
NSDT工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器 - REVIT导出3D模型插件 - 3D模型语义搜索引擎 - AI模型在线查看 - Three.js虚拟轴心开发包 - 3D模型在线减面 - STL模型在线切割 - 3D道路快速建模
当开始新的研究时,我的方法通常是测试不同的相关事物,直到有足够的经验让我开始将这些点联系起来。 在开始构建用于 3D 对象检测的自定义模型之前,我购买了一台 LiDAR 并处理了一些数据。 下一个明显的步骤是在我为自己的数据贴标签之前找出研究界如何标记这些数据。
有一些非常流行的自动驾驶点云数据集,其中最受欢迎的是 KITTI 数据集、NuScenes、Waymo 开放数据集等。 不久前,我花了一些时间研究 KITTI 数据集,总的来说,我注意到找到合适的工具来可视化数据是多么困难。 直到我发现了 Open3D,它使我可以轻松处理和可视化点云。 Open3D 可以选择与 Open3D-ML 捆绑在一起,其中包括用于可视化带注释的点云数据的工具,以及训练/构建/测试 3D 机器学习模型(更多内容将在以后的帖子中介绍)。

Open3D-ML GitHub 页面提供了使用 pip 安装库的简单说明,但这仅适用于特定版本的 CUDA 和 TensorFlow。 因为我想使用此类库的较新版本,所以我决定从源代码构建 Open3D。 这样做的时候,我发现有些步骤缺失或者不够清晰。 为了简化有兴趣构建此库的任何人的生活,我在下面列出了安装和测试 Open3D-ML 所遵循的步骤。 请注意,我的系统是 Ubuntu 20.04.4 LTS,并且我有支持 Cuda 的 GPU,因此,此处提供的说明可能会因您的系统而异。
第1步:安装Conda
建议使用 Conda 来尝试新事物,而不会冒破坏系统的风险。 要安装 Conda,请按照此处的官方步骤操作。
第2步:创建并激活Conda环境
确保将 myenv 替换为你要使用的实际名称。
conda create --name myenv
conda activate myenv第3步:安装 Node.js
要安装 Node.js,你可以按照以下步骤操作:
curl -fsSL https://deb.nodesource.com/setup_18.x | sudo -E bash -
sudo apt-get install -y nodejs
sudo npm install -g yarn第 4 步:安装 TensorFlow
要安装 TensorFlow,请按照此处的官方步骤操作。
第5步:安装Jupyter Lab
conda install -c conda-forge jupyterlab第 6 步:克隆 Open3D
git clone https://github.com/isl-org/Open3D第7步:安装依赖项
cd Open3d
./util/install_deps_ubuntu.sh第 8步:创建构建目录并克隆 Open3D-ML
mkdir build
cd build
git clone https://github.com/isl-org/Open3D-ML.git第 9 步:配置安装
这是假设你有一个支持 Cuda 的 GPU。 确保将 /path/to/your/conda/env/bin/python 替换为 Python 的正确路径。 另外不要忘记命令末尾的两个点。
cmake -DBUILD_CUDA_MODULE=ON -DGLIBCXX_USE_CXX11_ABI=ON -DBUILD_TENSORFLOW_OPS=ON -DBUNDLE_OPEN3D_ML=ON -DOPEN3D_ML_ROOT=Open3D-ML -DBUILD_JUPYTER_EXTENSION:BOOL=ON -DBUILD_WEBRTC=ON -DPython3_ROOT=/path/to/your/conda/env/bin/python ..第10步:构建库
make -j$(nproc)第 11 步:安装为 Python 包
make install-pip-package第12步:测试Open3D安装
python -c "import open3d"第 13 步:使用 TensorFlow 安装测试 Open3D-ML
python -c "import open3d.ml.tf as ml3d"第 14 步:下载并准备数据集
在此步骤中,我们将下载 SemanticKITTI 数据集。 该数据集超过 80 GB,因此请确保有足够的空间和时间。 以下步骤将下载并准备数据集。 确保将 /path/to/save/dataset 替换为所需的路径。
cd Open3D-ML/scripts/
./download_semantickitti.sh /path/to/save/dataset第 15 步:加载并可视化数据集
为了可视化 SemanticKITTI 数据集,请将以下 Python 代码保存在文件中并运行它。 请记住将 /path/to/save/dataset/ 替换为保存 SemanticKITTI 数据集的路径。
import open3d.ml.tf as ml3d
# construct a dataset by specifying dataset_path
dataset = ml3d.datasets.SemanticKITTI(dataset_path='/path/to/save/dataset/SemanticKitti/')
# get the 'all' split that combines training, validation and test set
all_split = dataset.get_split('all')
# print the attributes of the first datum
print(all_split.get_attr(0))
# print the shape of the first point cloud
print(all_split.get_data(0)['point'].shape)
# show the first 100 frames using the visualizer
vis = ml3d.vis.Visualizer()
vis.visualize_dataset(dataset, 'all', indices=range(340))当你运行 Python 脚本时,可视化工具会打开并加载前 340 个数据帧。 你可以更改代码中加载的帧数。 打开后,可以根据强度探索点云,但最有趣的部分是根据每个点的语义标签探索点云。 下面的视频显示了两个示例。
在第一个视频中,你可以了解如何通过选择多个帧将它们作为动画播放。 确保从提供的选项中选择标签作为数据类型。
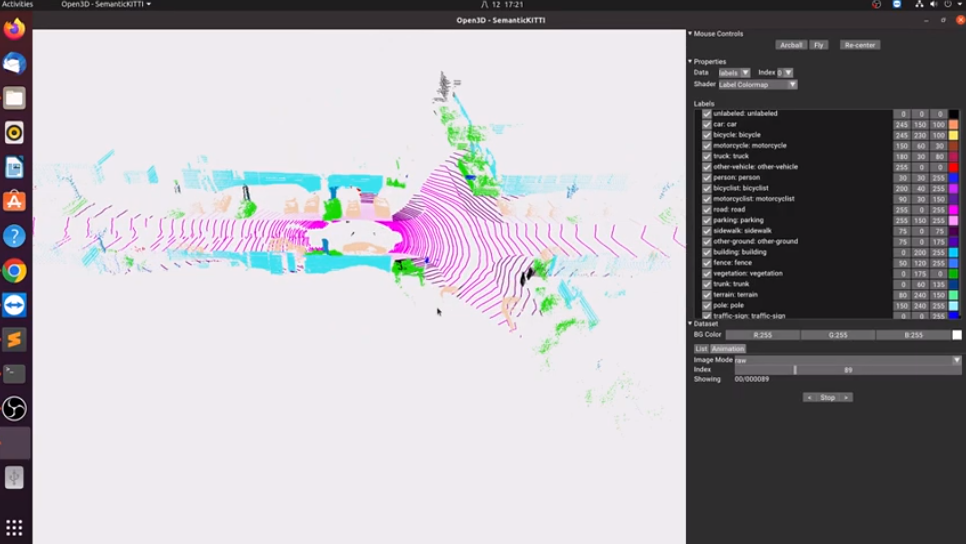
第二个视频展示了如何选择给定的帧并通过激活和停用某些标签来检查存在的语义对象。 当某些颜色太浅而难以看到时,你可以更改颜色以提高可见度。
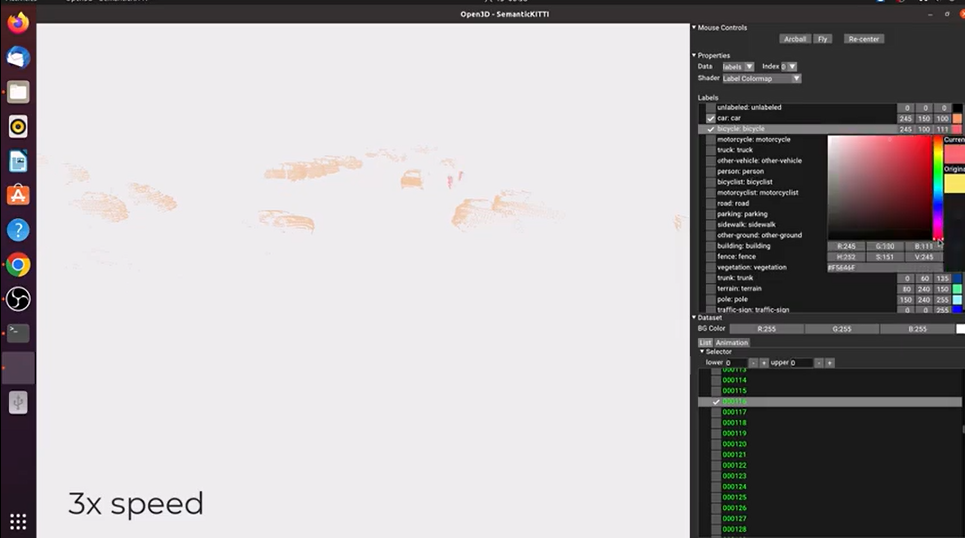
第 16 步:故障排除
在执行上述步骤时,我遇到了以下异常。 修复它们很容易,如果你也找到它们的话。
如果出现 ModuleNotFoundError: No module named ‘yapf’
pip install yapf如果出现 ModuleNotFoundError: No module named ‘jupyter_packaging’
pip install jupyter-packaging就是这样。 Open3D-ML 是可视化点云数据集的绝佳工具。 下一步是研究数据集以了解它们是如何标记的。 然后,我将介绍使用 Open3D 训练/测试 3D 模型。 希望这将使我更接近使用自定义数据执行相同的操作。
原文链接:Testing Open3D-ML for 3D Object Detection and Segmentation
BimAnt翻译整理,转载请标明出处





