
NSDT工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器 - REVIT导出3D模型插件 - 3D模型语义搜索引擎 - AI模型在线查看 - Three.js虚拟轴心开发包 - 3D模型在线减面 - STL模型在线切割 - 3D道路快速建模
数据是目前深度学习的主要限制因素。 好的数据很难获得。 收集和标记数据是一项艰苦的体力劳动。 这是昂贵、耗时且困难的。
AI获胜者并不是有最好算法的人,而是有最多数据的人。 -安德鲁·吴
此问题的一个“次优”解决方案是以编程方式生成合成数据。 合成数据无疑不如真实世界的数据。 然而,在缺乏或缺乏真实数据的情况下,它是最好的选择。
本文是用OpenCV编程生成合成数据,更简单的方法是用UnrealSynth这个基于UE5开发的合成数据生成器,效果更逼真,而且无需编程:
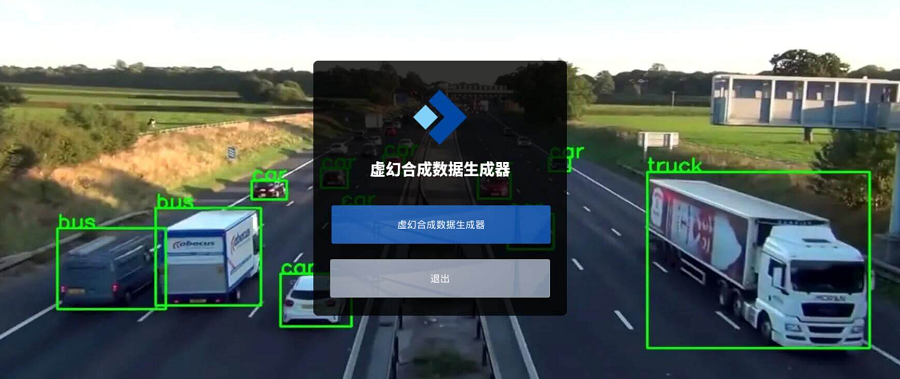
1、项目介绍
在本文中,我将使用 detectorron2 构建一个对象检测模型,用于检测招牌上的英语和阿拉伯语文本。
通常,要构建多类对象检测模型,每个类需要大约 300 个训练图像。 通过批量下载图像并手动标记它们来创建这样的数据集大约需要 6 小时的手动工作。 这可能会给我们带来最好的结果。 出于实验目的,我决定不采用这种方法。 相反,我以编程方式创建一个合成数据集。
合成数据集包括带有一些英语或阿拉伯语文本的矩形或圆形“标志板”,随机放置在背景图像上。 文本的边界框坐标也可用于每个图像。

2、模型训练方法
我的模型训练方法如下:
- 创建包含阿拉伯语和英语文本的图像和边界框坐标的综合数据集。
- 在合成数据集上训练 Faster RCNN 模型
- 收集一些现实生活中的英语和阿拉伯语标牌示例并评估模型
3、合成数据集的生成
创建合成数据集涉及的步骤如下:
- 选择招牌形状
- 选择阿拉伯语和英语短语 — 随机选择 1-4 个单词并组成短语
- 创建招牌 - 选择招牌上的字体、文本位置
- 选择纹理——在招牌上叠加纹理
- 选择背景图片
- 选择比例、旋转、将图像放置在背景上

经过以上步骤得到的结果图像如下所示:

3、用合成数据训练R-CNN
Facebook 的 detectorron2 包可用于快速训练和评估对象检测模型。 查看 github 上的训练脚本以了解完整实施。
4、评估训练好的R-CNN模型
在一些真实图像上评估模型:

对于这个小型评估来说,这似乎做得相当不错。
尽管合成数据明显是粗糙的、仓促拼凑的并且明显是假的,但该模型仍然设法从中学习基本的文本本地化。 它能够检测我们测试的真实图像中的文本并正确对它们进行分类。
请注意,我没有遵循任何科学方法来确保这些结果的公正性或统计相关性。 这不是一项学术研究,只是一个实践记录。 通常,合成数据用于增强和平衡现实生活数据集,而不是取代它们。
完整代码可以在我的 github 上找到。
原文链接:Generating synthetic dataset for object detection
BimAnt翻译整理,转载请标明出处





