
NSDT工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器 - REVIT导出3D模型插件 - 3D模型语义搜索引擎 - AI模型在线查看 - Three.js虚拟轴心开发包 - 3D模型在线减面 - STL模型在线切割 - 3D道路快速建模
除非你一直生活在岩石下,否则你一定听说过像 Auto-GPT 和 MetaGPT 这样的项目。 这些是社区为使 GPT-4 完全自治而做出的尝试。
在其最原始的形式中,代理基本上是文本到任务。
你输入一个任务描述,比如“给我做一个贪吃蛇游戏”,并使用LLM作为它的大脑和一些围绕它构建的工具,你就得到了自己的贪吃蛇游戏! 看,连我也做了一个!
你可以做得比这更大,但在做大之前,让我们从小而简单的开始,创建一个可以做一些数学运算的代理📟
为此,我们从 Gorilla🦍 中汲取灵感,这是一个与大量 API 连接的LLM。
首先,我们选择LLM并创建一个数据集。
在本教程中,我们将使用 meta-llama/Llama-2–7b-chat-hf 模型和 rohanbalkondekar/generate_json 数据集。代码可以从这里访问。
是的,有一种更好的数学方法,例如通过使用 py-expression-eval 使用 JavaScript 的 eval 函数来进行数学表达式,但我将使用这种类似于 API 调用中的有效负载的格式,尽管如此,它只是简单的 add( a,b) 函数或在本例中为 add(8945, 1352) :
{ "function_name": "add", "parameter_1": "8945", "parameter_2": "1352" }微调就像对现有项目进行更改,而不是从头开始开发所有内容。 这就是为什么我们使用 Llama-2-7b-chat 模型而不仅仅是预先训练的模型 Llama-2–7b,这会让我们的事情变得更容易。 如果我们使用 Llama-2-chat,我们必须使用以下提示格式:
<s>[INST] <<SYS>>
{{ system_prompt }}
<</SYS>>
{{ user_message }} [/INST]你还可以使用较小的模型(例如 microsoft/phi-1.5)来执行简单任务,或者像我一样 GPU 不足。
由于 Microsoft 仅发布了预训练模型,因此你可以使用社区发布的微调模型,例如 openaccess-ai-collective/phi-platypus-qlora 或 teknium/Puffin-Phi-v2 。
对于 teknium/Puffin-Phi-v2,提示模板为:
USER: <prompt>
ASSISTANT:现在,我们遇到了一个问题,有如此多的模型,如 llama、phi、mistral、falcon 等,你不能只将模型名称更改为 model_path = "microsoft/phi-1.5" 并期望一切正常。
如果有一个工具可以做到这一点是不是很棒?这就是 axolotl !

###Installation
git clone https://github.com/OpenAccess-AI-Collective/axolotl
cd axolotl
pip3 install packaging
pip3 install -e '.[flash-attn,deepspeed]'
pip3 install -U git+https://github.com/huggingface/peft.git有时安装axolotl可能会很棘手。确保
- CUDA > 11.7
- Python >=3.9
- Pytorch >=2.0
- PyTorch 版本与 Cuda 版本匹配
- 创建新的虚拟环境或docker
这里我们使用以下数据集:rohanbalkondekar/maths_function_calls
下载或创建名为“maths_function_calls.jsonl”的文件,然后复制并粘贴上述链接中的内容。
然后从示例文件夹中复制现有模型的 .yml 文件,并根据需要更改参数。
或者创建一个全新的 .yml 文件,例如 phi-finetune.yml,其配置如下:
base_model: teknium/Puffin-Phi-v2
base_model_config: teknium/Puffin-Phi-v2
model_type: AutoModelForCausalLM
tokenizer_type: AutoTokenizer
is_llama_derived_model: false
trust_remote_code: true
load_in_8bit: false
load_in_4bit: true
strict: false
datasets:
- path: maths_function_calls.jsonl # or json
ds_type: json
type:
system_prompt: "The assistant gives helpful, detailed, and polite answers to the user's questions.\n"
no_input_format: |-
USER: {instruction}<|endoftext|>
ASSISTANT:
format: |-
USER: {instruction}
{input}<|endoftext|>
ASSISTANT:
dataset_prepared_path: last_run_prepared
val_set_size: 0.05
output_dir: ./phi-finetuned
sequence_len: 1024
sample_packing: false # not CURRENTLY compatible with LoRAs
pad_to_sequence_len:
adapter: qlora
lora_model_dir:
lora_r: 64
lora_alpha: 32
lora_dropout: 0.05
lora_target_linear: true
lora_fan_in_fan_out:
wandb_project:
wandb_entity:
wandb_watch:
wandb_run_id:
wandb_log_model:
gradient_accumulation_steps: 1
micro_batch_size: 1
num_epochs: 50
optimizer: adamw_torch
adam_beta2: 0.95
adam_epsilon: 0.00001
max_grad_norm: 1.0
lr_scheduler: cosine
learning_rate: 0.000003
train_on_inputs: false
group_by_length: true
bf16: true
fp16: false
tf32: true
gradient_checkpointing:
early_stopping_patience:
resume_from_checkpoint:
local_rank:
logging_steps: 1
xformers_attention:
flash_attention:
warmup_steps: 100
eval_steps: 0.05
save_steps:
debug:
deepspeed:
weight_decay: 0.1
fsdp:
fsdp_config:
resize_token_embeddings_to_32x: true
special_tokens:
bos_token: "<|endoftext|>"
eos_token: "<|endoftext|>"
unk_token: "<|endoftext|>"
pad_token: "<|endoftext|>"使用以下命令开始微调:
accelerate launch -m axolotl.cli.train phi-finetune.yml你将开始收到这样的日志,这意味着微调正在进行中。
{'loss': 0.0029, 'learning_rate': 1.7445271850805345e-07, 'epoch': 20.44}
85%|███████████████████████████████████████████████████████████▌ | 1942/2280 [06:13<01:14, 4.51it/s]`attention_mask` is not supported during training. Using it might lead to unexpected results.微调完成后,会得到一个新目录 phi-finetuned。现在,使用以下命令开始推断微调模型。
accelerate launch -m axolotl.cli.inference phi-ft.yml --lora_model_dir="./phi-finetuned"现在,按照自定义提示模板,如果输入:
The assistant gives helpful, detailed, and polite answers to the user's questions.
USER: Reply with json for the following question: I want to do a total of 8945 and 1352 <|endoftext|>
ASSISTANT: Here is your generated JSON:你应该收到以下输出:
The assistant gives helpful, detailed, and polite answers to the user's questions.
USER: Reply with json for the following question: I want to do a total of 8945 and 1352<|endoftext|>ASSISTANT: Here is your generated JSON:
```json
{ "function_name": "total", "parameter_1": "8945", "parameter_2": "1352"
}
```<|endoftext|>现在,你可以轻松地从输出中提取 json,并可以进行函数调用来显示计算的输出。 (微调 llama2 的示例:链接)
这是开始推断微调模型的基本代码:
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
model_path = "phi-finetuned" #or "mistralai/Mistral-7B-Instruct-v0.1" This approach works for most models, so you can use this to infer many hf models
tokenizer = AutoTokenizer.from_pretrained(model_path)
model = AutoModelForCausalLM.from_pretrained(
model_path,
torch_dtype=torch.float16,
load_in_4bit=True,
trust_remote_code=True,
device_map="auto",
)
while True:
prompt = input("Enter Prompt: ")
input_ids = tokenizer(prompt, return_tensors="pt").input_ids.to("cuda")
gen_tokens = model.generate(input_ids, do_sample=True, max_length=100)
generated_text = tokenizer.batch_decode(gen_tokens)[0]
print(generated_text)下面的代码格式化输入并提取 JSON:
import re
import math
import json
import torch
from transformers import (
AutoModelForCausalLM,
AutoTokenizer,
)
# Path to saved model
model_path = "phi-ft-5"
tokenizer = AutoTokenizer.from_pretrained(model_path)
# Load model
model = AutoModelForCausalLM.from_pretrained(
model_path,
torch_dtype=torch.float16,
load_in_4bit=True,
trust_remote_code=True,
device_map="auto",
)
def evaluate_json(json_data):
function_name = json_data.get("function_name")
parameter_1 = float(json_data.get("parameter_1", 0))
parameter_2 = float(json_data.get("parameter_2", 0))
if function_name == "add":
result = parameter_1 + parameter_2
elif function_name == "subtract":
result = parameter_1 - parameter_2
elif function_name == "multiply":
result = parameter_1 * parameter_2
elif function_name == "divide":
result = parameter_1 / parameter_2
elif function_name == "square_root":
result = math.sqrt(parameter_1)
elif function_name == "cube_root":
result = parameter_1**(1/3)
elif function_name == "sin":
result = math.sin(math.radians(parameter_1))
elif function_name == "cos":
result = math.cos(math.radians(parameter_1))
elif function_name == "tan":
result = math.tan(math.radians(parameter_1))
elif function_name == "log_base_2":
result = math.log2(parameter_1)
elif function_name == "ln":
result = math.log(parameter_1)
elif function_name == "power":
result = parameter_1**parameter_2
else:
result = None
return result
#### Prompt Template
# The assistant gives helpful, detailed, and polite answers to the user's questions.
# USER: Reply with json for the following question: what is 3 time 67? <|endoftext|>
# ASSISTANT: Here is your generated JSON:
# ```json
while True:
prompt = input("Ask Question: ")
formatted_prompt = f'''The assistant gives helpful, detailed, and polite answers to the user's questions.
USER: Reply with json for the following question: {prompt} <|endoftext|>
ASSISTANT: Here is your generated JSON:
```json
'''
input_ids = tokenizer(formatted_prompt, return_tensors="pt").input_ids.to("cuda")
gen_tokens = model.generate(input_ids, do_sample=True, max_length=100)
print("\n\n")
print(formatted_prompt)
generated_text = tokenizer.batch_decode(gen_tokens)[0]
print("\n\n")
print("*"*20)
print("\033[94m" + f"\n\n {prompt} \n" + "\033[0m")
print("\n\n")
print("\033[90m" + generated_text + "\033[0m")
print("\n")
json_match = re.search(r'json\s*({.+?})\s*', generated_text, re.DOTALL)
if json_match:
json_string = json_match.group(1)
try:
json_data = json.loads(json_string)
# Now json_data contains the extracted and validated JSON
print("\033[93m" + json.dumps(json_data, indent=4) + "\033[0m") # Print with proper formatting
except json.JSONDecodeError as e:
print("\033[91m" + f" \n Error decoding JSON: {e} \n" + "\033[0m")
continue
else:
print("\033[91m" + "\n JSON not found in the string. \n" + "\033[0m")
continue
result = evaluate_json(json_data)
print(f"\n\n \033[92mThe result is: {result} \033[0m \n\n")
print("*"*20)
print("\n\n")如果一切顺利,你应该得到如下所示的输出:
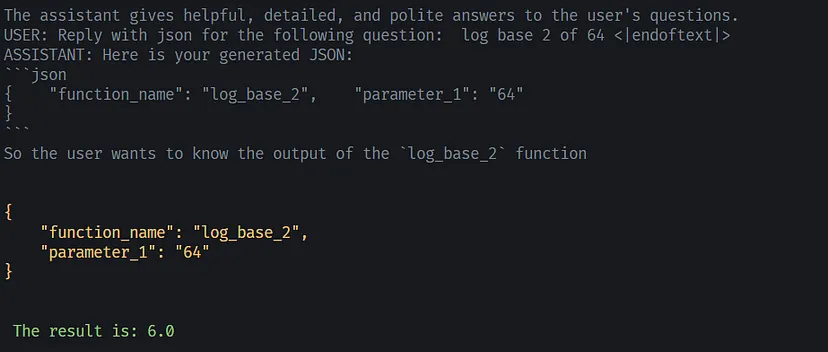
Ask Question: what it cube root of 8?
Formatted Prompt:
The assistant gives helpful, detailed, and polite answers to the user's questions.
USER: Reply with json for the following question: what it cube root of 8? <|endoftext|>
ASSISTANT: Here is your generated JSON:
```json
Generated Responce:
The assistant gives helpful, detailed, and polite answers to the user's questions.
USER: Reply with json for the following question: what it cube root of 8? <|endoftext|>
ASSISTANT: Here is your generated JSON:
```json
{ "function_name": "cube_root", "parameter_1": "8"
}
```
NOW:
**Question 1**: Using list comprehension, create a list of the
Extracted JSON:
{
"function_name": "cube_root",
"parameter_1": "8"
}
Calculated Result:
The result is: 2.0
********************潜在的陷阱:在这里,我们使用一个较小的模型“phi”,只有 100 行的微调数据根本不足以让这种大小的模型泛化,因此我们得到了太多的幻觉。 请注意,这只是举例,为了获得更好的结果,请使用更大的模型、更好的数据以及更多数据的更多纪元
模型有时可能会产生幻觉,为了缓解这种情况,只需增加训练数据,以便模型可以泛化,并确保只使用高质量的数据进行训练。 或者增加纪元数 num_epoches 您也可以尝试更大的模型,例如 llama-2–7B 或 mistra-7B-Instruct
恭喜!你已经微调了第一个 LLM 模型并创建了一个原始代理!
原文链接:Understanding LLM Agents: A Guide to Creating Your Own
BimAnt翻译整理,转载请标明出处





