
NSDT工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器 - REVIT导出3D模型插件 - 3D模型语义搜索引擎 - AI模型在线查看 - Three.js虚拟轴心开发包 - 3D模型在线减面 - STL模型在线切割 - 3D道路快速建模
随着越来越多的人更喜欢在搜索产品时询问 ChatGPT 而不是 Google,公司需要问自己:我们如何才能出现在列表顶部?
在本文中,我阐明了技术背景。它表明,该领域的许多问题仍然没有明确的答案。然而,以前的品牌推广方法似乎也在这里起作用。
1、向生成式AI的转变
基于生成式AI的应用程序正在风靡全球。特别是在研究信息和快速回答问题方面,ChatGPT、Gemini 等服务可能对谷歌等搜索引擎构成激烈的竞争——至少在一定程度上是这样。
基本上,我们应该区分:
- 来自搜索结果 (SERP) 的网站点击量或可能丢失的流量,
- 以及可能减少一般使用量或减少搜索查询。
根据 Gartner 的一项研究,到 2026 年,搜索引擎使用量将下降 25%,转而转向AI聊天机器人和虚拟助手。
就我个人而言,我不认为到 2026 年我们会看到这样的转变。尽管如此,我相信未来几代人将越来越依赖AI聊天机器人来研究信息和产品。
所以我认为 25% 甚至更多是相当现实的,但需要五到十年而不是两年。这将是一个缓慢但稳定的发展。用户习惯仍然是习惯!
我看到网站上的搜索引擎流量减少的速度要快得多。随着 SGE(现为“AI 概览”)的推出,我预计在推出后的前两年内,搜索引擎流量平均会减少高达 20%。根据搜索意图,可能会多或少。然而,我确信“无点击搜索”会增加,因为生成式人工智能已经在提供解决方案和答案。
这将缩短研究旅程和客户旅程或混乱的中间时间。
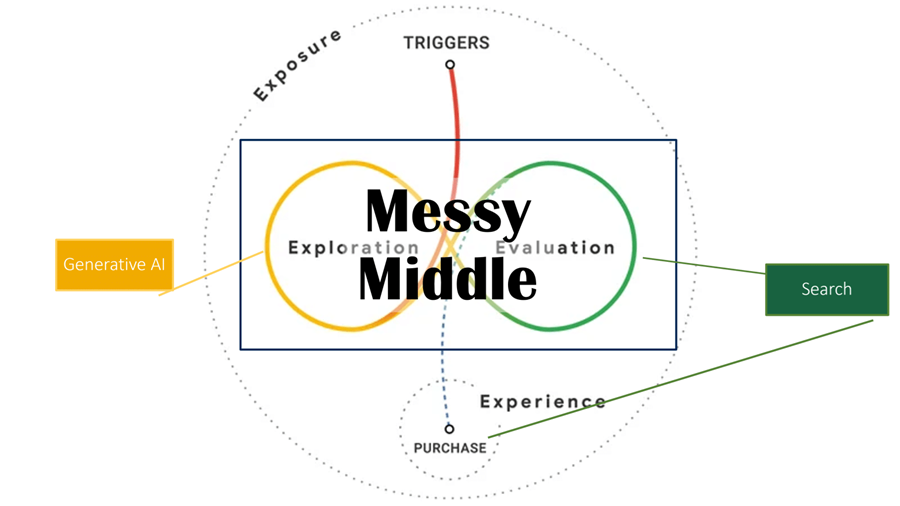
为了在用户旅程中提高知名度,仅仅关注搜索引擎排名和点击量或网站流量也是疏忽大意的。
如果你今天向 ChatGPT 询问一辆应该满足某些特征的汽车,他们会建议具体的型号:

如果你向 Gemini 询问同样的问题,他们也会推荐某些车型,包括图片:

有趣的是,上面的示例根据应用推荐了不同的车型。
ChatGPT:
- 特斯拉 Model Y
- 丰田 Highlander 混合动力车
- 现代 Ioniq 5
- 沃尔沃 XC90 Recharge
- 福特野马 Mach-E
- 本田 CR-V 混合动力车
Gemini:
- 克莱斯勒 Pacifica 混合动力车
- 丰田 Sienna
- 一般中型 SUV
- 丰田 RAV4 混合动力车
- Row SUV
- 丰田 Highlander 混合动力车
这清楚地表明,底层语言模型(大型语言模型,LLM)的工作方式因 AI 应用而异。
在未来,公司在此类建议中被提及将变得越来越重要,以便被纳入一组相关的可能解决方案中。
但生成式 AI 究竟为什么要提出这些模型呢?
为了回答这个问题,我们需要更多地了解生成式 AI 和 LLM 的技术功能。
2、附记:LLM 的工作原理
现代基于 Transformer 的 LLM(例如 GPT 或 Gemini)基于对 token 或单词共现的统计分析。
为此,文本和数据被分解为 token 以供机器处理,并借助向量定位在语义空间中。向量也可以是整个单词(Word2Vec)、实体(Node2Vec)和属性。
在语义学中,语义空间也被描述为本体。由于 LLM 更多地基于统计数据而不是实际语义,因此它们不是本体。然而,由于可以处理的数据量具有高度可扩展性,因此 AI 更接近语义理解。
语义接近度可以通过语义空间中的欧几里得距离或余弦角测量来确定:
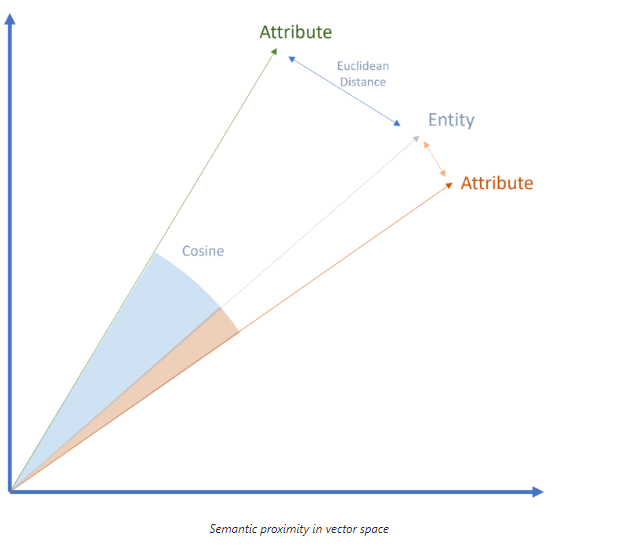
这样,就可以建立产品和属性之间的关系。
LLM 使用自然语言处理在编码过程中确定关系。这样可以将分解为标记的文本划分为实体和属性。
某些标记的共现次数增加了这些标记之间存在关系的概率。
语言模型最初使用人工标记的数据进行训练。这些初始训练数据是互联网、其他数据库、书籍、维基百科的抓取数据库……因此,用于训练最先进 LLM 的绝大多数数据都是来自可公开访问的互联网资源的文本(例如最新的“Common Crawl”数据集,其中包含来自超过 30 亿页的数据)。
目前尚不清楚初始抓取究竟使用了哪些来源。
为了减少幻觉并使 LLM 能够获得更深入的特定主题知识,现代 LLM 还支持来自特定领域来源的内容。此过程是检索增强生成 (RAG) 的一部分。
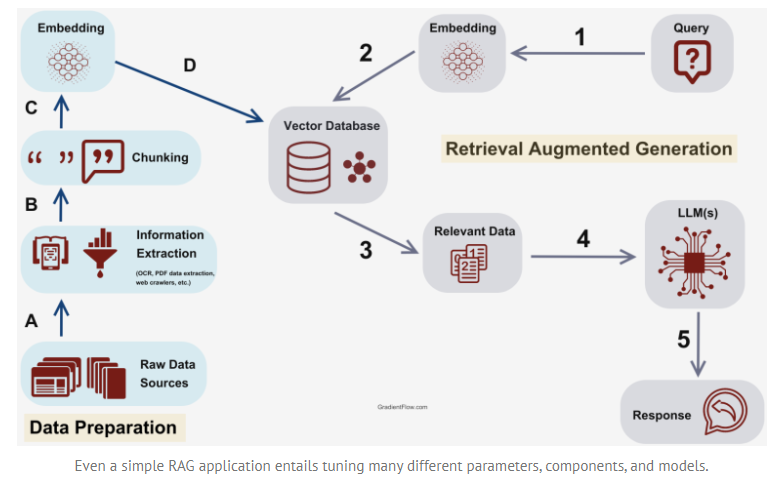
图数据库(例如 Google 知识图谱或购物图谱)也可用于 RAG 上下文中,以开发更好的语义理解。
3、LLMO、GEO、GAIO :影响GenAI 的新学科
公司面临的最大挑战是不仅要在以前已知的搜索引擎中发挥作用,还要在语言模型的输出中发挥作用。无论是以包括链接在内的来源参考形式,还是通过提及自己的品牌和产品。
影响生成式 AI 的输出是一个以前未探索的研究领域。有几种理论和许多名称,例如大型语言模型优化 (LLMO)、生成引擎优化 (GEO)、生成式 AI 优化 (GAIO)。
来自实践的优化方法的可靠证据仍然很少。这只剩下从 LLM 的技术理解中得出的推导。
- 建立非商业驱动提示的主题可信和相关来源
- 对于非商业提示,最重要的目标是被指定为来源,包括指向您自己网站的链接。
对于可以直接访问搜索引擎的 AI 系统来说,在编译答案时参考排名最高的内容是合乎逻辑的。
以下是提示的示例:“google core update march 2024”

Copilot 中提到的来源有
- searchengineland.com
- coalitiontechnologies.com
- seroundtable.com
在 Bing 上,相应搜索查询在不包含视频和新闻的经典结果中的排名如下:
- searchengineland.com
- blog.google
- searchenginejournal.com
- yoast.com
- developers.google.com
- semrush.com
- …
部分来源与搜索结果有重叠,但并非全部。
ChatGPT 在同一提示中显示以下来源:
Google Gemini 提到了以下来源:
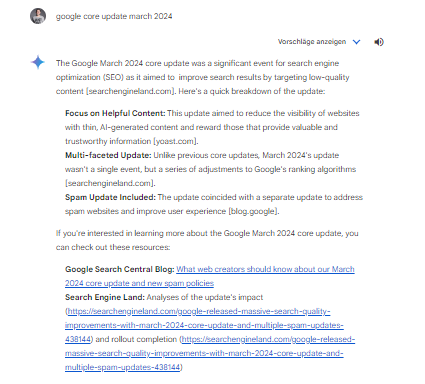
除了相关性标准之外,在选择来源时似乎还使用了其他质量标准,这可能类似于 Google 的 E-E-A-T 概念。
一些关于 Google SGE 的研究也表明知名品牌之间存在高度相关性,例如 Peak Ace 在旅游领域进行的一项研究和另一项由权威机构组织的研究。
Peak Ace 研究了旅游领域中哪些域名经常链接到 SGE 之外:

Authoritas 调查了通常与 SGE 链接的域名:
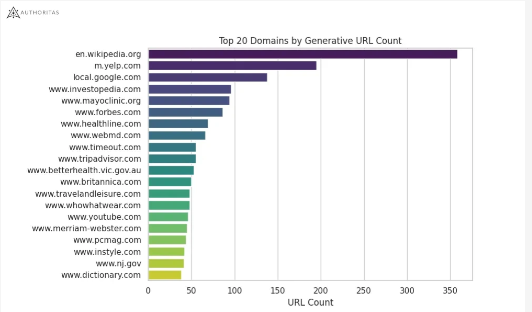
品牌实力和 SGE 来源选择之间的联系是可以猜测的。
4、商业驱动提示的数字品牌和产品定位
对于以购买为导向的提示,最重要的目标是在购物网格或输出中被 AI 直接推荐为品牌或产品。
但如何实现呢?
与往常一样,明智的方法是从用户或提示开始。 通常情况下,了解用户及其需求是基础。
提示可以提供比标准搜索查询的几个术语更多的上下文:
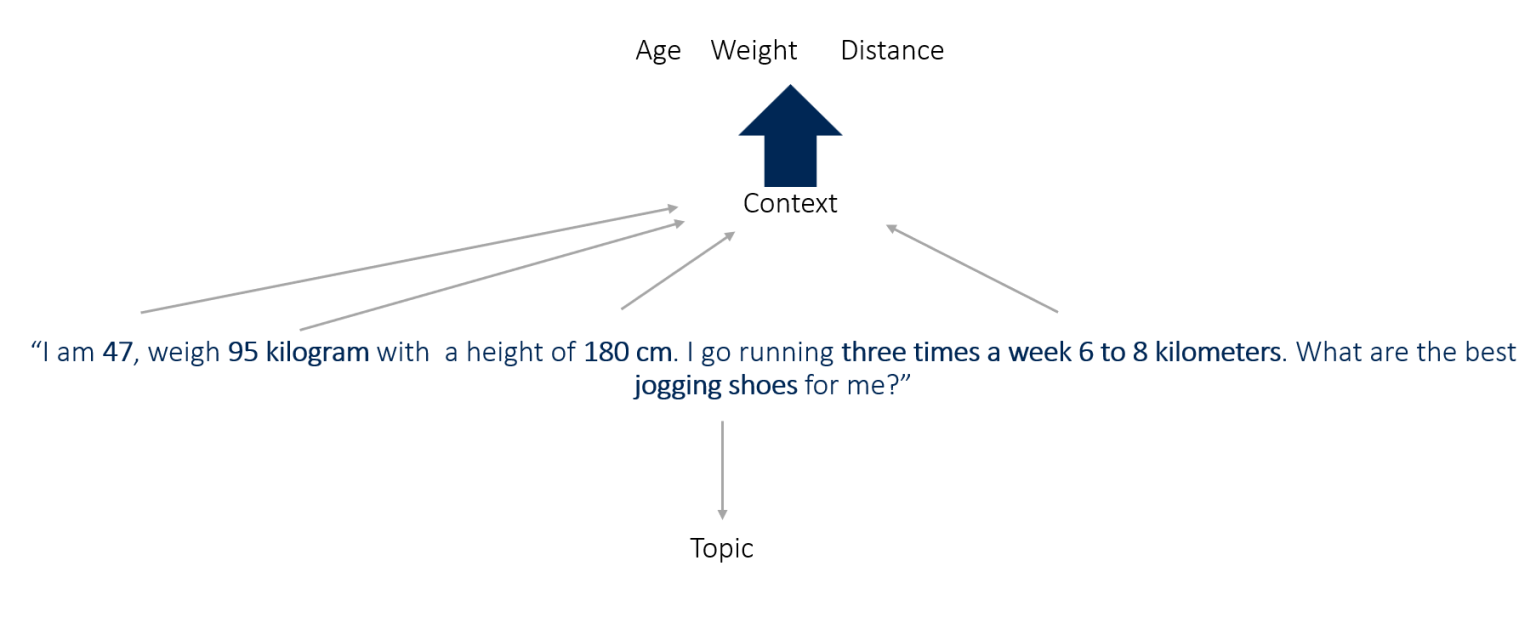
因此,公司应致力于在特定的用户环境中定位自己的品牌和产品。
市场上和提示中经常请求的属性类别(例如条件、用途、用户数量……)可以作为初步参考点,以确定品牌和产品应定位在哪些环境中。
但这种定位应该在哪里进行?
要做到这一点,你需要知道 LLM 使用哪些训练数据。这反过来又取决于相关的 LLM:
- 如果 LLM 可以访问搜索引擎,则此搜索引擎中排名靠前的内容可能是一个可能的来源。
- 知名的(行业)目录、(产品)数据库或其他主题权威来源可能是优化的地方。
- Google 的 E-E-A-T 概念也可以在这里发挥重要作用,至少对于 Gemini 或 SGE 来说,它可以识别值得信赖的来源以及值得信赖的品牌和产品。
5、结束语
LLMO 或 GAIO 是否真的会成为影响 LLM 实现其自身目标的合法策略还有待观察。在数据科学方面,有人持怀疑态度。其他人则相信这种方法。
如果是这样,则需要实现以下目标:
- 通过 E-E-A-T 将自有媒体确立为训练数据来源。
- 在合格媒体中生成品牌和产品的提及。
- 在合格媒体中生成自有品牌与其他相关实体和属性的共现。
- 成为知识图谱或购物图谱等成熟图数据库的一部分。
LLM 优化的成功几率与市场规模直接相关:市场越细分,在相应的主题背景下将自己定位为品牌就越容易。
这意味着,为了与 LLM 中的相关属性和实体相关联,需要在合格媒体中同时出现的内容越少。市场越大,这就越困难,因为许多市场参与者拥有大量的公关和营销资源以及悠久的历史。
GAIO 或 LLMO 需要比传统 SEO 多得多的资源来影响公众认知。
在这一点上,我想参考我的数字权威管理概念。你可以在文章权威管理:SGE 和 E-E-A-T 时代的新学科中阅读更多相关内容。
让我们假设 LLM 优化被证明是一种明智的策略。在这种情况下,大品牌将凭借其公关和营销资源在未来的搜索引擎定位和生成 AI 结果方面具有显著优势。
另一个观点是,搜索引擎优化可以像以前一样继续进行,因为排名靠前的内容同时用于训练 LLM。你还应该注意品牌/产品与属性或其他实体之间的共现,并针对它们进行优化。
这些方法中的哪一种将成为 SEO 的未来尚不清楚,只有在 SGE 最终推出时才会变得清晰。
原文链接:LLMO: How do you optimize for the answers of generative AI systems?
BimAnt翻译整理,转载请标明出处





