
NSDT工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器 - REVIT导出3D模型插件 - 3D模型语义搜索引擎 - AI模型在线查看 - Three.js虚拟轴心开发包 - 3D模型在线减面 - STL模型在线切割 - 3D道路快速建模
在本系列的第一篇博文中,我们介绍了人工智能如何对许多企业变得越来越具有战略意义,但 MLOps 和在生产中部署模型的能力仍然非常困难。
在第二篇博客文章中,我们介绍了 Ray 如何通过提供单个脚本来大规模执行数据预处理、训练和调整来帮助简化您的 MLOps 实践,而 Ray Serve 提供了实时管道的开发和 部署。 这使得团队能够在不牺牲扩展性的情况下简化其技术堆栈、更好地协调并最大限度地减少整体摩擦。
我们还在第一篇博客文章中强调,选择通用 Python Web 服务器(例如 FastAPI)和专门的 ML 服务解决方案框架的开发人员之间几乎存在平等的分歧。
让我们深入研究每个选项并展示一些功能以及为什么你可能会选择其中一个而不是另一个。
1、通用 Python Web 服务器
Python 已成为数据科学的通用语言,但 Python 作为一种编程语言也越来越受欢迎。
根据 Python 软件基金会和 JetBrains 最近进行的 Python 开发者调查,FastAPI 这一现代的快速 Web 框架在 Python Web 框架中增长最快,与前一年相比增长了 9 个百分点。
FastAPI 的创建者出于对现有 Python Web 框架的不满而创建了该库。 FastAPI 旨在使用集成开发环境 (IDE) 优化开发人员体验,同时在高性能异步服务器网关接口 (ASGI) 引擎之上利用 OAuth 和开放 API 等通用标准。 结果是“一个现代、快速(高性能)的 Web 框架,用于基于标准 Python 类型提示使用 Python 3.6+ 构建 API。”
以下是 FastAPI 网站的一些突出功能:
- 快速:非常高的性能,与 NodeJS 和 Go 相当(感谢 Starlette 和 Pydantic)。 可用的最快的 Python 框架之一。
- 快速编码:将开发功能的速度提高约 200% 到 300%。
- 更少的错误:减少约 40% 的人为(开发人员)引起的错误。
- 直观:强大的编辑器支持。 无处不在的自动完成。 调试时间更少。
- 容易:旨在易于使用和学习。 阅读文档的时间更少。
- 简短:最大限度地减少代码重复。 每个参数声明具有多个功能。 更少的错误。
- 健壮:获取可用于生产的代码。 具有自动交互式文档。
基于标准:基于(并完全兼容)API 开放标准:OpenAPI(以前称为 Swagger)和 JSON Schema。
这些功能现在对于 Web 服务器框架来说很常见,旨在优化开发人员构建微服务的体验。 典型的 Web 框架允许路径管理、运行状况检查、端点测试、类型检查和对开放标准的支持。
虽然通用 Python Web 服务器旨在构建微服务,但它们并不是为服务 ML 模型而设计的。
2、专业机器学习服务
随着模型(基础模型)规模不断增大,需要 AI 加速器(GPU、TPU、AWS Inferentia)来提供更好的性能和服务 ML 模型的特定功能,出现了许多 ML 服务框架(Seldon Core、KServe、TorchServe、Tensorflow Serving、 ETC。)。
它们的目标都是在不牺牲延迟的情况下优化吞吐量,同时还提供用于服务实时 ML 模型的特定功能。
剪枝和量化等不同的模型编译技术已经出现,可以帮助减小模型大小,而又不会牺牲太多的准确性,从而减少计算推理所需的时间和总体内存占用。
微批处理等其他技术有助于最大限度地提高人工智能加速器的计算量并提高吞吐量,而无需牺牲延迟。 GPU 等人工智能加速器可以采用矢量化指令来并行执行计算。 通过批处理执行推理可以提高模型的吞吐量以及硬件的利用率。
装箱模型允许你在主机上并置多个模型并共享资源,因为这些模型不会同时调用,从而减少主机上的空闲时间。
“缩放到零”可以让你在没有流量时释放资源。 代价是,当你第一次调用模型时,通常会出现冷启动损失。
自动缩放可能需要不同的指标。 例如,你可能希望根据 CPU/GPU 利用率阈值设置策略。
适应文本、音频、视频等复杂数据类型的不同处理程序通常与那些专门的 ML 服务库一起打包。
这些功能在专业库中很常见,允许机器学习从业者优化生产中的实时模型服务。
3、Ray Serve + FastAPI
Ray Serve 提供了两全其美的功能:高性能的 Python Web 服务器和专门的 ML 服务库。
Ray Serve 允许你轻松插入 aiohttp 或 FastAPI 等 Web 服务器。
例如,Ray Serve 允许你使用 @serve.ingress 装饰器与 FastAPI 集成。
import requests
from fastapi import FastAPI
from ray import serve
# 1: Define a FastAPI app and wrap it in a deployment with a route handler.
app = FastAPI()
@serve.deployment(route_prefix="/")
@serve.ingress(app)
class FastAPIDeployment:
# FastAPI will automatically parse the HTTP request for us.
@app.get("/hello")
def say_hello(self, name: str):
return f"Hello {name}!"
# 2: Deploy the deployment.
serve.start()
FastAPIDeployment.deploy()
# 3: Query the deployment and print the result.
print(requests.get("http://localhost:8000/hello", params={"name": "Theodore"}).json())
# "Hello Theodore!"这允许你利用所有 FastAPI 功能,例如变量路由、自动类型验证以及与 Ray Serve ML 服务功能相结合的依赖项注入。
正如之前的博客文章中所述,Ray Serve 允许你使用部署图 API 在 Python 中构建多模型推理管道。 根据设计,实时管道的每个步骤都可以通过注解 serve.deployment装饰器在不同的硬件(CPU、GPU等)和/或节点上独立扩展。
如果你还记得我们在第二篇博客文章中使用了产品标记/内容理解实时推理管道。
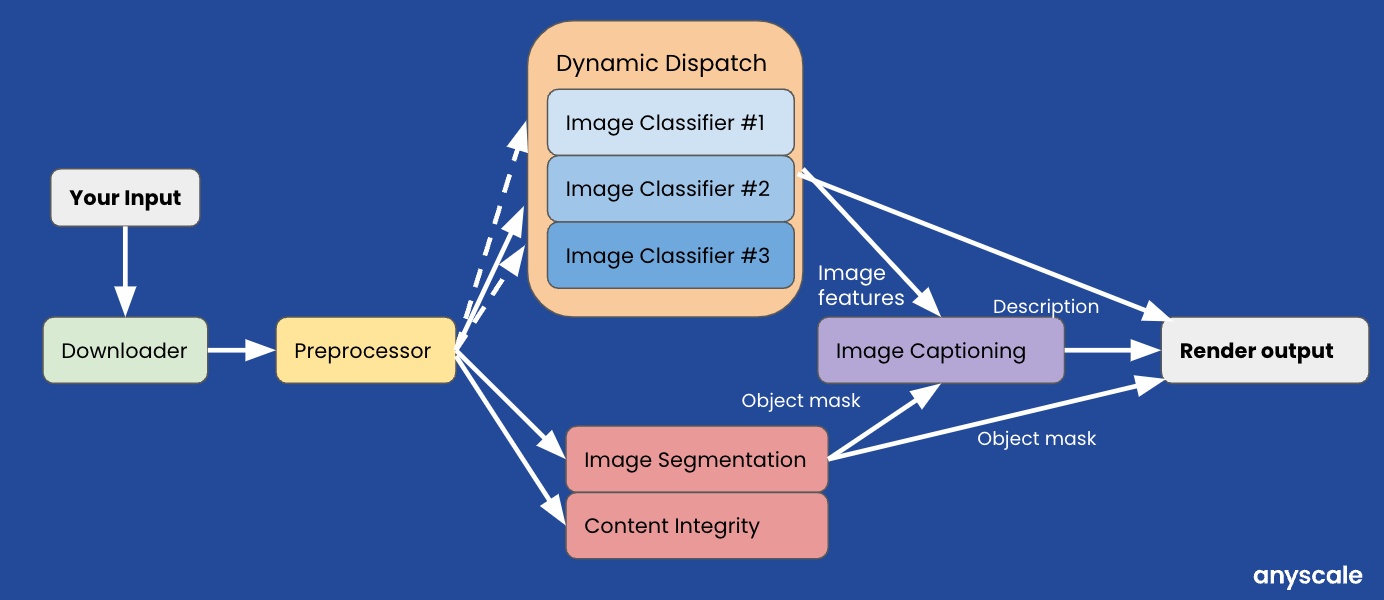
如果我们使用 Ray Serve 部署图来实现上述用例,它将如下所示:

请注意,每个任务/参与者都可以进行细粒度的资源分配,从而在不牺牲延迟的情况下提高每台主机的利用率(即 ray_actor_options={"num_cpus": 0.5})。
Ray Serve 允许你在管道的每个步骤配置副本数量。 这使你能够以毫秒为单位自动缩放 ML 服务应用程序。
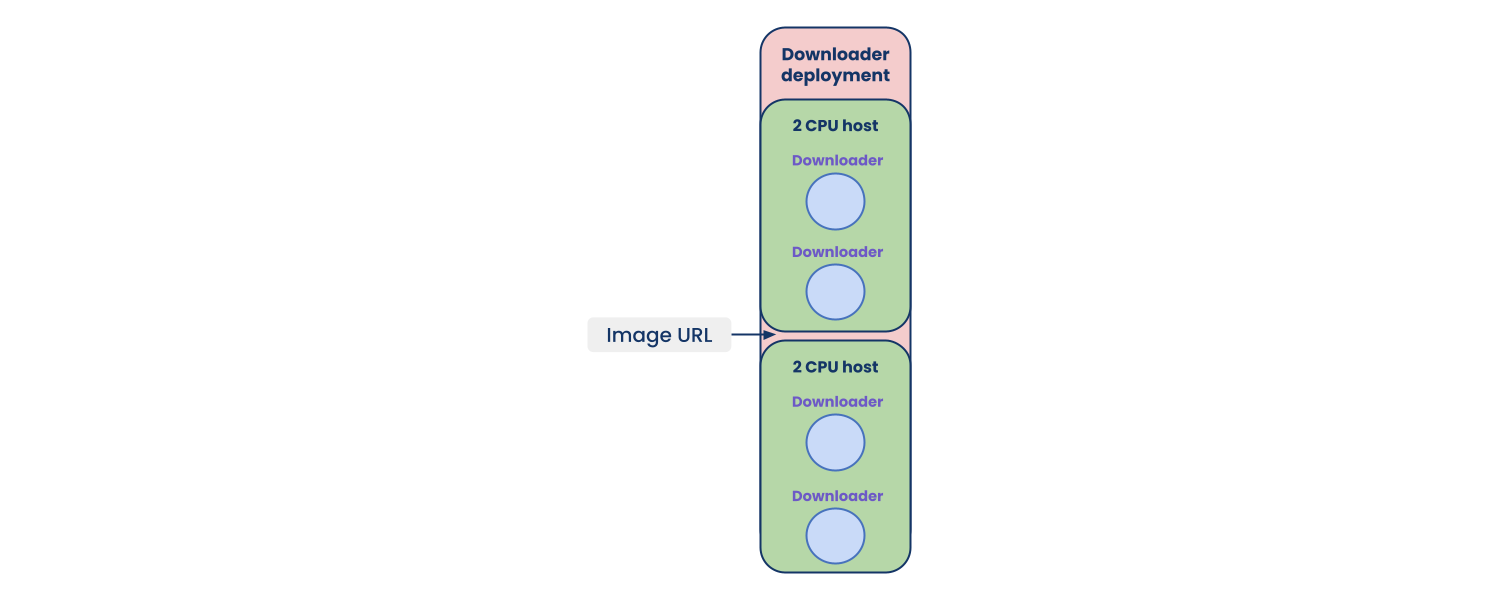
微批处理请求也可以通过使用 @serve.batch 装饰器来实现。 这不仅为开发人员提供了可重用的抽象,而且还为他们的批处理逻辑提供了更多的灵活性和定制机会。
使用经过验证的 Web 服务器框架为部署微服务提供了完善的标准和解决方案。 路由、端点测试、类型检查和运行状况检查都可以继续遵循 FastAPI 之上的当前微服务范例,而 Ray Serve 提供了所有功能来优化实时 ML 模型的服务。

当可以两全其美时,为什么还要妥协呢!
在路线图上,Ray Serve 将进一步优化你的计算,以零副本负载和模型缓存为您的模型提供服务。
零复制加载允许使用 Ray 在几毫秒内加载大型模型或加快 340 倍。 模型缓存将允许你在 Ray 内部内存中保留模型池,并允许你与给定端点的模型进行热交换。 这使你可以拥有比主机可以处理的更多的模型,并允许你根据流量、需求或业务规则优化端点主机上的资源。
原文链接:Ray Serve + FastAPI: The best of both worlds
BimAnt翻译整理,转载请标明出处





