AI 3D建模工具: Tripo 3D | Meshy AI
训练自己的 AI 模型比你想象的要容易得多。
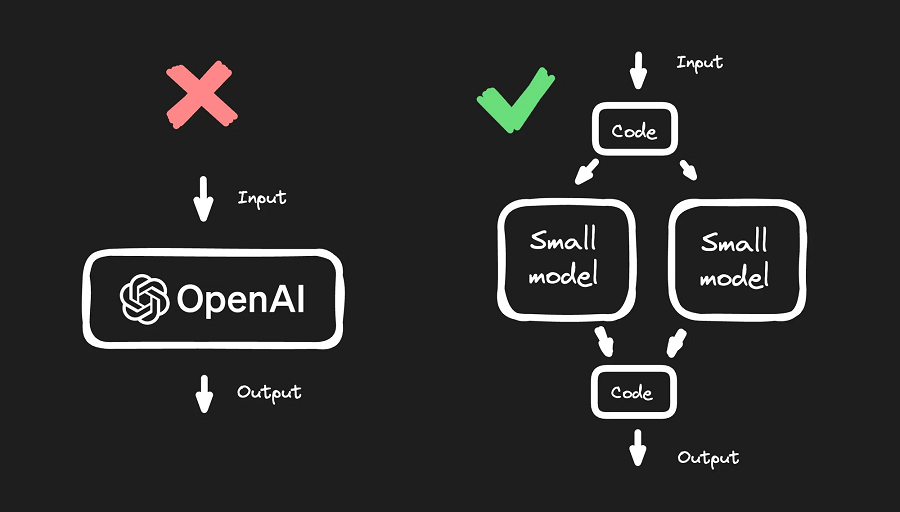
我将向你展示如何仅使用基本的开发技能来做到这一点,对我们来说,这种方式比使用 OpenAI 提供的现成大型模型更快、更便宜、效果更好。
但首先,为什么不直接使用 LLM?
1、为什么不直接使用 LLM?
根据我们的经验,我们尝试将 LLM 应用于我们的问题,例如 OpenAI 的 GPT-3 或 GPT-4,但结果对我们的用例非常令人失望。它非常慢、非常昂贵、非常不可预测,并且很难定制。

因此,我们改为训练自己的模型。
这并不像我们预期的那么具有挑战性,而且由于我们的模型很小且很专业,因此结果就是它们的速度快了 1,000 倍以上,而且成本更低。
它们不仅更好地满足了我们的用例,而且更可预测、更可靠,当然,可定制性也更高。

那么,让我们来分析一下如何像我们一样训练自己的专用 AI 模型。
2、分解问题
首先,你需要将问题分解成更小的部分。在我们的案例中,我们希望采用任何 Figma 设计并将其自动转换为高质量代码。

为了解决这个问题,我们首先探索了各种选择。
3、首先尝试一个已建立的模型
我建议你首先尝试的是……基本上是我刚才建议不要做的事情,即看看你是否可以使用现有模型解决问题。
如果你发现这种方法有效,它可以使你更快地将产品推向市场并在真实用户身上进行测试,同时了解竞争对手复制这种方法的难易程度。
如果你发现这种方法对你很有效,但我提到的一些缺点(例如成本、速度或定制)会成为问题,你可以一边训练自己的模型,一边不断改进它,直到它的表现优于你首先尝试的 LLM。
但在很多情况下,你可能会发现这些流行的通用模型根本不适合你的用例。

在我们的案例中,我们尝试将 Figma 设计作为原始 JSON 数据输入,并要求另一端输出 React 组件,但坦率地说,效果非常糟糕。
我们还尝试了 GPT-4V,截取 Figma 设计的屏幕截图,并从另一端输出代码,同样,结果非常难以预测,而且往往非常糟糕。
因此,如果你不能直接拿起并使用现成的模型,那么现在我们需要探索训练我们自己的模型会是什么样子。
4、训练自己的模型
很多人直觉地认为他们应该只制作一个巨大的模型,其中输入是 Figma 设计,输出是完整的代码。我们只需应用数百万个 Figma 设计和数百万个代码片段,就可以了;AI 模型将解决我们所有的问题!
现实比这要微妙得多。
首先,训练大型模型非常昂贵。模型越大,需要的数据越多,训练和运行的成本就越高。
大型模型也需要大量时间来训练,因此随着你进行迭代和改进,你的迭代周期可能需要几天才能等待训练完成。
即使你可以负担得起那么多的时间费用,并且拥有制作这些大型复杂自定义模型所需的专业知识,你也可能无法生成所需的所有数据。

如果你在开放的网络上找不到这些数据,那么你真的会付钱给数千名开发人员,让他们手动将数百万个 Figma 设计编码到 React 或任何其他框架中吗?更不用说所有不同的样式选项,例如 tailwind、emotion 和 CSS 模块?
这只是一个难以解决的复杂问题。因此,一个为我们完成所有事情的超级模型可能不是正确的方法。至少现在不是。
5、尝试在没有AI的情况下解决你的问题
当你遇到这样的问题时,我强烈建议你尝试将钟摆摆到另一端,尽可能地在不使用AI的情况下解决尽可能多的问题。
这迫使你将问题分解成许多离散的部分,你可以为这些部分编写正常的传统代码,看看你能解决到什么程度。
根据我的经验,无论你认为你能解决到什么程度,只要经过一些迭代和创造性,你就能取得比你想象的更远的成就。
当我们尝试将这个问题分解成简单的代码时,我们意识到我们必须解决几个不同的具体问题。

我们发现,五个问题中至少有两个问题可以用代码轻松解决:将样式应用于 Figma 和 CSS/原生样式,以及从预定义的布局层次结构生成基本代码。
我们遇到的挑战是在其他三个领域:识别图像、构建布局层次结构和自定义最终代码输出。
因此,让我们迈出识别图像的第一步,并介绍如何训练我们自己的专用模型来解决这个用例。
6、训练专用模型
如今,训练自己的模型实际上只需要两个关键要素。首先,你需要确定适合你的用例的模型类型;其次,你需要生成大量数据示例。

在我们的案例中,我们能够找到人们训练的一种非常常见的模型类型,即对象检测模型,它可以拍摄图像并返回一些在其中包含特定类型对象的边界框。

因此我们问自己,我们是否可以在一个稍微新颖的用例上进行训练,即采用 Figma 设计,它在整个过程中使用了数百个矢量,但对于我们的网站或移动应用程序,其中某些组应该被压缩成一张图像,它能否识别这些图像点的位置,以便我们可以将它们压缩成一个并相应地生成代码。

因此,这引出了第二步。我们需要生成大量示例数据,并查看相应地训练此模型是否适合我们的用例。
7、生成数据集
因此,我们想,等一下,我们能从某个地方,某个公开且免费的地方获取这些数据吗?
就像 OpenAI 等工具所做的那样,它们在网络和 GitHub 上抓取大量公开数据,并将其用作训练的基础。
最终,我们意识到,是的!
我们编写了一个简单的爬虫,它使用无头浏览器将网站拉入其中,然后评估页面上的一些 JavaScript 以识别图像的位置及其边界框,这能够非常快速地为我们生成大量训练数据。

现在,请记住一件至关重要的事情:模型的质量完全取决于数据的质量。
让我大声说出来:
模型的质量完全取决于数据的质量
不要犯这样的错误:在不完美的数据上花费昂贵的训练时间,最终只会给你(在最好的情况下)一个不完美的模型,其准确性仅与输入的数据一样。
因此,在我们生成的数百个示例中,我们手动检查并使用工程师来验证每个边界框每次都是正确的,并使用可视化工具随时纠正不正确的情况。
根据我的经验,这可能成为机器学习中最复杂的领域之一。即构建自己的工具来生成、QA 和修复数据,以确保数据集尽可能完美,从而使你的模型具有最高质量的信息。
现在,就这个对象检测模型而言,幸运的是,我们使用了 Google 的 Vertex AI,它内置了该工具。
事实上,我们通过 Vertex AI 上传了所有数据并训练模型,甚至根本不需要在代码中执行这些操作。
8、开始训练
你可以使用许多工具来训练自己的模型,从托管云服务到大量优秀的开源库。我们之所以选择 Vertex AI,是因为它让我们能够非常轻松地选择模型类型、上传数据、训练模型并部署模型。
因此,我将详细介绍我们如何使用 Vertex AI 做到这一点,但实际上,相同的步骤可以应用于任何类型的训练。
要开始训练,首先我们需要将数据集上传到 Google Cloud。
你需要做的就是转到 Google Cloud 控制台的 Vertex AI 部分并上传我们的数据集:

你可以通过从计算机中选择文件来手动完成此操作,然后使用其可视化工具来概述对我们重要的区域,这是一个巨大的帮助,我们不必自己构建。

或者在我们的例子中,因为我们以编程方式生成了所有数据,所以我们可以以这种格式将其上传到 Google Cloud,你可以在其中提供图像的路径,然后列出要识别的对象的边界框。
{
"imageGcsUri": "gs://ml-image-data-test/test1/Visual%20Editor%20%7C%20Builder.io.png",
"boundingBoxAnnotations": [
{
"displayName": "image",
"yMin": 0.0083,
"xMin": 0.01465,
"yMax": 0.03955,
"xMax": 0.12695
},
{
"displayName": "image",
"yMin": 0.2998,
"xMin": 0.01953,
"yMax": 0.3918,
"xMax": 0.32129
},
...
]
}然后回到 Google Cloud,你可以使用相同的可视化工具根据需要手动验证或调整数据。
然后,一旦你的数据集成型,我们所需要做的就是训练我们的模型。我使用所有默认设置,并使用最少的训练时间。

请注意,这是需要花费一些钱的一件事(除了最后还要托管你的模型)。
在这种情况下,所需的最低训练量大约需要 60 美元。这比购买自己的 GPU 并让它一次运行数小时或数天要便宜得多。
但如果你不想付钱给云提供商,在自己的机器上进行训练仍然是一种选择。有很多不错的 Python 库并不复杂,你也可以这样做。
一旦你点击“开始训练”,我们的训练大约需要三个小时。
9、部署和测试你的模型
训练完成后,你可以找到你的训练结果,只需单击按钮即可部署你的模型。

部署可能需要几分钟,然后你将拥有一个 API 端点,你可以向其发送图像并返回一组带有置信度的边界框。
我们还可以直接在仪表板中使用 UI 来测试我们生成的模型。
因此,现在要在 Figma 中测试它,我将截取此 Figma 文件的一部分的屏幕截图,因为我很懒,我可以直接将其上传到 UI 进行测试。

就这样。我们可以看到它做得不错,但这里也有一些错误。
10、找到正确的置信度阈值
但有一点很重要:此 UI 会显示所有可能的图像,无论置信度如何。当我将光标悬停在每个置信度高的区域上时,这些区域都是正确的,而奇怪的区域则是置信度非常低的区域。

这甚至为你提供了一个 API,可以在其中指定返回的结果应高于某个置信度阈值。通过查看这个,我认为我们需要的阈值至少为 0.2。
11、把所有东西放在一起
就是这样。我们训练的这个专门模型将比 LLM 运行得更快、更便宜。
当我们分解问题时,我们发现对于图像识别,专门的模型是一个更好的解决方案。为了类似地构建布局层次结构,我们也为此制作了自己的专门模型。

对于样式和基本代码生成,纯代码是完美的解决方案。别忘了:纯代码始终是速度最快、成本最低、最容易测试、最容易调试、最可预测的,并且是大多数用例的最佳选择 - 因此,只要你可以使用它,就绝对可以这样做。
最后,为了让人们自定义他们的代码名称,最好使用不同的库,我们已经支持我们使用 LLM 作为最后一步。
现在我们能够采用设计和大型基线代码,LLM 非常擅长采用基本代码并对代码进行调整,为您提供带有小改动的新代码。
因此,尽管我对 LLM 有诸多抱怨,而且我仍然讨厌该流程中该步骤的速度和成本。它曾经是并且现在仍然是该特定部分的最佳解决方案。
现在,当我们将所有这些整合在一起并启动 Builder.io Figma 插件时,我需要做的就是单击生成代码,我们将快速运行这些专门的模型,并将其启动到 Builder.io 可视化编辑器,我们将该设计转换为响应式和像素完美的代码。

幸运的是,因为我们创建了整个工具链,所以我们每天都可以根据客户反馈对所有这些进行改进。
12、结束语
我始终建议针对您的用例测试语言模型 (LLM),尤其是出于探索目的。
但是,如果它不能满足你的需求,请考虑尽可能多地编写普通的旧式代码。
遇到瓶颈时,请探索专门的模型。你可以通过生成自己的数据集和使用 Vertex AI 等产品来训练这些模型。
这种方法将帮助你创建一个强大的工具链,以令人兴奋且可能前所未有的工程壮举打动你的用户。
我迫不及待地想看看你去构建什么!
原文链接:Training Your Own AI Model Is Not As Hard As You (Probably) Think
BimAnt翻译整理,转载请标明出处





