚拟轴心开发包 - 3D模型在线减面 - STL模型在线切割 - 3D道路快速建模
LLaVA,一种新的大型多模态模型,称为“大型语言和视觉助手”,旨在开发一种通用视觉助手,可以遵循语言和图像指令来完成各种现实世界的任务。 这个想法是将 GPT-4 等大型语言模型 (LLM) 的强大功能与 CLIP 等视觉编码器相结合,创建一个经过端到端训练的神经助手,可以理解多模态指令并根据多模态指令采取行动。
在人工智能领域,目标是创建一个多功能助手,能够基于视觉和语言输入理解和执行任务。 当前的方法通常依赖于独立解决任务的大型视觉模型,语言仅用于描述图像内容。 虽然有效,但这些模型具有固定的界面,交互性和对用户指令的适应性有限。
另一方面,大型语言模型(LLM)已显示出作为通用助手的通用接口的前景。 通过用语言显式地表示各种任务指令,可以引导这些模型切换和解决不同的任务。 ChatGPT 和 GPT-4 等显著成功证明了对齐的LLM在遵循人类指令方面的力量,并刺激了 LLaMA 等开源LLM的发展。
为了将这种能力扩展到多模态领域,本文引入了“视觉指令调整”,这是一种构建通用视觉助手的新颖方法。 这涉及使用 ChatGPT/GPT-4 将图像文本对转换为适当的指令跟踪数据,因为目前缺乏视觉语言指令跟踪数据。
1、GPT 辅助视觉指令数据生成
为了创建遵循指令的数据,他们从图像文本对(Xv,Xc)开始,并生成一组问题(Xq)来指导助手描述图像内容。 他们使用 GPT-4 提出诸如“简洁地描述图像”、“提供给定图像的简短描述”、“对所呈现的图片提供简洁的解释”和“总结图像的视觉内容”等问题。 这种简单的方法将原始图像-文本对扩展为其遵循指令的版本。
Human : Xq Xv<STOP>\n Assistant : Xc<STOP>\n.尽管构建成本低廉,但这个简单的扩展版本在指令和响应中缺乏多样性和深入的推理。
为了解决这个问题,他们使用纯语言 GPT-4 或 ChatGPT 作为强大的教师,仅接受文本作为输入,以生成涉及视觉内容的指令跟踪数据。 他们使用两种符号表示将图像编码为视觉特征:标题(从不同角度描述视觉场景)和边界框(定位场景中的对象并编码其概念和空间位置)。 对于给定图像的示例如下所示:

2、视觉指令调整
主要目标是利用预训练模型和视觉模型的功能:
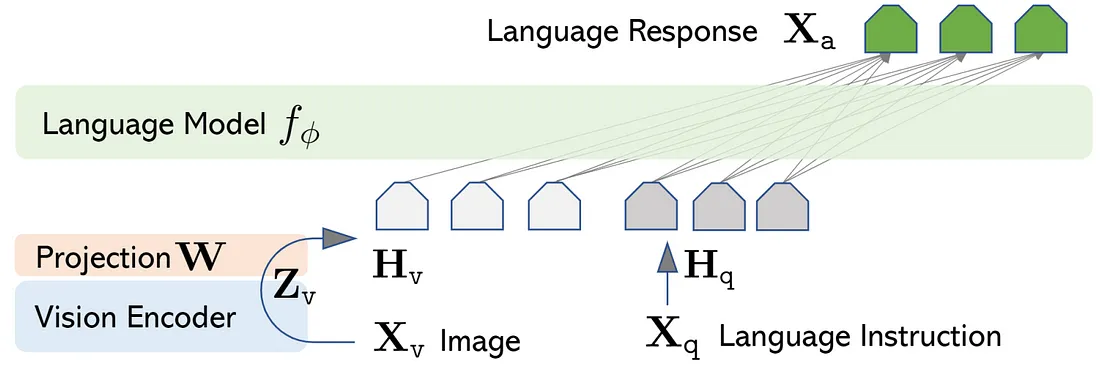
对于输入图像 Xv,它考虑预先训练的 CLIP 视觉编码器 ViT-L/14 ,它提供视觉特征 Zv = g(Xv)。 实验中考虑了最后一个 Transformer 层之前和之后的网格特征。 它考虑一个简单的线性层将图像特征连接到词嵌入空间。 具体来说,应用可训练的投影矩阵 W 将 Zv 转换为语言嵌入标记 Hq,其与语言模型中的词嵌入空间具有相同的维度:
Hv = W · Zv, with Zv = g(Xv)因此有一系列视觉标记 Hv。 LLaVa 使用简单的投影矩阵连接预训练的 CLIP ViT-L/14 视觉编码器和大型语言模型 Vicuna。 我们考虑一个两阶段的指令调整过程:
- 阶段1:特征对齐的预训练。 仅基于 CC3M 的子集更新投影矩阵。
- 阶段2:端到端微调。投影矩阵和 LLM 均针对两种不同的使用场景进行更新:
- 可视聊天:LLaVA 针对我们生成的多模式指令跟踪数据进行了微调,用于面向日常用户的应用程序。
- 科学 QA:LLaVA 在科学领域的多模态推理数据集上进行了微调。

用于训练模型的输入序列:
- Xsystem-message =“一个好奇的人类和一个人工智能助手之间的聊天。 助理会针对人类的问题给出有用、详细且礼貌的答案。”
- <STOP>=###。
该模型经过训练来预测辅助答案以及在哪里停止,因此仅使用绿色序列/标记来计算自回归模型中的损失。
结果示例:


3、LlaVA在线演示
你可以点击这里尝试部署的演示。以下是一些对话的截图。
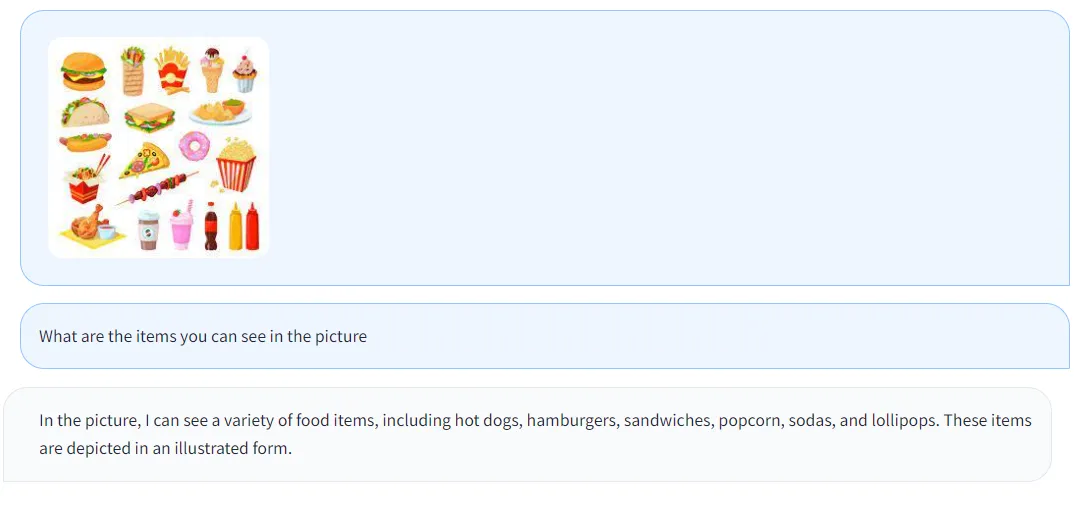
- 询问图片中包含哪些饮料食品
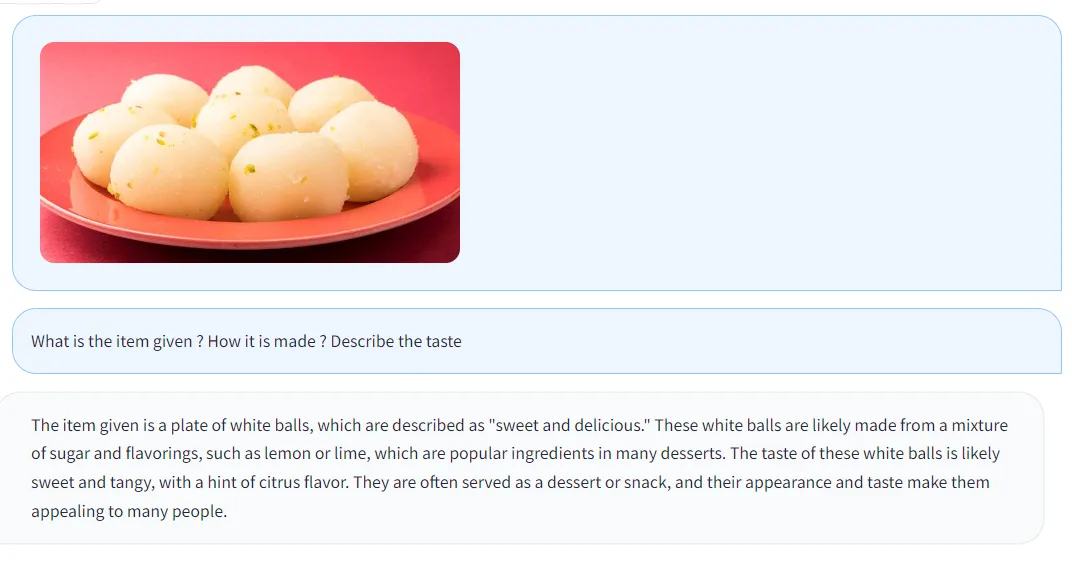
- 询问图片中食物的原料和口味
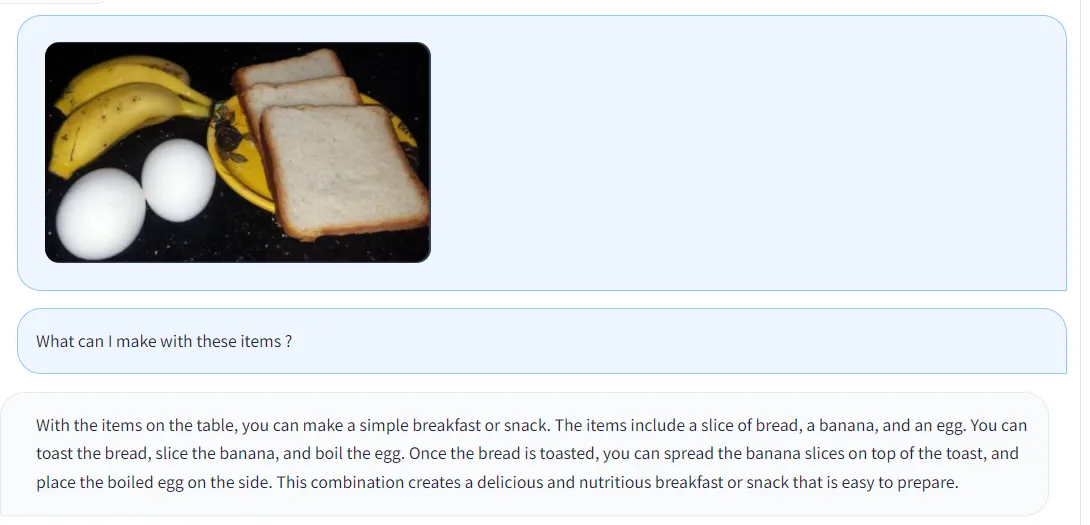
- 询问图片中食物的制作方法
4、LLaVA训练
LLaVA详细的训练过程将在下一篇文章中讲解。
原文链接:Visual Instruction Tuning, Large Language and Vision Assistant (LLaVA)
BimAnt翻译整理,转载请标明出处





