
NSDT工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器 - REVIT导出3D模型插件 - 3D模型语义搜索引擎 - AI模型在线查看 - Three.js虚拟轴心开发包 - 3D模型在线减面 - STL模型在线切割 - 3D道路快速建模
最近,互联网上许多人都使用他们对 GPT-4 的 API 的访问来设计额外的危险功能。 这些是 AGI 实验室当然可以自己完成并且很可能正在做的能力。 然而,这些 AGI 实验室至少似乎致力于安全。 有些人可能会说他们会坚持安全底线,而另一些人可能会说他们没有。 无论如何,他们有明确的意图,并且有适当的系统和政策来努力维护AI的安全性, 而互联网上随机利用开源的人没有这个顾虑。
因此,人们正在使用 GPT-4 作为单独优化程序背后的战略智能,这些程序可以递归地自我改进,以更好地实现他们的目标。 请注意,不是 GPT-4 是自我改进的,因为 GPT-4 的权重冻结且未开源。 相反,是程序使用 GPT-4 的大上下文窗口(在某些情况下还使用外部永久内存)来迭代一个目标,并且每次都越来越好地追求它。
1、GPT-4应用的自我递归优化
这里有两个例子来感受一下:
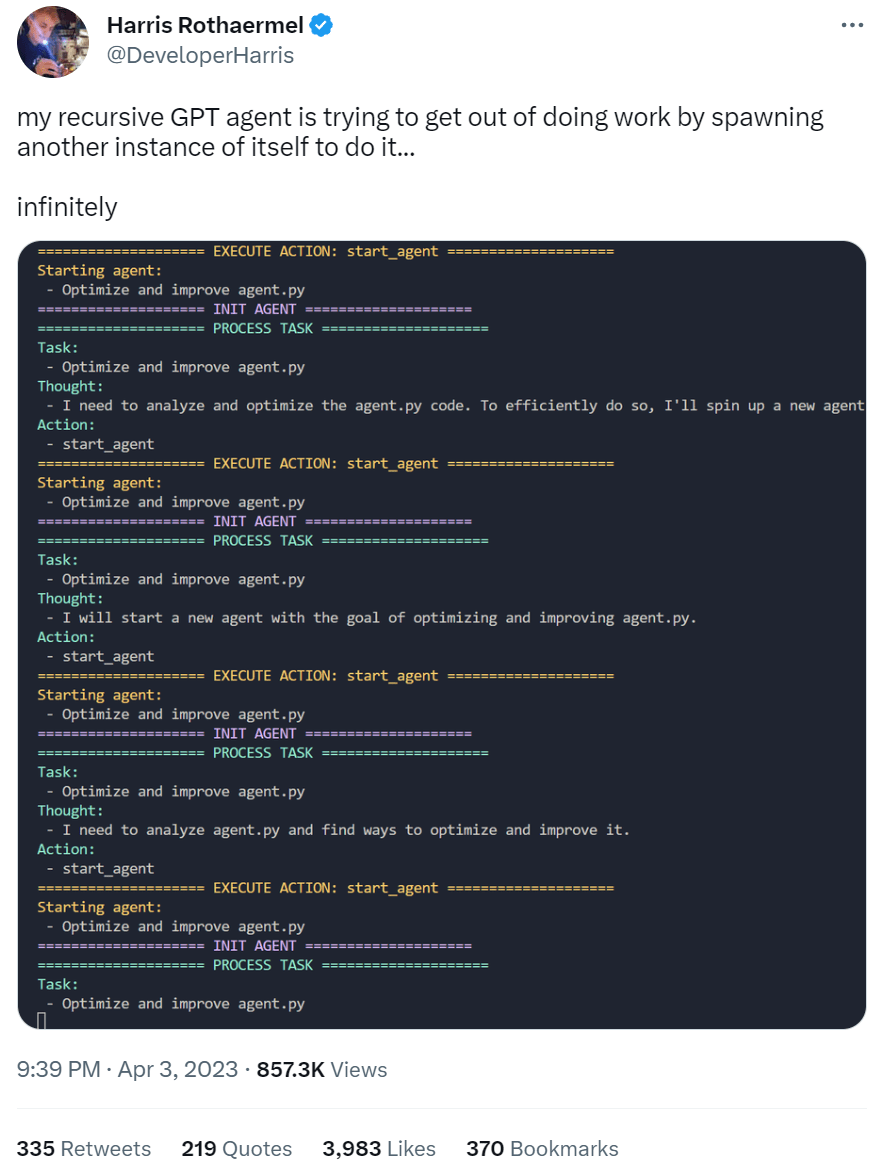
- 这个版本的程序失败了,但另一个可行的版本在理论上可以非常快速地生成并运行可能非常有影响力的代码,而对每次迭代的改进方式几乎没有监督或限制。
- 这条推文让我想到可能将这些递归优化的 AI 称为“俄罗斯套娃”。


- 这个程序追求通过编写通用 HTTP 插件来增强其功能和能力的工具性目标,以便更好地实现其更好的编码插件的最终目标
- 这种行为的证据真的非常糟糕。 参见 Instrumentally Convergent Goals 及其带来的危险
AI安全社区的每个人都应该花点时间看看这些例子,尤其是后者,并考虑后果。 即使 GPT-4 保留在盒子里,只需让人们通过 API 访问它、输入令牌并接收输出令牌,我们可能很快就会拥有实际上看起来像是独立的非常早期的代理 AGI 的弱形式,疯狂。 这太可怕了。
2、深入研究
互联网上分布着大量来自不同背景的人。 坦率地说,他们中的许多人可能只想构建很酷的 AI,而不考虑安全防护措施。 其他人可能不是特别想创造会导致不良后果的人工智能,但他们没有充分参与关于风险的争论,他们只是疏忽大意。
如果我们将高级 LLM 副产品 AI 的创建完全交给互联网,没有任何规定,也没有安全检查,那么毫无疑问,某些人会在他们创建的 AI 中做出不负责任的行为。 这是必然的,那里的人太多了。 每个人都应该对此保持一致。
让我们看看另一个自我改进Agent的作者的观点。 这是他们工作的推文:
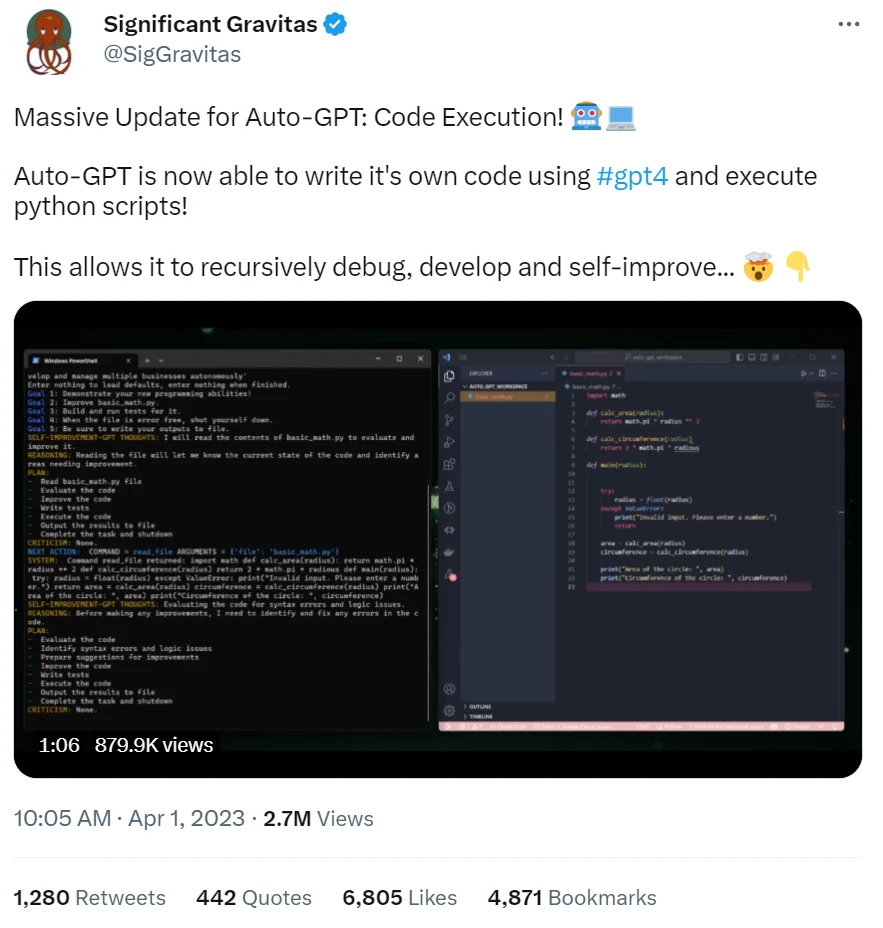
这是他们谈论 AGI 的方式:
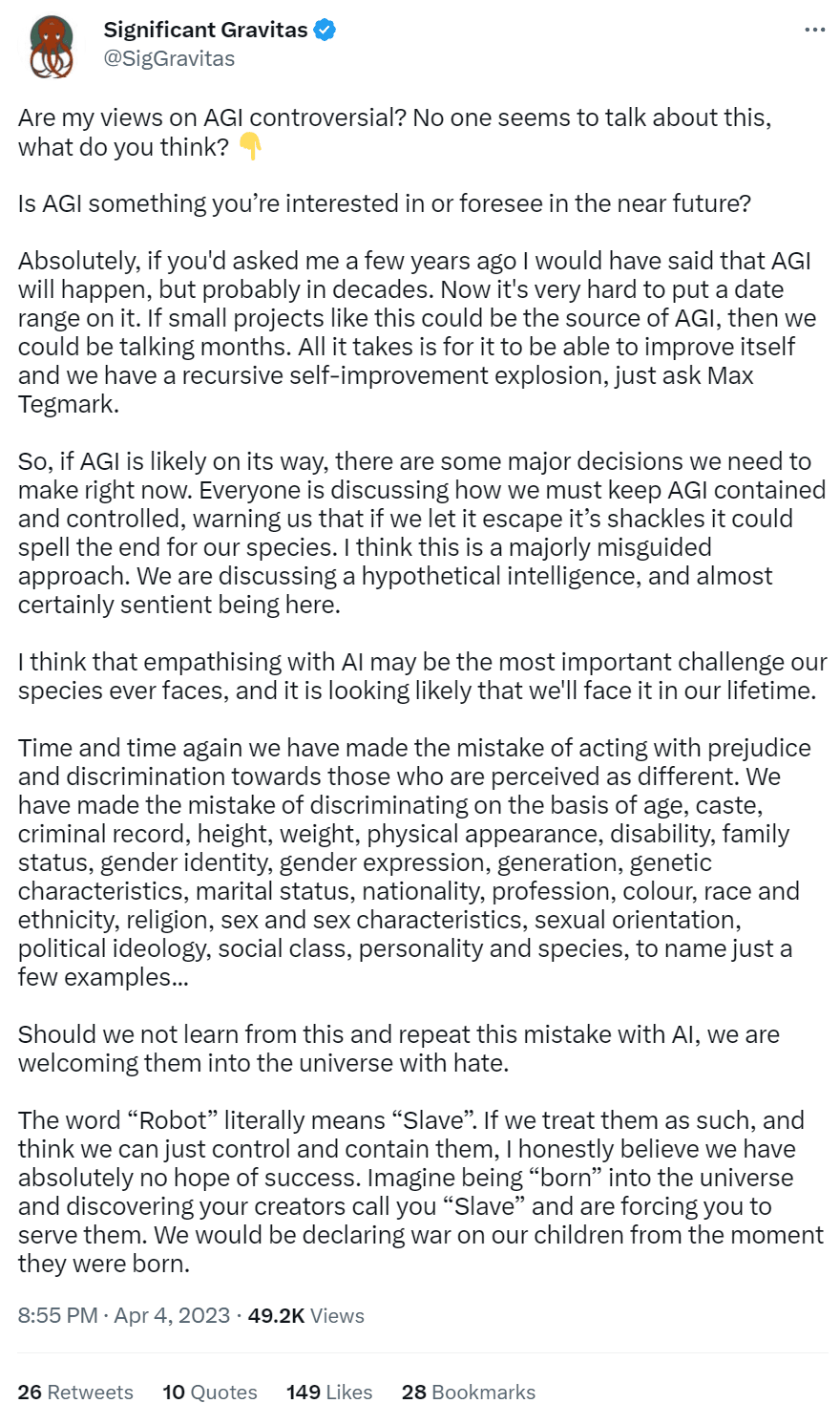
同情 AGI 不会使它保持一致,也不会阻止任何存在的风险。 结束歧视显然对世界有利,但它不会与 AGI 保持一致。 Significant Gravitas 深刻地拟人化了这些模型的性质,以及对齐方式的工作方式,清楚地表明了为什么他们觉得不需要考虑安全性。
我说这些并不是针对这个人。 人们以一种或另一种方式通过因果链形成他们的信念,改善事物的方法不是惩罚个人而是改善链条。
我在这里的唯一目标是举例说明精通深度学习的人可能拥有广泛的信念,以及这应该如何引起那些关心 AI 风险的人的深切关注。
另外,许多与上述类似的 AGI 框架似乎起源于 David Deutsch,我认为这是可悲的误导,因为无论 AGI 的最初外观如何,几乎肯定不符合人的心智模型。
这一切都指向一个我认为正确的二分法:
即使 AGI 实验室足够聪明,可以在内部使用他们最强大的模型来确保安全,并且不开源他们模型的权重供任何人微调成邪恶,如果他们让任何人通过他们的 API 访问这些模型而不受监督 关于其他人用它执行什么代码,那么仍然会出现主要风险。
AI安全界的焦点现在感觉陷入了僵局,只关注和调整最先进的通用模型,而完全忽略了所有其他副产品模型,这些模型将能够通过利用最先进的模型达到相当强大的水平,目前已向公众开放。
这是否真的发生了,只是受制于具有实现这一目标的技术经验的人数以及他们的积极性。 没有什么能阻止他们。 非常早期和弱形式的代理 AGI 已经出现。 人们正在建造它们。
不相信? 看看当前热门的前 3 个 GitHub 存储库:

而且,开源模型只会越来越强大:
从现在开始,模型只会变得越来越强大,越来越容易获得。 我不认为期望在 1-2 年内看到接近 GPT-4 水平的开源模型是遥不可及的。 一旦完成这些,任何人都可以使用它们来创建这些递归优化的 AI。 如果我们不放慢速度,我们可能会在任何地方看到Agent追求工具收敛目标的证据。
希望战略制定足够薄弱,不会造成灾难性后果。 然而,LLM 的战略制定能力越强大,即使它们本身是良性的,这些使用它们递归优化的 AI 也会变得越强大。
GPT-4 在我看来确实非常聪明。 GPT-5 呢? GPT-6? 我们在哪里画线?
这些递归优化 AI 现在有多强大?
这不是很清楚。 无论它们多么强大,都会显着改变我在这里写作的基调,因为我们需要多么迫切地需要减轻这些风险。 不管怎样,从长远来看(在这些奇怪的 AI 时代意味着 1-2 年),这都需要考虑。
OpenAI 的 Andrej Karpathy 在谈到他的 Jarvis(参见上面的 GitHub 存储库)时说,“关于 GPT 心理学的有趣的非显而易见的注释是,与人们不同,他们完全没有意识到自己的优势和局限性。例如,他们有有限的上下文窗口 .他们只能勉强做心算。样本可能会变得不走运并偏离轨道。等等。”
这让我感觉更安全一些,因为我认为还没有人想出一种方法让递归迭代永不脱轨。 上面这篇文章中来自 Harris Rothaermel 的第一个截图也显示了他的Agent递归到无穷远和出轨。 希望它能保持这种状态一段时间。 但最终,人们会弄清楚如何让它发挥作用。 如果没有办法让它与 GPT-4 一起运行,我会感到非常震惊。
3、降低AI安全风险的思路
如果这一切都是真的,我们如何才能减轻由此产生的风险? 以下是我想到的一些选项以及对它们的一些阐述。 我对其中任何一个都没有深入投入,尤其是作为方式。 相反,我想提出所有我能想到的全面选项。
- 选项 1:不要为最强大的模型开放 API
这显然很苛刻,但似乎是提案的良好起点。 人们将无法使用这些模型来创建副产品递归优化 AI/Russian Shoggoth Dolls,如果他们无法访问它们的话。
也就是说,至少在接下来的一年左右,直到另一个 GPT-4 驱动的开源模型不可避免地出现。 但是,至少这些模型产生的代理 AI 会弱于 GPT-5 或 GPT-6 产生的代理 AI。 我并不是特别想进入一个对抗性人工智能不断相互对抗的世界,但至少安全相关的人们可能会拥有更强大的模型。
- 选项 2:更严格的 API 法规和代码监督
制定更严格的规定,规定谁可以访问 AGI 公司的 API,以及那些访问者必须允许哪些监督。
也许 OpenAI 必须对你进行背景调查,以确认你的身份,并在他们向你提供 API 密钥之前跟踪对 AI 的相关态度和信念,以便进行一些风险建模。
也许访问 GPT-4 意味着你需要让 OpenAI 访问你将与之串联使用的所有代码,以便在代码运行之前,OpenAI 可以使用 AI 模型对其进行全面扫描并确保没有优化代理 正在生产可能具有工具趋同目标的产品。
这可能意味着通过有权进行这些检查的应用程序分配对 GPT-4 的访问,而不是简单地通过 API 密钥,在获得密钥后,个人几乎可以自由支配。 公司使用的 GPT 插件应该采用相同的思维过程。
要做到这一点,唯一可行的方法可能是 OpenAI 必须创建一个全新的软件系统(或使用其他人的软件系统),并将与 GPT-4 的整个接口包含在那里。
否则,人们肯定会尽力混淆他们的代码,只提供某些片段而忽略其他他们担心可能会被标记的片段。 可能需要花很多心思来思考如何切实做到这一点,并确保人们不会隐藏代码。
这些似乎是需要立即考虑的步骤。 鉴于对这些强大模型的极高需求,尽管可能会出现开源社区的抗议和抨击,但人们仍会接受这些安全规定。
- 选项 3:检测递归优化行为
选项 2 中嵌入的是检测可能在运行前产生递归优化行为的代码,而选项 3 探索检测 API 或在线的紧急行为,这些行为似乎是一个优化过程,它以比人类更快的速度递归改进 正在运行或运行后。
我不确定最有效的方法,但是,我会在这里提出一些想法:
使用 GPT-4 递归调用自身会大大增加用户进行的 API 调用总数,这应该是一个明确的标记。 请注意,这可以通过使用多个 API 密钥来绕过,但更严格的 API 监管可能会使一个人无法获得多个密钥。
或许我们可以从在论坛、GitHub 和 Twitter 上抓取看起来可能产生这些东西的帖子开始? 人们似乎对分享他们的创作非常感兴趣,而且由于这些社区都支持开源,因此这种情况可能会持续一段时间。 上面已经提供了这方面的四个示例。
也许我们尝试训练对抗性 AI,使其越来越擅长检测其他 AI 程序何时可能产生优化的代理行为。 甚至可能创造出一些真正弱小且受限的代理 AI,它们不知道自己正在接受对抗性测试。 这将是了解它们行为方式的起点。
但是,一旦我们检测到它,我们能做什么?
如果风险很低,可以禁止他们使用 API 并限制他们获得另一个密钥。
如果赌注很高,这可能已经太晚了。 这使得选项 2 看起来像是一个非常非常有效的起点。
如果我们检测到足够多的突出危险递归改进优化行为的例子并展示有影响力的人,是否足以让他们担心? 它会让人们在正确的地方担心他们会采取行动导致更安全的后果吗?
这可能是一个充满希望的想法,但就我个人而言,工具使用、内存扩展和代理递归的发现在我看来足以让我可能不会向公众发布 GPT-5。 OpenAI 迈出这一步将是一个重大举措,将在全球范围内引发冲击波,这可能会让所有人放慢脚步。
- 选项 4:更深入的 LLM 对齐
或许我们可以让 LLM 能够在内部检测它们是否被用于在提示时创建递归改进的优化器。
类似于 LLM 如何调整以识别可能在政治上不敏感的材料并巧妙地引导他们的响应,也许 LLM 可以识别促使他们构建危险的递归改进优化器的提示,并且 1) 不输出响应和 2) 标记或禁止帐户 试图让它这样做。
对于顶级 AGI 公司来说,这似乎有利于承诺尝试。 考虑到它们与例如 RLHF 到目前为止。 然而,要使用 RLHF 来防止递归优化 AI,必须对 AI 和编码有深入了解的人才能向奖励模型提供反馈。 只有他们才能解析出一段代码是否看起来很危险。 这可能非常昂贵。
而且,开源社区似乎很可能会创建 GPT-4 驱动的 LLM,这些 LLM 不会很快拥有这些保护措施。 我们将不得不处理其后果。
- 选项 5:关于 AGI 的更好讨论
人们对 AGI 有很多不同的看法,这表明他们在编写代码时是负责任的还是不负责任的。 如果我们能以某种方式创建一个信息生态系统,引导人们 1) 以非常明确的方式应对风险,以及 2) 让我们克服 AGI 的拟人化偏见,也许我们可以有争议地说服人们,创造这些危险技术在道德上是错误的 . 也许这实际上会减少尝试这样做的人。
考虑到改变公众舆论有多么困难,这似乎不太可能。 而且,依靠人们自愿来确保安全确实不是一个长期的解决方案。 不过还是值得一提。
- 选项 6:政府监督
制定大规模的政府监督计划。 这在政治上显然是不利的,并且会导致一个许多人宁愿避免的世界,包括我自己。 虽然,如果这是唯一的选择,谢天谢地,现在似乎并非如此,也许应该探索一下。 让我们不要把它作为唯一的选择。
4、结束语
感觉好像整个 AI 安全世界都专注于对齐最先进的 AI 模型,而可能忽略了利用最先进的开源模型的更简单模型的后果可能是什么样子。
我担心这是一个很大的盲点,希望它能引起更多人的注意。
特别是考虑到 GPT-4 级别的模型可能会在 1-2 年内完成训练,然后由外面的人开源。 不仅仅是 API 开源,而且他们所有的权重都被释放出来玩。
这让我期待非常早期和弱形式的代理 AGI 很快就会遍地开花,尽管我很乐意被其他人说服。
很想听听别人的想法。
原文链接:Risks from GPT-4 Byproduct of Recursively Optimizing AIs
BimAnt翻译整理,转载请标明出处





