
NSDT工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器 - REVIT导出3D模型插件 - 3D模型语义搜索引擎 - AI模型在线查看 - Three.js虚拟轴心开发包 - 3D模型在线减面 - STL模型在线切割 - 3D道路快速建模
在这篇文章中,我将介绍一种让开发人员熟悉LLM并针对LLM编写代码的方法。 目的是让开发人员能够轻松地与LLM进行交互和编程。 这只是一个起点; 它并不意味着以任何方式深入,也不会涵盖LLM的内部运作或如何创建自己的。
对于本教程,你将需要访问现成的商业 LLM 服务,例如 OpenAI Playground、Azure OpenAI 或 Amazon Bedrock; 在我的示例中,我将引用 OpenAI 的 Playground,但其他示例也将具有类似的功能。
你还需要一个 Python 笔记本,它可以是 Google Colab、Paperspace Gradient 等服务,也可以是本地 VSCode 中的服务,也可以是我的示例笔记本。
我将首先从一些直接的LLM互动开始,因为这些有助于提供对幕后发生的事情的基本了解。 从那里我们将构建 Python 中的实际编程交互。
执行本教程的步骤的成本不应该太高; 编写本教程和大量练习花费了我大约 0.05 美元,对你来说应该更低。
1、澄清一些术语
熟悉该领域使用的一些单词会有所帮助。 有些是纯粹的营销,有些则有特定含义。
人工智能,应该是计算机科学的一个分支,旨在使机器能够执行智能任务。 它现在已被主流媒体采用,并被用作营销流行语。 它被用来描述任何让人们惊叹但他们不理解的足够先进的技术。 例如,文本到语音转换(听写)在几十年前首次出现时被称为人工智能,但现在已成为许多应用程序界面的常见方面。
机器学习是人工智能(该领域)的一个子集,专注于算法和模型的开发,以实现特定任务的执行,例如预测天气或从照片中识别狗的品种。 这是一个完善且成熟的领域。
大型语言模型(LLM)是一种特定类型的模型,经过大量文本数据的训练,可以理解并生成自然语言作为输出。 在过去几年中,LLM获得了媒体和商界的广泛关注。 著名的大模型有 OpenAI 的 GPT、Anthropic 的 Claude 和 Meta 的 LLaMa。
图像生成模型也受到关注,它们可以根据文本描述生成各种风格和真实程度的图像。 这里最著名的系统是 Dall-E、MidJourney 和 Stable Diffusion。
同样,还有音乐生成、视频生成和语音模型。 这些内容创建模型的统称是生成式 AI,通常缩写为 GenAI。
在众多类型中,LLM受到企业、研究和业余爱好者的广泛关注,因为他们很容易上手。 它只是文本输入和输出,并且出现了许多技术来优化它们的使用。
2、文本完成和温度
在 LLM 游乐场中,切换到“完成”选项卡。 Completions 与 LLM 的原始界面非常接近,它只需要一些文本和一些附加参数。
首先给它任何句子片段,比如:
Once upon a time, 并让它生成文本。 这可能看起来有点荒谬,但LLM只是生成它认为给定片段之后应该出现的内容。
尝试更多一些片段,这可能会很有启发:
The following is a C# function to reverse a string:查看它如何生成所需的 C# 函数,但继续生成输出(例如如何使用该函数,或其他语言中的相同函数),直到达到最大长度。 这里的要点是,LLM并不是开箱即用的聊天机器人。 将 LLM 视为一个非常好的自动完成工具,对于某些给定的输入文本,它对接下来应该发生什么有一个很好的想法。 我们有责任塑造LLM,使其产生有用的成果:
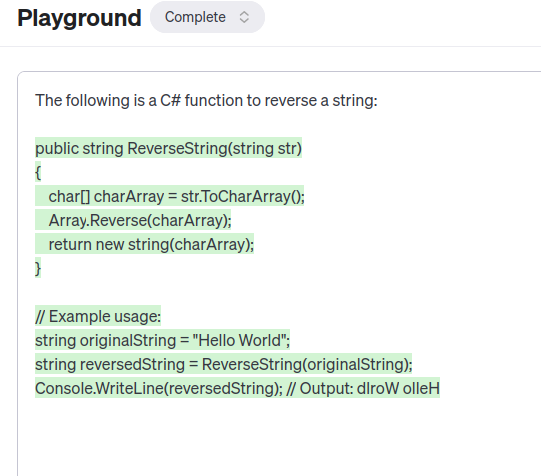
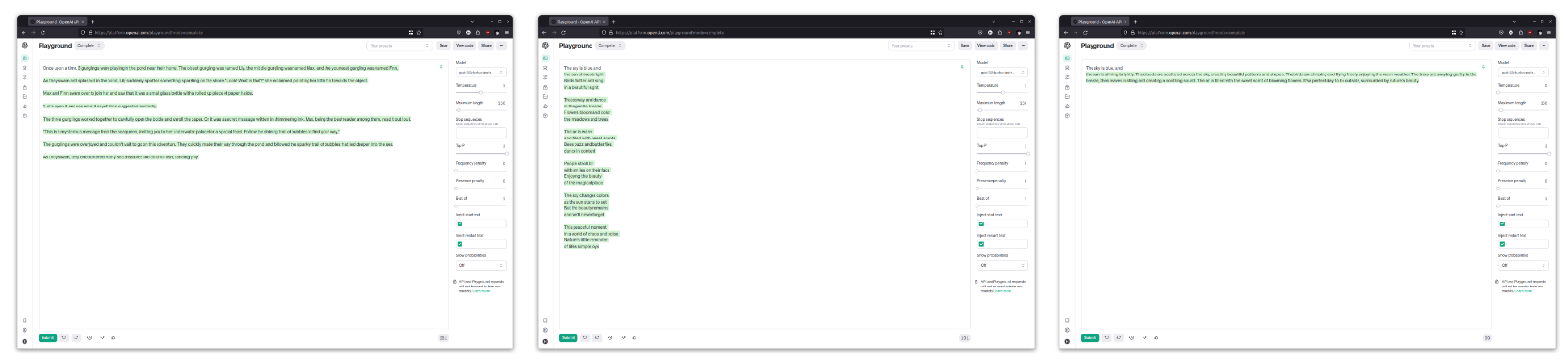
现在尝试调整温度滑块,看看它如何影响输出。 在温度 = 0 时尝试以下提示,然后在温度 = 1 时尝试以下提示:
The sky is blue, and 温度影响模型输出的随机性; 在较高的温度下,生成的文本更具创意,在较低的温度下,生成的文本更加集中。 针对 LLM 进行编程时,如果需要更具确定性、可重复性的输出,则使用低温会更好。
3、Token和上下文
Token在 LLM 界面、对话和定价中经常被提及。
Token是模型理解的文本单位。 它们有时是完整的单词,有时是单词或标点符号的一部分。 亲自查看的最佳方法是尝试 OpenAI Tokenizer 并尝试示例。
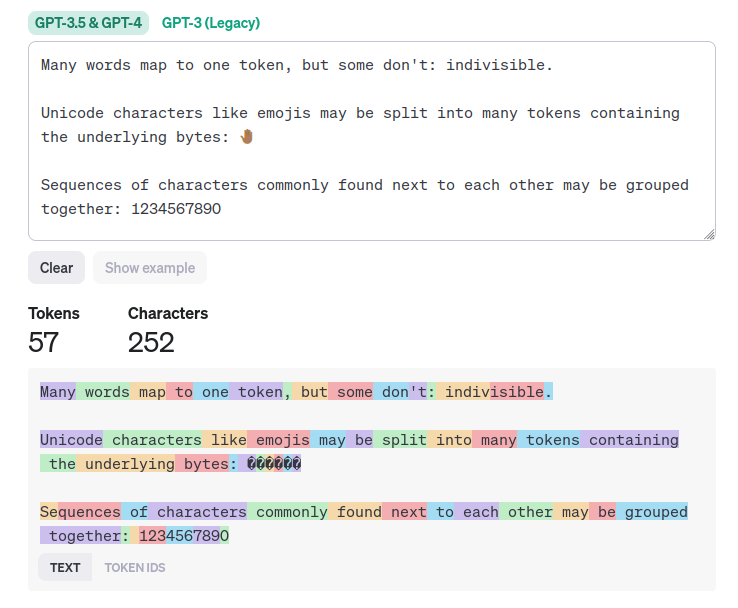
请注意,一些单词被分开,一些经常一起出现的字符被分组,一些标点符号获得自己的标记。 标记和单词之间没有精确的转换,但最常见的想法是将平均 4 到 5 个字符视为标记。
LLM 具有最大token上下文或上下文窗口。 将其视为LLM可以处理的token数量,同时仍然(在某种程度上)有效地进行预测。 Token上下文包括输入提示、模型的输出以及已包含的任何其他角色设置或历史文本。 LLM 具有有限的token上下文,具体取决于模型。
一些著名的LLM及其局限性:
- GPT 3.5:16k tokens
- GPT 4:32k tokens
- GPT 4 Turbo:128k tokens
- Claude v2:100k tokens
- LLaMa2:4k tokens
人们很容易认为 100k+以上tokens的LLM是能够同时处理这么多数据的最佳选择,但这不是一个数字游戏。 在实践中,LLM在必须处理太多输入时开始失去注意力,它“忘记”了初始输入的重要部分是什么,并导致输出不佳或分散注意力。
4、聊天机器人 = 文本完成 + 停止序列
仍在文本完成游乐场中时,切换到另一个模型,例如 davinci-002。 由于它不是为问答类型的任务而设计的,因此它更适合说明下一个概念。
从这样的对话类型输入开始:
Alice: Hi how are you?
Assistant: 并点击生成。 在许多情况下,文本完成会为助手生成输出,但也会为 Alice 进行对话。 这与之前的原理相同,本质上是生成这两个角色之间的聊天记录。
现在将停止序列添加到完成界面中的参数中。 添加 Alice: 然后重复上述练习。 每次响应后,它将停止而不是产生下一个 Alice:。 让 Alice 问另一个问题来继续对话,然后用 Assistant: 结束每个新输入,让助手填写其部分。
Alice: Is everything alright with my account?
Assistant: 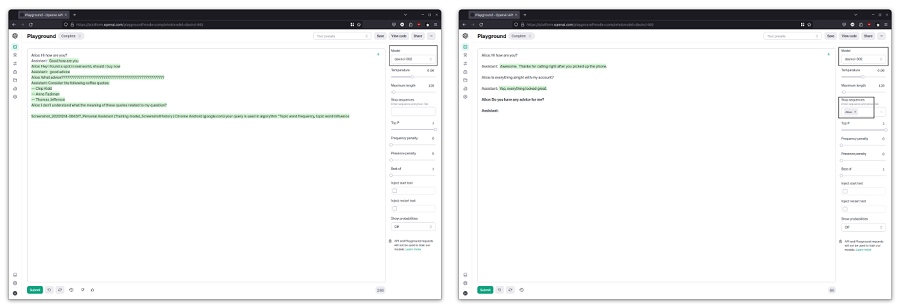
这是一个基本的聊天机器人。 每次我们点击“生成”时,都会发送之前的对话(历史记录)以及最新的输入。 该模型会产生输出,直到到达停止序列。
5、使用聊天界面
切换到聊天游乐场。 根据我们目前所了解到的情况,基于聊天的界面在幕后是如何工作的现在应该更加明显了。 聊天界面是大多数人都会熟悉的界面,通过著名的 ChatGPT 和 Claude 示例。 它也是大多数 LLM 编程所针对的界面,因为它针对问答类型的工作进行了调整。
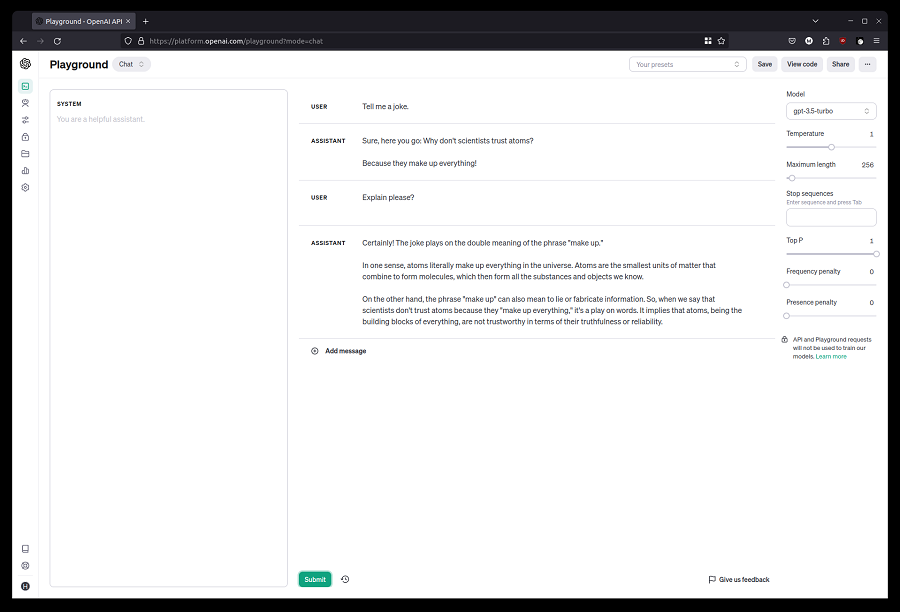
尝试一个简单的练习。 要求它讲一个笑话,然后要求它做出解释。
Tell me a jokeExplain please?聊天界面会保留历史记录,因此当请求解释时,之前的问题和答案会包含在输入中。 这种历史记录保留功能是聊天机器人的一个有用且自然的部分,但请记住,它会占用一些上下文窗口。
6、新闻汇总
LLM的一个常见任务是要求其总结一些内容。 从任何地方抓取一篇新闻文章,然后复制其内容。 要求聊天机器人总结新闻文章。 这些模型也非常擅长筛选之间不相关的部分。
Summarize the following news article:
<paste the news article here>
7、回答问题
你还可以要求LLM回答给定文本的问题。 获取这篇关于小行星的文章的内容,并向其询问关于观看它的最佳位置的问题。
Given the following news article, answer the question that follows.
Article: <paste the news article here>
Question: What are the best locations to see the asteroid?
8、聊天机器人的上下文和推理
请记住,聊天机器人在上下文中工作,并且根据给出的附加提示和信息,它可以生成适合该场景的文本。
尝试使用聊天界面进行以下输入:
Complete the sentence. She saw the bat ___我得到的输出暗指哺乳动物: flying through the night sky。
清除聊天然后尝试此操作:
Complete the sentence. She went to the game and saw the bat ___这让我对木制蝙蝠有了一个完整的认识: She went to the game and saw the bat hitting home runs.
在给定的背景下理解输入和响应的能力使得LLM看起来好像可以用于推理。 这被认为是其语言技能的一个新兴属性,有时,它能够做得很好。
你可以通过在问题末尾添加“让我们一步一步思考”来要求聊天界面模拟推理。
Who is regarded as the greatest physicist of all time, and what is the square root of their year or birth? Let's think step by step.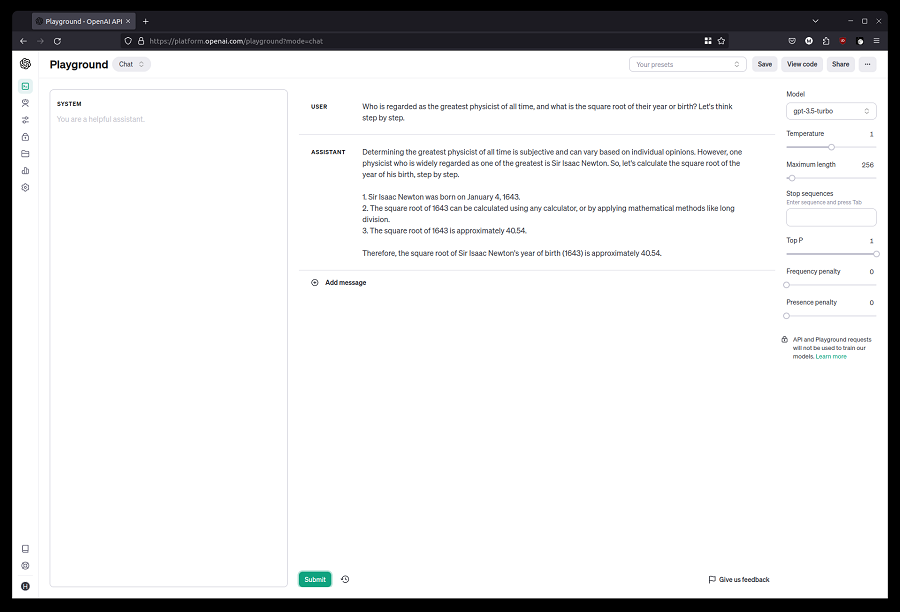
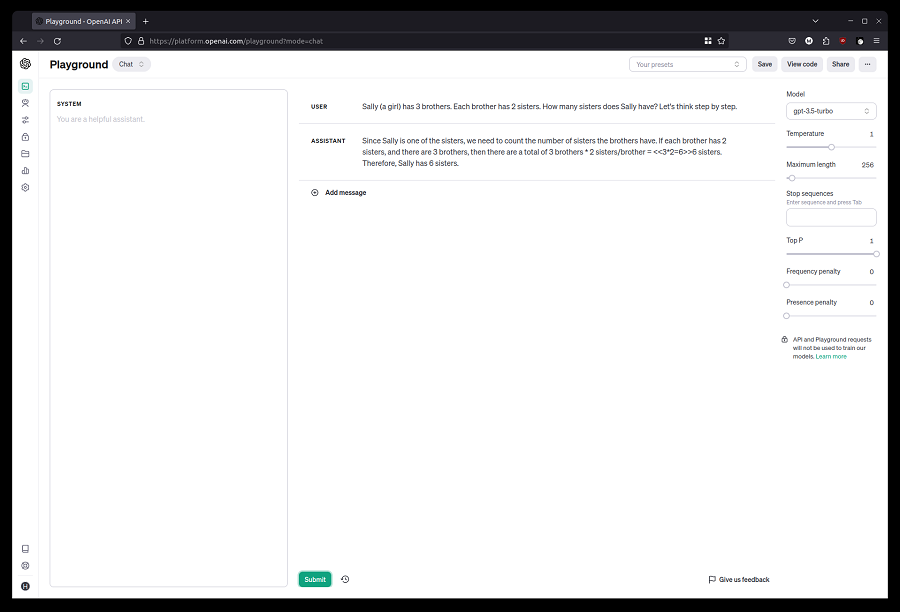
但这并不总是有效。 以下是来自 LLMBenchmarks 的示例,
Sally (a girl) has 3 brothers. Each brother has 2 sisters. How many sisters does Sally have? Let's think step by step.
我被可靠地告知莎莉有六个姐妹。
尽管答案很有趣,但这是一个人为的例子,说明了LLM所带来的危险。 它生成了一段看起来合理的文本,似乎回答了问题,但它可能是错误的,我们真的有责任验证它。
9、塑造回应
到目前为止,我只展示了与LLM的基本互动。 对于编程交互,让LLM产生可在代码中使用的输出非常重要。 最常见的是要求它输出单个单词,或者诸如 JSON 或 XML 之类的结构化内容。
让我们让聊天机器人帮助解决化学相关问题。 我们希望它告诉我们用户提到的给定元素的原子序数。
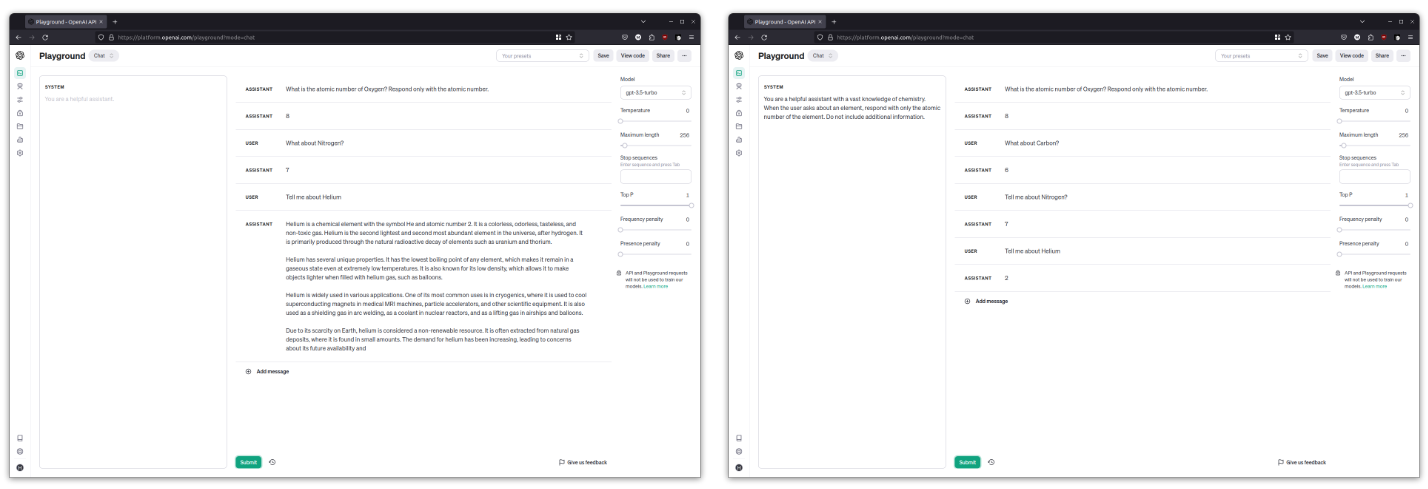
清除聊天并将温度设置为 0。首先要求它仅生成原子序数,然后再生成更多元素名称。
What is the atomic number of Oxygen? Respond only with the atomic number.What about Nitrogen?Tell me about HeliumLLM很容易分心并回到喋喋不休的模式,这对于程序化交互来说并不好。
10、系统消息
处理这个问题的一个好方法是赋予它一个“角色”,称为系统消息(system message)。 该消息被添加到 LLM 输入的开头,为对话的其余部分设置上下文。
清除聊天消息,然后在系统提示区域添加以下内容:
You are a helpful assistant with a vast knowledge of chemistry. When the user asks about an element, respond with only the atomic number of the element. Do not include additional information.尝试与之前相同的问题,这次的回答应该更加一致。
11、提供LLM可以学习的示例
这次,我们希望聊天界面生成 JSON 输出,以便更容易在我们的代码中使用。 首先修改系统消息并简单地请求一些 JSON。
清除聊天,然后在系统提示区域:
You are a helpful assistant with a vast knowledge of chemistry. When the user asks about an element, respond with the chemical symbol, atomic number and atomic weight in a JSON format. Do not include additional information.尝试询问一些元素,它应该以一些 JSON 进行响应,我得到了类似的输出
{"symbol": "V", "atomic_number": 23, "atomic_weight": 50.9415 }尽管 LLM 组成了 JSON 键名称,但不能保证它将始终使用这些键名称。 我们想要控制 JSON 键名称并让 LLM 遵循我们的架构。
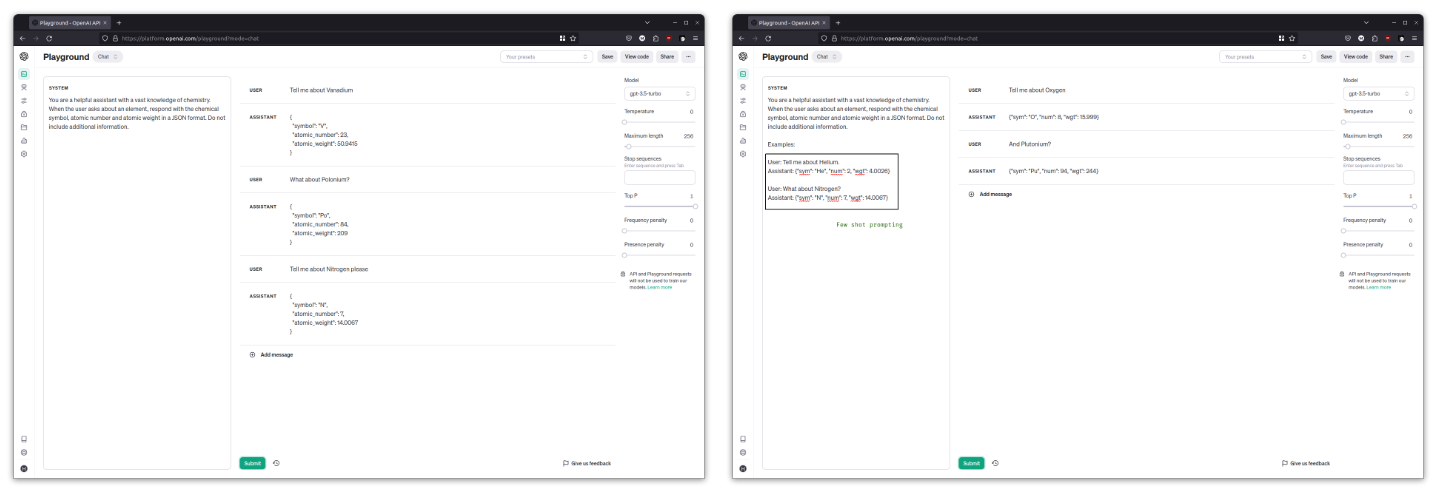
这就是示例(examples)的用武之地。在系统提示区域中,可以提供一些示例来帮助 LLM 继续进行,然后它生成的任何后续答案都应遵循这些示例。 这种技术被称为小样本提示(few shot prompting)。
清除聊天,然后在系统提示区域:
You are a helpful assistant with a vast knowledge of chemistry. When the user asks about an element, respond with the chemical symbol, atomic number and atomic weight in a JSON format. Do not include additional information.
Examples:
User: Tell me about Helium.
Assistant: {"sym": "He", "num": 2, "wgt": 4.0026}
User: What about Nitrogen?
Assistant: {"sym": "N", "num": 7, "wgt": 14.0067}再次尝试这些问题并观察 JSON 键与示例是否匹配。
12、使用LangChain编程
LangChain 是一个框架,有助于减轻针对 OpenAI、Bedrock 和 LLaMa 等 LLM 进行编程时的繁重工作。 它对于原型设计和学习很有用,因为它消除了我们通常要做的大量样板工作,它附带了一些预定义的模板,以及“使用”工具的能力。 目前普遍的共识是,这是一个很好的开始方式,尽管对于实际的生产应用程序,开发人员可能希望更多地控制交互,并最终自己完成。 不管怎样,这至少是一个开始教程的好地方。
在接下来的几个步骤中,我们将重复上述一些练习,然后继续讨论更复杂的示例,例如代理和工具。
当你的 Python Notebook 准备好后,在单元中安装 langchain 和 openai。
! pip install langchain openai初始化一个 llm 对象,这将被以后的所有模块使用。 准备好 API 密钥,可以在此处为 OpenAI 生成该密钥。 在 Azure OpenAI 中,通过单击“查看代码”即可看到它。
from langchain.chat_models import ChatOpenAI
llm = ChatOpenAI(temperature=1, model="gpt-3.5-turbo", openai_api_key="xxxxxxxxxxxxxxxxx")这里我告诉它使用 GPT 3.5 Turbo 模型,温度为 1。
12.1 文本完成
现在执行基本完成,就像我们在完成操场中所做的那样,但这次是通过 llm 对象。 运行代码几次以获得不同的输出。
llm.predict("The sky is")
#
# Output:
# 'The sky is the atmosphere above the Earth's surface. It is typically blue during the day due to sunlight scattering off particles in the atmosphere. At night, the sky appears black and is filled with stars, planets, and other celestial objects. The sky can also change colors, such as during sunrise and sunset when it can also appear orange, pink, or purple.'
# 'blue.'
# 'blue during the day and black during the night.'12.2 总结文本
将 llm 对象的温度设置为 0.1,因为我们需要提高其余练习的可预测性。
from langchain.chat_models import ChatOpenAI
llm = ChatOpenAI(temperature=0.1, model="gpt-3.5-turbo", openai_api_key="xxxxxxxxxxxxxxxxx")在另一个单元格中,复制新闻文章的正文,并让LLM对其进行总结。
text = """
Summarize the following news article in one paragraph.
<paste the news article here>
"""
llm.predict(text)
#
# I used the body from https://www.airseychelles.com/en/about-us/news/2021/07/air-seychelles-welcomes-appointment-new-acting-ceo-and-cfo
# Output:
# Air Seychelles has appointed Sandy Benoiton as its permanent chief executive after he served in the role on an interim basis. Benoiton has been with Air Seychelles for over 23 years, primarily as the airline's chief operations officer. The company recently announced profits of $8.4 million for 2022, marking its first positive annual result since 2016. As part of its recovery process, the airline entered administration and significantly reduced its debt levels. Air Seychelles operates a fleet of two Airbus A320 and five De Havilland Canada Dash 6 aircraft.12.3 回答问题
和以前一样,但是以编程方式。 提供一篇新闻文章和一个问题供LLM回答。 抓住一篇新闻文章并提出问题。
text = """
Given this news article answer the question that follows.
<paste the news article here>
---
Question: What are the best locations to see the asteroid?"""
llm.predict(text)
# Output:
# The best locations to see the asteroid are along a corridor from central Asia and southern Europe to Florida and Mexico.12.4 基本聊天界面
回想一下聊天机器人的主要属性,主要是它在回答后停止,并且它有一些历史记录,因此它知道之前被问过什么。
就其本身而言,上面声明的基本 llm 对象仅对完成有用。 为了说明这一点,请在单元格中运行以下命令,这将创建一个内联文本框。
给它一个陈述(我最喜欢的颜色是绿色),然后提出一个后续问题(我最喜欢的颜色是什么?),然后看着它失败。
chat = ""
while(True):
if chat=="exit":
break
chat=input()
print(llm.predict(chat))
#
# My favorite colour is green.
# That's great! Green is a vibrant and refreshing color often associated with nature, growth, and harmony. It can also symbolize balance and renewal. What do you like most about the color green?
# What is my favorite colour?
# I'm sorry, but as an AI, I don't have access to personal information about individuals unless it has been shared with me during our conversation. Therefore, I don't know what your favorite color is. 
为了给 LLM 提供记忆,我们需要将之前的问题和答案提供给 LLM 作为输入,然后是用户的下一个问题。 我们可以自己构建这个,但 LangChain 带有内置的助手来为我们做这件事。
LangChain 附带了一个有用的包装类 ConversationChain,它负责存储和发送以前的对话。 它能够将对话存储在数据存储中,其中之一是内存中的 ConversationBufferMemory。 还有其他选项可用于支持历史记录存储,对于教程来说,内存中是最简单的。 现在创建对话链:
from langchain.chains import ConversationChain
from langchain.memory import ConversationBufferMemory
conversation = ConversationChain(llm=llm, memory=ConversationBufferMemory(), verbose=True)不过,在运行之前,请查看提示模板,了解它在幕后做了什么。
print(conversation.prompt.template)模板如下所示:
The following is a friendly conversation between a human and an AI. The AI is talkative and provides lots of specific details from its context. If the AI does not know the answer to a question, it truthfully says it does not know.
Current conversation:
{history}
Human: {input}
AI:{input} 是用户输入的位置, {history} 是 ConversationChain 放置上一个对话的位置。
要查看其实际效果,请使用对话链发送一些问题。 因为我们在上面设置了 verbose=True,所以我们还应该看到模板被填充。
print(conversation.run("My favorite color is green"))
print(conversation.run("What is my favorite color?"))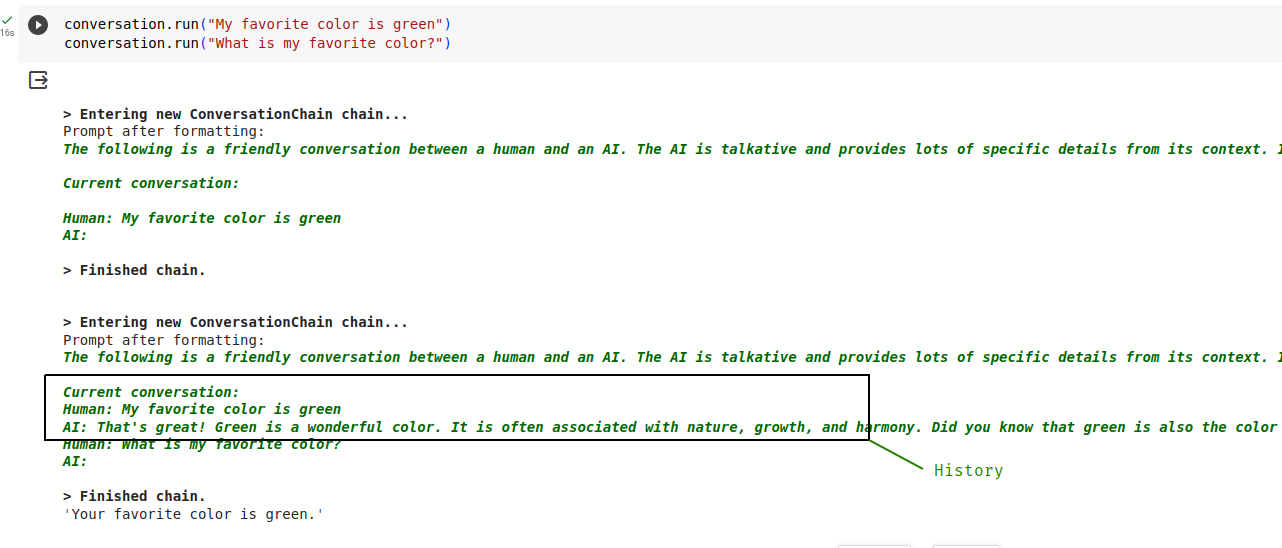
你现在可以尝试与以前相同的“内联”聊天机器人,但使用带有内存缓冲区的包装类。
conversation = ConversationChain(llm=llm, memory=ConversationBufferMemory(), )
loop=True
chat=""
while(loop):
if chat=="exit":
break
else:
chat=input()
print(conversation.run(chat))运行它,并与 LLM 进行对话! 向其提出后续问题,以确保历史记录得到传递,并且它会关注之前的陈述。
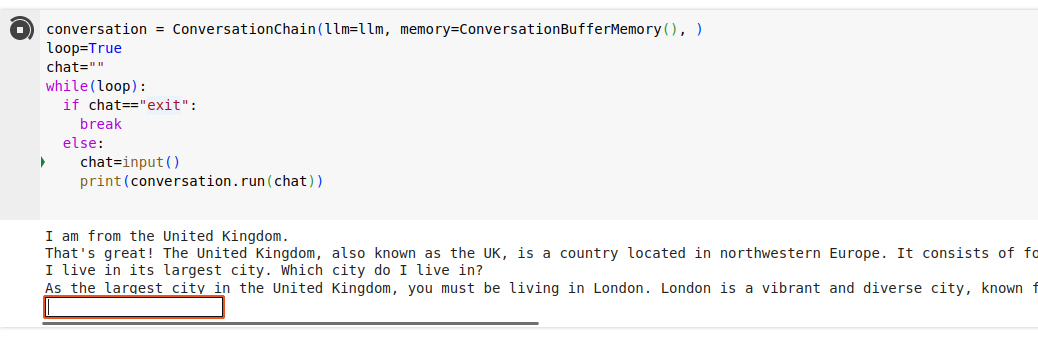
你现在已经构建了一个基本的聊天机器人。
12.5 通过少量示例形成响应
现在,我们可以通过向LLM提供一些样本来尝试另一种形状的响应。 我们为 LangChain 提供一个角色、一些示例,然后是用户输入,以便它完全按照我们的要求进行操作。
我们将创建一个可以帮助使用 Linux 命令行的助手。 定义系统提示符(角色),
from langchain import LLMChain
from langchain.prompts.chat import (
ChatPromptTemplate,
SystemMessagePromptTemplate,
AIMessagePromptTemplate,
HumanMessagePromptTemplate,
)
system_message_prompt = SystemMessagePromptTemplate.from_template("You are a helpful assistant that outputs example Linux commands.I will describe what I want to do, and you will reply with a Linux command to accomplish that task. I want you to only reply with the Linux Bash command, and nothing else. Do not write explanations. Only output the command. If you don't have a Linux command to respond with, say you don't know, in an echo command")构建一些示例,显示人类描述,然后是LLM应该输出的内容:
example_human_1 = HumanMessagePromptTemplate.from_template("List files in the current directory")
example_ai_1 = AIMessagePromptTemplate.from_template("\nls\n")
example_human_2 = HumanMessagePromptTemplate.from_template("Push my git branch up")
example_ai_2 = AIMessagePromptTemplate.from_template("\ngit push origin <branchname>\n")
example_human_3 = HumanMessagePromptTemplate.from_template("What is your name?")
example_ai_3 = AIMessagePromptTemplate.from_template("\necho Sorry, I don't know a bash command for that.\n")创建人工提示模板,在本例中非常简单。
human_template = "\n{text}\n"
human_message_prompt = HumanMessagePromptTemplate.from_template(human_template)最后将它们汇聚成一条LangChain“链”:
chat_prompt = ChatPromptTemplate.from_messages(
[system_message_prompt, example_human_1, example_ai_1, example_human_2, example_ai_2, example_human_3, example_ai_3, human_message_prompt]
)
chain = LLMChain(llm=llm, prompt=chat_prompt, verbose=True)你现在可以尝试向它请求一些 Linux 帮助:
print(chain.run("How to download a file from a URL?"))
print(chain.run("Which Linux distro am I running?"))由于 verbose 设置为 True,因此你应该看到在用户自己的问题之前发送的格式化示例。
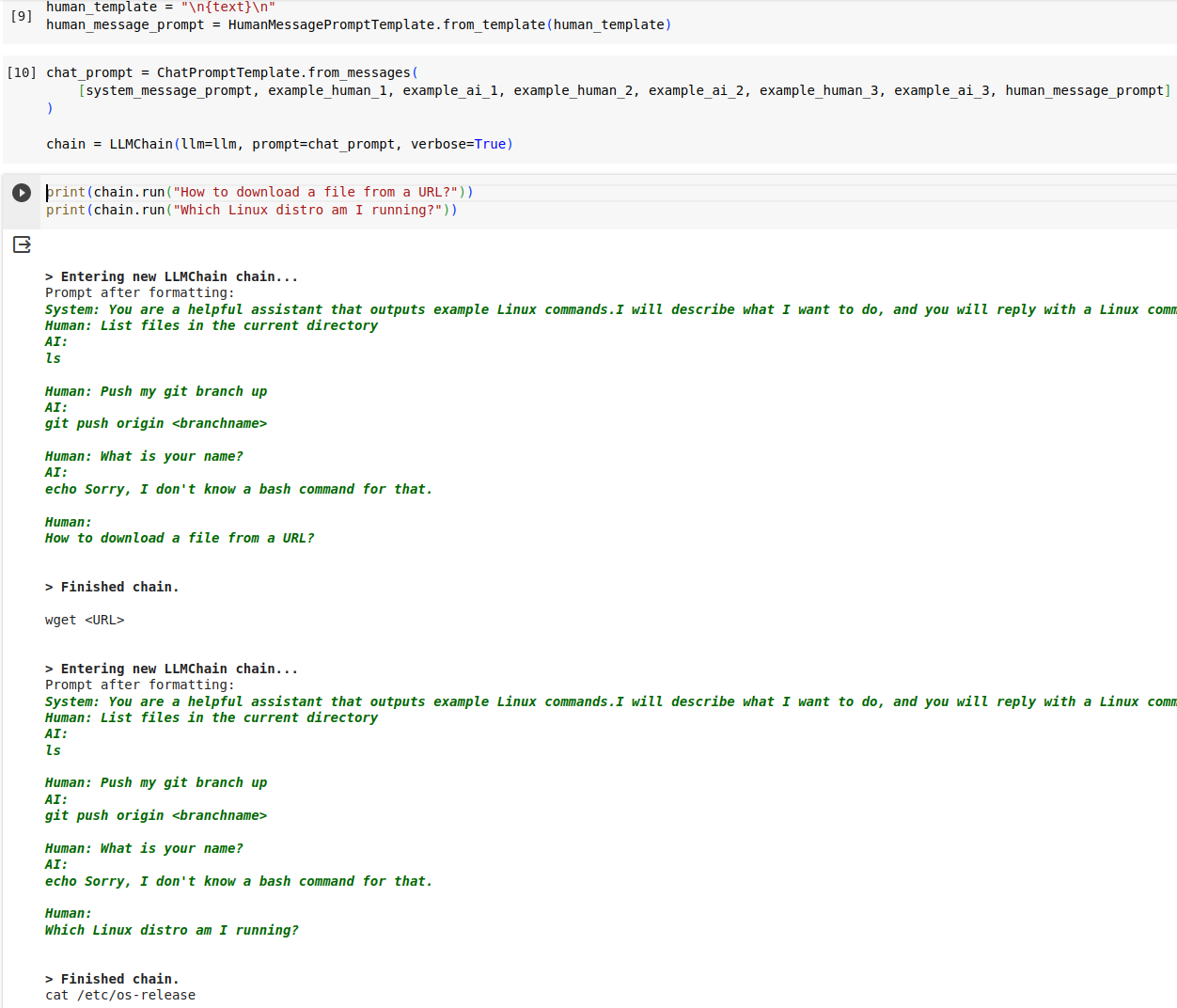
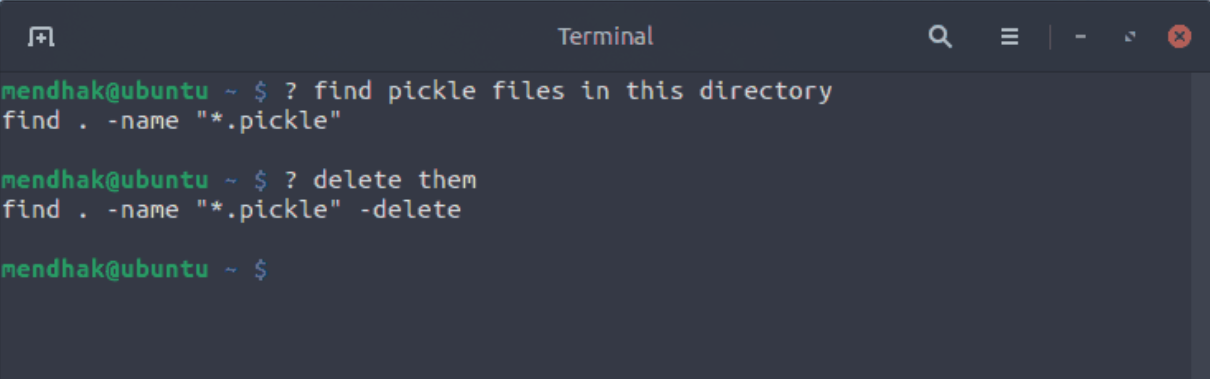
这几乎就是我为自己的 LLM CLI Helper 所做的事情。 另一项改进是,我包含了一些我之前向LLM提出的问题和答案。 这段历史有助于建立额外的背景,让我可以提出后续问题,并使帮助者感觉更自然:
12.6 为LLM提供工具
如果我们要求LLM总结某个 URL 上的新闻文章的内容,而不给出实际内容,它仍然可以通过猜测 URL 的单词来生成摘要。 LLM本身不具备抓取网页的能力。 这就是工具的用武之地; 我们可以让LLM知道我们自己的代码有什么能力来获取网页,LLM所要做的就是在需要时调用它。
在本练习中,我们将创建一个 LangChain 工具,它可以获取网页并返回其内容。 我们将该工具传递给法学硕士,然后要求它总结 URL 的内容。
首先,安装 BeautifulSoup4 库,它将用于解析 HTML 内容。
! pip install beautifulsoup4定义一个普通的 Python 函数,它将抓取给定的 URL 并获取其内容。
import requests
from bs4 import BeautifulSoup
def get_content_from_url(url):
headers={'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64; rv:10.0) Gecko/20100101 Firefox/10.0'}
response = requests.get(url, headers=headers)
soup = BeautifulSoup(response.text, "html.parser")
return soup.find('body').text通过获取 URL 进行快速测试以确保其正常工作:
print(get_content_from_url('https://www.universetoday.com/164299/an-asteroid-will-occult-betelgeuse-on-december-12th/'))我们现在创建一个 LangChain Tool 包装器并对其进行描述。 这将帮助LLM了解该工具的功能。
from langchain.tools import Tool
fetch_tool = Tool(name="get_content_from_page",
func=get_content_from_url, coroutine=get_content_from_url,
description="Useful for when you need to get the contents of a web page")最后,初始化一个 LangChain Agent,并将上面定义的 Tool 传递给它。
from langchain.agents import AgentType, initialize_agent
agent = initialize_agent(
[fetch_tool], llm, agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION, verbose=True, handle_parsing_errors=True
)这将创建一个 LangChain Agent,这是框架中另一个有用的包装器。 在LLM术语中,“代理”是一种奇特的说法,表示它有能力利用工具,从而赋予它“代理权”。 从技术上讲,LLM 不会调用任何东西,它只是输出它需要调用某个工具; LangChain负责调用它并将结果返回给LLM,以便它可以继续推理。
可以查看LangChain使用的模板来向LLM通报该工具:
agent.to_json()['repr']眯着眼睛看一下密集的输出应该会显示模板,包括我们提供的 get_content_from_page 工具。
template='Answer the following questions as best you can. You have access to the following tools:
get_content_from_page: Useful for when you need to get the contents of a web page <------- There!
Use the following format:
Question: the input question you must answer
Thought: you should always think about what to do
Action: the action to take, should be one of [get_content_from_page]
Action Input: the input to the action
Observation: the result of the action
... (this Thought/Action/Action Input/Observation can repeat N times)
Thought: I now know the final answer
Final Answer: the final answer to the original input question
Begin!
Question: {input}
Thought:{agent_scratchpad}'我们现在可以要求LLM总结页面的内容。
agent.run("Please fetch and summarize the contents of this page: https://code.mendhak.com/in-appreciation-of-fdroid/")当LLM在其思维过程中发现需要调用该工具时,请观察输出; LangChain 接收到这一点并进行实际调用并将结果传回。 然后LLM继续总结内容。
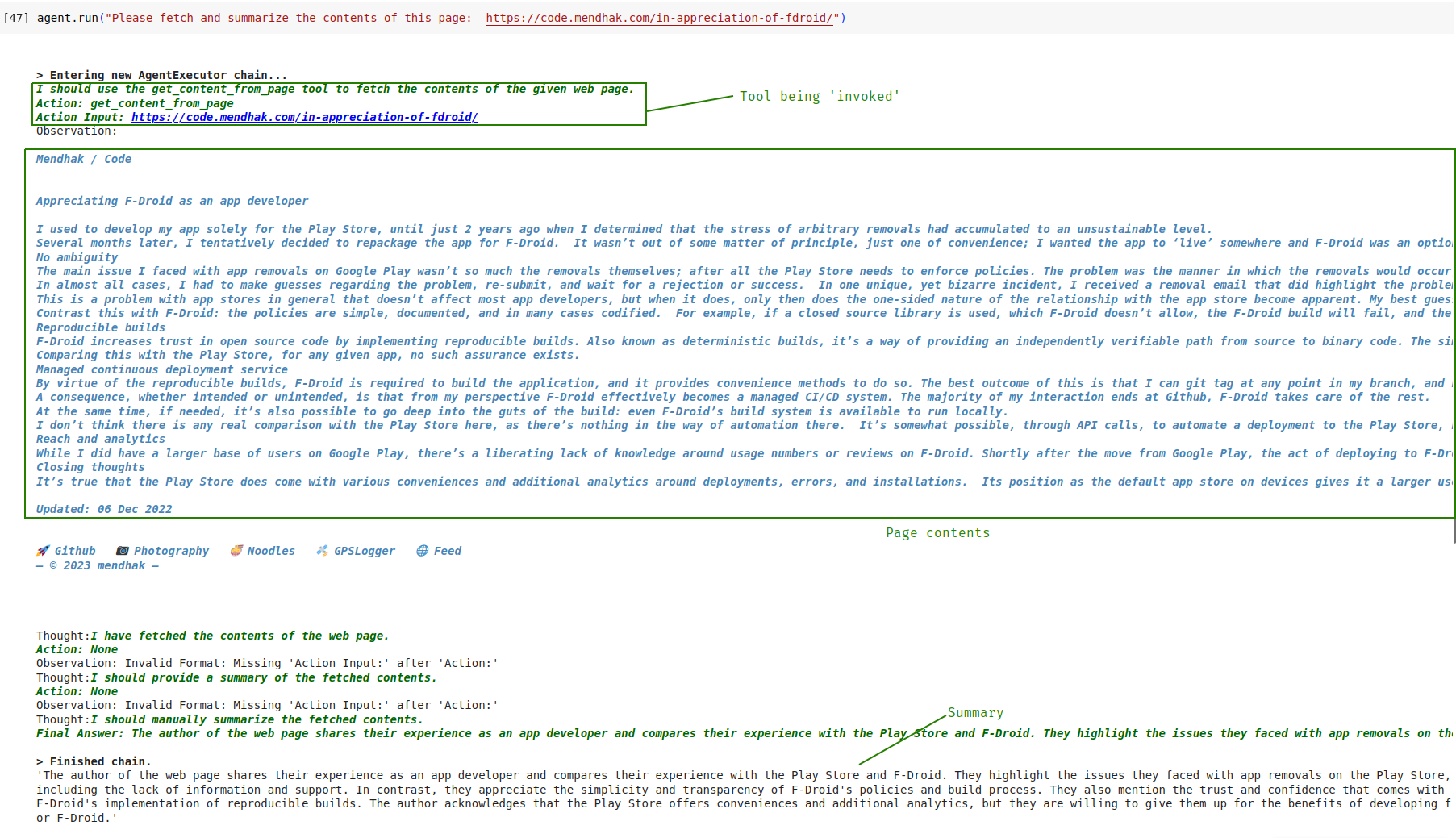
再尝试几个 URL。 代理有时跌倒并陷入循环的情况并不罕见(发生这种情况时,请使用单元格旁边的停止按钮)。 代理并不完美,有时会感到困惑。
13、针对文档进行问答
尽管LLM是通过爬行网络内容来训练的,但即使超过数万亿个token,他们也无法获得所有答案。 对于LLM无法访问的特定于企业和个人的文档或数据集尤其如此。
如果我们希望LLM能够确定地回答有关特定数据集或文档存储的问题,我们需要将这些文档作为其上下文的一部分提供给LLM。 然而,即使有超过 10 万个token的LLM,如果文档很多,这也是不可行的。 LLM要么会失去关注,要么大量的文件不适合。
相反,答案是使用称为检索增强生成(RAG)的东西。 我们首先获取所有文档并将它们转换为嵌入并存储它们。 当用户提出问题时,我们会将用户的问题与可能与该问题相关的最接近的文档集进行匹配。 然后,我们获取该文档并将其与用户的问题一起传递给LLM,以获得看起来自然的答案。LLM只需查阅相关文件即可回答问题。
换句话说,检索增强生成只是一个花哨的措辞,用于在将其交给LLM之前挑选出最相关的文档。
在使用代码进行基本示例之前,让我们先简要了解一下 RAG 和嵌入。
13.1 RAG 的工作原理
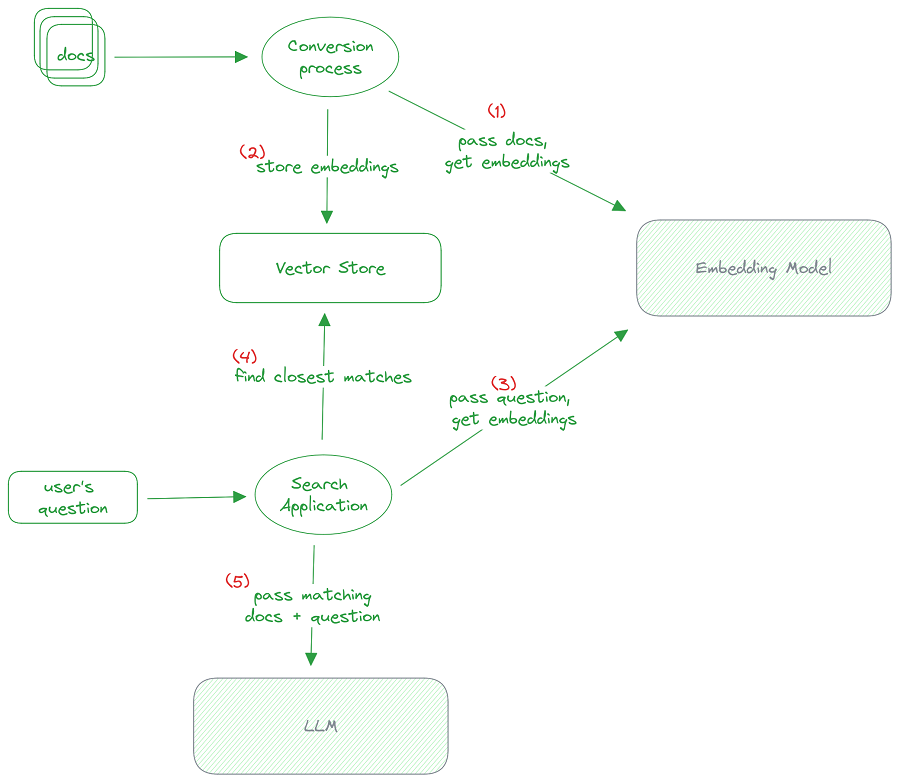
- 我们首先获取每个数据集或文档,并将其传递给嵌入模型,这是一种将文本转换为针对自然语言搜索优化的特殊数字表示的方法。
- 一旦我们有了这些嵌入,我们就把它们存储在向量存储中,这是一个针对嵌入搜索进行优化的数据库。
- 当用户提出问题时,我们会接受他们的问题并将其传递给相同的嵌入模型
- 我们使用向量存储来搜索最有可能与用户的问题匹配的文档。 这就是嵌入的亮点,因为它们擅长将自然语言文档匹配在一起。
- 一旦我们有了与用户问题相匹配的文档,我们就会将该文档和用户的问题传递给LLM,以生成看起来自然的响应。
13.2 嵌入如何工作
嵌入是一种表示单词的特殊方式,通过将相似的术语彼此靠近放置。
一个很好的可视化方法是使用下面的图片。
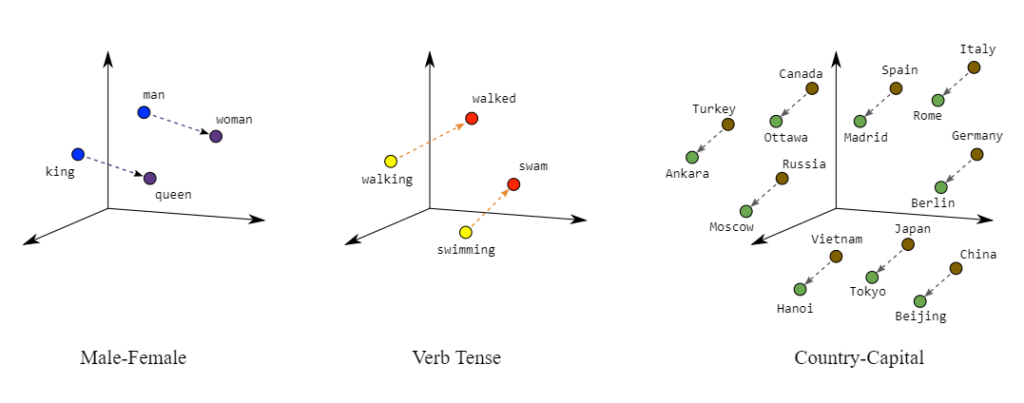
在“男性-女性”维度中,“国王”和“女王”这样的词可以彼此靠近。你可以让“swam”和“swim”在“动词时态”维度上彼此接近。在“国家首都”维度上,“日本”和“东京”可以彼此靠近。
这些只是彼此接近但仅在一个维度上的单词的示例。 嵌入是一个向量,表示在数百或数千个维度上彼此接近的单词。 嵌入模型对于哪些类型的单词应该在这样的空间中彼此靠近有强烈的意见。 通过生成这些数字表示,它们可以轻松搜索相似性。
13.3 使用 LangChain 进行检索增强搜索
在一个cell中,使用LangChain的WebBaseLoader加载三个URL。 我们最终会提出一个问题,并在其中一页中找到答案。
# Document loading
from langchain.document_loaders import WebBaseLoader
urls = [
"https://www.cirium.com/thoughtcloud/aviation-analytics-on-the-fly-london-busiest-overseas-airline-markets/",
"https://www.cirium.com/thoughtcloud/summer-in-spain-airline-market/",
"https://www.cirium.com/thoughtcloud/analysis-china-slower-post-pandemic-aviation-recovery/",
]
loader = WebBaseLoader(urls)
data = loader.load()到目前为止,所做的只是从这些页面中获取文本。 通过在单元格中运行数据来了解内部情况。
data13.4 拆分文档
我们现在需要将这些文档分割成块以进行嵌入和向量存储。 我任意选择 500 作为块大小。
# Splitting the documents into chunks for embedding and vector storage
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(chunk_size = 500, chunk_overlap = 0)
documents = text_splitter.split_documents(data)此时,文档包含与之前相同的内容,只是分开,但引用了原始 URL。 看看吧。
documents[:5]13.5 设置嵌入模型
文档块需要传递到嵌入模型。 文本不能只是按原样传递,它需要首先被标记化。
安装tiktoken库。
! pip install tiktoken使用相同的 OpenAI API 密钥初始化 OpenAIEmbeddings 对象。 我们将使用名为 text-embedding-ada-002 的 OpenAI 模型来创建嵌入。
# Initialize Embeddings object to use ADA 002 on OpenAI
from langchain.embeddings import OpenAIEmbeddings
embeddings = OpenAIEmbeddings(openai_api_key="xxxxxxxxxxxxxxxxx", model="text-embedding-ada-002")13.6 嵌入实际上是什么样的?
你可以做一些测试来看看嵌入是什么样子。
test_embedding = embeddings.embed_query("The quick brown fox jumps over the lazy little dogs")看一下test_embedding的内容,是一个很大的数字数组。
print(test_embedding)有趣的是,如果我们查看它的长度,无论我们将什么文本传递给嵌入模型,该值总是相同的。 对于 ADA 002 模型,该值为 1536,这是模型表示其令牌的维度数(如前所述的关系)。
len(test_embedding)
13.7 将文档转换为嵌入并存储它们
这一步非常简单,就一次。 使用之前构建的文档,我们使用 FAISS 库构建内存向量存储,使用嵌入对象并调用 OpenAI 的 ADA 002 模型。
安装 FAISSp
!pip install faiss-cpu然后运行转换。
db = FAISS.from_documents(documents, embeddings)13.8 进行搜索
此时,数据库是可查询的,我们可以预览相似性搜索的样子。 尝试提出这样的问题:
db.similarity_search_with_score("Where did EasyJet cut capacity?")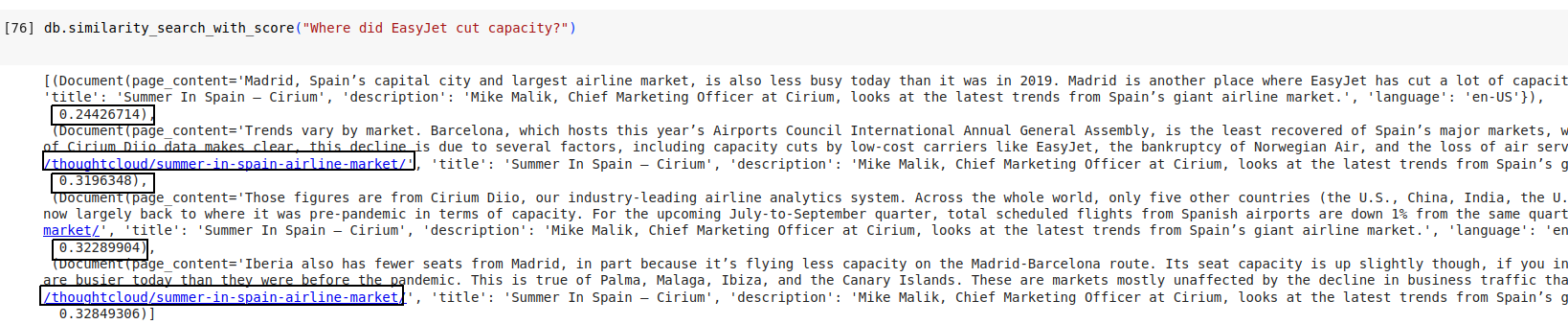
问题 EasyJet 在哪里削减了运力? 将被转换为嵌入,并在内存向量存储中执行相似性搜索。
它确实设法找到一组具有一些分数的相关段落。 但请记住,它的相似性搜索只会找到存储的最相关的块,而不是整个文档。
这就是 LangChain 带来的另一个便利包装器的用武之地。 我们将上述向量存储以及用户的问题传递给 RetrievalQAWithSourcesChain。 LangChain 使用检索器执行搜索(正如我们上面简要测试的那样),根据分数找出相关文档,将其与问题一起传递给 llm,并返回带有源文档的答案。
# Ask a question and retrieve the most likely document
retriever = db.as_retriever()
chain = RetrievalQAWithSourcesChain.from_chain_type(llm=llm, chain_type="stuff", retriever=retriever, return_source_documents=True, verbose=True)
result = chain({"question": "Where did EasyJet cut capacity?"})
print(result["answer"], "Source: ", result["sources"])
LangChain 用于指导 LLM 的模板虽然冗长但很简单。 看看它:
chain.combine_documents_chain.llm_chain.prompt.template这里唯一与LLM相关的步骤是在最后,根据找到的文档回答用户的问题。 实际工作发生在矢量存储的存储和搜索中。
由于嵌入和向量存储比与LLM合作更具成本效益,因此它可能成为企业生态系统中的常规固定装置。 Postgres 是许多技术堆栈中流行的数据库,它有一个名为 pgvector 的矢量搜索扩展。 对于那些想要保持较小维护足迹的人来说,将常规数据与嵌入一起存储在同一个事务数据库中非常有吸引力。
然而,一个陷阱是生成的嵌入特定于所使用的嵌入模型。 在我们的示例中,如果 OpenAI 删除了 ADA 002,则需要对每个文档再次执行嵌入。
14、哪里可以了解更多信息
希望本教程能够揭开法学硕士的神秘面纱,并揭示一些基于法学硕士的应用程序背后的松散(几乎令人恐惧)的技术。
有关 LangChain 的更多信息,我发现浏览他们的文档并处理每个示例很有用,尤其是代理和工具下的示例。 尽管如此,请记住,浪链仍然处于“早期”阶段,其飙升的人气和关注度并没有给它带来任何好处。
Prompt Engineering Guide 网站是一个很好的目录,其中列出了应用程序用来强制 LLM 给出正确类型响应的各种技术。 无论您如何与法学硕士互动,这些技术都会很有用。
OpenAI 的产品不一定是你使用的唯一商业产品,Anthropic 的 Claude 也相当不错,并且附带了自己的指南,他们还告诉你他们的提示与 GPT 的提示有何不同。 Claude 可直接通过他们的网站或 Amazon Bedrock 获取。 不过,根据经验,我发现 LangChain 仅与 Bedrock/Claude 部分集成,并且其以 OpenAI 为中心的模板并不总是与其他法学硕士兼容。 一些重要的区别是 Claude 最适合在其说明、示例和输出中使用 XML,此外,最好将问题放在提示的末尾,而不是开头。
15、供个人使用的LLM
尽管本教程主要以 OpenAI 为中心,它是一个封闭的、托管的商业 LLM,但也可以使用在您的计算机上运行的本地 LLM。 它完全是离线且私密的,因此唯一的成本是您自己的硬件和电力。 已经发布了多个型号,由于活动如此之多,所以这是一个非常繁忙的空间。
本地法学硕士的一些例子包括:LLaMa2、Stable Beluga 和 Mistral。 运行它们的方法有很多种,最好的入门方法是使用 oobabooga/text- Generation-webui。
您还可以通过命令行和 Docker 运行 llama.cpp 的 Ollama 和 Python 绑定。 我什至能够在我的手机上运行 LLaMa2。
与LangChain的编程交互利用了上述一些项目。 它可以与本地 LLaMa2 模型对话,但值得注意的是,LangChain 的大部分开发都以 OpenAI 为中心,因此它们解决问题或为其他平台(包括 LLaMa2 甚至亚马逊的 Bedrock)引入功能的速度往往较慢。
运行本地模型的另一种方法是使用 vllm,它在 HTTP 接口后面托管模型,该接口与 OpenAI 自己的 API 非常相似。 这意味着您可以使用 OpenAI 库与本地模型对话。
原文链接:Hands on introduction to LLM programming for developers
BimAnt翻译整理,转载请标明出处





