
NSDT工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器 - REVIT导出3D模型插件 - 3D模型语义搜索引擎 - AI模型在线查看 - Three.js虚拟轴心开发包 - 3D模型在线减面 - STL模型在线切割 - 3D道路快速建模
得益于现有的硬件和加速器,深度学习在 2010 年代初开始兴起,在这种支持下,研究人员和工程师提出了更复杂、更大的模型。然而,内存消耗和执行时间等限制仍然是一个挑战。由于计算资源的限制,这些挑战在工程和商业领域变得更加突出。
近年来,随着更大、更复杂的模型的普及,优化模型以使其能够以最小的资源消耗输出尽可能高的质量已成为一个关键问题。这一主题在深度学习模型的推理阶段的重要性是双重的。这种重要性除了运行时的优化(速度和内存消耗)外,还与模型训练环境和推理环境之间的差异有关。一般来说,在环境中训练和推理模型并不总是可能的。因此,提供将开发和训练过程与部署和推理过程分开的条件一直是机器学习工程师和研究人员关注的问题之一。
在本系列文章中,我们打算通过解决底层细节来研究在 ONNX 和 ONNX Runtime 的帮助下优化神经网络模型所面临的挑战。
在第 1 部分中,我们将回顾模型优化和加速方法的介绍,并解释需要通用中间表示 ONNX 的原因。在第 2 部分中,我们将深入了解 ONNX Runtime 的构建块。
本文为第1部分,接下来,我们将概述推理阶段可用的优化和加速方法:
1、推理加速栈

推理加速栈由不同级别组成,至少应使用其中一个级别才能实现更快的推理。它可以分为三种类型的级别:
1.1 硬件:通过并行化提高计算能力
硬件设备处于加速器的最低级别。CPU、GPU、TPU 等单元执行计算。尽管存在差异,但更快的计算可带来更快的模型推导。然而,由于摩尔定律等原因,硬件加速存在根本限制。

1.2 软件:不改变模型的加速
任何不改变模型的加速都属于此类别。这些方法用于优化计算图,使模型保持不变。
这些方法分为两组:
低级库:硬件特定的优化
这些库(例如 cuDNN、MKL-DNN 等)通常用于图形计算,并为主要使用 GPU 并行性的常见过程(例如前向和后向卷积、池化、规范化、激活层)提供高度调整的实现。

图形编译器:优化计算图中的前向或后向路径
我们稍后会讨论这些软件加速器组。
1.3 算法:通过改变模型进行加速
这些类型的加速通过改变模型或架构来加速推理过程。这些方法的重点是消除模型中可能存在的冗余,或保留模型的重要信息并丢弃不太重要的信息。
这些方法可分为三类:
- 修剪:过滤网络中不太重要的权重
- 网络量化:用精度较低的紧凑表示替换浮点权重或激活
- 神经架构搜索 (NAS):通过从允许的架构空间中选择正确的架构来实现网络架构工程的自动化
2、图编译器
在之前的推理加速堆栈中,图形编译器被提及为软件加速器之一。在本节中,我们将更深入地讨论它们。
大多数深度学习架构都可以使用有向无环图 (DAG) 来描述,其中每个节点代表一个神经元。如果一个节点的输出是另一个节点的输入,则两个节点通过一条边连接。与此 DAG 表示类似,计算图中的节点表示向量运算符,而它们的边表示它们之间的数据依赖关系。

当我们在 TensorFlow 或 PyTorch 中定义神经网络时,该网络将成为计算图,然后在所需的硬件上执行。因此,计算图可以被视为中间表示 (IR),这对于优化和在不同设备上执行非常有用。
计算图复杂度随大小线性增加。图编译器实际上在此时发挥作用。他们的目标是优化生成的计算图以在给定硬件上进行推理。
然而,使用图编译器的最大挑战源于框架和编译器通常是彼此独立开发的:
- 框架可能会实现编译器尚未实现的新运算符。
- 一些基本层(例如卷积)具有不同的实现。
- 有些编译器仅适用于某些框架;例如,OpenVino 仅适用于 TensorFlow 和 ONNX。因此,如果我们有一个要在 OpenVino 上编译的 PyTorch 模型,则必须先将其编译为 ONNX,然后再编译为 OpenVino(我们稍后会讨论 ONNX)。
图编译器(例如 TVM、TensorRT、OpenVino 等)将深度学习框架中的高级计算图映射到可以在给定硬件上执行的操作。在编译计算图或将其映射到硬件时,编译器会对硬件执行优化以提高推理速度。这些优化包括:
图重写
图的结构指定了操作的执行顺序。作业调度考虑确定执行一系列操作的最佳顺序。
通常可以通过应用一些基本操作来实现此最佳顺序;操作包括:
- 删除/添加节点或边
- 节点融合
- 用另一个子图替换一个子图
- 删除具有未使用输出的层
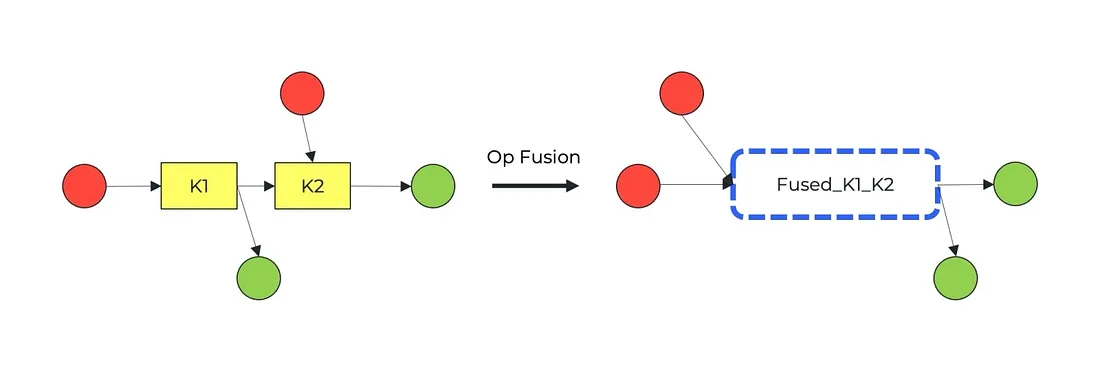
操作融合
计算图通常包含相对频繁或具有特殊硬件内核的操作序列。
许多编译器都利用了这一事实,通过融合操作(如果可能)并消除不必要的内存访问。
在许多情况下都可以看到操作融合;例如,卷积、ReLU 和 BatchNorm 通常组合成一个操作。
操作分配/操作调度
优化的一部分是确定目标硬件的最佳操作分配,尤其是在多台设备上的推理阶段。
图编译器提供了一个额外的硬件抽象层,可加速各种设备上的推理过程。操作根据不同的策略进行调度。
如果有多个不同的设备,则每个设备都有自己的随时可运行的操作队列。在这种情况下,图编译器通过确定为图中的不同节点分配优先级所需的适当调度策略并考虑跨设备依赖性来执行优化。
今天,每个框架都有自己的计算图表示。此外,框架通常针对特定目的进行优化(例如快速训练、支持复杂架构、在移动设备上进行推理等)。因此,开发人员可以根据上述目标之一选择所需的框架。
根据上述内容,要求使用不同框架开发的模型能够在任何环境中并根据该环境的配置最佳地工作。换句话说,我们需要一个共同的中间表示。
3、ONNX,一种通用的中间表示
ONNX 是一种通用的中间表示 (IR),有助于在该领域建立强大的生态系统。通过提供计算图的通用表示,ONNX 可帮助开发人员根据其目的选择正确的框架,使作者能够专注于创造性的改进,并使硬件供应商能够促进其平台上的优化。

ONNX 的三个主要任务可以列出如下:
- 将模型从任何框架转换为 ONNX 格式
- 将 ONNX 格式转换为任何所需的框架
- 在支持的运行时引擎上使用 ONNX 模型进行更快的推理
4、ONNX 文件格式
ONNX 文件实际上是一个可扩展的规范,由三部分组成:
- 可扩展计算图模型的定义
- 标准数据类型定义
- 内部运算符(内置)的定义
前两种情况实际上一起形成了相同的中间表示或 IR。内置运算符的完整列表也可以在此处和此处找到。
ONNX 以协议缓冲区格式存储数据。此格式是一种具有自己的 IR 和编译器的数据序列化方法。在协议缓冲区的 IR 格式中,定义了将要交换的消息。消息中的每个字段都用唯一的数字编号,并且在信息交换中只传输此数字,以避免发送大量信息。在这种格式中,只确定数据类型和数据顺序。每个数据都由使用它的软件解释。
例如,在 Protocol Buffers 格式中,具有以下规格的节点:
Y = Conv[kernel=1, pad=1, stride=1](X, W, B)
定义如下:

计算图的其他组件(例如图、节点、特征、张量等)具有类似的结构。
ONNX 中最高级别的数据结构是 Protocol Buffers 中定义为 ModelProto 的“模型”:

例如, opset_import 是提供给模型的“操作集”标识符的集合。实现必须支持集合中的所有运算符,否则将拒绝该模型。更改、增加或减少运算符的数量可能会导致 opset 的新版本。因此,ONNX 中的操作是版本化的。
通过在大多数随机数据上运行模型,在给定框架中开发的模型将转换为 ONNX 格式。这种转换以这样的方式发生:执行的操作映射到 ONNX 操作,最终将整个模型图映射到 ONNX 格式。
由于 ONNX 文件是二进制文件,因此可以使用 Protocol Buffers 编译器解码后检查其内容。在 ONNX 源代码中,布局了此结构及其解释方式,可用于对二进制模型进行编码和解码。
将 ONNX 模型解码为协议缓冲区格式:
protoc — decode=onnx.ModelProto onnx.proto < yourfile.onnx > yourfile.onnx.txt也可以编码为 ONNX 模型:
protoc — encode=onnx.ModelProto onnx.proto < yourfile.onnx.txt > yourfile.onnx此外,还开发了 Netron、VisualDL 和 Zetane 等工具来抽象可视化 ONNX 模型计算图,可以通过将 ONNX 模型提供给它们来进行视觉检查。
在下一篇文章中,我们将讨论 ONNX 运行时构建块。
原文链接:A Deep Dive into ONNX & ONNX Runtime (Part 1)
BimAnt翻译整理,转载请标明出处





