
NSDT工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器 - REVIT导出3D模型插件 - 3D模型语义搜索引擎 - AI模型在线查看 - Three.js虚拟轴心开发包 - 3D模型在线减面 - STL模型在线切割 - 3D道路快速建模
如果你曾经参与过 PyTorch 模型的微调,可能会遇到 PyTorch 的内置变换函数,这使得数据增强变得轻而易举。 即使你之前没有使用过这些功能,也不必担心。 在本文中,我们将深入研究 PyTorch 变换换函数的世界。 我们将探索你可以使用的各种转换以及它们如何帮助训练强大的模型。
本文是PyTorch微调终极指南的第三部分,前两部分点击这里查看:一、二。
1、PyTorch 转换函数到底是什么?
转换函数是 PyTorch 库的一部分,可以轻松地对输入数据使用不同的数据增强技术。 这些功能允许你同时应用一项或多项更改。
可以在这里找到 PyTorch 官方文档。
请注意 - PyTorch 建议使用 torchvision.transforms.v2 变换而不是 torchvision.transforms 中的变换。
下面是一个读取图像并使用 PyTorch Transforms 更改图像大小的示例脚本:
from torchvision.transforms import v2
from PIL import Image
import matplotlib.pyplot as plt
# Load the image
image = Image.open('your_image.jpg') # Replace 'your_image.jpg' with the path to your image file
# Define a transformation
transform = v2.Compose([
v2.Resize((256, 256)), # Resize the image to 256x256 pixels
v2.ToTensor(), # Convert the image to a PyTorch tensor
])
# Apply the transformation to the image
transformed_image = transform(image)在上面的示例中,我们可以看到对输入图像应用了两种变换。 首先,它被调整大小,其次,它被转换成张量。 这两种改变结合在一起,我们可以用其他类型的转换做同样的事情,依次应用它们。
我们可以将不同的变换函数分为四大类:
- 几何变换:geometric transforms
- 光度变换:photometric transforms
- 类型转换:将输入数据从一种类型转换为另一种类型
- 变化组合:将一个或多个变换组合在一起
- 其他变换:不知道该把它归为哪一类
我们将详细研究每个类别。
2、几何变换
顾名思义,几何变换是在不修改像素值的情况下改变图像几何形状的操作。 虽然像素值本身在这些变换过程中基本保持不变,但它们在图像中的位置发生了变化。
为什么需要这些几何变换?
几何变换能够以各种形式表示数据,提供对数据的不同视角并增强深度学习模型的稳健性。 在输入数据中加入几何变换可以增强模型对几何变化的适应能力。
以下是 PyTorch 中可用的各种几何变换:
2.1 调整大小
顾名思义,resize有助于将图像大小调整为给定大小。 我们可以定义所需的大小,或者如果我们希望将随机调整大小应用于输入图像以获得更好的调整大小方差,则可以定义一个范围。
# To resize input image for specified size
img = v2.Resize((300, 300))(orig_img)
# To resize inpur randomly given two range; ps - here max_range > min_range
max_range, min_range = 400, 300
img = v2.RandomResize(max_range,min_range)(orig_img)
2.2 旋转
这有助于我们为输入图像应用不同的旋转(rotate)给定角度。 在通过将模型暴露于旋转图像的训练过程中,可以要求它保持方向不变。 这意味着模型应该识别对象或特征,无论其方向如何。 你可以应用不同的旋转变换。
# To apply rotation on input image with specified angle
angle = 140
img = v2.functional.rotate(orig_img, angle)
# To rotate image randomly given two range; ps - here max_range > min_range
max_range, min_range = 180, 0
img = v2.RandomRotation(degrees=(min_range, max_range))(orig_img)
您可以在设定的旋转角度或范围(最小和最大)上随机旋转图像。 随机旋转主要用于在训练模型时为数据添加更多多样性。
2.3 翻转
翻转(flip)与旋转非常相似,但它不是将图像旋转特定角度,而是水平或垂直旋转图像,即绕 x 轴或 y 轴旋转 180 度。
# to apply left-to-right flip
img = v2.functional.horizontal_flip(orig_img)
# to apply top-to-bottom flip
img = v2.functional.vertical_flip(orig_img)
# to apply these flips randomly on input image
# Here p is probabality, if p=1 then applies flip on all the input image during training
img = v2.RandomHorizontalFlip(p=1)(orig_img)
img = v2.RandomVerticalFlip(p=1)(orig_img)
当你随机翻转图像时,可以使用 p 来表示你希望它发生的频率。 如果 p 为 0.5(例如 50%),则意味着批次中的一半图像会被翻转。 我们在训练模型时主要使用随机翻转来使我们的数据更加多样化。
以下是旋转和翻转可能有益的一些实例:
- 人脸识别:训练人脸识别模型时,水平翻转图像可以帮助模型识别人脸,无论向左还是向右。
- 行人检测:自动驾驶车辆需要检测不同方向的行人,例如步行、背向或倾斜的行人。 旋转增强有助于模型适应这些变化。
- 文本方向检测:分析文档时,文本的方向可能会有所不同。 旋转增强有助于检测和纠正方向,使其对于 OCR 任务非常有用。
- 还有更多..
2.4 填充
填充(padding)在图像角周围添加额外的像素值以增加图像尺寸。 这样做可以确保图像具有一致的尺寸或纵横比,可以确保不会丢失信息或为特定模型架构准备图像。
# If a single int is provided this is used to pad all borders
padd_pixel = 100
img = v2.Pad(padding=padd_pixel)(orig_img)
# If sequence of length 2 is provided this is the padding on left/right and top/bottom respectively.
left_top, right_bottom = 100, 150
img = v2.Pad(padding=(left_top, right_bottom))(orig_img)
# If a sequence of length 4 is provided this is the padding for the left, top, right and bottom borders respectively.
left, right, top, bottom = 100, 100, 150, 150
img = v2.Pad(padding=(left, top, right, bottom))(orig_img)
2.5 裁剪
这些 PyTorch 变换函数可帮助你将图像裁剪(crop)为所需大小或随机大小。
# Crop function expect exact co-ordinate x(left),y(top),w,h of crop region
top, left, height, width = 200, 50, 300, 300
img = v2.functional.crop(orig_img, top, left, height, width)
# We can also apply crop of specified size randomly on input image
height, width = 300, 300
img = v2.RandomCrop((height, width))(orig_img)
# We can also cropb the input at the centre of specified crop size
height, width = 300, 300
img = v2.CenterCrop((height, width))(orig_img)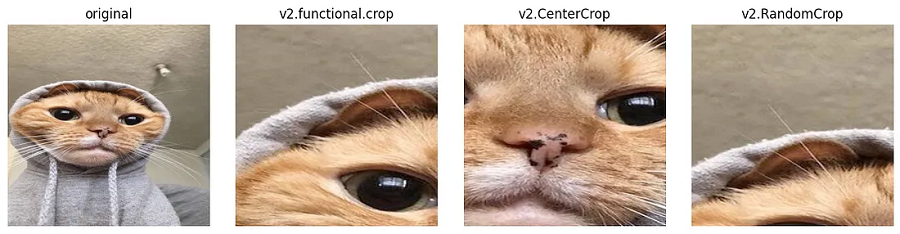
2.6 调整裁剪大小
这是另一种类型的裁剪变换,但它以独特的方式运作。 它首先随机选择图像的一部分,然后将所选区域的大小调整为指定的大小。
# randomly selects the region to crop then applies specified size to resize the crop
crop_size = (150, 150)
img = v2.RandomResizedCrop(size=crop_size)(orig_img)
这是非常有用的增强,广泛用于训练 Inception 网络。
以下是添加裁剪增强功能可能有益的一些实例:
- 在物体检测任务中:裁剪可以创建不同物体尺度和位置的训练样本,帮助模型学习检测各种上下文中的物体。
- 在场景理解任务中:随机作物增强可以引入场景组成的可变性,帮助模型识别不同的环境元素。
- 在对细粒度类别进行分类时,随机裁剪会突出显示特定的对象细节,使模型更能够区分相似的类别,例如不同的鸟类物种。
- 还有更多..
2.7 透视变换
通过将透视(perspective)转换应用于 2D 图像,你可以创建模拟不同视角和视点(在 3D 空间中)的新训练样本。
# apply a random perspective transform on an input image
img = v2.RandomPerspective(distortion_scale=0.5, p=1.0)(orig_img)
现在,让我们看看传递给 RandomPerspective 的不同参数:
Distortion_scale:此参数控制图像上透视变换的程度。 扭曲比例为 0.2 表示图像可能会经历最多其宽度和高度 20% 的随机透视偏移。 这种转变改变了图像的视角,导致外观倾斜。p:参数p设置为1.0,表示应用透视变换的概率为100%。 它使用代表概率得分的 p 值来确定是否应对图像应用变换。 当 p 等于 0 时,不应用变换。
以下是一些示例,其中将随机透视变换添加到增强中可能是有益的:
- 透视变换可以模拟镜头畸变或模拟物体在鱼眼相机中出现的方式,从而增强模型处理现实世界相机畸变的能力。
- 对于面部表情识别,透视变换可以引入面部图像的变化,模拟不同的头部角度和视角。
- 在手写识别任务中,透视变换可用于通过模拟从不同角度查看时手写文本的显示方式来增强训练数据。
- 还有更多..
2.8 仿射变换
这允许你对图像应用各种仿射(affine)变换,例如旋转、平移、缩放和剪切。 这与仅旋转不同,因为这考虑了其他参数而不仅仅是旋转角度。
关于这种特定增强的最好的部分是,你可以一起引入图像平移、缩放和旋转。 您必须格外小心传递给 Affine 函数的参数值。
# apply random affine transform on the input image
img = v2.RandomAffine(degrees=(30, 70), translate=(0.0, 0.1), scale=(0.5, 0.7))(orig_img)
现在,让我们看看传递给 RandomAffine 的不同参数:
旋转:
degrees=(30,70):这表示图像旋转的允许范围,其中 30 是最小度数,70 是最大度数。 旋转_度从范围 (30, 70) 中随机选择并应用于图像。- 如果
degree=0设置为 0,则禁用图像旋转并且不应用旋转。
平移:
translate = (0.0,0.1):此参数控制随机图像平移或移动的程度。 这些值表示为图像宽度和高度的分数。 在这种情况下,图像在水平和垂直方向上可能会经历最多其宽度或高度 10% 的随机移动。- 默认情况下,图像没有应用任何平移。
缩放:
scale=(0.5, 0.7):此参数定义随机图像缩放的允许范围,使每个图像能够随机调整为 0.5 到 0.7 之间的系数。 这相当于将图像尺寸调整为原始尺寸的 50% 到 70% 之间。- 默认情况下,它保持原始图像比例。
由于 RandomRotation 已经为你提供了旋转功能,因此可以使用 RandomAffine 实现图像缩放和平移变换。
图像平移和缩放变换可能有益的实例:
- 在目标检测任务中,图像平移和缩放可以创建具有不同位置和大小的目标的多样化训练样本,帮助模型学习检测不同上下文和尺度下的目标。
- 在基于内容的图像检索中,翻译和缩放图像可以创建用于检索的多样化查询图像,从而使模型能够在大型图像数据库中找到相关匹配。
- 对于手写识别模型,图像平移和缩放可以模拟手写文本的位置和大小的变化,帮助模型更好地泛化。
- 还有更多..
2.9 弹性变换
这就像图像变形一样,弹性(elastic)变换产生非常有趣的水状透视效果。
弹性变换模拟图像变形,如拉伸和扭曲,增强模型对现实世界中此类变化的适应能力。 它们有多种应用,但应明智地选择 alpha 值以避免过度使用。
# apply elastic transform on the input image
img = v2.ElasticTransform(alpha=250)(orig_img)
3、光度变换
光度变换(photometric transforms)通过修改像素值同时保留图像几何形状来改变图像的光度属性。 它包括广泛的变换,如照明、颜色、图像纹理等。
为什么需要这些光度转换?
为了使我们的视觉模型更加稳健和通用,我们可以应用光度变换。 在图像上应用这些变换后,我们实现了更广泛的颜色和照明变化,这使得模型在现实场景中表现更好,在现实场景中,图像可能并不总是符合理想的照明和颜色标准。
以下是 PyTorch 中可用的各种光度转换:
3.1 ColorJitter
该变换函数应用随机光度变换,即基于定义范围的亮度、色调、饱和度和对比度。 首先,让我们快速浏览一下代码,然后,我们将深入探讨每个转换的彻底解释。
# apply ColorJitter transformation to the input image
img = v2.ColorJitter(brightness=0.4,
contrast=0.5,
saturation=0.4,
hue=0.3)(org_img)
这些参数中的每一个(即亮度、色调、饱和度和对比度)都可以接受单个浮点数(例如 0.4)或指定范围的元组(例如(0.2,0.6))形式的值。 单个浮点指定固定值,而元组定义最小值和最大值。
以下是有关 ColorJitter 需要牢记的一些要点:
- 默认值:亮度、色调、饱和度和对比度的默认值均设置为 0。这意味着,如果未提供特定值,则不会应用这些颜色调整,并且图像在这些属性方面将保持不变 。
- 转换顺序:设置所有参数后,将按特定顺序应用转换。 首先,进行亮度更改,然后更改对比度,然后更改饱和度,最后将色调更改应用于输入图像。 此顺序可确保颜色转换的顺序一致。
3.2 亮度变换
亮度(brightness)改变图像的整体光线。 可以通过缩放所有像素值来完成。 增加亮度使图像变亮,降低亮度使图像变暗。 让我们看一下代码:
# apply ColorJitter to alter image brightness
# to only apply brightness changes you must not sepcify other parameters # or set others to zero
img = v2.ColorJitter(brightness=(0.1, 1))(orig_img)
亮度应该是非负数,它可以是单个浮点值或浮点值的元组。 亮度值应介于 (0, inf) 之间。
下面关于亮度背景下的固定值和元组的解释至关重要,并且同样适用于饱和度和对比度。
如果亮度是单个固定浮点值,即 brightness=0.4:
- ColorJitter 在内部创建一个范围,并从该范围中随机均匀地选择亮度因子。
- 例如,如果
v2.ColorJitter(brightness=0.4)(orig_img)那么这就是范围的计算方式

- 因此,在这种情况下,brightness_factor 是从每个图像的范围 [0.6, 1.4] 中随机选择的,并应用于输入图像。
如果亮度是浮点值的元组,即 brightness=(0.1, 1):
- 如果传入参数是元组,那么index0被认为是最小值,而index1被认为是最大值。
- 最大值应大于最小值, 即
max > min。 Brightness_factor是从给定的(min,max)范围中统一选择的。 在本例中 为(0.1, 1)。
在模型训练期间改变图像亮度可能有益的情况:
- 天气监测可能涉及分析由于云层覆盖、太阳角度或降水而具有不同亮度水平的卫星或雷达图像。 亮度变换有助于模型适应这些变化。
- 在质量控制和缺陷检测中,调整图像亮度可以模拟工厂车间的照明变化,帮助模型识别不同照明条件下的缺陷。
- 监控摄像头经常在不同的照明条件下捕捉镜头。 图像亮度变换可以帮助训练模型来检测不同照明水平下的物体和个体。
3.3 对比度变换
对比度(contrast)是图像最暗部分和最亮部分之间的差异。 调整对比度会改变像素值的分布。 增加对比度会使暗区更暗,亮区更亮,从而增强整体视觉差异。
# alter only image contrast
img = v2.ColorJitter(contrast=(0, 10))(orig_img)
对比度应该是非负数,它可以是单个浮点值或浮点值的元组。 对比度值应介于 (0, inf) 之间。
请注意 - 请再次月度上面的亮度部分,以更好地理解对比度因子计算。
我们提供 contrast=0.4单个值或元组 contrast=(0,10),将应用于图像的 contrast_factor从范围中选择,其方式与计算 brightness_factor相同。
在训练过程中改变图像对比度并将其添加为增强效果可能是有益的:
- 在遥感和卫星图像分析中,图像对比度变换可以揭示地球表面的重要特征,例如土地覆盖类型、水体和城市地区。
- 对于艺术风格识别,调整图像对比度可以呈现出独特的艺术特征和特征,使模型能够识别不同的艺术风格。
- 在水下成像中,对比度变换可以提高海洋生物、珊瑚礁和水下地形的可见度,提高物种识别和环境监测的准确性
3.4 饱和度变换
饱和度(saturation)调整控制图像中颜色的强度。 增加饱和度使颜色更加鲜艳,而减少饱和度则使颜色更加柔和。 无论颜色鲜艳度如何,这都可以帮助模型更加稳健并表现良好。
# alter just the image saturation
img = v2.ColorJitter(saturation=(0.1, 1))(orig_img)
饱和度应该是非负数,它可以是单个浮点值或浮点值的元组。 饱和度值应介于 (0, inf) 之间。
请注意 - 请访问上面的亮度部分,以更好地了解饱和度因子计算。
我们要么提供 saturation = 0.4 的单个值,要么提供元组 saturation = (0.1,1),将应用于图像的饱和度因子的选择方式与亮度因子的计算方式相同。
图像饱和度增强可能有益的实例:
- 在农业和植物科学中,图像饱和度变换可以通过增强植物图像的颜色差异来帮助模型识别健康和受胁迫的植被。
- 对于农业害虫检测,图像的颜色和照明可能会根据天气和一天中的时间而变化。 饱和度增强确保模型可以识别不同条件下的害虫。
3.5 色调变换
色调(hue)调整沿着色轮移动图像中的颜色,而不改变图像亮度或饱和度。 色调可用于改变图像的整体色调。 这对于增强等各种问题都很有用。
# Create a color jitter transform to apply only hue changes
# Here, setting the hue range from 0.1 (minimum) to 0.4 (maximum)
img = v2.ColorJitter(hue=(0.1, 0.4))(orig_img)
改变图像色调属性需要考虑的几个重要要点:
- 我们可以将色调传递给单个值或元组。 但色调值应在 (-0.5, 0.5) 之间。
- 如果提供单个值,即
hue =0.2,则从范围 (-0.2, 0.2) 中统一选择色调因子 - 如果传入元组,则索引 0 被视为最小色调,索引 1 被视为最大色调。 这里色调min≥-0.5且max≤0.5。 色调因子是从范围(最小值,最大值)中统一选择的。
- 要改变图像色调,输入图像的像素值应为非负数才能转换为 HSV 空间
使用色调变换可能有益的情况:
- 在面部识别等任务中,由于不同的光照条件,人们可能会出现不同的肤色。 使用色调调整图像进行训练使模型能够识别各种肤色下的个体。
- 对于花卉种类识别,图像色调变换可以强调花卉颜色图案的变化,帮助模型区分不同种类。
- 对于水果成熟度检测,图像色调变换可以模拟水果成熟时颜色的变化,使模型能够准确识别成熟和未成熟的水果。
3.6 清晰度变换
以给定的概率调整图像的清晰度(sharpness)。
# adjust the image sharpness
img = v2.RandomAdjustSharpness(sharpness_factor=10, p=0.8)(orig_img)
这里,p是概率,默认值为0.5, sharpness_factor可以是任何非负数。
3.7 高斯模糊变换
高斯模糊(Gaussian Blur)是平滑操作。 它通过对局部邻域内的像素值进行平均来引入受控的平滑量来模糊图像。 这有助于减少训练数据中的噪声和细粒度细节,从而使模型对现实数据中的噪声不太敏感。
# Apply blur on input image with GaussianBlur
img = v2.GaussianBlur(kernel_size=(11, 21), sigma=(5, 50)))(orig_img)
kernel_size 和 sigma 这两个因素共同决定图像中平滑或模糊的程度。 通过调整这些参数,你可以微调高斯模糊效果,以达到图像所需的平滑程度。
sigma:
sigma控制用于模糊的高斯分布的标准偏差。 它确定应用于图像的平滑或模糊量。sigma可以是单个固定值或元组(min_sigma、max_sigma)。- 如果
sigma=0.5为单个值,则sigma是固定的,如果是元组(min_sigma, max_sigma)则从范围(min_sigma, max_sigma)中均匀随机选择sigma。 sigma值越大,模糊范围越广、越强烈。
kernel_size:
kernel_size确定用于执行高斯模糊操作的卷积核的大小。kernel_size应该是一个正数。kernel_size定义内核的宽度和高度。- 较大的
kernel_size意味着模糊时会考虑更广泛的图像区域,从而产生更平滑、更明显的模糊效果。 kernel_size定义的高斯内核的大小控制模糊在图像区域上的传播方式。
图像模糊增强可能有益的实例:
- 在交通监控中,图像模糊变换可以模拟移动车辆的运动模糊。 这有助于模型估计车速并监控交通流量。
- 在自动驾驶汽车等应用中,模糊可以模拟恶劣的天气条件,增强模型在不利情况下导航和做出决策的能力。
3.8 曝光变换
Solarize 是一种将图像中的像素值反转到超过特定阈值的操作。 换句话说,它翻转亮度值,使暗区域变亮,亮区域变暗。 此效果适用于高于指定阈值的像素值。
曝光图像的结果是令人震惊且常常超现实的外观。 它可以创造视觉上有趣和高对比度的效果,黑暗区域呈现出发光或“日光化”的质量。 曝光可用于艺术和创意图像处理。
# Solarize the input image
img = v2.RandomSolarize(threshold=5.0, Solarize)(orig_img)
阈值是像素值,因此如果阈值=5.0,则意味着所有超过5的像素值都被反转。
4、数据类型转换
类型转换与前两者有很大不同; 它们更多地是作为效用转换而不是增强。 通过这些转换,我们可以在 PIL 图像和张量之间切换或根据需要更改输入数据类型。
请注意 - 在应用转换变换之前,请参阅此文档 ,因为其中一些转换可能会将数值从unit8缩放到float,反之亦然。
# Sample PIL image
pil_image = Image.open("sample_image.jpg")以下是 PyTorch 中可用的各种转换:
- PIL 图像到张量 — 这会将 PIL 图像转换为相同数据类型的张量,而不影响像素值。 我们看一下代码:
# Convert PIL image to a PyTorch tensor
tensor_image = transforms.PILToTensor()(pil_image)- 张量到 PIL 图像 — 这会将输入 and.array 或张量转换为 PIL 图像。 让我们看一下代码:
# Convert the tensor back to a PIL image
tensor_to_pil = transforms.ToPILImage()(tensor_image)还有更多,请参阅文档了解更多详细信息。
5、合成变换
合成(composition)变换就像将不同的变换函数组合在一起并将它们应用到输入图像上。 当你在图像上使用此转换管道时,它会遵循你为这些转换函数设置的顺序,一个接一个地应用它们。 创建脚本来加载数据以训练模型时,可以指定要在输入图像上使用的变换函数的组合。 让我们仔细看看这些函数。
PyTorch 中有两个主要使用的组合函数:
- compose:组合
- randomApply:随机应用
我们只会考虑这两个,因为它们更相关。
5.1 组合
组合(compose)基本上允许你创建一系列可应用于数据集的数据转换,特别是图像数据。 它允许你将多个数据增强组合到单个转换管道中。
让我们看一下代码。
# Define a list of transformations you want to apply to your data
transformations_list = [
v2.Resize((224, 224)), # Resize the image to a fixed size
v2.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2, hue=0.2), # Randomly adjust color
v2.RandomHorizontalFlip(), # Randomly flip the image horizontally
v2.RandomRotation(15)] # Randomly rotate the image by up to 15 degrees
# Pass the list of transformations to Compose function
transformations = v2.Compose(transformations_list)
# Apply the transformations to the image
transformed_image = transformations(orig_img)Compose 函数将转换函数列表作为输入。 当你通过此管道运行图像时,它会按照列出的顺序逐一应用每个转换。

有几件事需要注意:
- 如果使用
compose进行训练或推理,则可以使用v2.Totensor()将图像转换为 PyTorch 张量 - 如果需要,你可以添加一个额外的维度,使其成为批大小为 1 的
Transformed_imgae = Transformed_imgae.unsqueeze(0)
5.2 随机应用
这是我第一次发现这一点,因为我通常使用 Compose。 这也颇为有趣。 它的功能与 Compose 类似,主要区别在于它允许你指定要应用于输入图像的每个变换函数的概率 p。 现在,让我们看一下代码,看看它是如何工作的。
# Define a list of transformations you want to apply to your data
transformations_list = [
v2.Resize((224, 224)), # Resize the image to a fixed size
v2.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2, hue=0.2), # Randomly adjust color
v2.RandomHorizontalFlip(), # Randomly flip the image horizontally
v2.RandomRotation(15)] # Randomly rotate the image by up to 15 degrees
# Pass the list of transformations to Compose function
transformations = v2.RandomApply(transformations_list, p=0.7)
# Apply the transformations to the image
transformed_image = transformations(orig_img)RandomApply 函数接受一系列变换函数和概率分数作为输入。 当通过该管道处理输入图像时,它以概率 p 顺序将每个变换应用于图像。
6、结束语
在对 PyTorch 变换函数的深入探索中,我们涵盖了用于空间操作的几何变换、用于视觉变化的光度变换以及用于组合两个或多个变换的合成变换。 总之,充分了解这些功能和增强功能,我们可以提高数据质量并训练更强大的深度学习模型,确保它们为应对现实世界的挑战做好充分准备。
BimAnt翻译整理,转载请标明出处





