
NSDT工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器 - REVIT导出3D模型插件 - 3D模型语义搜索引擎 - AI模型在线查看 - Three.js虚拟轴心开发包 - 3D模型在线减面 - STL模型在线切割 - 3D道路快速建模
损失度量对于神经网络非常重要。 由于所有机器学习模型都是这样或那样的优化问题,因此损失是要最小化的目标函数。 在神经网络中,优化是通过梯度下降和反向传播来完成的。 但什么是损失函数,它们如何影响你的神经网络?
在这篇文章中,我们将学习:
- 什么是损失函数及其在训练神经网络模型中的作用
- 回归和分类问题的常见损失函数
- 如何在 PyTorch 模型中使用损失函数
1、什么是损失函数?
在神经网络中,损失函数有助于优化模型的性能。 它们通常用于衡量模型在预测中产生的一些惩罚,例如预测与真实标签的偏差。 损失函数通常在其域内是可微的(但允许仅对于非常特定的点未定义梯度,例如 x=0,实际中基本被忽略)。 在训练循环中,它们根据参数进行区分,这些梯度用于反向传播和梯度下降步骤,以优化训练集上的模型。
损失函数也与指标略有不同。 虽然损失函数可以告诉你模型的性能,但它们可能不是人类直接感兴趣的或容易解释的。 这就是指标的用武之地。准确性等指标对于人类理解神经网络的性能更有用,尽管它们可能不是损失函数的良好选择,因为它们可能不可微分。
接下来,我们将探讨回归问题和分类问题的一些常见损失函数。
2、回归问题的损失函数
在回归问题中,模型是预测连续范围内的值。 你的模型可以始终预测准确的值,这太好了,但如果该值足够接近,那就足够了。 因此,你需要一个损失函数来衡量它的接近程度。 离准确值越远,你的预测损失就越大。
一个简单的功能就是测量预测值和目标值之间的差异。 在查找差异时,你并不关心该值大于还是小于目标值。 因此,在数学中,我们可以试用平均绝对误差 (MAE):
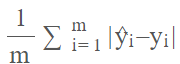
其中m表示训练样本的数量,yi 和yi_hat分别是所有训练示例的目标值和预测值的平均值。
MAE 永远不会是负数,只有当预测与真实情况完美匹配时才会为零。 它是一种直观的损失函数,也可以用作你的指标之一,特别是对于回归问题,因为你希望最大限度地减少预测中的错误。
然而,绝对值在 0 处不可微分。这并不是真正的问题,因为你很少达到该值。 但有时人们更喜欢使用均方误差 (MSE):
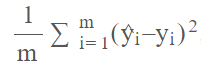
MSE与 MAE 类似,但使用平方函数代替绝对值。
均方误差测量预测值与目标值的偏差。 然而,MSE 对此差进行平方(始终为非负,因为实数的平方始终为非负),这使其属性略有不同。 一个特性是均方误差有利于大量的小误差而不是少量的大误差,这导致模型具有较少的离群值,或者至少离群值比使用 MAE 训练的模型不太严重。 这是因为与小误差相比,大误差会对误差产生明显更大的影响,从而对误差梯度产生更大的影响。
让我们以图形方式看一下平均绝对误差和均方误差损失函数的样子:
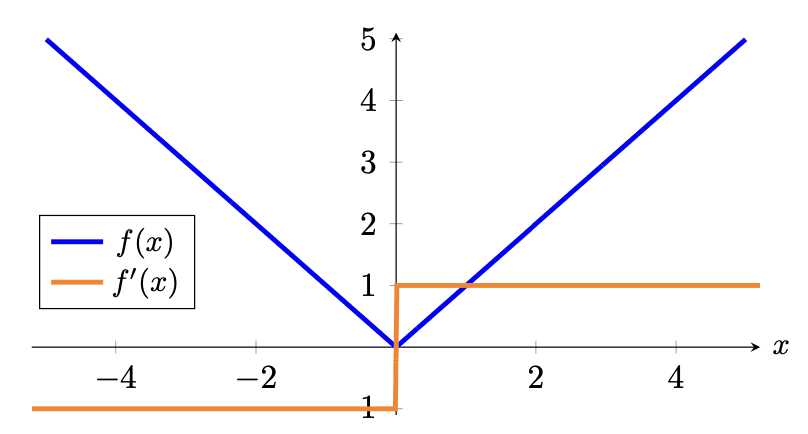
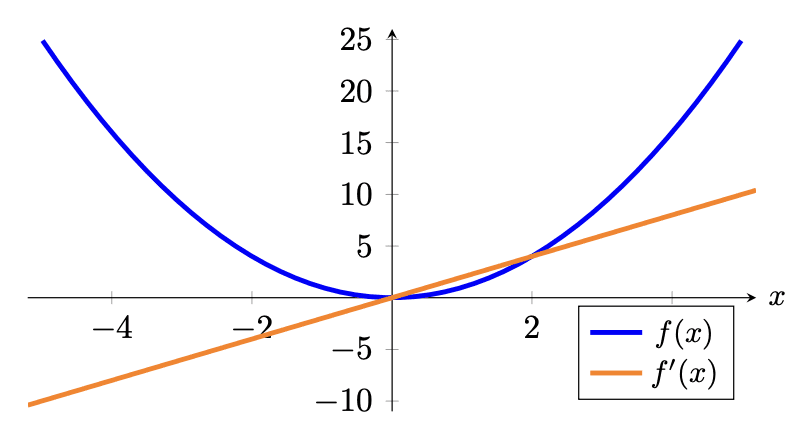
与激活函数类似,你可能也对损失函数的梯度感兴趣,因为稍后你将使用梯度进行反向传播来训练模型的参数。 你应该看到,在 MSE 中,较大的误差将导致较大的梯度幅度和较大的损失。 因此,例如,两个偏离其基本事实 1 个单位的训练示例将导致 2 的损失,而偏离其基本事实 2 个单位的单个训练示例将导致 4 的损失,因此有 影响较大。 MAE 中的情况并非如此。
在 PyTorch 中,可以分别使用 nn.L1Loss() 和 nn.MSELoss() 创建 MAE 和 MSE 作为损失函数。 之所以命名为L1,是因为MAE的计算在数学上也被称为L1范数。 下面是计算两个向量之间的 MAE 和 MSE 的示例:
import torch
import torch.nn as nn
mae = nn.L1Loss()
mse = nn.MSELoss()
predict = torch.tensor([0., 3.])
target = torch.tensor([1., 0.])
print("MAE: %.3f" % mae(predict, target))
print("MSE: %.3f" % mse(predict, target))结果应该如下:
MAE: 2.000
MSE: 5.000MAE 是 2.0 ,因为:
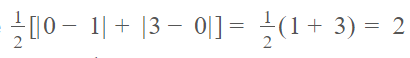
而 MSE 是 5.0,因为:
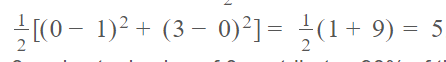
请注意,在 MSE 中,预测值为 3 且实际值为 0 的第二个示例在均方误差下贡献了 90% 的误差,而在平均绝对误差下贡献了 75% 的误差。
有时,你可能会看到人们使用均方根误差 (RMSE) 作为衡量标准。 这将取 MSE 的平方根。 从损失函数的角度来看,MSE和RMSE是等价的。 但从数值的角度来看,RMSE 与预测值的单位相同。 如果你的预测是美元金额,MAE 和 RMSE 都会告诉你预测值与美元真实价值的平均偏差程度。 但MSE的单位是平方美元,其物理意义并不直观。
3、分类问题的损失函数
对于分类问题,输出可以采用一小部分离散的数字。 此外,用于对类进行标签编码的数字是任意的并且没有语义意义(例如,使用标签 0 表示猫、1 表示狗、2 表示马并不代表狗是一半猫和一半马)。 因此,它不应该对模型的性能产生影响。
在分类问题中,模型的输出通常是每个类别的概率向量。 通常,该向量通常被期望为“logits”,即使用 softmax 函数转换为概率的实数,或 softmax 激活函数的输出。
两个概率分布之间的交叉熵是两个概率分布之间差异的度量。 准确地说,下面是概率P和Q的交叉熵公式:
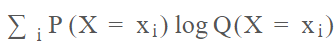
在机器学习中,概率P通常由训练数据提供,概率Q则由模型预测,即
1 代表正确的类别,0 代表所有其他类别。 预测概率Q通常是一个介于 0 和 1 之间的浮点。因此,当用于机器学习中的分类问题时,该公式可以简化为:

其中ptarget是该特定样本的真实类别的模型预测概率。
交叉熵度量有一个负号,因为当x趋向0时,log(x) 趋于负无穷。当概率接近 0 时,我们希望获得更高的损失;当概率接近 1 时,我们希望获得更低的损失。从图形上看,
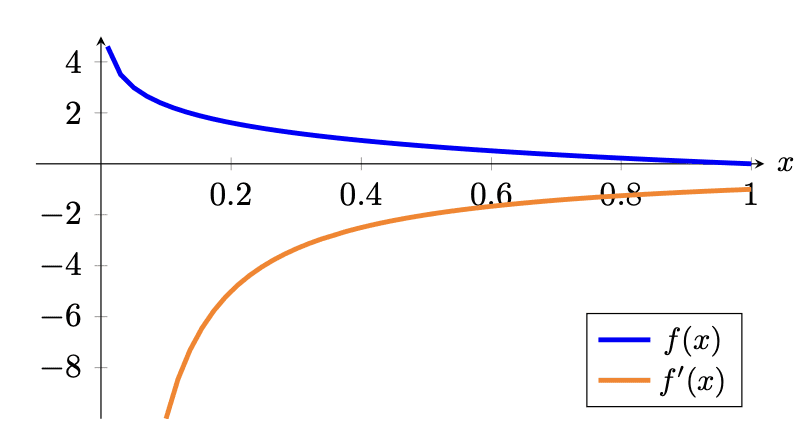
请注意,如果真实类别的概率如预期为 1,则损失恰好为 0。 此外,由于真实类别的概率趋于 0,损失也趋于正无穷大,因此会严重惩罚错误的预测。 你可能会认识到逻辑回归的这个损失函数,除了逻辑回归损失特定于二元类的情况之外,它是相似的。
查看梯度,你可以看到梯度通常为负,这也是预期的,因为为了减少这种损失,您会希望真实类别的概率尽可能高。 回想一下,梯度下降的方向与梯度相反。
在 PyTorch 中,交叉熵函数由 nn.CrossEntropyLoss() 提供。 它将预测的逻辑和目标作为参数并计算分类交叉熵。 请记住,在 CrossEntropyLoss() 函数内部,softmax 将应用于 logits,因此你不应在输出层使用 softmax 激活函数。 使用 PyTorch 的交叉熵损失函数的示例如下:
import torch
import torch.nn as nn
ce = nn.CrossEntropyLoss()
logits = torch.tensor([[-1.90, -0.29, -2.30], [-0.29, -1.90, -2.30]])
target = torch.tensor([[0., 1., 0.], [1., 0., 0.]])
print("Cross entropy: %.3f" % ce(logits, target))结果如下:
Cross entropy: 0.288请注意,交叉熵损失函数的第一个参数是 logit,而不是概率。 因此,每一行的总和不等于 1。然而,第二个参数是包含概率行的张量。 如果使用 softmax 函数将上面的 logits 张量转换为概率,则为:
probs = torch.tensor([[0.15, 0.75, 0.1], [0.75, 0.15, 0.1]])每行的总和为 1.0。 这个张量也揭示了为什么上面计算出的交叉熵是 0.288,即log0.75。
在 PyTorch 中计算交叉熵的另一种方法是不在目标中使用 one-hot 编码,而是使用整数索引标签:
import torch
import torch.nn as nn
ce = nn.CrossEntropyLoss()
logits = torch.tensor([[-1.90, -0.29, -2.30], [-0.29, -1.90, -2.30]])
indices = torch.tensor([1, 0])
print("Cross entropy: %.3f" % ce(logits, indices))这给出了相同的交叉熵 0.288。 注意,
import torch
target = torch.tensor([[0., 1., 0.], [1., 0., 0.]])
indices = torch.argmax(target, dim=1)
print(indices)结果为:
tensor([1, 0])这就是 PyTorch 解释目标张量的方式。 在其他库中,它也被称为“稀疏交叉熵”函数,以区别于它不需要一个one hot向量。
请注意,在 PyTorch 中,你可以使用 nn.LogSoftmax() 作为激活函数。 就是对一层的输出应用softmax,然后对每个元素取对数。 如果这是你的输出层,应该使用 nn.NLLLoss() (负对数似然)作为损失函数。 从数学上讲,这对组合与交叉熵损失相同。 可以通过检查下面的代码产生相同的输出来确认这一点:
import torch
import torch.nn as nn
ce = nn.NLLLoss()
# softmax to apply on dimension 1, i.e. per row
logsoftmax = nn.LogSoftmax(dim=1)
logits = torch.tensor([[-1.90, -0.29, -2.30], [-0.29, -1.90, -2.30]])
pred = logsoftmax(logits)
indices = torch.tensor([1, 0])
print("Cross entropy: %.3f" % ce(pred, indices))如果分类问题只有两个类别,则变为二元分类。 它很特别,因为该模型现在是一个逻辑回归模型,其中只能有一个输出,而不是两个值的向量。 你仍然可以将二元分类实现为多类分类,并使用相同的交叉熵函数。 但是如果你输出x
作为“正类”的概率(介于 0 和 1 之间),已知“负类”的概率必须为1-x。
在 PyTorch 中,有 nn.BCELoss() 用于二进制交叉熵。 它专门用于二进制情况。 例如:
import torch
import torch.nn as nn
bce = nn.BCELoss()
pred = torch.tensor([0.75, 0.25])
target = torch.tensor([1., 0.])
print("Binary cross entropy: %.3f" % bce(pred, target))结果如下:
Binary cross entropy: 0.288这是因为:
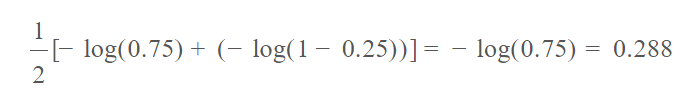
请注意,在 PyTorch 中,目标标签 1 被视为“正类”,标签 0 被视为“负类”。 目标张量中不应有其他值。
4、PyTorch 中的自定义损失函数
请注意,上面的损失指标是使用 torch.nn 模块中的对象计算的。 计算出的损失度量是 PyTorch 张量,因此可以对它进行微分并开始反向传播。 只要可以根据模型的输出计算张量,就没有什么可以阻止你创建自己的损失函数。
PyTorch 不会提供所有可能的损失指标。 例如,不包括平均绝对百分比误差。 它就像 MAE,定义为:
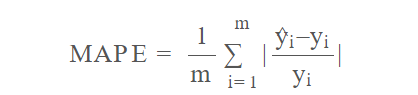
有时你可能更喜欢使用 MAPE。 回想一下加州住房数据集的回归示例,预测是针对房价的。 根据百分比差异而不是美元差异来考虑预测的准确性可能更有意义。 你可以定义 MAPE 函数,只需记住使用 PyTorch 函数进行计算并返回 PyTorch 张量即可。
请参阅下面的完整示例:
import copy
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import torch
import torch.nn as nn
import torch.optim as optim
import tqdm
from sklearn.model_selection import train_test_split
from sklearn.datasets import fetch_california_housing
from sklearn.preprocessing import StandardScaler
# Read data
data = fetch_california_housing()
X, y = data.data, data.target
# train-test split for model evaluation
X_train_raw, X_test_raw, y_train, y_test = train_test_split(X, y, train_size=0.7, shuffle=True)
# Standardizing data
scaler = StandardScaler()
scaler.fit(X_train_raw)
X_train = scaler.transform(X_train_raw)
X_test = scaler.transform(X_test_raw)
# Convert to 2D PyTorch tensors
X_train = torch.tensor(X_train, dtype=torch.float32)
y_train = torch.tensor(y_train, dtype=torch.float32).reshape(-1, 1)
X_test = torch.tensor(X_test, dtype=torch.float32)
y_test = torch.tensor(y_test, dtype=torch.float32).reshape(-1, 1)
# Define the model
model = nn.Sequential(
nn.Linear(8, 24),
nn.ReLU(),
nn.Linear(24, 12),
nn.ReLU(),
nn.Linear(12, 6),
nn.ReLU(),
nn.Linear(6, 1)
)
# loss function and optimizer
def loss_fn(output, target):
# MAPE loss
return torch.mean(torch.abs((target - output) / target))
optimizer = optim.Adam(model.parameters(), lr=0.0001)
n_epochs = 100 # number of epochs to run
batch_size = 10 # size of each batch
batch_start = torch.arange(0, len(X_train), batch_size)
# Hold the best model
best_mape = np.inf # init to infinity
best_weights = None
for epoch in range(n_epochs):
model.train()
for start in batch_start:
# take a batch
X_batch = X_train[start:start+batch_size]
y_batch = y_train[start:start+batch_size]
# forward pass
y_pred = model(X_batch)
loss = loss_fn(y_pred, y_batch)
# backward pass
optimizer.zero_grad()
loss.backward()
# update weights
optimizer.step()
# evaluate accuracy at end of each epoch
model.eval()
y_pred = model(X_test)
mape = float(loss_fn(y_pred, y_test))
if mape < best_mape:
best_mape = mape
best_weights = copy.deepcopy(model.state_dict())
# restore model and return best accuracy
model.load_state_dict(best_weights)
print("MAPE: %.2f" % best_mape)
model.eval()
with torch.no_grad():
# Test out inference with 5 samples
for i in range(5):
X_sample = X_test_raw[i: i+1]
X_sample = scaler.transform(X_sample)
X_sample = torch.tensor(X_sample, dtype=torch.float32)
y_pred = model(X_sample)
print(f"{X_test_raw[i]} -> {y_pred[0].numpy()} (expected {y_test[i].numpy()})")与另一篇文章中的示例相比,你可以看到 loss_fn 现在被定义为自定义函数。
原文链接:Loss Functions in PyTorch Models
BimAnt翻译整理,转载请标明出处





