
NSDT工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器 - REVIT导出3D模型插件 - 3D模型语义搜索引擎 - AI模型在线查看 - Three.js虚拟轴心开发包 - 3D模型在线减面 - STL模型在线切割 - 3D道路快速建模
本文重点介绍使用 Three.js 和 Tensorflow.js 实现实时人脸网格点云所需的步骤,假定你了解异步 javascript 和 Three.js 基础知识,本教程不会涵盖基础知识。
该项目的源代码可以在这个 Git 仓库中找到。 在阅读本文时查看该代码将会很有帮助,因为将跳过一些基本的实现步骤。
本文还将以具有大量抽象的面向对象的方式实现该项目,因此对 Typescript 中的类有基本的了解是一个优势。
实施步骤如下:
- 获取Three.Js 设置
- 从网络摄像头生成视频数据
- 创建人脸网格检测器
- 创建空点云
- 将跟踪信息提供给点云
1、获取 Three.js 设置
由于我们在本教程中的目标是渲染人脸点云,因此我们需要从设置three. js 场景开始。
设置场景所需的数据和方法封装在sceneSetUp.ts中一个名为ThreeSetUp的工厂类中。 这个类负责创建所有必要的场景对象,如渲染器、相机和场景。 它还会启动 canvas 元素的调整大小处理程序。 此类具有以下公共方法:
- getSetUp:此函数返回一个包含相机、场景、渲染器和画布尺寸信息的对象。
getSetUp(){
return {
camera: this.camera,
scene: this.scene,
renderer : this.renderer,
sizes: this.sizes,
}
}- apply OrbitControls:此方法将负责在我们的设置中添加轨道控制并返回我们需要调用以更新轨道控制的函数。
applyOrbitControls(){
const controls = new OrbitControls(
this.camera, this.renderer.domElement!
)
controls.enableDamping = true
return ()=> controls.update();
}我们的主要实现类 FacePointCloud 将启动 ThreeSetUP 类并调用这两个方法来获取设置元素并应用轨道控制。
2、从网络摄像头生成视频数据
为了能够获得面部网格跟踪信息,我们需要一个像素输入来提供给面部网格跟踪器。在这种情况下,我们将使用设备网络摄像头来生成此类输入。我们还将使用 HTML 视频元素(不将其添加到 Dom)从网络摄像头读取媒体流,并以我们的代码可以与之交互的方式加载它。
在这一步之后,我们将设置一个 HTML canvas 元素(同样不添加到 Dom)并将我们的视频输出渲染到它。这使我们还可以选择从画布生成 Three Js 纹理并将其用作材质(我们不会在本教程中实现它)。 canvas 元素是我们将用作 FaceMeshTracker 的输入的元素。
为了处理从网络摄像头读取媒体流并将其加载到视频 HTML 元素,我们将创建一个名为 WebcamVideo 的类。此类将处理创建 HTML 视频元素并调用导航器 api 以加载获取用户权限并从设备的网络摄像头加载信息。
在启动此类时,将调用具有以下代码的私有 init 方法:
private init(){
navigator.mediaDevices.getUserMedia(this.videoConstraints)
.then((mediaStream)=>{
this.videoTarget.srcObject = mediaStream
this.videoTarget.onloadedmetadata = () => this.onLoadMetadata()
}
).catch(function (err) {
alert(err.name + ': ' + err.message)
}
)
}此方法调用Navigator对象的 mediaDevices 属性上的 getUserMedia 方法。 此方法将视频约束(又名视频设置)作为参数并返回一个承诺。 此承诺解析为包含来自网络摄像头的视频数据的 mediaStream 对象。 在 promise 的 resolve 回调中,我们将视频元素的源设置为返回的 mediaStream。
在 promise resolve 回调中,我们还在视频元素上添加了一个 loadedmetadata 事件监听器。 此监听器的回调触发对象的 onLoadMetaData 方法并设置以下附带作用:
- 自动播放视频
- 确保视频内联播放
- 调用我们传递给对象的可选回调,以便在事件触发时调用
private onLoadMetadata(){
this.videoTarget.setAttribute('autoplay', 'true')
this.videoTarget.setAttribute('playsinline', 'true')
this.videoTarget.play()
this.onReceivingData()
}此时我们有一个 WebcamVideo 对象,它处理创建包含我们的实时网络摄像头数据的视频元素。 下一步是在画布对象上绘制视频输出。
为此,我们将创建一个使用 WebcamVideo 类的特定 WebcamCanvas 类。 此类将创建 WebcamVideo 类的一个实例,并使用它使用 drawImage() 画布上下文方法将视频输出绘制到画布上。 这将在 updateFromWebcam 方法上实现。
updateFromWebCam(){
this.canvasCtx.drawImage(
this.webcamVideo.videoTarget,
0,
0,
this.canvas.width,
this.canvas.height
)
}我们将不得不在渲染循环中不断调用此函数,以使用视频的当前帧不断更新画布。
此时,我们已经准备好像素输入作为显示网络摄像头的画布元素。
3、使用 Tensorflow.js 创建面部网格检测器
创建人脸网格检测器和生成检测数据是本教程的主要部分。 这将实现 Tensorflow.js 人脸界标检测模型。
npm add @tensorflow/tfjs-core, @tensorflow/tfjs-converter
npm add @tensorflow/tfjs-backend-webgl
npm add @tensorflow-models/face-detection
npm add @tensorflow-models/face-landmarks-detection安装所有相关包后,我们将创建一个类来处理以下内容:
- 加载模型,
- 获取检测器对象,
- 将检测器添加到类中,
- 实现一个公共检测功能以供其他对象使用。
我们创建了一个名为 faceLandmark.ts 的文件来实现该类。 文件顶部的导入是:
import '@mediapipe/face_mesh'
import '@tensorflow/tfjs-core'
import '@tensorflow/tfjs-backend-webgl'
import * as faceLandmarksDetection from '@tensorflow-models/face-landmarks-detection'这些模块将需要运行和创建检测器对象。
我们创建如下所示的 FaceMeshDetectorClass:
export default class FaceMeshDetector {
detectorConfig: Config;
model: faceLandmarksDetection.SupportedModels.MediaPipeFaceMesh;
detector: faceLandmarksDetection.FaceLandmarksDetector | null;
constructor(){
this.model = faceLandmarksDetection.SupportedModels.MediaPipeFaceMesh;
this.detectorConfig = {
runtime: 'mediapipe',
refineLandmarks: true,
solutionPath: 'https://cdn.jsdelivr.net/npm/@mediapipe/face_mesh',
}
this.detector = null;
}
private getDetector(){
const detector = faceLandmarksDetection.createDetector(
this.model,
this.detectorConfig as faceLandmarksDetection.MediaPipeFaceMeshMediaPipeModelConfig
);
return detector;
}
async loadDetector(){
this.detector = await this.getDetector()
}
async detectFace(source: faceLandmarksDetection.FaceLandmarksDetectorInput){
const data = await this.detector!.estimateFaces(source)
const keypoints = (data as FaceLandmark[])[0]?.keypoints
if(keypoints) return keypoints;
return [];
}
}此类中的主要方法是 getDetector,它调用我们从 Tensorflow.js 导入的 faceLandMarksDetection 上的 createDetector 方法。 然后 createDetector 采用我们在构造函数中引入的模型:
this.model = faceLandmarksDetection.SupportedModels.MediaPipeFaceMesh;和指定检测器参数的检测配置对象:
this.detectorConfig = {
runtime: 'mediapipe',
refineLandmarks: true,
solutionPath: 'https://cdn.jsdelivr.net/npm/@mediapipe/face_mesh',
}detect 函数将返回一个 promise,promise 将解析为检测器对象。 然后在 loadDetector 公共异步方法中使用私有 getDetector 函数,此方法将类上的 this.detector 属性设置为检测器。
FaceMeshDetector 类还实现了一个公共的 detectFace 方法:
async detectFace(source){
const data = await this.detector!.estimateFaces(source)
const keypoints = (data as FaceLandmark[])[0]?.keypoints
if(keypoints) return keypoints;
return [];
}此方法采用作为像素输入的源参数。 这是我们将使用上面的画布元素作为跟踪源的地方。 该函数将按如下方式调用:
faceMeshDetector.detectFace(this.webcamCanvas.canvas)此方法调用检测器上的 estimateFaces 方法,如果此方法检测到网络摄像头输出中的人脸,它将返回一个数组,其中包含一个包含检测数据的对象。 这个对象有一个叫做关键点的属性,它包括一个对象数组,对应模型在脸上检测到的 478 个点中的每一个。 每个对象都有 x、y 和 z 属性,其中包括画布中点的坐标。 例子:
[
{
box: {
xMin: 304.6476503248806,
xMax: 502.5079975897382,
yMin: 102.16298762367356,
yMax: 349.035215984403,
width: 197.86034726485758,
height: 246.87222836072945
},
keypoints: [
{x: 406.53152857172876, y: 256.8054528661723, z: 10.2, name:
"lips"},
{x: 406.544237446397, y: 230.06933367750395, z: 8},
...
],
}
]请务必注意,这些点作为画布空间中的坐标返回,这意味着参考点 x: 0 和 y: 0 点位于画布的左上角。 稍后当我们必须将坐标转换为 Three.js 场景空间时,这将是相关的,该场景空间的参考点位于场景的中心。
此时,我们有了像素输入源,以及将为我们提供检测点的面部网格检测器。 现在,我们可以转到 Three.js 部分了!
4、创建空点云
为了在 Three.js 中生成面部网格,我们必须从检测器加载面部网格点,然后将它们用作 Three js Points 对象的位置属性。 为了使三个 js 面部网格反映视频中的运动(实时反应),只要我们创建的检测器的面部检测发生变化,我们就必须更新此位置属性。
为了实现这一点,我们将创建另一个名为 PointCloud 的工厂类,它将创建一个空的 Points 对象,以及一个公共方法,我们可以使用它来更新该点对象的属性,例如位置属性。 这个类看起来像这样:
export default class PointCloud {
bufferGeometry: THREE.BufferGeometry;
material: THREE.PointsMaterial;
cloud: THREE.Points<THREE.BufferGeometry, THREE.PointsMaterial>;
constructor() {
this.bufferGeometry = new THREE.BufferGeometry();
this.material = new THREE.PointsMaterial({
color: 0x888888,
size: 0.0151,
sizeAttenuation: true,
});
this.cloud = new THREE.Points(this.bufferGeometry, this.material);
}
updateProperty(attribute: THREE.BufferAttribute, name: string){
this.bufferGeometry.setAttribute(
name,
attribute
);
this.bufferGeometry.attributes[name].needsUpdate = true;
}
}此类启动空的 BufferGrometry,这是点的材质和消耗两者的点对象。 将这个点对象添加到场景中不会改变任何东西,因为几何体没有任何位置属性,换句话说没有顶点。
PointCloud 类还公开了 updateProperty 方法,该方法接受缓冲区属性和属性名称。 然后它将调用 bufferGeometry setAttribute 方法并将 needsUpdate 属性设置为 true。 这将允许 Three.js 在下一次 requestAnimationFrame 迭代中反映 bufferAttribute 的变化。
此 updateProperty 方法是我们将用于根据从 Tensorflow.js 检测器接收到的点更改点云形状的方法。
现在,我们的点云也准备好接收新的位置数据。 所以,是时候把所有东西绑在一起了!!
5、将跟踪信息提供给 PointCloud
为了将所有内容联系在一起,我们将创建一个实现类来调用我们需要的类、方法和步骤来让所有内容正常工作。 这个类叫做 FacePointCloud。 在构造函数中,它将实例化以下类:
- ThreeSetUp类获取场景设置对象
- CanvasWebcam 获取显示网络摄像头内容的画布对象
- 用于加载跟踪模型并获取检测器的 faceLandMark 类
- PointCloud 类,用于设置空点云并稍后使用检测数据对其进行更新
constructor() {
this.threeSetUp = new ThreeSetUp()
this.setUpElements = this.threeSetUp.getSetUp()
this.webcamCanvas = new WebcamCanvas();
this.faceMeshDetector = new faceLandMark()
this.pointCloud = new PointCloud()
}此类还将有一个名为 bindFaceDataToPointCloud 的方法,它执行我们逻辑的主要部分,即获取检测器提供的数据,将其转换为 Three.js 可以理解的形式,从中创建一个 Three.js 缓冲区属性并使用 它更新点云。
async bindFaceDataToPointCloud(){
const keypoints = await
this.faceMeshDetector.detectFace(this.webcamCanvas.canvas)
const flatData = flattenFacialLandMarkArray(keypoints)
const facePositions = createBufferAttribute(flatData)
this.pointCloud.updateProperty(facePositions, 'position')
}因此,我们将画布像素源传递给 detectFace 方法,然后在实用函数 flattenFacialLandMarkArray 中对返回的数据执行操作。 这非常重要,因为有两个问题:
- 正如我们上面提到的,人脸检测模型的点将以以下形状返回:
keypoints: [
{x: 0.542, y: 0.967, z: 0.037},
...
]而 buffer 属性需要以下形状的数据/数字:
number[] or [0.542, 0.967, 0.037, .....]- 数据源和画布之间的坐标系差异,画布的坐标系如下所示:
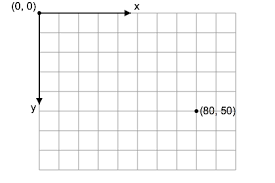
Three.js 场景坐标系统如下所示:
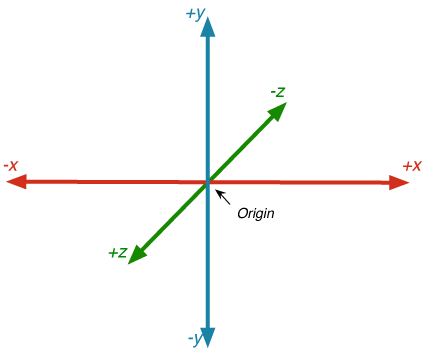
所以考虑到这两个选项,我们实现了 flattenFacialLandMarkArray 函数来处理这些问题。 此函数的代码如下所示:
function flattenFacialLandMarkArray(data: vector[]){
let array: number[] = [];
data.forEach((el)=>{
el.x = mapRangetoRange(500 / videoAspectRatio, el.x,
screenRange.height) - 1
el.y = mapRangetoRange(500 / videoAspectRatio, el.y,
screenRange.height, true)+1
el.z = (el.z / 100 * -1) + 0.5;
array = [
...array,
...Object.values(el),
]
})
return array.filter((el)=> typeof el === 'number');
}flattenFacialLandMarkArray 函数获取我们从人脸检测器接收到的关键点输入,并将它们分散到一个数组中,以数字 [] 形式而不是对象 [] 形式。 在将数字传递给新的输出数组之前,它通过 mapRangetoRange 函数将它们从画布坐标系映射到 three.js 坐标系。 该函数如下所示:
function mapRangetoRange(from: number, point: number, range: range, invert: boolean = false): number{
let pointMagnitude: number = point/from;
if(invert) pointMagnitude = 1-pointMagnitude;
const targetMagnitude = range.to - range.from;
const pointInRange = targetMagnitude * pointMagnitude +
range.from;
return pointInRange
}我们现在可以创建我们的 init 函数和我们的动画循环。 这是在 FacePointCloud 类的 initWork 方法中实现的,如下所示:
async initWork() {
const { camera, scene, renderer } = this.setUpElements
camera.position.z = 3
camera.position.y = 1
camera.lookAt(0,0,0)
const orbitControlsUpdate = this.threeSetUp.applyOrbitControls()
const gridHelper = new THREE.GridHelper(10, 10)
scene.add(gridHelper)
scene.add(this.pointCloud.cloud)
await this.faceMeshDetector.loadDetector()
const animate = () => {
requestAnimationFrame(animate)
if (this.webcamCanvas.receivingStreem){
this.bindFaceDataToPointCloud()
}
this.webcamCanvas.updateFromWebCam()
orbitControlsUpdate()
renderer.render(scene, camera)
}
animate()
}我们可以看到这个 init 函数是如何将所有东西联系在一起的,它获取 Three.js 设置元素并设置相机,将 gridHelper 添加到场景和我们的点云中。
然后它在 faceLandMark 类上加载检测器并开始设置我们的动画功能。 在这个动画函数中,我们首先检查我们的 WebcamCanvas 元素是否正在从网络摄像头接收流,然后调用 bindFaceDataToPointCloud 方法,该方法在内部调用检测面部函数并将数据转换为 bufferAttribute 并更新点云位置属性。
现在,如果你运行代码,你应该在浏览器中得到以下结果!
原文链接:Real-time face mesh point cloud with Three.JS, Tensorflow.js and Typescript
BimAnt翻译整理,转载请标明出处





