
NSDT工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器 - REVIT导出3D模型插件 - 3D模型语义搜索引擎 - AI模型在线查看 - Three.js虚拟轴心开发包 - 3D模型在线减面 - STL模型在线切割 - 3D道路快速建模
Yao 等人于 2022 年引入了一个名为 ReAct 的框架,其中 LLM 用于以交错的方式生成推理轨迹(reasoning traces)和特定于任务的操作。
生成推理轨迹允许模型诱导、跟踪和更新行动计划,甚至处理异常。 操作步骤允许与外部源(例如知识库或环境)交互并收集信息。
ReAct 框架可以允许LLM与外部工具交互,以检索更多信息,从而获得更可靠和更真实的响应。
结果表明,ReAct 在语言和决策任务方面的表现可以优于多种最先进的基线。 ReAct 还可以提高LLM的人类可解释性和可信度。 总的来说,作者发现最好的方法是使用 ReAct 与思想链 (CoT) 相结合,允许使用推理过程中获得的内部知识和外部信息。
1、ReAct原理
ReAct 的灵感来自行动(acting)和推理(reasoning)之间的协同作用,它使人类能够学习新任务并做出决策或推理。
思想链 (CoT) 提示显示了LLM执行推理跟踪以生成涉及算术和常识推理等问题的答案的能力 (Wei et al., 2022)。 但缺乏与外部世界的接触或无法更新其知识可能会导致事实幻觉和错误传播等问题。
ReAct 是一种将推理和行动与LLM相结合的通用范式。 ReAct 提示LLM为任务生成口头推理轨迹和行动。 这使得系统能够执行动态推理来创建、维护和调整行动计划,同时还能够与外部环境(例如维基百科)进行交互,以将附加信息合并到推理中。 下图显示了 ReAct 的示例以及执行问答所涉及的不同步骤。

在上面的示例中,我们传入一个类似于以下HotpotQA问题的提示:
Aside from the Apple Remote, what other devices can control the program Apple Remote was originally designed to interact with?请注意,上下文中的示例也会添加到提示中,但为了简单起见,我们在此处将其排除。 我们可以看到该模型生成了任务解决轨迹(思考、行动)。 Obs 对应于来自正在交互的环境(例如搜索引擎)的观察。 本质上,ReAct 可以检索信息来支持推理,而推理有助于确定下一步要检索的内容。
2、ReAct提示
为了演示 ReAct 提示的工作原理,让我们按照本文中的一个示例进行操作。
第一步是从训练集中(例如 HotPotQA)选择案例并组成 ReAct 格式的轨迹。 这些在提示中用作少数样本。 轨迹由多个思考-行动-观察步骤组成,如上图所示。 自由形式的思维用于实现不同的任务,例如分解问题、提取信息、执行常识/算术推理、指导搜索公式以及综合最终答案。
以下是 ReAct 提示示例的示例(从论文中获取,为简单起见,缩写为一个示例):
Question What is the elevation range for the area that the eastern sector of the
Colorado orogeny extends into?
Thought 1 I need to search Colorado orogeny, find the area that the eastern sector
of the Colorado orogeny extends into, then find the elevation range of the
area.
Action 1 Search[Colorado orogeny]
Observation 1 The Colorado orogeny was an episode of mountain building (an orogeny) in
Colorado and surrounding areas.
Thought 2 It does not mention the eastern sector. So I need to look up eastern
sector.
Action 2 Lookup[eastern sector]
Observation 2 (Result 1 / 1) The eastern sector extends into the High Plains and is called
the Central Plains orogeny.
Thought 3 The eastern sector of Colorado orogeny extends into the High Plains. So I
need to search High Plains and find its elevation range.
Action 3 Search[High Plains]
Observation 3 High Plains refers to one of two distinct land regions
Thought 4 I need to instead search High Plains (United States).
Action 4 Search[High Plains (United States)]
Observation 4 The High Plains are a subregion of the Great Plains. From east to west, the
High Plains rise in elevation from around 1,800 to 7,000 ft (550 to 2,130
m).[3]
Thought 5 High Plains rise in elevation from around 1,800 to 7,000 ft, so the answer
is 1,800 to 7,000 ft.
Action 5 Finish[1,800 to 7,000 ft]
...请注意,不同类型的任务使用不同的提示设置。 对于推理最为重要的任务(例如 HotpotQA),任务解决轨迹使用多个思考-行动-观察步骤。 对于涉及大量行动步骤的决策任务,很少使用思考。
3、知识密集型任务的结果
论文首先在问答(HotPotQA)和事实验证(Fever)等知识密集型推理任务上评估 ReAct。 以PaLM-540B为基础模型进行提示。
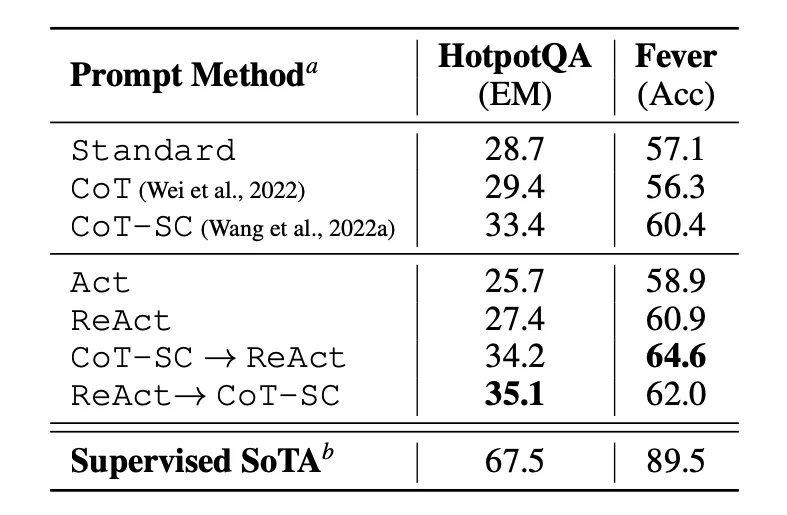
使用不同提示方式对 HotPotQA 和 Fever 进行的提示结果表明,ReAct 在这两项任务上总体表现均优于 Act(仅涉及行动)。
我们还可以观察到,ReAct 在 Fever 上的表现优于 CoT,在 HotpotQA 上落后于 CoT。 论文中提供了详细的错误分析。 总之:
- CoT患有事实幻觉
- ReAct 的结构约束降低了其制定推理步骤的灵活性
- ReAct 在很大程度上取决于它检索的信息; 无信息的搜索结果使模型推理脱轨,并导致恢复和重新表达思想的困难
结合并支持 ReAct 和 CoT+Self-Consistency 之间切换的提示方法通常优于所有其他提示方法。
4、决策任务的结果
该论文还报告了展示 ReAct 在决策任务上的性能的结果。 ReAct 在 ALFWorld(基于文本的游戏)和 WebShop(在线购物网站环境)两个基准上进行评估。 两者都涉及复杂的环境,需要推理才能有效地采取行动和探索。
请注意,ReAct 提示针对这些任务进行了不同的设计,但仍保持推理与行动相结合的相同核心理念。 下面是涉及 ReAct 提示的 ALFWorld 问题的示例。
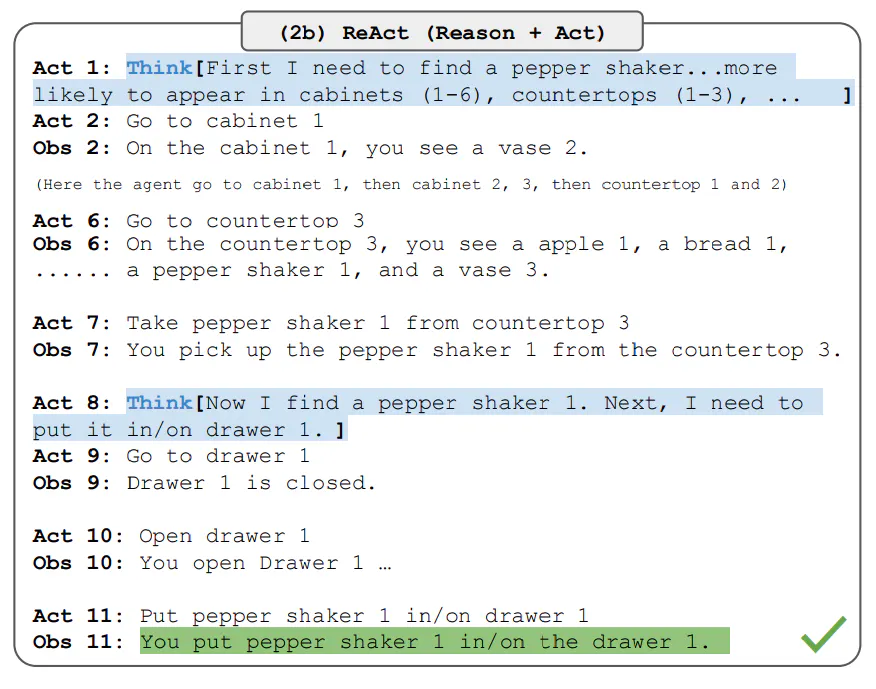
ReAct 在 ALFWorld 和 Webshop 上的表现都优于 Act。 没有任何思考的行动无法正确地将目标分解为子目标。 对于这些类型的任务,ReAct 中的推理似乎很有优势,但当前基于提示的方法与专家在这些任务上的表现仍然相去甚远。
查看论文以获取更详细的结果。
5、LangChain ReAct使用
下面是 ReAct 提示方法在实践中如何运作的高级示例。 我们将为 LLM 和 LangChain 使用 OpenAI,因为它已经具有内置功能,可以利用 ReAct 框架来构建代理,通过结合 LLM 和不同工具的功能来执行任务。
首先,让我们安装并导入必要的库:
%%capture
# update or install the necessary libraries
!pip install --upgrade openai
!pip install --upgrade langchain
!pip install --upgrade python-dotenv
!pip install google-search-results
# import libraries
import openai
import os
from langchain.llms import OpenAI
from langchain.agents import load_tools
from langchain.agents import initialize_agent
from dotenv import load_dotenv
load_dotenv()
# load API keys; you will need to obtain these if you haven't yet
os.environ["OPENAI_API_KEY"] = os.getenv("OPENAI_API_KEY")
os.environ["SERPER_API_KEY"] = os.getenv("SERPER_API_KEY")
现在我们可以配置 LLM、我们将使用的工具以及允许我们将 ReAct 框架与 LLM 和工具一起利用的代理。 请注意,我们使用搜索 API 来搜索外部信息,并使用 LLM 作为数学工具。
llm = OpenAI(model_name="text-davinci-003" ,temperature=0)
tools = load_tools(["google-serper", "llm-math"], llm=llm)
agent = initialize_agent(tools, llm, agent="zero-shot-react-description", verbose=True)配置完成后,我们现在可以使用所需的查询/提示来运行代理。 请注意,这里我们不希望提供本文中解释的少数样本。
agent.run("Who is Olivia Wilde's boyfriend? What is his current age raised to the 0.23 power?")链执行如下:
> Entering new AgentExecutor chain...
I need to find out who Olivia Wilde's boyfriend is and then calculate his age raised to the 0.23 power.
Action: Search
Action Input: "Olivia Wilde boyfriend"
Observation: Olivia Wilde started dating Harry Styles after ending her years-long engagement to Jason Sudeikis — see their relationship timeline.
Thought: I need to find out Harry Styles' age.
Action: Search
Action Input: "Harry Styles age"
Observation: 29 years
Thought: I need to calculate 29 raised to the 0.23 power.
Action: Calculator
Action Input: 29^0.23
Observation: Answer: 2.169459462491557
Thought: I now know the final answer.
Final Answer: Harry Styles, Olivia Wilde's boyfriend, is 29 years old and his age raised to the 0.23 power is 2.169459462491557.
> Finished chain.我们得到的输出如下:
"Harry Styles, Olivia Wilde's boyfriend, is 29 years old and his age raised to the 0.23 power is 2.169459462491557."我们改编自 LangChain 文档中的示例,因此要归功于他们。 我们鼓励学习者探索工具和任务的不同组合。你可以在此处找到此代码的笔记本。
原文链接:ReAct Prompting
BimAnt翻译整理,转载请标明出处





