
NSDT工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器 - REVIT导出3D模型插件 - 3D模型语义搜索引擎 - AI模型在线查看 - Three.js虚拟轴心开发包 - 3D模型在线减面 - STL模型在线切割 - 3D道路快速建模
神经网络可以执行许多不同的任务。 无论是分类数据,如将动物图片分组为猫和狗;或回归任务,如预测月收入,还是其他任何事情。 每个任务都有不同的输出,需要不同类型的损失函数。
配置损失函数的方式可以成就或破坏算法的性能。 通过正确配置损失函数,可以确保模型按您希望的方式工作。
对我们来说幸运的是,可以使用损失函数来充分利用机器学习任务。
在本文中,我们将讨论 PyTorch 中流行的损失函数,以及构建自定义损失函数。 阅读完本文后,就知道为项目选择哪一个损失函数了。
1、什么是损失函数?
在进入 PyTorch 细节之前,让我们回顾一下什么是损失函数。
损失函数用于衡量预测输出与提供的目标值之间的误差。 损失函数告诉我们算法模型离实现预期结果还有多远。 “损失”一词是指模型因未能产生预期结果而受到的惩罚。
例如,损失函数(我们称之为 J)可以采用以下两个参数:
- 预测输出 (y_pred)
- 目标值 (y)
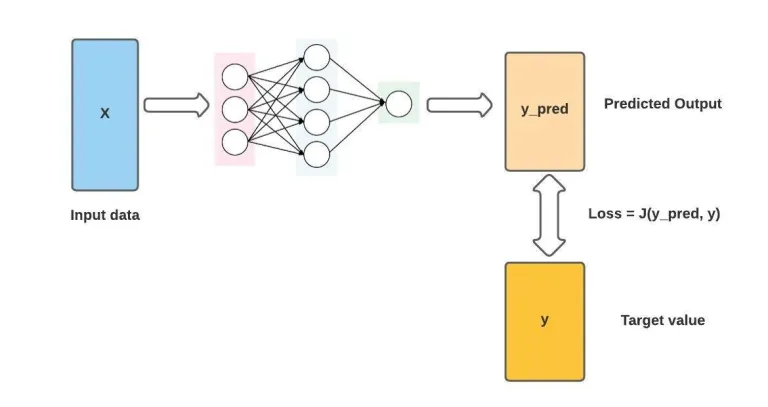
此函数通过将预测输出与预期输出进行比较来确定模型的性能。 如果 y_pred和 y的偏差很大,loss值会很高。
如果偏差很小或值几乎相同,它会输出一个非常低的损失值。 因此,当模型在提供的数据集上训练时,你需要使用可以适当惩罚模型的损失函数。
损失函数会根据你的算法试图解决的问题陈述而变化。
2、如何添加 PyTorch 损失函数?
PyTorch 的 torch.nn 模块有多个标准损失函数,可以在你的项目中使用。
要添加它们,需要先导入库:
import torch
import torch.nn as nn接下来,定义要使用的损失类型。 以下是定义平均绝对误差损失函数的方法:
loss = nn.L1Loss()添加函数后,可以使用它来完成你的特定任务。
3、PyTorch 中有哪些损失函数可用?
从广义上讲,PyTorch 中的损失函数分为两大类:回归损失和分类损失。
当模型预测连续值(例如人的年龄)时,会使用回归损失函数。
当模型预测离散值时使用分类损失函数,例如电子邮件是否为垃圾邮件。
当模型预测输入之间的相对距离时使用排名损失函数,例如根据产品在电子商务搜索页面上的相关性对产品进行排名。
现在我们将探索 PyTorch 中不同类型的损失函数,以及如何使用它们:
- 平均绝对误差损失
- 均方误差损失
- 负对数似然损失
- 交叉熵损失
- 铰链嵌入损失
- 边际排名损失
- 三元组边际损失
- Kullback-Leibler 散度
3.1 PyTorch平均绝对误差(L1损失函数)
torch.nn.L1Loss平均绝对误差 (MAE),也称为 L1 损失,计算实际值和预测值之间的绝对差之和的平均值。
它检查一组预测值中误差的大小,而不关心它们的正方向或负方向。 如果不使用误差的绝对值,则负值可以抵消正值。
Pytorch L1 Loss 表示为:
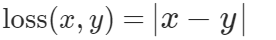
x 代表实际值,y 代表预测值。
什么时候可以用L1损失?
回归问题,特别是当目标变量的分布有异常值时,例如与平均值相差很大的小值或大值。 它被认为对异常值更稳健。
示例如下:
import torch
import torch.nn as nn
input = torch.randn(3, 5, requires_grad=True)
target = torch.randn(3, 5)
mae_loss = nn.L1Loss()
output = mae_loss(input, target)
output.backward()
print('input: ', input)
print('target: ', target)
print('output: ', output)###################### OUTPUT ######################
input: tensor([[ 0.2423, 2.0117, -0.0648, -0.0672, -0.1567],
[-0.2198, -1.4090, 1.3972, -0.7907, -1.0242],
[ 0.6674, -0.2657, -0.9298, 1.0873, 1.6587]], requires_grad=True)
target: tensor([[-0.7271, -0.6048, 1.7069, -1.5939, 0.1023],
[-0.7733, -0.7241, 0.3062, 0.9830, 0.4515],
[-0.4787, 1.3675, -0.7110, 2.0257, -0.9578]])
output: tensor(1.2850, grad_fn=<L1LossBackward>)3.2 PyTorch 均方误差损失函数
torch.nn.MSELoss均方误差 (MSE),也称为 L2 损失,计算实际值和预测值之间的平方差的平均值。
无论实际值和预测值的符号如何,Pytorch MSE Loss 始终输出正结果。 为了提高模型的准确性,你应该尝试减少 L2 Loss——一个完美的值是 0.0。
平方意味着较大的错误比较小的错误产生更大的错误。 如果分类器偏离 100,则错误为 10,000。 如果偏离 0.1,则误差为 0.01。 这会惩罚犯大错误的模型并鼓励小错误。
Pytorch L2 Loss 表示为:
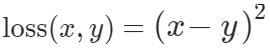
x 代表实际值,y 代表预测值。
什么时候可以用?
- MSE 是大多数 Pytorch 回归问题的默认损失函数。
示例如下:
import torch
import torch.nn as nn
input = torch.randn(3, 5, requires_grad=True)
target = torch.randn(3, 5)
mse_loss = nn.MSELoss()
output = mse_loss(input, target)
output.backward()
print('input: ', input)
print('target: ', target)
print('output: ', output)3.3 PyTorch 负对数似然损失函数
torch.nn.NLLLoss负对数似然损失函数 (NLL) 仅适用于以 softmax 函数作为输出激活层的模型。 Softmax 是指计算层中每个单元的归一化指数函数的激活函数。
Softmax函数表示为:
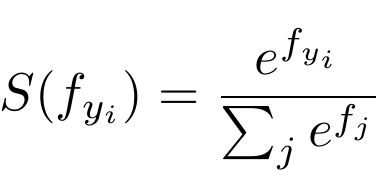
该函数采用大小为 N 的输入向量,然后修改值,使每个值都落在 0 和 1 之间。此外,它对输出进行归一化,使向量的 N 个值之和等于 1。
NLL 使用否定含义,因为概率(或可能性)在0和1之间变化,并且此范围内值的对数为负。 最后,损失值变为正值。
在 NLL 中,最小化损失函数有助于我们获得更好的输出。 从近似最大似然估计 (MLE) 中检索负对数似然。 这意味着我们尝试最大化模型的对数似然,并因此最小化 NLL。
在 NLL 中,模型因做出正确预测的概率较小而受到惩罚,并因预测概率较高而受到鼓励。 对数执行惩罚。
NLL 不仅关心预测是否正确,还关心模型对高分预测的确定性。
Pytorch NLL Loss 表示为:
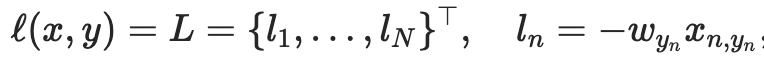
其中 x 是输入,y 是目标,w 是权重,N 是批量大小。
什么时候可以用?
- 多类分类问题
示例如下:
import torch
import torch.nn as nn
# size of input (N x C) is = 3 x 5
input = torch.randn(3, 5, requires_grad=True)
# every element in target should have 0 <= value < C
target = torch.tensor([1, 0, 4])
m = nn.LogSoftmax(dim=1)
nll_loss = nn.NLLLoss()
output = nll_loss(m(input), target)
output.backward()
print('input: ', input)
print('target: ', target)
print('output: ', output)###################### OUTPUT ######################
input: tensor([[ 1.6430, -1.1819, 0.8667, -0.5352, 0.2585],
[ 0.8617, -0.1880, -0.3865, 0.7368, -0.5482],
[-0.9189, -0.1265, 1.1291, 0.0155, -2.6702]], requires_grad=True)
target: tensor([1, 0, 4])
output: tensor(2.9472, grad_fn=<NllLossBackward>)3.4 PyTorch 交叉熵损失函数
torch.nn.CrossEntropyLoss此损失函数针对提供的一组事件或随机变量计算两个概率分布之间的差异。
它用于计算出一个分数,该分数总结了预测值和实际值之间的平均差异。 为了提高模型的准确性,你应该尝试最小化分数——交叉熵分数介于 0 和 1 之间,完美值为 0。
其他损失函数,如平方损失,惩罚不正确的预测。 交叉熵会因为非常自信和错误而受到很大惩罚。
与不根据预测置信度进行惩罚的负对数似然损失不同,交叉熵惩罚不正确但置信度高的预测,以及正确但置信度较低的预测。
交叉熵函数有多种变体,其中最常见的类型是二元交叉熵 (BCE)。 BCE Loss主要用于二元分类模型; 也就是说,模型只有 2 个类。
Pytorch 交叉熵损失表示为:
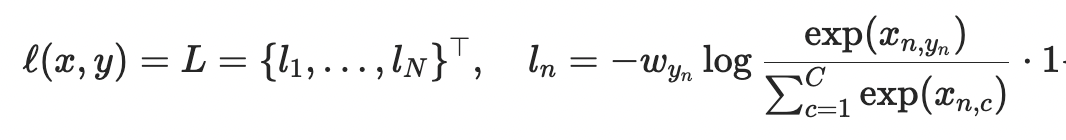
其中 x 是输入,y 是目标,w 是权重,C 是类数,N 跨越小批量维度。
什么时候可以用?
- 二元分类任务,它是 Pytorch 中的默认损失函数。
- 创建有信心的模型——预测将是准确的,而且概率更高。
示例如下:
import torch
import torch.nn as nn
input = torch.randn(3, 5, requires_grad=True)
target = torch.empty(3, dtype=torch.long).random_(5)
cross_entropy_loss = nn.CrossEntropyLoss()
output = cross_entropy_loss(input, target)
output.backward()
print('input: ', input)
print('target: ', target)
print('output: ', output)###################### OUTPUT ######################
input: tensor([[ 0.1639, -1.2095, 0.0496, 1.1746, 0.9474],
[ 1.0429, 1.3255, -1.2967, 0.2183, 0.3562],
[-0.1680, 0.2891, 1.9272, 2.2542, 0.1844]], requires_grad=True)
target: tensor([4, 0, 3])
output: tensor(1.0393, grad_fn=<NllLossBackward>)3.5 PyTorch 铰链嵌入损失函数
torch.nn.HingeEmbeddingLossHinge Embedding Loss 用于计算输入张量 x 和标签张量 y 时的损失。 目标值介于 {1, -1} 之间,这使其适用于二元分类任务。
使用 Hinge Loss 函数,只要实际类别值和预测类别值之间的符号存在差异,就可以给出更多错误。 这激励示例具有正确的符号。
Hinge Embedding Loss 表示为:
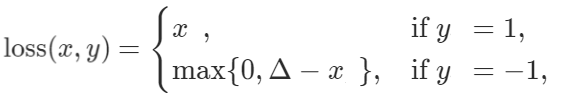
什么时候可以用?
- 分类问题,尤其是在确定两个输入是不同还是相似时。
- 学习非线性嵌入或半监督学习任务。
示例如下:
import torch
import torch.nn as nn
input = torch.randn(3, 5, requires_grad=True)
target = torch.randn(3, 5)
hinge_loss = nn.HingeEmbeddingLoss()
output = hinge_loss(input, target)
output.backward()
print('input: ', input)
print('target: ', target)
print('output: ', output)###################### OUTPUT ######################
input: tensor([[ 0.1054, -0.4323, -0.0156, 0.8425, 0.1335],
[ 1.0882, -0.9221, 1.9434, 1.8930, -1.9206],
[ 1.5480, -1.9243, -0.8666, 0.1467, 1.8022]], requires_grad=True)
target: tensor([[-1.0748, 0.1622, -0.4852, -0.7273, 0.4342],
[-1.0646, -0.7334, 1.9260, -0.6870, -1.5155],
[-0.3828, -0.4476, -0.3003, 0.6489, -2.7488]])
output: tensor(1.2183, grad_fn=<MeanBackward0>)3.6 PyTorch 边际排名损失函数
torch.nn.MarginRankingLossMargin Ranking Loss 计算一个标准来预测输入之间的相对距离。 这不同于其他损失函数,例如 MSE 或交叉熵,它们学习直接从一组给定的输入进行预测。
使用 Margin Ranking Loss,你可以计算损失,前提是有输入 x1、x2 以及标签张量 y(包含 1 或 -1)。
当 y == 1 时,第一个输入将被假定为较大的值。 它将比第二个输入排名更高。 如果 y == -1,则第二个输入的排名更高。
Pytorch Margin Ranking Loss 表示为:
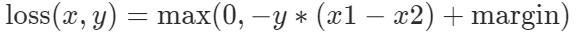
什么时候可以用?
- 排名问题
示例如下:
import torch
import torch.nn as nn
input_one = torch.randn(3, requires_grad=True)
input_two = torch.randn(3, requires_grad=True)
target = torch.randn(3).sign()
ranking_loss = nn.MarginRankingLoss()
output = ranking_loss(input_one, input_two, target)
output.backward()
print('input one: ', input_one)
print('input two: ', input_two)
print('target: ', target)
print('output: ', output)###################### OUTPUT ######################
input one: tensor([1.7669, 0.5297, 1.6898], requires_grad=True)
input two: tensor([ 0.1008, -0.2517, 0.1402], requires_grad=True)
target: tensor([-1., -1., -1.])
output: tensor(1.3324, grad_fn=<MeanBackward0>)3.7 PyTorch Triplet Margin 损失函数
torch.nn.TripletMarginLossTriplet Margin Loss 计算衡量模型中三重态损失的标准。 使用此损失函数,你可以计算损失,前提是输入张量 x1、x2、x3 以及值大于零的边距。
三元组由 a(锚点)、p(正例)和 n(负例)组成。
Pytorch Triplet Margin Loss 表示为:
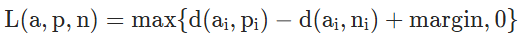
什么时候可以用?
- 确定样本之间存在的相对相似性。
- 用于基于内容的检索问题
示例如下:
import torch
import torch.nn as nn
anchor = torch.randn(100, 128, requires_grad=True)
positive = torch.randn(100, 128, requires_grad=True)
negative = torch.randn(100, 128, requires_grad=True)
triplet_margin_loss = nn.TripletMarginLoss(margin=1.0, p=2)
output = triplet_margin_loss(anchor, positive, negative)
output.backward()
print('anchor: ', anchor)
print('positive: ', positive)
print('negative: ', negative)
print('output: ', output)###################### OUTPUT ######################
anchor: tensor([[ 0.6152, -0.2224, 2.2029, ..., -0.6894, 0.1641, 1.7254],
[ 1.3034, -1.0999, 0.1705, ..., 0.4506, -0.2095, -0.8019],
[-0.1638, -0.2643, 1.5279, ..., -0.3873, 0.9648, -0.2975],
...,
[-1.5240, 0.4353, 0.3575, ..., 0.3086, -0.8936, 1.7542],
[-1.8443, -2.0940, -0.1264, ..., -0.6701, -1.7227, 0.6539],
[-3.3725, -0.4695, -0.2689, ..., 2.6315, -1.3222, -0.9542]],
requires_grad=True)
positive: tensor([[-0.4267, -0.1484, -0.9081, ..., 0.3615, 0.6648, 0.3271],
[-0.0404, 1.2644, -1.0385, ..., -0.1272, 0.8937, 1.9377],
[-1.2159, -0.7165, -0.0301, ..., -0.3568, -0.9472, 0.0750],
...,
[ 0.2893, 1.7894, -0.0040, ..., 2.0052, -3.3667, 0.5894],
[-1.5308, 0.5288, 0.5351, ..., 0.8661, -0.9393, -0.5939],
[ 0.0709, -0.4492, -0.9036, ..., 0.2101, -0.8306, -0.6935]],
requires_grad=True)
negative: tensor([[-1.8089, -1.3162, -1.7045, ..., 1.7220, 1.6008, 0.5585],
[-0.4567, 0.3363, -1.2184, ..., -2.3124, 0.7193, 0.2762],
[-0.8471, 0.7779, 0.1627, ..., -0.8704, 1.4201, 1.2366],
...,
[-1.9165, 1.7768, -1.9975, ..., -0.2091, -0.7073, 2.4570],
[-1.7506, 0.4662, 0.9482, ..., 0.0916, -0.2020, -0.5102],
[-0.7463, -1.9737, 1.3279, ..., 0.1629, -0.3693, -0.6008]],
requires_grad=True)
output: tensor(1.0755, grad_fn=<MeanBackward0>)3.8 PyTorch Kullback-Leibler 散度损失函数
torch.nn.KLDivLossKullback-Leibler 散度,缩写为 KL 散度,计算两个概率分布之间的差异。
使用此损失函数,你可以计算在预测概率分布用于估计预期目标概率分布的情况下丢失的信息量(以位表示)。
它的输出告诉你两个概率分布的接近程度。 如果预测的概率分布与真实的概率分布相差甚远,就会导致很大的损失。 如果 KL Divergence 的值为零,则意味着概率分布相同。
KL 散度的行为就像交叉熵损失,它们在处理预测概率和实际概率的方式上存在关键差异。 Cross-Entropy 根据预测的置信度对模型进行惩罚,而 KL Divergence 则不会。 KL 散度仅评估概率分布预测与地面实况分布有何不同。
KL Divergence Loss表示为:
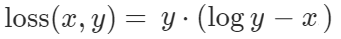
x 代表真实标签的概率,y 代表预测标签的概率。
什么时候可以用?
- 逼近复杂函数
- 多类分类任务
- 如果你想确保预测的分布与训练数据的分布相似
示例如下:
import torch
import torch.nn as nn
input = torch.randn(2, 3, requires_grad=True)
target = torch.randn(2, 3)
kl_loss = nn.KLDivLoss(reduction = 'batchmean')
output = kl_loss(input, target)
output.backward()
print('input: ', input)
print('target: ', target)
print('output: ', output)###################### OUTPUT ######################
input: tensor([[ 1.4676, -1.5014, -1.5201],
[ 1.8420, -0.8228, -0.3931]], requires_grad=True)
target: tensor([[ 0.0300, -1.7714, 0.8712],
[-1.7118, 0.9312, -1.9843]])
output: tensor(0.8774, grad_fn=<DivBackward0>)4、如何在 PyTorch 中创建自定义损失函数?
PyTorch 允许你创建自己的自定义损失函数以在项目中实施。
下面介绍如何创建自己的简单交叉熵损失函数。
一种方法是创建自定义损失函数作为 python 函数:
def myCustomLoss(my_outputs, my_labels):
#specifying the batch size
my_batch_size = my_outputs.size()[0]
#calculating the log of softmax values
my_outputs = F.log_softmax(my_outputs, dim=1)
#selecting the values that correspond to labels
my_outputs = my_outputs[range(my_batch_size), my_labels]
#returning the results
return -torch.sum(my_outputs)/number_examples还可以创建其他高级 PyTorch 自定义损失函数。
另一种方法是使用类定义创建自定义损失函数
让我们修改计算两个样本之间相似度的 Dice 系数,作为二元分类问题的损失函数:
class DiceLoss(nn.Module):
def __init__(self, weight=None, size_average=True):
super(DiceLoss, self).__init__()
def forward(self, inputs, targets, smooth=1):
inputs = F.sigmoid(inputs)
inputs = inputs.view(-1)
targets = targets.view(-1)
intersection = (inputs * targets).sum()
dice = (2.*intersection + smooth)/(inputs.sum() + targets.sum() + smooth)
return 1 - dice5、如何监控 PyTorch 损失函数?
很明显,在训练模型时,需要关注损失函数值以跟踪模型的性能。 随着损失值不断减小,模型不断变好。 我们可以通过多种方式做到这一点。 让我们来看看它们。
为此,我们将训练一个在 PyTorch 中创建的简单神经网络,它将对著名的 Iris 数据集进行分类。
进行获取数据集所需的导入。
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler加载数据集:
iris = load_iris()
X = iris['data']
y = iris['target']
names = iris['target_names']
feature_names = iris['feature_names']将数据集缩放为均值 = 0 和方差 = 1,可以快速收敛模型。
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)以 80-20 的比例将数据集拆分为训练集和测试集。
X_train, X_test, y_train, y_test = train_test_split(X_scaled, y, test_size=0.2, random_state=2)为我们的神经网络及其训练进行必要的导入。
import torch
import torch.nn.functional as F
import torch.nn as nn
import matplotlib.pyplot as plt
import numpy as np
plt.style.use('ggplot')定义网络:
class PyTorch_NN(nn.Module):
def __init__(self, input_dim, output_dim):
super(PyTorch_NN, self).__init__()
self.input_layer = nn.Linear(input_dim, 128)
self.hidden_layer = nn.Linear(128, 64)
self.output_layer = nn.Linear(64, output_dim)
def forward(self, x):
x = F.relu(self.input_layer(x))
x = F.relu(self.hidden_layer(x))
x = F.softmax(self.output_layer(x), dim=1)
return x定义用于获得准确性和训练网络的函数。
def get_accuracy(pred_arr,original_arr):
pred_arr = pred_arr.detach().numpy()
original_arr = original_arr.numpy()
final_pred= []
for i in range(len(pred_arr)):
final_pred.append(np.argmax(pred_arr[i]))
final_pred = np.array(final_pred)
count = 0
for i in range(len(original_arr)):
if final_pred[i] == original_arr[i]:
count+=1
return count/len(final_pred)*100
def train_network(model, optimizer, criterion, X_train, y_train, X_test, y_test, num_epochs):
train_loss=[]
train_accuracy=[]
test_accuracy=[]
for epoch in range(num_epochs):
#forward feed
output_train = model(X_train)
train_accuracy.append(get_accuracy(output_train, y_train))
#calculate the loss
loss = criterion(output_train, y_train)
train_loss.append(loss.item())
#clear out the gradients from the last step loss.backward()
optimizer.zero_grad()
#backward propagation: calculate gradients
loss.backward()
#update the weights
optimizer.step()
with torch.no_grad():
output_test = model(X_test)
test_accuracy.append(get_accuracy(output_test, y_test))
if (epoch + 1) % 5 == 0:
print(f"Epoch {epoch+1}/{num_epochs}, Train Loss: {loss.item():.4f}, Train Accuracy: {sum(train_accuracy)/len(train_accuracy):.2f}, Test Accuracy: {sum(test_accuracy)/len(test_accuracy):.2f}")
return train_loss, train_accuracy, test_accuracy创建模型、优化器和损失函数对象。
input_dim = 4
output_dim = 3
learning_rate = 0.01
model = PyTorch_NN(input_dim, output_dim)
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)6、在notebook中监控PyTorch loss
现在你一定已经注意到 train_network 函数中的打印语句来监控损失和准确性。 这是一种方法。
X_train = torch.FloatTensor(X_train)
X_test = torch.FloatTensor(X_test)
y_train = torch.LongTensor(y_train)
y_test = torch.LongTensor(y_test)
train_loss, train_accuracy, test_accuracy = train_network(model=model, optimizer=optimizer, criterion=criterion, X_train=X_train, y_train=y_train, X_test=X_test, y_test=y_test, num_epochs=100)我们得到这样的输出。

如果需要,我们还可以使用 Matplotlib 绘制这些值:
fig, (ax1, ax2, ax3) = plt.subplots(3, figsize=(12, 6), sharex=True)
ax1.plot(train_accuracy)
ax1.set_ylabel("training accuracy")
ax2.plot(train_loss)
ax2.set_ylabel("training loss")
ax3.plot(test_accuracy)
ax3.set_ylabel("test accuracy")
ax3.set_xlabel("epochs")我们会看到这样的图表,表明损失和准确性之间的相关性。
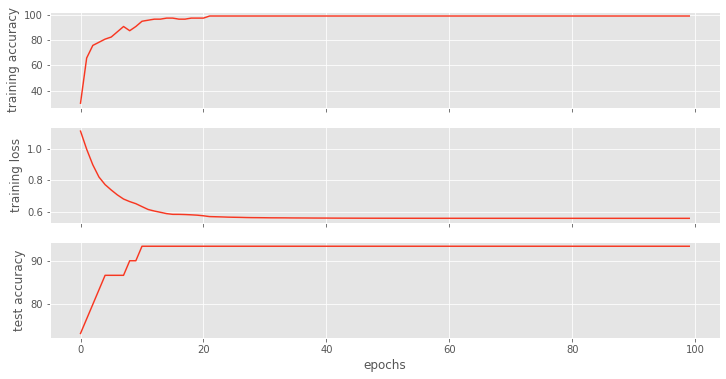
这种方法还不错,可以完成工作。 但我们必须记住,我们的问题陈述和模型越复杂,它需要的监控技术就越复杂。
7、使用 Neptune 监控 PyTorch 损失
一种更简单的监控指标的方法是将其记录在一个地方,使用 Neptune 之类的服务,并专注于更重要的任务,例如构建和训练模型。
为此,我们只需要执行几个小步骤。
首先,让我们安装所需的东西。
pip install neptune-client现在让我们初始化 Neptune 运行。
import neptune.new as neptune
run = neptune.init(project = 'common/pytorch-integration',
api_token = 'ANONYMOUS',
source_files = ['*.py'])我们还可以分配配置变量,例如:
run['config/model'] = type(model).__name__
run['config/criterion'] = type(criterion).__name__
run['config/optimizer'] = type(optimizer).__name__这是它在 UI 中的样子。
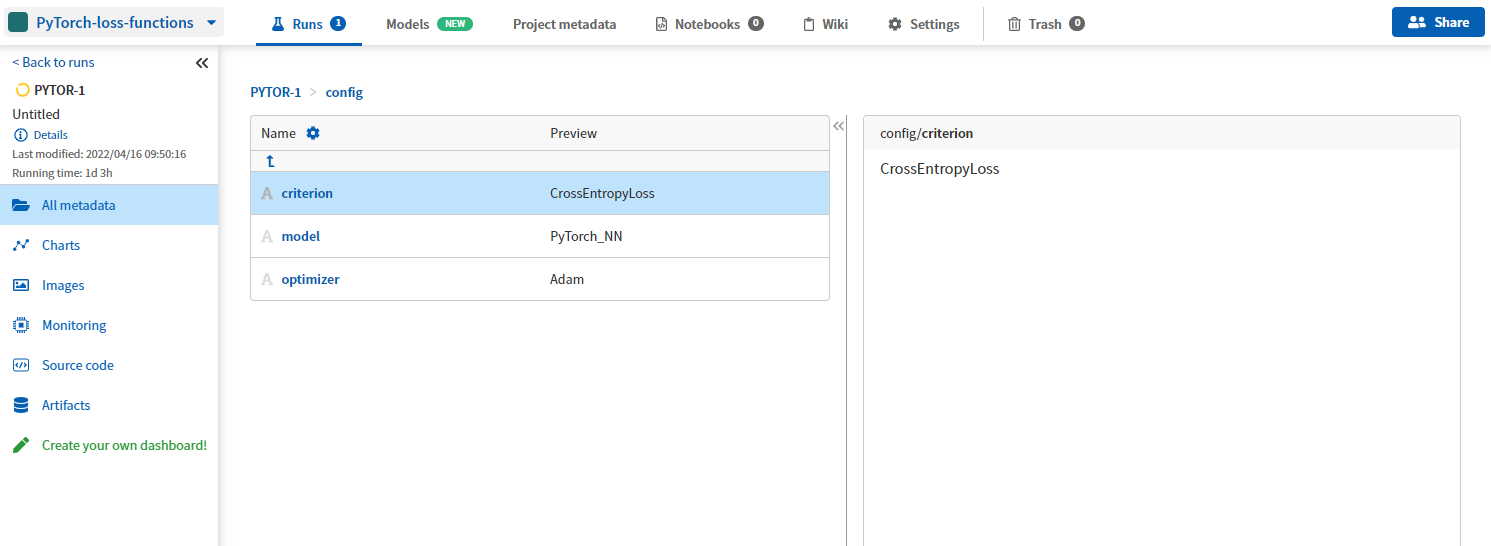
最后,我们可以通过在 train_network 函数中添加几行来记录我们的损失。 注意“运行”相关的行。
def train_network(model, optimizer, criterion, X_train, y_train, X_test, y_test, num_epochs):
train_loss=[]
train_accuracy=[]
test_accuracy=[]
for epoch in range(num_epochs):
#forward feed
output_train = model(X_train)
acc = get_accuracy(output_train, y_train)
train_accuracy.append(acc)
run["training/epoch/accuracy"].log(acc)
#calculate the loss
loss = criterion(output_train, y_train)
run["training/epoch/loss"].log(loss)
train_loss.append(loss.item())
#clear out the gradients from the last step loss.backward()
optimizer.zero_grad()
#backward propagation: calculate gradients
loss.backward()
#update the weights
optimizer.step()
with torch.no_grad():
output_test = model(X_test)
test_acc = get_accuracy(output_test, y_test)
test_accuracy.append(test_acc)
run["test/epoch/accuracy"].log(test_acc)
if (epoch + 1) % 5 == 0:
print(f"Epoch {epoch+1}/{num_epochs}, Train Loss: {loss.item():.4f}, Train Accuracy: {sum(train_accuracy)/len(train_accuracy):.2f}, Test Accuracy: {sum(test_accuracy)/len(test_accuracy):.2f}")
return train_loss, train_accuracy, test_accuracy这是我们在仪表板中得到的。 绝对无缝。
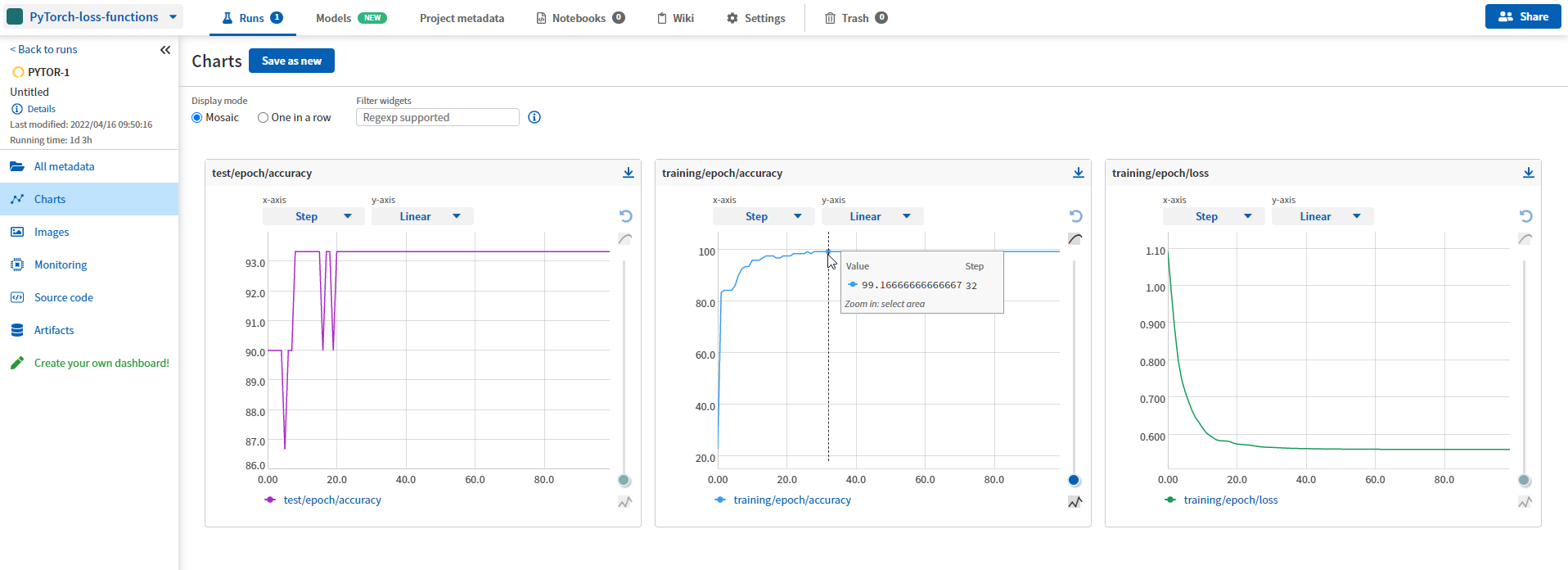
可以在此处的 Neptune UI 中查看此运行。 不用说,你可以用任何损失函数来做到这一点。
8、结束语
我们介绍了 PyTorch 中最常见的损失函数。 你可以选择适合自己项目的任何函数,或创建自己的自定义函数。
希望本文能作为你在机器学习任务中使用 PyTorch 损失函数的快速入门指南。
如果想更深入地了解该主题或了解其他损失函数,可以访问 PyTorch 官方文档。
原文链接:PyTorch Loss Functions: The Ultimate Guide
BimAnt翻译整理,转载请标明出处





