
NSDT工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器 - REVIT导出3D模型插件 - 3D模型语义搜索引擎 - AI模型在线查看 - Three.js虚拟轴心开发包 - 3D模型在线减面 - STL模型在线切割 - 3D道路快速建模
Stability AI 最近于 2023 年 11 月 21 日推出了其最新模型—稳定视频扩散(SVD)。视频生成模型的这一突破取决于数据管理的关键作用。 除了模型检查点之外,他们还发布了一份技术报告。 让我们在 Stability AI 的技术报告和一些引人注目的示例视频的指导下,深入探讨这种新的视频数据管理方法。
由于本报告的研究结果侧重于数据管理部分,因此它们可以与其他正在进行的专注于模型架构或训练和推理方法的研究相结合,例如几天前发布的 Make Pixels Dance, 2023。
1、为什么数据管理至关重要?
在人工智能中,数据质量往往胜过数量。 Stability AI 的研究强调对高质量数据的需求,消除质量较差的数据以提高模型性能。 他们报告的图 3b 就是一个引人注目的例子。 在这里,与更大的随机采样集相比,小四倍但精心策划的数据集因其准确性和整体质量而受到青睐。
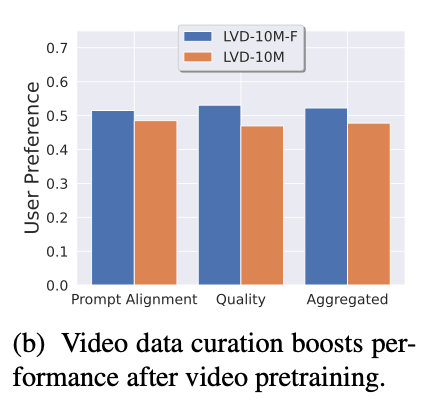
LVD-10M 包含 1000 万个随机二次采样视频,而 LVD-10M-F 包含约 250 万个精选视频。 尽管精选集小了 4 倍,但用户研究表明,就即时对齐和质量而言,用户更喜欢根据精选数据训练的模型。
让我们深入探讨他们如何能够如此出色地管理视频数据的关键组成部分!
2、视频数据管理:关键组成部分
稳定视频扩散技术报告描述了以下五个关键组件作为其视频数据管理管道的一部分:
- 检测场景切换:为了避免用包含多个场景的编辑视频误导人工智能,采用了一种检测和分离场景切换的机制。 这确保了训练中准确的场景描述。
- 合成字幕:利用 Google Research 的 CoCa 模型,为视频剪辑生成字幕,这对于生成文本条件视频至关重要。
- 使用光流进行运动检测:该技术捕获视频剪辑中的运动,这是过滤静态视频的重要方面。
- 使用 OCR 进行文本覆盖检测:识别并删除具有过多文本覆盖的剪辑,使训练重点保持在视频内容而不是文本干扰上。
- 基于 CLIP 的评分:评估美学吸引力和文本图像对齐,进一步细化数据集。

现在我们将浏览各个组件并详细解释它们。
3、检测场景切换
处理来自网络的视频时,很可能会得到经过编辑并包含多个合并在一起的剪辑的视频。 想象一个电影场景,镜头从一个演员跳到另一个演员。 场景剪切本身并不坏,但是我们在生成模型的训练过程中必须妥善处理它们。 我们想要防止的情况是,我们将多个剪辑视为单个剪辑,因为它们都是同一视频的一部分。 这可能会导致单个标题描述完全不同的场景(想想这个失败的视频剪辑)。 我们的模型在训练过程中会感到困惑,因为它必须根据不相关的标题生成几个不同的场景。

为了缓解这个问题,稳定视频扩散提出了一种机制来检测场景剪切并将它们视为处理管道中的单独剪辑。
报告中实施的剪切检测的一个重要部分是它的“级联”。 以不同的帧速率运行检测器还有助于捕获“缓慢”的变化,例如在过渡期间混合两个剪辑时。
4、合成字幕
为了生成以文本为条件的视频,我们需要描述视频剪辑内容的字幕或摘要来训练我们的模型。 作者使用 CoCa, 2022 为每个剪辑的中间帧创建字幕。
CoCa 是 Google Research 的一篇论文,基于 CLIP 等方法。 Clip 训练图像和单独的文本编码器以将图像-文本对放入同一嵌入空间中,而 CoCa 还尝试仅基于图像特征重建原始标题。 将此视为 CLIP + 字幕损失。 CLIP 不能用于获取图像的标题。 我们需要向后遍历模型(从图像嵌入到文本输入)。
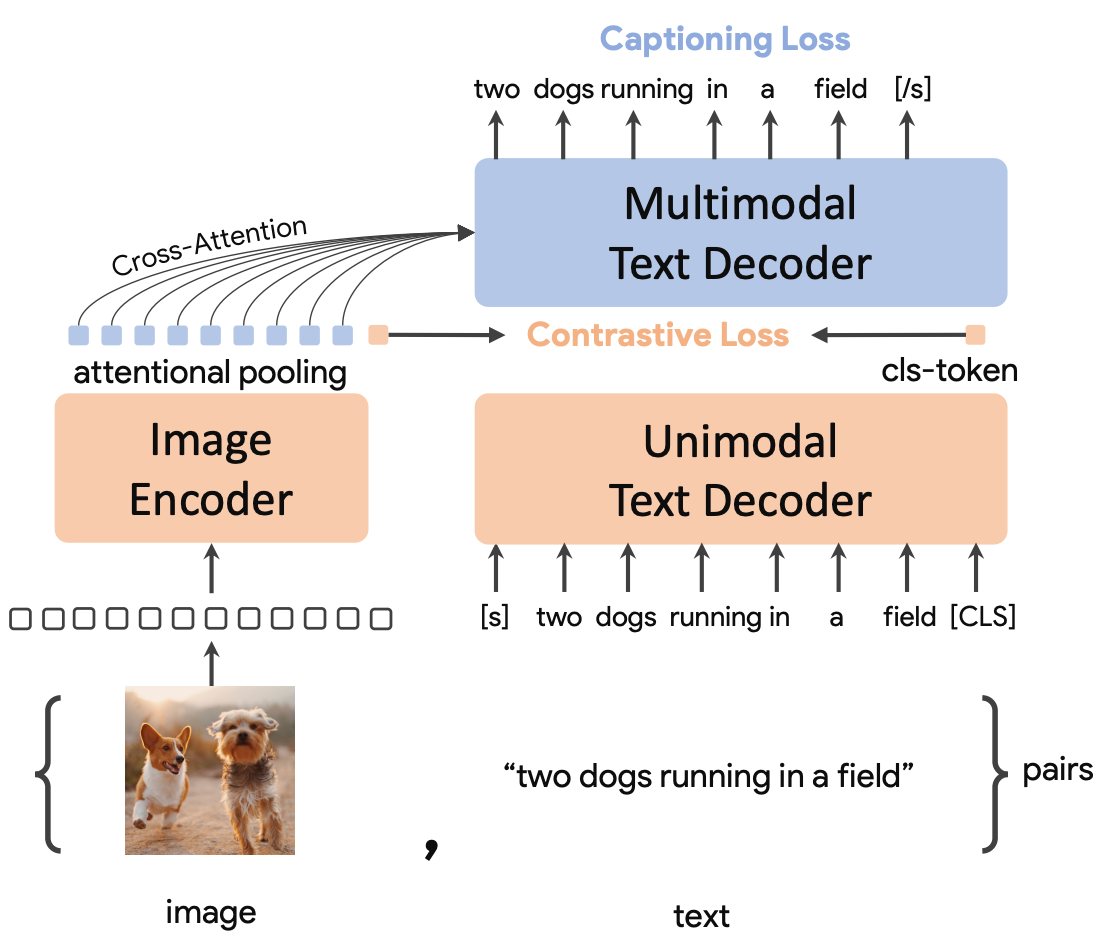
另一方面,经过训练的 CoCa 模型可以使用额外的文本解码器来创建字幕。 由于 CoCa 在单帧上工作,Stable Video Diffusion 的作者还使用 VideoBLIP(修改后的 BLIP-2 代码)为第一帧、中间帧和最后一帧创建附加字幕。
最后,作者使用未进一步定义的 LLM 来获取两个摘要(CoCa 和 VideoBLIP)并为每个视频剪辑创建最终摘要标题。
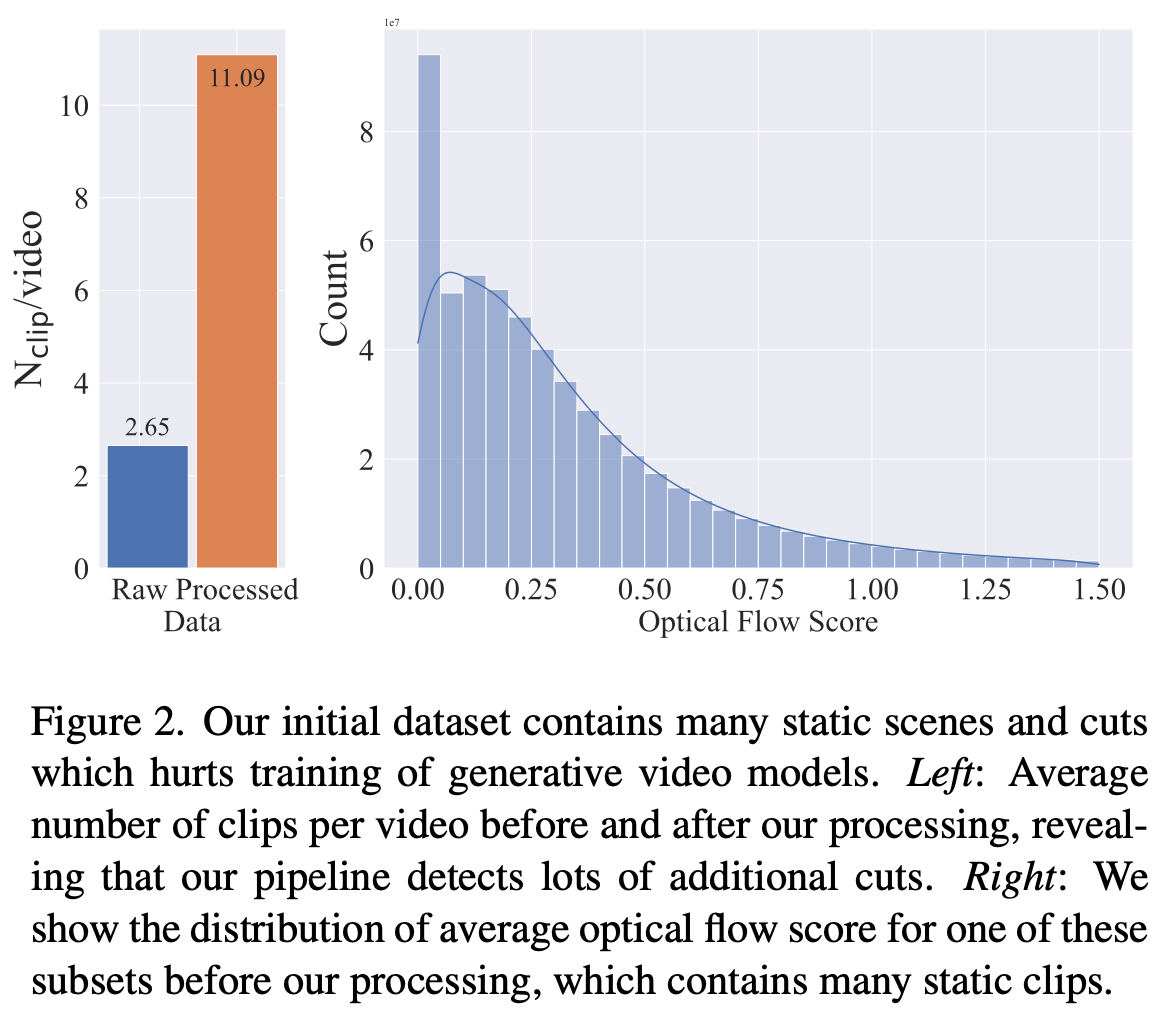
6、检测静态视频
网络上充斥着基本上是带有音轨的静态图像的视频。 YouTube 上的许多视频剪辑,例如这个示例(时间碎片 — Ben Böhmer),显示的是没有任何运动的静态图像:

训练集中包含静态视频的另一个问题是,我们的模型可能无法决定何时生成运动视频以及何时生成静态视频。

检测视频中的运动的一种简单方法是检查像素在帧与帧之间的变化量。 光流是解决这一挑战的相关研究领域。 光流方法尝试表示框架各部分的运动。 在稳定视频扩散报告中,作者计算了两帧之间的平均运动。 这使我们能够计算每个视频剪辑的平均运动量分数。
7、标题相似性和美感
为了进一步改进数据集,稳定视频扩散使用字幕的 CLIP 嵌入(合成字幕步骤中 LLM 的输出)以及第一个、中间和最后一个视频帧。 标题和帧之间的相似性用于验证它们是否匹配。 附加的美学分数用于分类帧是否符合视觉美学。 分数是通过在 CLIP 特征之上拟合线性层获得的,如 LAION-5B 论文中所述。
8、文本检测
来自网络的视频可能包含大量文本叠加。 如果在字幕过程中没有明确捕获该文本,则可能会干扰训练过程。 作者决定删除超过一定文本内容阈值的视频剪辑。 为此,他们使用了一个名为 CRAFT 的现成文本检测器,并在每个视频剪辑的第一帧、中间帧和最后一帧上运行它。

9、结束语
稳定视频扩散论文强调了视频生成领域中生成模型的数据管理的重要性。 论文中概述的结果与其他论文以及我们自己的实验的结果相匹配,我们在这里进行了总结。
原文链接:Data Curation Demystified for Stable Video Diffusion
BimAnt翻译整理,转载请标明出处





