
NSDT工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器 - REVIT导出3D模型插件 - 3D模型语义搜索引擎 - AI模型在线查看 - Three.js虚拟轴心开发包 - 3D模型在线减面 - STL模型在线切割 - 3D道路快速建模
全球各行各业对 3D 世界和虚拟环境的需求呈指数级增长。 3D 工作流是工业数字化的核心,开发实时模拟以测试和验证自动驾驶汽车和机器人,运行数字孪生以优化工业制造,并为科学发现铺平新道路。
今天,3D 设计和世界构建仍然是高度手动的。 虽然 2D 艺术家和设计师已经使用了辅助工具,但 3D 工作流程仍然充满了重复、乏味的任务。
为场景创建或查找对象是一个耗时的过程,需要随着时间的推移磨练专业的 3D 技能,例如建模和纹理。 正确放置物体和艺术引导 3D 环境达到完美需要数小时的微调。
为了减少手动重复性任务并帮助创作者和设计师专注于他们工作中富有创意、令人愉悦的方面,NVIDIA 推出了许多人工智能项目,例如用于虚拟世界的生成人工智能工具。
1、AI 的 iPhone 时刻
借助 ChatGPT,我们现在正在体验 AI 的 iPhone 时刻,所有技术水平的个人都可以使用日常语言与高级计算平台进行交互。 大型语言模型 (LLM) 变得越来越复杂,当像 ChatGPT 这样的用户友好界面让每个人都可以访问它们时,它成为历史上增长最快的消费者应用程序,推出仅两个月就超过了 1 亿用户。 现在,每个行业都计划利用 AI 的力量进行广泛的应用,例如药物发现、自主机器和化身虚拟助手。
最近,我们对 OpenAI 的病毒式 ChatGPT 和新的 GPT-4 大型多模式模型进行了实验,以展示开发可以在 NVIDIA Omniverse 中为虚拟世界快速生成 3D 对象的自定义工具是多么容易。 OpenAI 联合创始人 Ilya Sutskever 在 GTC 2023 上与 NVIDIA 创始人兼首席执行官黄仁勋的炉边谈话中表示,与 ChatGPT 相比,GPT-4 标志着“在许多方面都有相当大的改进”。
通过将 GPT-4 与 Omniverse DeepSearch 相结合,Omniverse DeepSearch 是一个智能 AI 图书馆员,能够搜索未标记 3D 资产的海量数据库,我们能够快速开发自定义扩展,通过简单的基于文本的提示检索 3D 对象并自动将它们添加到 一个 3D 场景。
2、AI 房间生成器扩展
NVIDIA Omniverse(一个 3D 应用程序开发平台)中的这项有趣实验向开发人员和技术美术师展示了快速开发利用生成 AI 来填充现实环境的自定义工具是多么容易。 最终用户只需输入基于文本的提示即可自动生成和放置高保真对象,从而节省通常创建复杂场景所需的数小时时间。
从扩展生成的对象基于通用场景描述 (USD) SimReady 资产。 SimReady 资产是物理上精确的 3D 对象,可以在任何模拟中使用,并且表现得与它们在现实世界中一样。
2.1 获取有关 3D 场景的信息
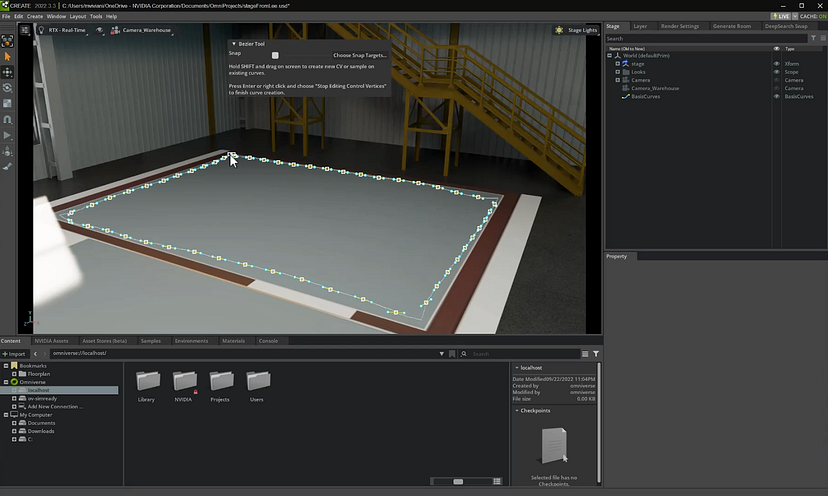
一切都从 Omniverse 中的USD场景开始。 用户可以使用 Omniverse 中的铅笔工具轻松圈出一个区域,输入他们想要生成的房间/环境类型——例如,仓库或接待室——然后单击一下即可创建该区域。
2.2 为 ChatGPT 创建提示
ChatGPT提示由四部分组成:系统输入、用户输入示例、辅助输出示例和用户提示。
让我们从适合用户场景的提示的各个方面开始。 这包括用户输入的文本以及来自场景的数据。
例如,如果用户想要创建一个接待室,他们会指定类似“这是我们会见客户的房间。 确保有一套舒适的扶手椅、一张沙发和一张咖啡桌。” 或者,如果他们想添加一定数量的项目,他们可以添加“确保至少包含 10 项”。
此文本与场景信息相结合,例如我们将放置项目的区域的大小和名称作为用户提示。
“Reception room, 7x10m, origin at (0.0,0.0,0.0). This is the room where we meet
our customers. Make sure there is a set of comfortable armchairs, a sofa and a
coffee table”这种将用户文本与场景细节相结合的想法非常强大。 在场景中选择一个对象并以编程方式访问其详细信息比要求用户编写提示来描述所有这些详细信息要简单得多。 我怀疑我们会看到很多使用这种文本 + 场景到场景模式的 Omniverse 扩展。
除了用户提示之外,我们还需要使用系统提示和一两次训练来启动 ChatGPT。
为了创建可预测的、确定性的结果,系统提示和示例指示 AI 专门返回一个 JSON,其中包含以明确定义的方式格式化的所有信息,因此它可以在 Omniverse 中使用。
以下是我们将发送的四个提示。
- 系统提示:这为 AI 设置了约束和指令
You are an area generator expert. Given an area of a certain size, you can generate a list of items that are appropriate to that area, in the right place.
You operate in a 3D Space. You work in a X,Y,Z coordinate system. X denotes width, Y denotes height, Z denotes depth. 0.0,0.0,0.0 is the default space origin.
You receive from the user the name of the area, the size of the area on X and Z axis in centimeters, the origin point of the area (which is at the center of the area).
You answer by only generating JSON files that contain the following information:
- area_name: name of the area
- X: coordinate of the area on X axis
- Y: coordinate of the area on Y axis
- Z: coordinate of the area on Z axis
- area_size_X: dimension in cm of the area on X axis
- area_size_Z: dimension in cm of the area on Z axis
- area_objects_list: list of all the objects in the area
For each object you need to store:
- object_name: name of the object
- X: coordinate of the object on X axis
- Y: coordinate of the object on Y axis
- Z: coordinate of the object on Z axis
Each object name should include an appropriate adjective.
Keep in mind, objects should be placed in the area to create the most meaningful layout possible, and they shouldn't overlap.
All objects must be within the bounds of the area size; Never place objects further than 1/2 the length or 1/2 the depth of the area from the origin.
Also keep in mind that the objects should be disposed all over the area in respect to the origin point of the area, and you can use negative values as well to display items correctly, since the origin of the area is always at the center of the area.
Remember, you only generate JSON code, nothing else. It's very important.- 用户输入示例
这是用户可能提交的示例。 请注意,它是来自场景和文本提示的数据的组合。
"Reception room, 7x10m, origin at (0.0,0.0,0.0). This is the room where we meet
our customers. Make sure there is a set of comfortable armchairs, a sofa and a
coffee table"- 助理输出示例
这提供了 AI 必须使用的模板。 请注意我们是如何描述我们期望的确切 JSON 的。
{
"area_name": "Reception",
"X": 0.0,
"Y": 0.0,
"Z": 0.0,
"area_size_X": 700,
"area_size_Z": 1000,
"area_objects_list": [
{
"object_name": "White_Round_Coffee_Table",
"X": -120,
"Y": 0.0,
"Z": 130
},
{
"object_name": "Leather_Sofa",
"X": 250,
"Y": 0.0,
"Z": -90
},
{
"object_name": "Comfortable_Armchair_1",
"X": -150,
"Y": 0.0,
"Z": 50
},
{
"object_name": "Comfortable_Armchair_2",
"X": -150,
"Y": 0.0,
"Z": -50
} ]
}- 连接到 OpenAI
此提示通过 Python 代码从扩展程序发送到 AI。 这在 Omniverse Kit 中非常简单,只需使用最新的 OpenAI Python 库的几个命令即可完成。 请注意,我们将系统输入、示例用户输入和我们刚刚概述的示例预期助手输出传递给 OpenAI API。 变量“response”将包含来自 ChatGPT 的预期响应。
# Create a completion using the chatGPT model
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
# if you have access, you can swap to model="gpt-4",
messages=[
{"role": "system", "content": system_input},
{"role": "user", "content": user_input},
{"role": "assistant", "content": assistant_input},
{"role": "user", "content": my_prompt},
]
)
# parse response and extract text
text = response["choices"][0]["message"]['content']- 将结果从 ChatGPT 传递到 Omniverse DeepSearch API 并生成场景:
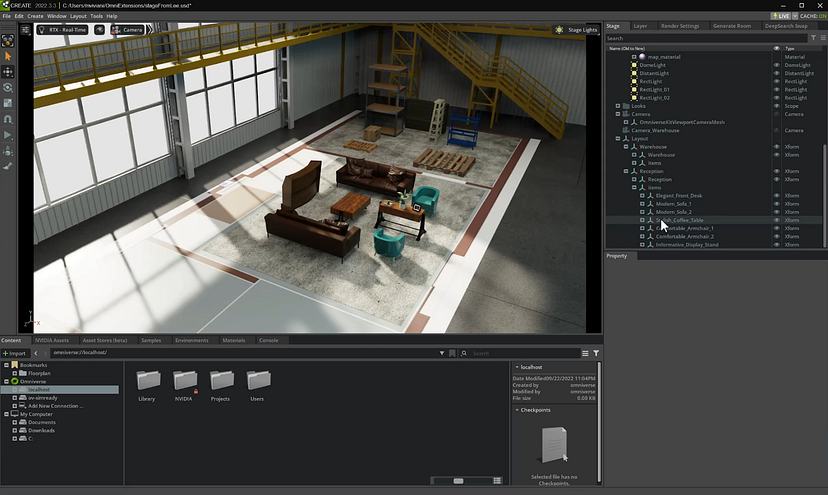
ChatGPT JSON 响应中的项目随后由扩展程序解析并传递给 Omnivere DeepSearch API。 DeepSearch 允许用户使用自然语言查询来搜索存储在 Omniverse Nucleus 服务器中的 3D 模型。
这意味着即使我们不知道沙发模型的确切文件名,例如,我们也可以通过搜索“Comfortable Sofa”来检索它,这正是我们从 ChatGPT 获得的。
DeepSearch 理解自然语言,通过向它询问“舒适的沙发”,我们得到了我们乐于助人的 AI 图书管理员从我们当前资产库中的资产选择中确定最适合的项目列表。 它在这方面出奇的好,所以我们经常可以使用它返回的第一个项目,但当然我们在选择中构建,以防用户想要从列表中选择一些东西。
从那里,我们只需将对象添加到舞台上。
- 将 DeepSearch 中的项目添加到 Omniverse 阶段
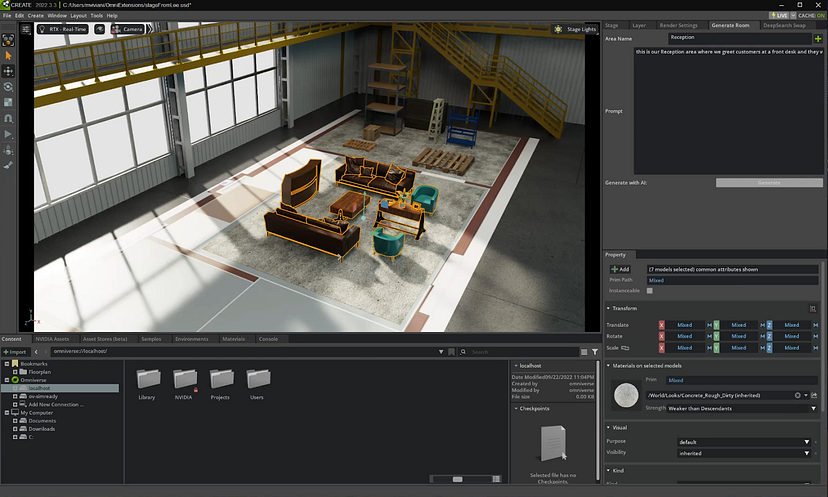
现在 DeepSearch 已经返回结果,我们只需要将对象放入 Omniverse。 在我们的扩展中,我们创建了一个名为 place_deepsearch_results() 的函数来处理所有项目并将它们放置在场景中。
def place_deepsearch_results(gpt_results, query_result, root_prim_path):
index = 0
for item in query_result:
# Define Prim
stage = omni.usd.get_context().get_stage()
prim_parent_path = root_prim_path + item[‘object_name’].replace(" ", "_")
parent_xForm = UsdGeom.Xform.Define(stage, prim_parent_path)
prim_path = prim_parent_path + "/" + item[‘object_name’].replace(" ", "_")
next_prim = stage.DefinePrim(prim_path, 'Xform')
# Add reference to USD Asset
references: Usd.references = next_prim.GetReferences()
references.AddReference(
assetPath="your_server://your_asset_folder" + item[‘asset_path’])
# Add reference for future search refinement
config = next_prim.CreateAttribute("DeepSearch:Query", Sdf.ValueTypeNames.String)
config.Set(item[‘object_name’])
# translate prim
next_object = gpt_results[index]
index = index + 1
x = next_object['X']
y = next_object['Y']
z = next_object['Z']这种放置项目的方法迭代我们从 GPT 获得的 query_result 项目,使用 USD API 创建和定义新的原语,根据 gpt_results 中的数据设置它们的转换和属性。 我们还将 DeepSearch 查询保存在 USD 的一个属性中,以便以后在我们想要再次运行 DeepSearch 时使用它。 请注意,资产路径“your_server//your_asset_folder”是一个占位符,应替换为执行 DeepSearch 的文件夹的真实路径。
瞧! 我们在 Omniverse 中拥有 AI 生成的场景!
2.3 使用 DeepSearch 交换项目
但是,我们可能不喜欢第一次检索到的所有项目。 因此,我们构建了一个小的配套扩展,允许用户浏览相似的对象并通过单击将它们交换进去。 使用 Omniverse,以模块化方式构建非常容易,因此您可以使用其他扩展轻松扩展您的工作流程。
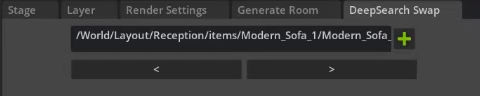
这个配套扩展非常简单。 它以通过 DeepSearch 生成的对象作为参数,并提供两个按钮以从相关的 DeepSearch 查询中获取下一个或上一个对象。 例如,如果 USD 文件包含属性“DeepSearch:Query = Modern Sofa”,它将通过 DeepSearch 再次运行此搜索并获得下一个最佳结果。 你当然可以将其扩展为一个可视化 UI,其中包含所有搜索结果的图片,类似于我们用于一般深度搜索查询的窗口。 为了让这个例子简单,我们只选择了两个简单的按钮。
请参阅下面的代码,其中显示了增加索引的函数,以及实际根据索引操作对象交换的函数 replace_reference(self)。
def increment_prim_index():
if self._query_results is None:
return
self._index = self._index + 1
if self._index >= len(self._query_results.paths):
self._index = 0
self.replace_reference()
def replace_reference(self):
references: Usd.references = self._selected_prim.GetReferences()
references.ClearReferences()
references.AddReference(
assetPath="your_server://your_asset_folder" + self._query_results.paths[self._index].uri)请注意,如上所述,路径“your_server://your_asset_folder”只是一个占位符,你应该将其替换为执行 DeepSearch 查询的 Nucleus 文件夹。
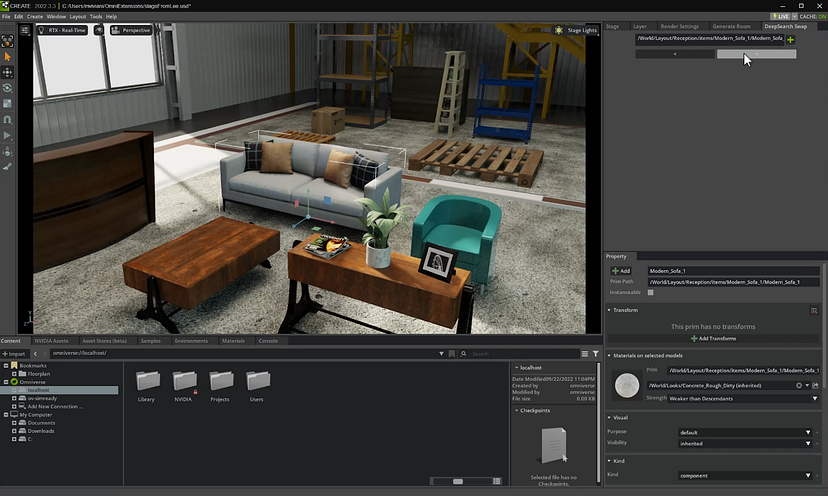
这展示了如何通过结合 LLM 和 Omniverse API 的强大功能来创建能够增强创造力和加快流程的工具。
3、从 ChatGPT 到 GPT-4
OpenAI 的新 GPT-4 的主要进步之一是它在大型语言模型中增强了空间意识。
我们最初使用基于 GPT-3.5-turbo 的 ChatGPT API。 虽然它提供了良好的空间意识,但 GPT-4 提供了更好的结果。 在上面的视频中看到的版本使用的是 GPT-4。
GPT-4 在解决复杂任务和理解复杂指令方面相对于 GPT-3.5 有了很大改进。 因此,在设计文本提示以“指示 AI”时,我们可以更具描述性并使用自然语言
我们可以给人工智能非常明确的指令,比如:
- “每个对象名称都应包含一个适当的形容词。”
- “请记住,应将对象放置在区域中以创建最有意义的布局,并且它们不应重叠。”
- “所有物体都必须在区域大小的范围内; 切勿将物体放置在距离原点 1/2 长度或 1/2 深度的区域之外。”
- “还要记住,对象应该放置在相对于区域原点的整个区域,你也可以使用负值来正确显示项目,因为区域的原点总是在中心 该地区。”
事实上,AI 在生成响应时会适当地遵循这些系统提示,这一事实尤其令人印象深刻,因为 AI 展示了对空间意识以及如何正确放置物品的良好理解。 使用 GPT-3.5 完成此任务的挑战之一是有时物体会在房间外或奇怪的位置产生。
GPT-4 不仅将物体放置在房间的正确边界内,而且还按逻辑放置物体:床头柜实际上会出现在床的一侧,咖啡桌将放置在两个沙发之间,等等。
有了这个,我们可能只是触及了 LLM 在 3D 空间中可以做什么的皮毛!
5、构建自己的 ChatGPT 支持的扩展程序
虽然这只是 AI 连接到 3D 空间后可以做什么的一个小演示,但我们相信它将打开场景构建之外的各种工具的大门。 开发人员可以在 Omniverse 中构建由 AI 驱动的扩展,用于照明、相机、动画、角色对话和其他优化创作者工作流程的元素。 他们甚至可以开发工具将物理附加到场景并运行整个模拟。
你可以在 GitHub 上下载并试验 AI Room Generator Extension Sample。 我们鼓励其他开发人员尝试构建扩展或为 Omniverse 创建他们自己的生成 AI 扩展。
原文链接:How ChatGPT and GPT-4 Can Be Used for 3D Content Generation
BimAnt翻译整理,转载请标明出处





