
NSDT工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器 - REVIT导出3D模型插件 - 3D模型语义搜索引擎 - AI模型在线查看 - Three.js虚拟轴心开发包 - 3D模型在线减面 - STL模型在线切割 - 3D道路快速建模
tinyML 的主要挑战是如何采用相对较大的神经网络(有时约为数百兆字节),并使其适合并在资源受限的微控制器上运行,同时保持最小的功耗预算。 为此,最有效的技术称为量化(quantization)。
1、小型机器学习神经网络的内存约束
在理解量化之前,有必要讨论一下为什么神经网络通常会占用如此多的内存。
神经网络由一系列层中的一系列互连神经元组成。 如图 1 所示,标准神经网络由互连的神经元层组成,每个神经元都有自己的权重、偏差和与其关联的激活函数。
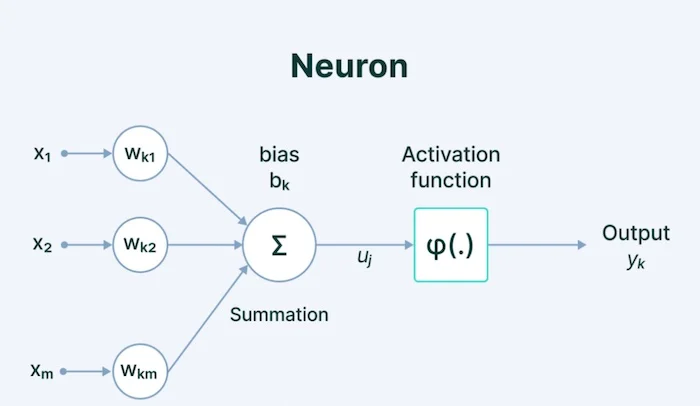
这些权重和偏差通常称为神经网络的“参数”。
每个神经元也有自己的“激活”,这个数字决定了该神经元的活跃程度。 神经元的激活基于其权重和偏差值以及所使用的激活函数。
权重和偏差是在训练期间进行调整的参数,并且通过扩展,神经元的激活也是如此。
这些值、权重、偏差和激活是神经网络物理存储在内存中的大部分内容。 标准是将这些数字表示为 32 位浮点值,这样可以实现高精度,并最终提高神经网络的准确性。
这种准确性就是神经网络往往占用大量内存的原因。 对于具有数百万个参数和激活的网络(每个参数和激活都存储为 32 位值),内存使用量会迅速增加。
例如,50 层 ResNet 架构包含大约 2600 万个权重和 1600 万个激活。 通过使用 32 位浮点值来表示权重和激活,整个架构将需要 168 MB 的存储空间。
2、什么是神经网络的量化?
量化是降低权重、偏差和激活精度的过程,从而消耗更少的内存。
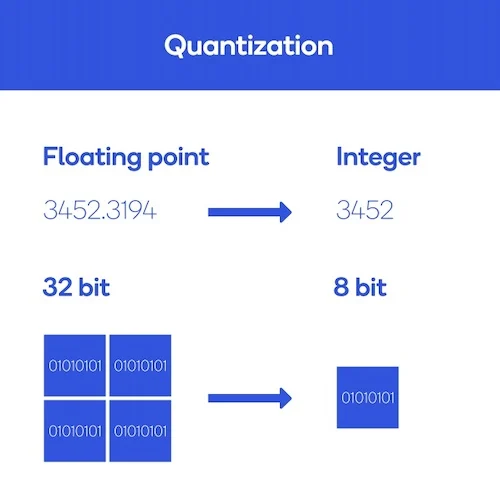
换句话说,量化的过程就将神经网络参数的32位浮点数表示,转换为更小的表示形式,例如8位整数。
例如,从 32 位变为 8 位将使模型大小减少 4 倍,因此量化的一个明显好处是显着减少内存。
图 2 显示了一个示例。
量化的另一个好处是它可以降低网络延迟并提高能效。
由于可以使用整数而不是浮点数据类型执行操作,因此网络速度得到了提高。 这些整数运算在大多数处理器内核(包括微控制器)上需要较少的计算。
总体而言,由于计算量减少和内存访问减少,功率效率得到了提高。
尽管有这些好处,但量化的代价是神经网络可能会失去准确性,因为它们不能精确地表示信息。 然而,根据损失的精度、网络架构和网络训练/量化方案,量化通常会导致非常小的精度损失,特别是在权衡延迟、内存使用方面的改进时 和功率。
3、如何量化机器学习模型
在实践中,有两种主要的量化方法:
- 训练后量化
- 量化感知的训练
顾名思义,训练后量化是一种神经网络完全使用浮点计算进行训练,然后进行量化的技术。
为此,一旦训练结束,神经网络就会被冻结,这意味着它的参数不能再更新,然后参数就会被量化。 量化模型最终被部署并用于执行推理,而无需对训练后参数进行任何更改。
虽然这种方法很简单,但它可能会导致更高的精度损失,因为所有与量化相关的误差都是在训练完成后发生的,因此无法补偿。
量化感知的训练(如图 3 所示)通过在训练期间使用前向传递中的量化版本来训练神经网络来补偿与量化相关的误差。
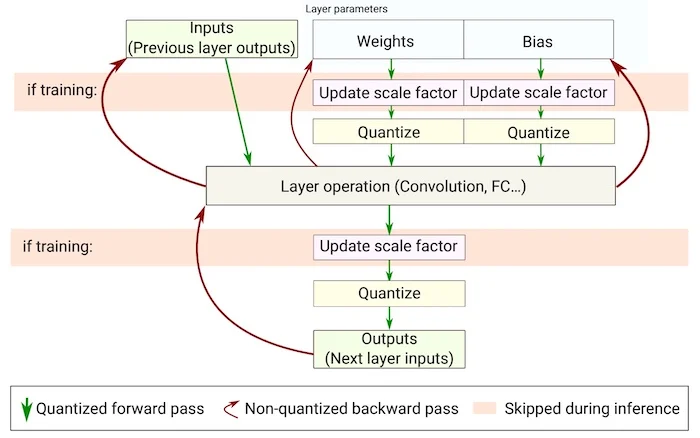
思路是与量化相关的误差将在训练期间累积在模型的总损失中,训练优化器将相应地调整参数并减少总体误差。
量化感知的训练的优点是比训练后量化损失低得多。
如需对量化背后的数学进行更深入的技术讨论,建议阅读 Gholami 等人的这篇论文。
4、TinyML 的量化
对于 TinyML 来说,量化是一个非常宝贵的工具,是整个领域的核心。
总而言之,量化是必要的,主要原因有以下三个:
- 量化显着减小了模型大小,这使得在微控制器等内存受限设备上运行机器学习变得更加可行。
- 量化允许 ML 模型运行,同时需要较少的处理能力 - TinyML 中使用的 MCU 往往具有比标准 CPU 或 GPU 更低的性能处理单元。
- 量化可以降低功耗——TinyML 的最初目标是以低于 1mW 的功率预算执行 ML 任务。 这对于在由纽扣电池等小型电池供电的设备上部署机器学习是必要的。
原文链接:Neural Network Quantization: What Is It and How Does It Relate to TinyML?
BimAnt翻译整理,转载请标明出处





