
NSDT工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器 - REVIT导出3D模型插件 - 3D模型语义搜索引擎 - AI模型在线查看 - Three.js虚拟轴心开发包 - 3D模型在线减面 - STL模型在线切割 - 3D道路快速建模
AI技术正在不断融入我们的日常生活。人工智能的一个应用包括多模态化,例如将语言与视觉模型相结合。这些视觉语言模型可以应用于视频字幕、语义搜索等任务。
本周,我将重点介绍一种名为 TinyGPT-V(Arxiv | GitHub)的最新视觉语言模型。这种多模态语言模型之所以有趣,是因为它对于大型语言模型来说非常“小”,并且可以部署在单个 GPU 上,只需 8GB 的 GPU 或 CPU 即可进行推理。这对于最大限度地提高人工智能模型的速度、效率和成本非常重要。
我想指出的是,我不是作者,也与模型的作者没有任何关系。然而,作为一名研究人员和从业者,我认为这是人工智能领域一个值得研究的有趣发展,尤其是因为拥有更高效的模型将解锁更多应用。让我们深入研究吧!
1、问题与解决方案
多模态模型(例如视觉语言模型)在人机交互方面取得了创纪录的性能。随着这些模型的不断改进,我们可以看到公司开始在现实场景和应用中应用这些技术。
然而,许多人工智能模型,尤其是多模态模型,需要大量的计算资源来进行模型训练和推理。时间、硬件资源和资金的物理限制是研究人员和从业人员的瓶颈。
此外,这些限制目前阻碍了多模态模型部署在某些应用程序界面中,例如边缘设备。需要研究和开发量化(更小)和高性能模型来应对这些挑战。
TinyGPT-V 是一个 2.8B 参数的视觉语言模型,可以在 24GB GPU 上进行训练,并使用 8GB GPU 或 CPU 进行推理。这很重要,因为其他最先进的“较小”视觉语言模型(例如 LLaVA1.5)仍然相对“较大”(7B 和 13B 参数)。
与其他较大的视觉语言模型进行基准测试时,TinyGPT-V 在多个任务上实现了类似的性能。总之,这项工作有助于通过减少 AI 模型的计算需求同时保持性能来提高其效率。平衡这两个目标将使视觉语言模型能够直接在设备上使用,从而提供更好的用户体验,包括减少延迟和提高鲁棒性。
2、TinyGPT-V相关工作和技术
不太大的基础视觉语言模型 (VLM)
VLM 学习图像/视频与文本之间的关系,可应用于许多常见任务,例如在照片中搜索对象(语义搜索)、在视频中提问和接收答案 (VQA) 以及更多任务。LLaVA1.5 和 MiniGPT-4 是两种多模态大型语言模型,截至 2024 年 1 月,它们都是最先进的,并且比类似的 VL 基础模型相对较小。但是,这些 VLM 仍然需要大量的 GPU 使用和训练时间。例如,作者描述了 LLaVA-v1.5 13B 参数模型的训练资源,该模型使用八个 A100 GPU 和 80GB RAM 进行 25.5 小时的训练。这对希望在野外研究、开发和应用这些模型的个人和机构来说是一个障碍。
TinyGPT-V 是旨在解决此问题的最新 VLM 之一。它为视觉和语言组件使用了两个独立的基础模型:EVA 编码器用作视觉组件,而 Phi-2 用作语言模型。简而言之,EVA 可扩展到 1B 参数视觉变换模型,该模型经过预先训练以重建蒙版图像文本特征。Phi-2 是一个 2.7B 参数语言模型,在精选的合成和网络数据集上进行训练。作者能够合并这两个模型并将它们量化为总参数大小为 2.8B。
下面显示的是 TinyGPT-V 与其他具有各种视觉语言任务的 VLM 相比的性能。值得注意的是,TinyGPT-V 的表现与 BLIP-2 相似,这可能是由于从 BLIP-2 中获取的预训练 Q-Former 模块。此外,与 TinyGPT-V 相比,InstructBLIP 似乎取得了更好的性能,尽管需要注意的是,最小的 InstructBLIP 模型是用 4B 参数训练的。根据应用的不同,这种权衡对从业者来说可能是值得的,并且需要进行额外的分析来解释这种差异。
模型训练使用的数据集包括:
- GQA:真实世界的视觉推理和组合 QA
- VSR:具有空间关系的英文文本-图像对
- IconQA:使用图标图像进行视觉理解和推理
- VizWiz:从视障人士用智能手机拍摄的照片中得出的视觉查询,并补充了 10 个答案。
- HM:旨在检测模因中的仇恨内容的多模式集合。
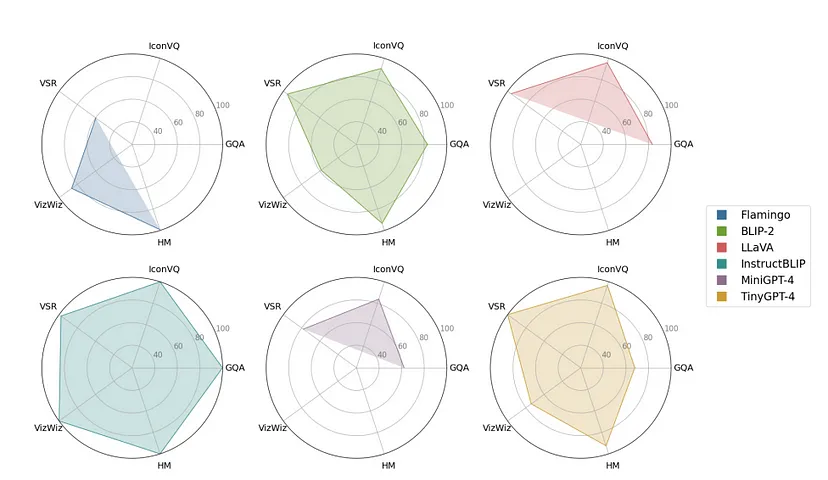
请注意,我们应该假设作者将他们的模型表示为“TinyGPT-4”。它的性能与 BLIP-2 相当,后者有 ~3.1B 个参数。InstructBLIP 在不同任务上的表现更好,但值得注意的是,它有 ~4B 个参数。这比 TinyGPT-V 要大得多,后者有 ~2.1B 个参数。
视觉和语言特征的跨模态对齐
VLM 训练由几个目标函数组成,用于优化 a) 扩展 VLM 的效用,b) 提高 VLM 的总体性能,以及 c) 降低灾难性遗忘的风险。除了不同的目标函数外,还有几种模型架构或方法来学习和合并视觉和语言特征的联合表示。我们将讨论训练 TinyGPT-V 的相关层,它们在下面以块的形式显示。

第 1 阶段是热身预训练阶段。第二阶段是训练 LoRA 模块的预训练阶段。第三训练阶段旨在对模型进行指令调整。最后,第四训练阶段旨在针对各种多模态任务对模型进行微调。
BLIP-2 论文中描述的 Q-Former 用于从对齐的图像文本数据中学习联合表示。 Q-Former 方法针对三个目标进行了优化,以学习视觉语言表示:
- 图像-文本匹配:学习图像和文本表示之间的细粒度对齐
- 图像-文本对比学习:对齐图像和文本表示以最大化获得的相互信息
- 基于图像的文本生成:训练模型以在给定输入图像的情况下生成文本
在 Q-former 层之后,他们采用了 MiniGPT-4(Vicuna 7B)中预先训练的线性投影层来加速学习。然后,他们应用线性投影层将这些特征嵌入到 Phi-2 语言模型中。
规范化
从不同模态训练较小的大规模语言模型面临着重大挑战。在训练过程中,他们发现模型输出容易受到 NaN 或 INF 值的影响。这在很大程度上归因于消失梯度问题,因为模型的可训练参数数量有限。为了解决这些问题,他们在 Phi-2 模型中应用了几种规范化程序,以确保数据具有足够的代表性以进行模型训练。
在整个 Phi-2 模型中应用了三种规范化技术,与原始实现相比略有调整。他们更新了在每个隐藏层中应用的 LayerNorm 机制,包括一个小数以实现数值稳定性。此外,他们在每个多头注意力层之后实施了 RMSNorm 作为后规范化程序。最后,他们加入了查询键规范化程序,他们认为这在低资源学习场景中很重要。
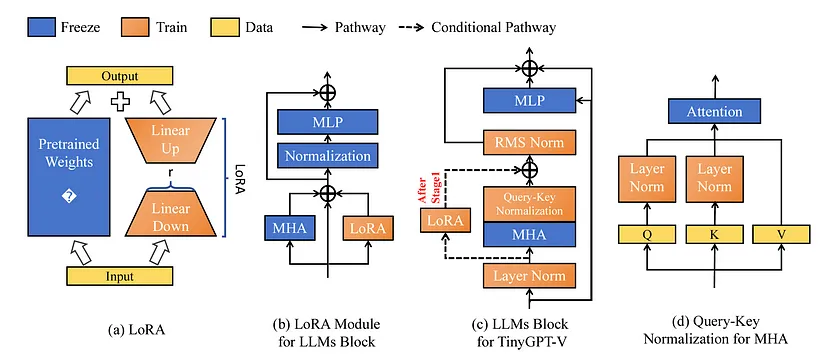
上图应用低秩自适应 (LoRA) 对 TinyGPT-V 进行微调。面板 c) 展示了如何在 TinyGPT-V 中实现 LoRA。面板 d) 展示了上一节中描述的查询键规范化方法。
3、结束语
TinyGPT-V 为提高多模态大型语言模型效率的一系列研究做出了贡献。在多个领域(例如 PEFT、量化方法和模型架构)的创新对于在不牺牲太多性能的情况下尽可能缩小模型至关重要。正如在预印本中所观察到的那样,TinyGPT-V 实现了与其他较小的 VLM 类似的性能。它与 BLIP-2 性能相匹配(最小模型有 31 亿个参数),虽然它在类似基准上的表现不如 InstructBLIP,但它的尺寸仍然较小(TinyGPT-V 有 28 亿个参数,而 InstructBLIP 有 40 亿个参数)。
对于未来的方向,肯定有一些方面可以探索以提高 TinyGPT 的性能。例如,可以应用其他 PEFT 方法进行微调。从预印本来看,尚不清楚这些模型架构决策是否纯粹基于经验性能,或者是否是为了方便实施。这应该进一步研究。
最后,在撰写本文时,预训练模型和针对指令学习进行微调的模型已经可用,而多任务模型目前是 GitHub 上的测试版本。随着开发人员和用户使用该模型,进一步的改进可以深入了解 TinyGPT-V 的其他优势和劣势。但总的来说,我认为这是一项有用的研究,有助于设计更高效的 VLM。
原文链接:Exploring “Small” Vision-Language Models with TinyGPT-V
BimAnt翻译整理,转载请标明出处





