
NSDT工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器 - REVIT导出3D模型插件 - 3D模型语义搜索引擎 - AI模型在线查看 - Three.js虚拟轴心开发包 - 3D模型在线减面 - STL模型在线切割 - 3D道路快速建模
在过去的几十年里,人工神经网络已被用于解决计算机视觉、自然语言处理等各种应用领域的问题。最近,科学机器学习 (ML) 社区出现了另一个非常有前途的应用:使用人工神经网络求解偏微分方程 (PDE),使用通常称为物理信息神经网络 (PINN) 的方法。 PINN 最初是在 [1] 中的开创性工作中引入的,如今它们不再局限于纯粹的研究主题,而且在行业中也越来越受欢迎,足以在 2021 年进入著名的 Gartner 新兴技术炒作周期。
PDE 在从流体动力学到声学和结构工程的许多工程和基础科学领域发挥着至关重要的作用。有限元建模 (FEM) 方法是行业中普遍使用的标准求解器。尽管它们很受欢迎,但 FEM 方法显示出一些局限性,例如它们对大型工业问题的计算成本(主要是由于所需的网格大小)以及利用外部数据源(例如传感器数据)来驱动 PDE 的解决方案的问题。
这篇文章中讨论的 PINN 方法被认为是 FEM 方法的一种有前途的替代方法,可以弥补其中的一些局限性。这种方法与标准的监督 ML 完全不同。事实上,它不是纯粹依赖数据,而是使用 PDE 本身的物理特性来指导训练过程。已知数据点可以很容易地添加到基于物理的损失函数之上,以加快训练速度。
这篇文章简单介绍了 PINN 背后的主要概念,然后展示了如何从头开始构建 PINN 来求解简单的一阶常微分方程。为了构建神经网络,我将使用神奇的 PyTorch 库。让我们开始吧!
1、PINN工作原理
为了更深入地了解 PINN,让我们从选择一个微分方程开始。 为了简单起见,在这篇文章中,我关注一个非常简单的一阶微分方程:
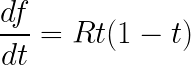
此处函数 f(t) 表示随时间 t 的人口增长率,参数 R 表示最大人口增长率。 为了完全指定该方程的解,需要施加边界条件,例如在 t = 0 时:
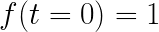
尽管这个方程的解可以很容易地通过分析得出,但用它作为案例来说明 PINN 的工作原理有助于我们的理解。 下面解释的所有技术都可以很容易地应用于更复杂的常微分方程和偏微分方程。 然而,通常需要进一步的技巧才能在更复杂的场景中获得良好的收敛。
PINN 基于 神经网络 的两个基本属性:
- 已经正式证明 [2] NN 是通用函数逼近器。 因此,一个神经网络,只要它有足够的深度和表现力,就可以逼近任何函数,因此也可以逼近上述微分方程的解。
- 使用自动微分 (AD) 计算 NN 输出相对于其任何输入(当然还有反向传播期间的模型参数)的导数(任意阶)既简单又便宜。自动微分实际上是神经网络如此高效和成功的最重要的原因
这些都是不错的功能,但我们如何才能让神经网络真正学习解决方案呢? 这里出现了 PINN [3、4] 背后出人意料的简单但极其聪明的想法:我们可以构造 NN 损失函数,以便在最小化时自动满足 PDE。 换句话说,最重要的损失贡献被视为微分方程的残差如下:
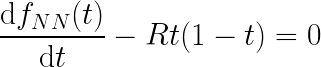
其中 f_NN(t) 是具有一个输入的 NN 的输出,其导数是自动计算的。 可以立即看出,如果 NN 输出符合上述方程,则实际上是在求解微分方程。 要计算来自 DE 残差的实际损失贡献,需要在方程域中指定一组点(通常称为配置点)并评估均方误差 (MSE) 或另一个损失函数作为所有所选坐标的平均值 :
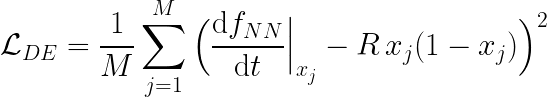
然而,仅基于上述残差的损失并不能确保方程具有唯一解。 因此,让我们以与上述完全相同的方式将边界条件添加到损失计算中:
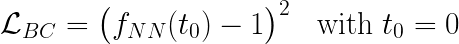
因此,最终的损失只是:
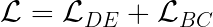
在优化过程中,这被最小化并且 NN 输出被训练以遵守微分方程和给定的边界条件,从而近似最终的 DE 解。
PINN 框架非常灵活,使用上面提出的想法,可以添加更多边界条件,包括更复杂的条件,例如对 f(x) 的导数的约束,或者使用具有多个 NN 处理时间相关和多维问题 输入。
现在让我们看看如何使用 PyTorch 构建的简单神经网络来构建这样的损失函数。
2、从零构建 PINN神经网络
PINN 的主要成分当然是神经网络本身。 对于这篇文章,我们选择了一个基本的神经网络架构,该架构由一堆具有标准 tanh 激活函数的线性层组成。 由于我们有一个自变量,即时间 t,NN 应该将一个特征作为输入并返回一个输出,该输出表示给定当前模型参数的最佳 DE 解决方案猜测。 下面是该架构的 PyTorch 实现,其中神经元和隐藏层的数量保留为输入(超)参数。
from torch import nn
class NNApproximator(nn.Module):
"""Simple neural network accepting one feature as input and returning a single output
In the context of PINNs, the neural network is used as universal function approximator
to approximate the solution of the differential equation
"""
def __init__(self, num_hidden: int, dim_hidden: int, act=nn.Tanh()):
super().__init__()
self.layer_in = nn.Linear(1, dim_hidden)
self.layer_out = nn.Linear(dim_hidden, 1)
num_middle = num_hidden - 1
self.middle_layers = nn.ModuleList(
[nn.Linear(dim_hidden, dim_hidden) for _ in range(num_middle)]
)
self.act = act
def forward(self, x):
out = self.act(self.layer_in(x))
for layer in self.middle_layers:
out = self.act(layer(out))
return self.layer_out(out)PINN 是一个非常活跃的研究领域,并且已经设计出更复杂且通常针对问题定制的神经网络架构。 对这些架构的讨论超出了本介绍性博客的范围。
3、构建损失函数
现在我们定义了我们的通用函数逼近器,让我们构建损失函数。 如前所述,这由 DE 残差项和边界条件项组成,DE 残差项充当物理知识正则化,边界条件项驱动网络收敛到无限可能的解中的所需解。
首先,需要选择一组托管点。 由于我们正在解决一个非常简单的问题,我们可以在时域中选择一个均匀间隔的网格: t = torch.linspace(0, 1, steps=10, requires_grad=True) 。 对于更复杂的问题,托管点的选择非常重要,需要更加谨慎的选择。
DE 残差损失需要评估 NN 输出相对于其输入的导数:
import torch
def f(nn: NNApproximator, x: torch.Tensor) -> torch.Tensor:
"""Compute the value of the approximate solution from the NN model"""
return nn(x)
def df(nn: NNApproximator, x: torch.Tensor = None, order: int = 1) -> torch.Tensor:
"""Compute neural network derivative with respect to the input feature(s) using PyTorch autograd engine"""
df_value = f(nn, x)
for _ in range(order):
df_value = torch.autograd.grad(
df_value,
x,
grad_outputs=torch.ones_like(x),
create_graph=True,
retain_graph=True,
)[0]
return df_value上面的代码使用 PyTorch autograd 引擎自动计算关于时间 t 的导数。 尽管所选微分方程只需要一阶导数,但代码还表明,通过重复应用 torch.autograd.grad 函数,可以计算任意阶导数。 这相当于执行多次向后传递。 使用上面的函数,MSE 损失很容易计算为每个托管点的 DE 贡献和边界贡献的总和:
T0 = 0.0 # initial time
F0 = 1.0 # boundary condition value
# DE contribution
interior_loss = df(nn, x) - R * x * (1 - x)
# boundary contribution
boundary = torch.Tensor([T0])
boundary.requires_grad = True
boundary_loss = f(nn, boundary) - F0
final_loss = \
# average over all the colocation points
interior_loss.pow(2).mean() + \
# boundary contribution is just a single value
boundary_loss ** 2上面定义的自定义损失确保在训练过程之后,NN 将逼近所选微分方程的解。 现在,让我们看看它的实际效果。
4、用 PINN 求解微分方程
由于上面定义的损失仅使用可微函数构建,我们可以使用向后传递(PyTorch 中的一行代码)直接计算模型参数的梯度:`final_loss.backward()`。 优化过程是标准的 PyTorch 代码,为简洁起见此处省略。
让我们看看一些结果。 我们使用随机梯度下降优化器,学习率为 0.1,只有 10 个训练点。 鉴于所选微分方程的简单性,20000 个时期足以几乎完美地再现最大增长率设置为 R = 1 的分析结果:
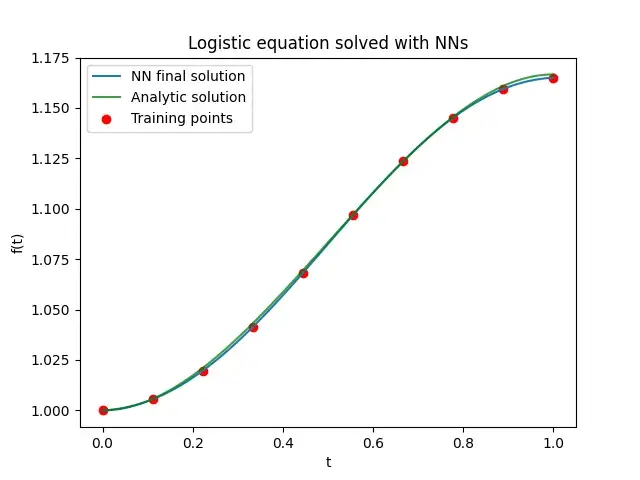
在上图中,解决方案是在 100 个均匀分布的点上进行评估的,我还显示了 10 个训练点以供比较。 损失情况如下所示:
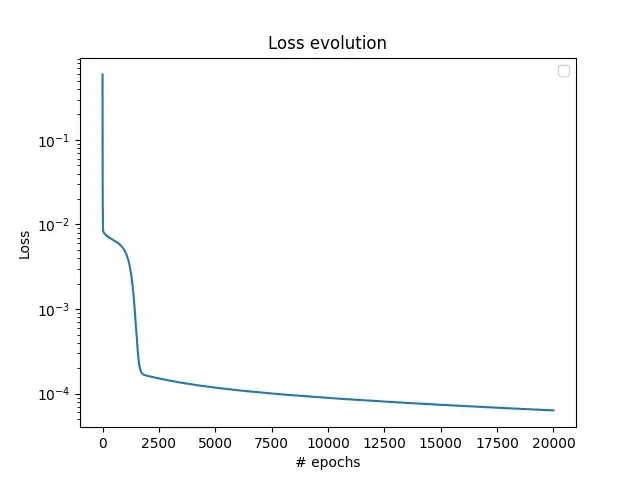
请注意,使用 Adam 优化器可以用更少的 epoch 获得更好的结果。 然而,优化结果超出了本文的范围,本文仅旨在解释 PINN 的工作原理。
在这里,我们解决了一个非常简单的一维问题。 对于更复杂的方程,收敛并不那么容易实现。 特别是对于时间相关的问题,在过去几年中已经设计出许多有用的技巧,例如使用不同的神经网络将解决方案域分解为不同的部分,对不同的损失贡献进行智能加权以避免收敛到平凡的解决方案等等。 我将在以后的帖子中介绍其中一些技巧,敬请期待。
原文链接:Introduction to Physics-informed Neural Networks
BimAnt翻译整理,转载请标明出处





