
NSDT工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器 - REVIT导出3D模型插件 - 3D模型语义搜索引擎 - AI模型在线查看 - Three.js虚拟轴心开发包 - 3D模型在线减面 - STL模型在线切割 - 3D道路快速建模
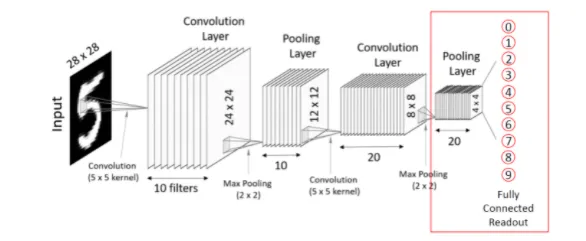
到目前为止,我们主要关注监督学习问题(主要是分类)。 在监督学习中,我们得到某种由输入/输出对组成的训练数据,目标是能够在学习模型后根据一些新输入来预测输出。 例如,我们之前研究过 MNIST 的卷积神经网络 (CNN) 分类模型; 给定 60000 个数字图像和相应数字标签(例如“5”)的训练集,我们学习了一个能够预测新 MNIST 图像的数字标签的模型。 换句话说,类似于(但不完全是)这样的东西:
如果我们想学习如何执行更复杂的行为,而数据收集可能会很昂贵,该怎么办? 如何教机器人走路? 自动驾驶汽车? 如何在围棋游戏中击败人类冠军?
1、强化学习
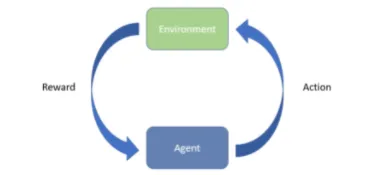
在强化学习中,我们的模型 — 在这种情况下通常称为代理(agent)— 通过采取行动 𝑎a 与环境进行交互,并以奖励 𝑟 的形式从环境中接收某种反馈。 从这个意义上说,强化学习算法是通过经验来学习的。 我们将任务从开始到结束的轨迹称为情节(episode),并且我们的智能体通常会通过经历许多情节来学习。
许多强化学习算法都被建模为马尔可夫决策过程 (MDP)。 在这些设置中,我们有一个状态𝑠的概念,它封装了代理的情况(例如位置、速度)。 从每个状态𝑠𝑡,代理采取行动𝑎𝑡,这会导致从一种状态𝑠𝑡转换到另一种状态𝑠𝑡+1。 在许多设置中,这种转变存在随机性,这意味着在 𝑠𝑡+1 上存在以 𝑠𝑡 和 𝑎𝑡 为条件的分布。 通常,其中一些状态被认为是情节结束,之后代理无法再进行任何转换或收集更多奖励。 这些对应于诸如达到最终目标、游戏结束或坠落悬崖等状态。 最后,我们的目标是学习策略𝜋或从状态到动作的映射。
在 MDP 中,我们假设我们总能知道我们的智能体处于哪个状态𝑠𝑡。但是,情况并非总是如此。 有时,我们所能获得的只是观察结果𝑜𝑡,它们提供了状态𝑠𝑡的信息,但足以精确地确定确切的状态。 我们将这种设置称为部分可观察马尔可夫决策过程(POMDP)。 想象一下,例如,Roomba 正在接受 RL 训练,可以在客厅中导航。 从其红外和机械“碰撞”传感器中,它接收到有关其可能所在位置的部分信息(𝑜𝑡ot),但不是明确的位置(𝑠𝑡)。 作为 POMDP 运行给 RL 算法增加了一整层的复杂性。 不过,在今天剩下的时间里,我们将重点关注 MDP,因为它们更简单、更容易用来教授基本概念。
2、一个简单的 MDP 示例
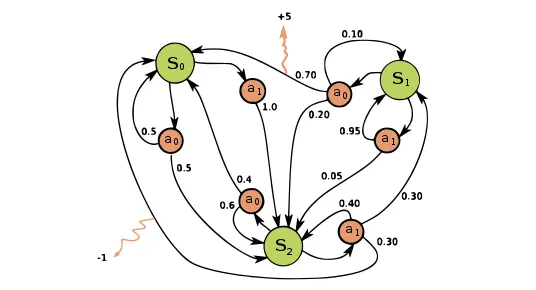
在上面的示例中,我们可以看到代理有 3 个可能的状态:𝑠0、𝑠1 和 𝑠2,每个状态有 2 个操作 𝑎0 和 𝑎1。 我们可以看到,每个操作都不会导致到下一阶段的确定性过渡,如每个操作的多个路径所示。 请注意,行动的每个结果都标有 0 到 1 之间的小黑色数字。这表示给定行动的结果(我们最终达到的状态)的概率; 由于这些是概率,因此在给定先前状态 𝑠𝑡st 和所选操作 𝑎𝑡 的情况下,到达下一个状态 𝑠𝑡+1 中的每个状态的概率之和为 1。
2.1 目标
代理的目标是最大化它可以通过多个步骤获得的总奖励𝑅R。 重要的是要确保奖励真正体现了我们希望代理实现的真正目标。 代理将尽职尽责地尝试最大化其给出的目标,而不考虑人类可能期望的任何隐含目标。 关于 RL 代理通过利用奖励函数的某些方面来学习不良行为的(有趣的)轶事有很多。 因此,定义这种奖励需要特别小心。
强化学习研究人员通常采用的一种对策是折扣奖励的概念。 这是通过乘法项 𝛾 完成的:未来 𝑇 步后得到的奖励被折扣为 𝛾𝑇𝑟𝑇。 使用折扣可以鼓励代理尽快完成任务,而不是推迟,这是一个常见的隐含标准。 通过折扣,RL 代理的目标是最大化:
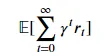
这远不是让我们的奖励准确地体现我们期望的目标的完整解决方案,但尽早而不是推迟获得更高的奖励几乎是普遍的偏好,所以我们几乎总是添加它。 设计一个好的奖励函数可以说是一门艺术,高度依赖于任务。
2.2 强化学习 vs. 监督学习
乍一看,这似乎与我们之前看过的监督方法没有太大不同,并且可能会出现一些自然问题:
为什么我们不能将强化学习视为一项有监督的任务? 为什么我们不能使用奖励(或者更确切地说,奖励的负数)作为我们的监督损失?
与监督学习不同,在强化学习中,我们通常没有预先分配的数据集可供学习。 在某些问题设置中,我们可能有其他代理(通常是人类)执行所需任务的示例,但这些不一定是如何最大化奖励的最佳示例,而这正是我们想要学习的。 在大多数强化学习设置中,除了我们的智能体通过试错所经历的情况之外,我们没有任何状态动作轨迹的例子,这甚至是次优的。
3、OpenAI Gym
在我们深入实施强化学习模型之前,首先需要一个环境。 请记住,我们的目标是学习一个可以按照我们想要的方式与环境交互的智能体,因此我们需要智能体可以与之交互并从中获得奖励的东西。 在机器人技术中,这通常是现实世界(或现实世界中的某些设置)。 然而,首先在模拟设置中测试我们的算法通常更便宜、更快。 有许多任务是强化学习社区的流行基准,例如cart pole、mountain car 或 Atari 2600 游戏。 本着加速研究社区进步和促进开放的精神,Open AI 很好地编写了 Open AI Gym,其中实现了许多此类环境供公众使用。 我们将使用这些环境,因为它使我们能够专注于算法本身,而不是担心自己实现每个问题设置。
要使用它,我们首先需要下载并安装它。 首先确保你处于 PyTorch 环境中!
# If you environment isn't currently active, activate it:
# conda activate pytorch
pip install gym安装后我们可以像任何其他 Python 模块一样导入Gym:
import gym3.1 FrozenLake世界
让我们从一个简单的环境开始:FrozenLake。 以下是 OpenAI Gym 的官方描述:
冬天来了。 你和你的朋友正在公园里扔飞盘,突然你猛烈地投掷,把飞盘扔到了湖中央。 水大部分都结冰了,但有一些冰已经融化的洞。 如果你踏入其中一个洞,你就会掉进冰冷的水中。 目前全球飞盘都短缺,因此你必须穿越湖并取回飞盘。 然而,冰很滑,所以你不会总是朝着你想要的方向移动。
FrozenLake 作为栅格世界的可视化:
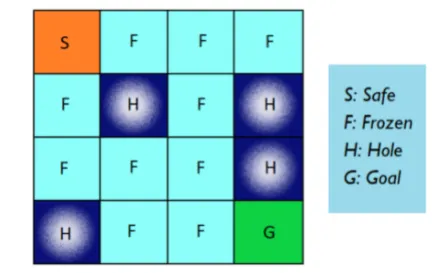
在情节开始时,我们从左上角 (S) 开始。 我们的目标是将自己移动到右下角(G),避免掉入洞中(H)。 冰水很冷。
用强化学习术语来说,网格上的 16 个位置中的每一个都是一个状态,动作是尝试沿四个方向(左、下、右、上)之一移动。 每次移动都会导致代理的状态从𝑠𝑡更改为𝑠𝑡+1,因为它改变了位置,除非它尝试向墙壁方向移动,这会导致代理的状态不变(代理不移动)。 达到目标(G)后,我们会获得“+1”的正奖励,并根据花费的时间进行折扣。 虽然掉入洞中并没有负奖励(H),但智能体仍然要支付惩罚,因为掉入洞是情节结束,因此阻止它获得任何奖励。 我们想要学习一个策略𝜋,它可以用尽可能少的步骤将我们从起始位置(S)带到目标(G)。
为了真正确定我们在这里想要实现的目标,有必要澄清一些常见的最初误解:
- 状态和转移概率的知识:从自上而下的角度来看,你的第一个想法可能是绘制一条从起点到终点的路径,就像迷宫一样。 然而,这个视图是提供给我们算法设计者的,这样我们就可以直观地看到手头的问题。 学习任务的智能体并没有获得这些先验知识; 我们要告诉的是,将会有 16 个状态,每个状态有 4 种可能的行动。 更恰当的比喻是,如果我蒙住你的眼睛,把你扔到结冰的湖中央,每次你决定向四个方向之一迈出一步时,告诉你当前状态(位置),然后在你踩中飞盘时放烟花。
- 目标(奖励)知识:在 OpenAI 对环境的官方描述中,你(智能体)知道你希望实现什么:你想要取回飞盘,同时避免掉进冰里。 代理并不知道这一点。 相反,它通过体验奖励(或惩罚)来学习目标,并且算法更新其策略,以便它更有可能(或更少)再次执行这些操作。 请注意,这意味着如果代理从未经历过某些奖励,它就不会知道它们的存在。
- 寻路、物理等先验知识:作为一个人,即使你以前没有解决过这个任务,你仍然会为这个问题带来大量的先验知识。 例如,你知道到达目的地的最短路径是一条线。 你知道北、南、东、西是方向,向北然后向南会带你回到原来的地方。 你知道冰很滑。 你知道冰水很冷。 你知道在冰冷的水中是很糟糕的。 重要的是要记住,我们的代理将开始不知道这些事情; 它最初的政策本质上是完全随机选择行动。 训练结束时,它仍然不知道“北/南”、“冷”或“滑”等抽象概念意味着什么,但它(希望)会学到一个好的策略,使其能够完成训练 目标。
3.2 与FrozenLake互动
这个例子很简单,我们可以很容易地自己编写环境及其界面的代码,但 OpenAI 已经做到了,我们希望尽可能关注解决它的算法。 我们可以用一行代码创建 FrozenLake 的实例:
env = gym.make('FrozenLake-v0')开放 AI Gym 环境提供了一种观察环境状态的机制,并且由于 FrozenLake 是 MDP(与 POMDP 相对),因此观察就是状态本身。 对于 FrozenLake,地图上有 16 个网格位置,这意味着我们有 16 个状态。 我们可以通过查看我们刚刚创建的环境的 Observation_space 属性的大小来确认这一点:
env.observation_space我们的代理将与该环境交互,导致其状态发生变化。 对于 FrozenLake,我们有 4 个选项,每个选项对应于尝试朝特定方向迈进:[左、下、右、上]。 我们可以通过查看环境的 action_space 的大小来确认这一点:
env.action_space在与环境交互之前,我们必须首先重置它以对其进行初始化。 重置还会返回重置后第一个状态的观察结果。 在 FrozenLake 中,我们总是从左上角开始,它对应于状态 0。因此,我们看到 reset() 命令返回 0:
env.reset()我们可以通过调用 render() 来可视化 FrozenLake 环境。 在更复杂的任务中,这实际上会在视频中添加帧来显示我们代理的进度,但对于 FrozenLake,它只是打印出文本表示,其中突出显示的字符显示我们代理的当前位置。 我们可以看到我们从左上角的“S”开始,正如所承诺的那样:
env.render()现在,让我们尝试移动。 需要记住的一件事是,最初的 FrozenLake 环境是“湿滑的”。 因为有冰,如果你尝试朝一个方向走,你最终有 1/3 的机会朝你想要的方向和两个相邻的方向走。 例如,如果我们尝试向右走,那么滑倒和上下移动的概率是相等的。 这让事情变得更加复杂,所以现在,我们首先关闭随机性,并使其成为确定性转变。 我们通过注册一种新类型的环境,然后实例化所述环境的副本来实现此目的,并确保首先重置它:
# Non-slippery version
from gym.envs.registration import register
register(
id='FrozenLakeNotSlippery-v0',
entry_point='gym.envs.toy_text:FrozenLakeEnv',
kwargs={'map_name' : '4x4', 'is_slippery': False},
)
env = gym.make('FrozenLakeNotSlippery-v0')
env.reset()我们使用 step() 方法在 OpenAI 环境中推动时间前进,该方法以 action 作为参数。 让我们尝试向右移动,这对应于动作 2。请注意,输出是一个由四个元素组成的元组:下一个观察(对象)、奖励(浮点数)、剧集是否完成(布尔值)和字典 可能对调试有用的信息(字典)(该字典不应在最终算法本身中使用):
env.step(2)接下来,让我们通过 render() 来可视化发生了什么。 观察这个特定的环境打印出我们在顶部括号中采取的操作,在本例中为“(右)”,然后显示该操作的结果。 请注意,虽然大多数时候,我们都能成功地朝着我们想要的方向前进,但有时我们会在冰上滑倒并朝着我们不希望的方向前进:
env.render()我们可以根据需要多次重复此操作。 由于我们在 Jupyter 中,我们可以继续运行相同的单元格(进行小的编辑来改变我们的操作)。
请注意,一旦我们掉进洞里,这一集就结束了,我们就不能再做任何事情了。 达到目标后也是如此:
env.step(0)
env.render()在我们进入任何强化学习之前,让我们看看随机动作在这个环境中如何执行:
env.reset()
done = False
while not done:
env.render()
action = env.action_space.sample()
_, _, done, _ = env.step(action)嗯。 不是很好。 好吧,很明显,随机选择步骤不太可能让我们达到目标。 仅从地图上就可以明显看出我们可以学习更好的政策。 我们要怎么做呢?
4、Q-learning
我们可以使用很多算法,但我们选择今天早些时候介绍过的 Q-learning。 请记住,在 Q -learning(以及 SARSA,事实证明)中,我们试图学习系统中状态的 Q 值。
策略 𝜋 的 Q 值是状态 𝑠s 和操作 𝑎a 的函数,定义如下:
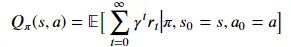
直观上,Q 值是如果智能体从状态 𝑠 采取行动 𝑎a,然后在该集的其余部分遵循策略 𝜋,它将获得的总奖励(包括折扣)。 正如人们所预料的那样,如果 Q 准确已知,并且策略 𝜋 选择具有最高 Q 值的 𝑎a,则代理将从 𝑠 中获得最高奖励。
好的,如果我们知道系统的 Q 值,那么我们就可以轻松找到最优策略。 那么系统的Q值是多少呢? 好吧,一开始我们不知道,但我们可以尝试通过经验来学习它们。 这就是 Q-learning的用武之地。Q-learning通过以下方式迭代更新 Q 值:
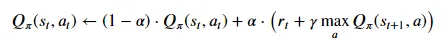
请注意,Q 学习是一种off-policy方法,从某种意义上说,你实际上并没有从实际采取的轨迹中学习(否则就会成为 SARSA)。 相反,我们从贪婪的过渡中学习,即我们知道如何采取的最佳行动。
就是这样! 我们运行我们的智能体经历许多episode,经历许多𝑠𝑡→𝑎𝑡→𝑠𝑡+1 转换和奖励,就像这样,我们最终学习到一个好的 Q 函数(从而获得一个好的策略)。 当然,现在有很多小细节和调整可以使其在实践中发挥作用,但我们稍后会讨论这些。
5、FrozenLake 中的 Q-learning
FrozenLake 是一个非常简单的设置,我们称之为玩具问题。 只有 16 个状态和 4 个动作,只有 64 个可能的状态动作对 (16x4=64),如果我们考虑到目标和情节结束时的漏洞,则数量会更少(但为了简单起见,我们不会这样做)。
通过这几个状态-动作对,我们实际上可以以表格的形式解决这个问题。 让我们建立一个 Q 表,并将所有状态-动作对的 Q 值初始化为零。 请注意,虽然我们可以,但在此示例中我们实际上并不需要 PyTorch; PyTorch 的 autograd 和神经网络库在这里是不必要的,因为我们只会修改数字表。 相反,我们将使用 Numpy 数组来存储 Q 表:
import numpy as np
#Initialize table with all zeros to be uniform
Q = np.zeros([env.observation_space.n, env.action_space.n])我们要设置的一些超参数:
- alpha:Q 函数的学习率
- gamma:未来奖励的折扣率
- num_episodes:我们的代理将学习的情节数(从开始到目标/洞的轨迹)
我们还将把奖励存储在一个名为 rs 的数组中:
# Learning parameters
alpha = 0.1
gamma = 0.95
num_episodes = 2000
# array of reward for each episode
rs = np.zeros([num_episodes])现在介绍算法本身的大部分内容。 请注意,我们将循环该过程 num_episodes 次,每次都会重置环境。 在每一步中,我们都会针对当前状态采取具有最高 Q 值的操作,并添加一些随机性(尤其是在开始时)以鼓励探索。 在每个动作之后,我们都会根据所经历的奖励和下一个最佳动作贪婪地更新我们的 Q 表。 我们还确保更新我们的状态、冲洗并重复。 我们继续在一个情节中采取行动,直到它完成为止,并存储该情节的最终总奖励:
for i in range(num_episodes):
# Set total reward and time to zero, done to False
r_sum_i = 0
t = 0
done = False
#Reset environment and get first new observation
s = env.reset()
while not done:
# Choose an action by greedily (with noise) from Q table
a = np.argmax(Q[s,:] + np.random.randn(1, env.action_space.n)*(1./(i/10+1)))
# Get new state and reward from environment
s1, r, done, _ = env.step(a)
# Update Q-Table with new knowledge
Q[s,a] = (1 - alpha)*Q[s,a] + alpha*(r + gamma*np.max(Q[s1,:]))
# Add reward to episode total
r_sum_i += r*gamma**t
# Update state and time
s = s1
t += 1
rs[i] = r_sum_i我们做得怎么样? 让我们看看我们保存的奖励。 我们可以绘制奖励与情节数的关系图,希望我们能看到随着时间的推移有所增加。 RL 性能可能非常嘈杂,所以让我们绘制一个移动平均值:
## Plot reward vs episodes
import matplotlib.pyplot as plt
# Sliding window average
r_cumsum = np.cumsum(np.insert(rs, 0, 0))
r_cumsum = (r_cumsum[50:] - r_cumsum[:-50]) / 50
# Plot
plt.plot(r_cumsum)
plt.show()结果如下:
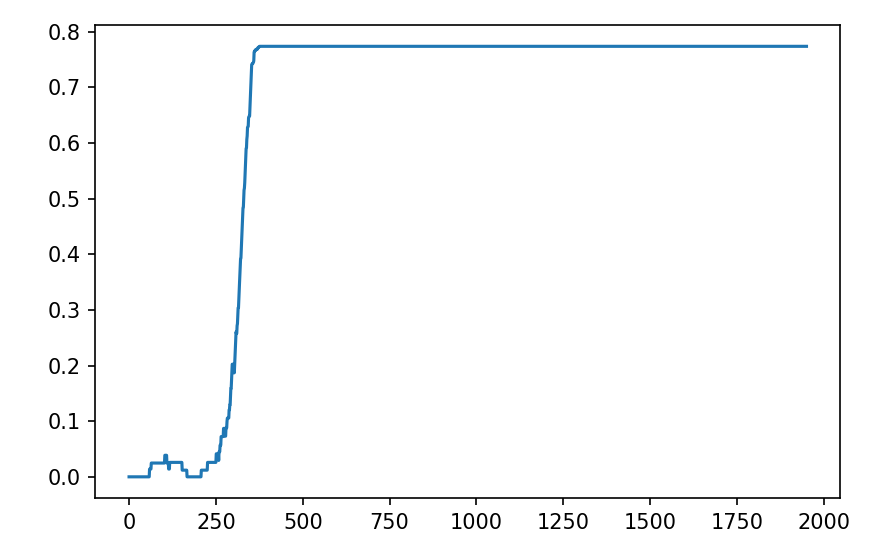
不错。 我们可能还对我们的代理实际达到目标的频率感兴趣。 这不会考虑代理到达那里的速度(这可能也很有趣),但现在让我们忽略它。 为了防止我们被数据点淹没,让我们将这些值分成 10 个区间,打印出每个区间有多少个情节导致找到目标:
# Print number of times the goal was reached
N = len(rs)//10
num_Gs = np.zeros(10)
for i in range(10):
num_Gs[i] = np.sum(rs[i*N:(i+1)*N] > 0)
print("Rewards: {0}".format(num_Gs))结果如下:
Rewards: [ 18. 185. 200. 200. 200. 200. 200. 200. 200. 200.]当我们的 RL 代理的移动是确定性的时,它在冰湖中的导航确实做得很好,但毕竟,这应该是冰湖,所以如果湖面不滑,乐趣在哪里呢? 让我们回到原来的环境,看看智能体是怎么做的:
env = gym.make('FrozenLake-v0')
#Initialize table with all zeros to be uniform
Q = np.zeros([env.observation_space.n, env.action_space.n])
# Learning parameters
alpha = 0.1
gamma = 0.95
num_episodes = 2000
# array of reward for each episode
rs = np.zeros([num_episodes])
for i in range(num_episodes):
# Set total reward and time to zero, done to False
r_sum_i = 0
t = 0
done = False
#Reset environment and get first new observation
s = env.reset()
while not done:
# Choose an action by greedily (with noise) from Q table
a = np.argmax(Q[s,:] + np.random.randn(1, env.action_space.n)*(1./(i/10+1)))
# Get new state and reward from environment
s1, r, done, _ = env.step(a)
# Update Q-Table with new knowledge
Q[s,a] = (1 - alpha)*Q[s,a] + alpha*(r + gamma*np.max(Q[s1,:]))
# Add reward to episode total
r_sum_i += r*gamma**t
# Update state and time
s = s1
t += 1
rs[i] = r_sum_i
## Plot reward vs episodes
# Sliding window average
r_cumsum = np.cumsum(np.insert(rs, 0, 0))
r_cumsum = (r_cumsum[50:] - r_cumsum[:-50]) / 50
# Plot
plt.plot(r_cumsum)
plt.show()
# Print number of times the goal was reached
N = len(rs)//10
num_Gs = np.zeros(10)
for i in range(10):
num_Gs[i] = np.sum(rs[i*N:(i+1)*N] > 0)
print("Rewards: {0}".format(num_Gs))输出如下:
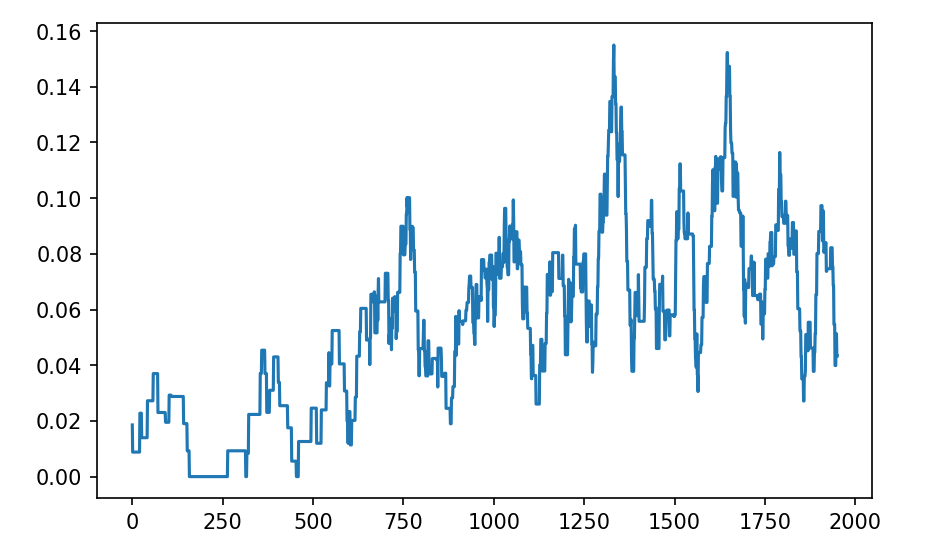
Rewards: [ 8. 3. 11. 24. 29. 31. 39. 31. 44. 33.]困难得多。 然而,我们可以看到该模型最终确实学到了一些东西。
6、强化学习中的 PyTorch
虽然前面的示例既有趣又简单,但它明显缺乏 PyTorch 的任何提示。
我们可以使用 PyTorch Tensor 来存储 Q 表,但这并不比使用 NumPy 数组更好。 PyTorch 的真正实用性来自于构建神经网络并自动计算/应用梯度,而学习 Q 表不需要这些。
6.1 连续域
在前面的例子中,我们提到,只有 16 个离散状态和 4 个动作/状态,Q 表只需要保存 64 个值,这是非常易于管理的。 但是,如果状态或动作空间是连续的怎么办? 你可以将其离散化,但随后必须选择一个解决方案,并且你的状态操作空间可能会呈指数级爆炸。 将这些分箱状态或操作视为完全不同的状态也忽略了两个连续的分箱在所需策略中可能非常相似。 你可以学会这些关系,但这样做效率极低。
那么,与其学习 Q 表,也许 Q 函数会更合适。 该函数将状态和动作作为输入,并返回 Q 值作为输出。 Q 函数可能非常复杂,但正如我们过去几天了解到的那样,神经网络非常灵活并且适合逼近任意函数。 Deep Q Networks 就采用了这样的方法。
6.2 Cart Pole问题
接下来我们看一下Cart Pole问题。 在这种情况下,我们将一根杆子连接到推车上的铰链上,目标是尽可能长时间地保持杆子垂直,而不是沿着轨道移动太远。 由于重力的原因,除非推车正好位于杆的重心下方,否则杆将会掉落。 为了防止杆子掉落,代理可以向小车施加 +1 或 -1 的力,以使其沿着轨道左右移动。 对于杆保持垂直的每个时间戳,代理都会收到 +1 的奖励; 当杆子与垂直方向倾斜超过 15 度或小车移动距离中心超过 2.4 个单位时,游戏结束。 我们将获得 +200 的奖励称为“成功”; 换句话说,代理需要在 200 个周期内避免上述故障情况。
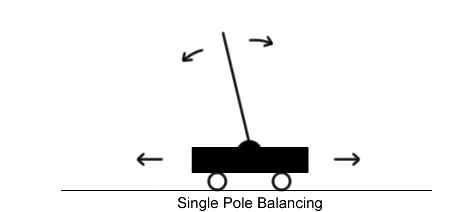
首先,让我们创建一个Cart Pole环境的实例:
env = gym.make('CartPole-v0')同样,我们可以查看该环境的 observation_space。 也与 FrozenLake 类似,由于此版本的车杆是 MDP(与 POMDP 相对),因此观察就是状态本身。 我们可以看到,小车杆的状态有 4 个维度,分别对应于[小车位置、小车速度、杆角度、杆角速度]。 重要的是,请注意这些状态是连续值:
env.observation_space我们也可以再次查看它们的 action_space。 在cart pole问题中,代理可以执行两种操作:[向左施加力,向右施加力]。 我们可以通过检查 action_space 属性来看到这一点:
env.action_space重置环境返回我们的第一个观察结果,我们可以看到它有 4 个值,对应于前面提到的 4 个状态变量:
env.reset()在开始任何强化学习之前,让我们看看如何在环境中执行操作:
done = False
while not done:
env.render()
action = env.action_space.sample()
_, _, done, _ = env.step(action)好吧,显然在每个时间步选择随机动作并不能真正实现我们保持杆子垂直的目标。 我们需要更智能的东西。
让我们关闭渲染窗口。 我们用 close() 来做到这一点。 请注意,Gym渲染可能有点挑剔,尤其是在 Windows 上; 可能需要 close() 或重新启动 Jupyter 内核才能关闭渲染的窗口:
env.close()Cart Pole实际上是一个相当简单的问题(维度非常低),因此有更简单的方法可以做到这一点,但由于我们在深度学习中获得了很多乐趣,所以让我们使用神经网络。 具体来说,让我们构建一个使用 Q 学习来学习如何平衡杆子的 DQN。 我们将为 DQN 代理提供 1000 个情节,以尝试达到 200 个得分的目标。
使这些模型正常工作需要很多小细节,因此我们不逐一进行介绍,而是完整的代码:
# Based on: https://gym.openai.com/evaluations/eval_EIcM1ZBnQW2LBaFN6FY65g/
from collections import deque
import random
import math
import gym
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
class DQN(nn.Module):
def __init__(self):
super().__init__()
self.fc1 = nn.Linear(4, 24)
self.fc2 = nn.Linear(24, 48)
self.fc3 = nn.Linear(48, 2)
def forward(self, x):
x = self.fc1(x)
x = F.relu(x)
x = self.fc2(x)
x = F.relu(x)
x = self.fc3(x)
return x
class DQNCartPoleSolver:
def __init__(self, n_episodes=1000, n_win_ticks=195, max_env_steps=None, gamma=1.0, epsilon=1.0, epsilon_min=0.01, epsilon_log_decay=0.995, alpha=0.01, alpha_decay=0.01, batch_size=64, monitor=False, quiet=False):
self.memory = deque(maxlen=100000)
self.env = gym.make('CartPole-v0')
if monitor: self.env = gym.wrappers.Monitor(self.env, '../data/cartpole-1', force=True)
self.gamma = gamma
self.epsilon = epsilon
self.epsilon_min = epsilon_min
self.epsilon_decay = epsilon_log_decay
self.alpha = alpha
self.alpha_decay = alpha_decay
self.n_episodes = n_episodes
self.n_win_ticks = n_win_ticks
self.batch_size = batch_size
self.quiet = quiet
if max_env_steps is not None: self.env._max_episode_steps = max_env_steps
# Init model
self.dqn = DQN()
self.criterion = torch.nn.MSELoss()
self.opt = torch.optim.Adam(self.dqn.parameters(), lr=0.01)
def get_epsilon(self, t):
return max(self.epsilon_min, min(self.epsilon, 1.0 - math.log10((t + 1) * self.epsilon_decay)))
def preprocess_state(self, state):
return torch.tensor(np.reshape(state, [1, 4]), dtype=torch.float32)
def choose_action(self, state, epsilon):
if (np.random.random() <= epsilon):
return self.env.action_space.sample()
else:
with torch.no_grad():
return torch.argmax(self.dqn(state)).numpy()
def remember(self, state, action, reward, next_state, done):
reward = torch.tensor(reward)
self.memory.append((state, action, reward, next_state, done))
def replay(self, batch_size):
y_batch, y_target_batch = [], []
minibatch = random.sample(self.memory, min(len(self.memory), batch_size))
for state, action, reward, next_state, done in minibatch:
y = self.dqn(state)
y_target = y.clone().detach()
with torch.no_grad():
y_target[0][action] = reward if done else reward + self.gamma * torch.max(self.dqn(next_state)[0])
y_batch.append(y[0])
y_target_batch.append(y_target[0])
y_batch = torch.cat(y_batch)
y_target_batch = torch.cat(y_target_batch)
self.opt.zero_grad()
loss = self.criterion(y_batch, y_target_batch)
loss.backward()
self.opt.step()
if self.epsilon > self.epsilon_min:
self.epsilon *= self.epsilon_decay
def run(self):
scores = deque(maxlen=100)
for e in range(self.n_episodes):
state = self.preprocess_state(self.env.reset())
done = False
i = 0
while not done:
if e % 100 == 0 and not self.quiet:
self.env.render()
action = self.choose_action(state, self.get_epsilon(e))
next_state, reward, done, _ = self.env.step(action)
next_state = self.preprocess_state(next_state)
self.remember(state, action, reward, next_state, done)
state = next_state
i += 1
scores.append(i)
mean_score = np.mean(scores)
if mean_score >= self.n_win_ticks and e >= 100:
if not self.quiet: print('Ran {} episodes. Solved after {} trials ✔'.format(e, e - 100))
return e - 100
if e % 100 == 0 and not self.quiet:
print('[Episode {}] - Mean survival time over last 100 episodes was {} ticks.'.format(e, mean_score))
self.replay(self.batch_size)
if not self.quiet: print('Did not solve after {} episodes 😞'.format(e))
return e
if __name__ == '__main__':
agent = DQNCartPoleSolver()
agent.run()
agent.env.close()强化学习可能有点噪音。 从某种意义上说,这取决于你的智能体“幸运”地采取了正确的行为,以便它可以从中学习,有时一个人可能会陷入困境。 即使你的智能体未能“解决”问题(即达到 200 个刻度),仍然应该看到平均生存时间随着智能体经历更多的事件而不断攀升。 你可能需要重新运行学习几次才能使代理达到 200 个刻度。
原文链接:Introduction to Reinforcement Learning (RL) in PyTorch
BimAnt翻译整理,转载请标明出处





