
NSDT工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器 - REVIT导出3D模型插件 - 3D模型语义搜索引擎 - AI模型在线查看 - Three.js虚拟轴心开发包 - 3D模型在线减面 - STL模型在线切割 - 3D道路快速建模
我们知道寻找良好的图像标记和注释工具对于创建准确且有用的数据集的重要性。 随着图像注释空间的增长,我们看到开源工具的可用性激增,这些工具使任何人都可以免费标记他们的图像并从强大的功能中受益。 继续阅读,了解计算机视觉标注的 10 个最佳开源工具!
1、Label Studio
我们最喜欢的开源标注工具是 Heartex Inc. 的 Label Studio。我们最近在上一篇文章中介绍了该工具的企业版,因为它的多功能性和用于主动学习和协作的高级功能给我们留下了深刻的印象。 该工具的开源版本适用于所有类型的数据,例如音频、文本、图像、视频和时间序列。
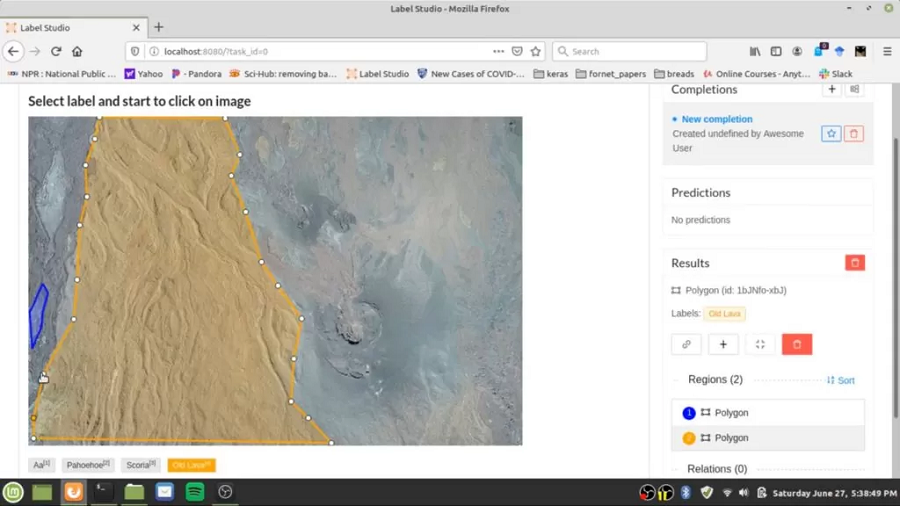
它支持广泛的标注,包括图像分类、对象检测、语义分割。 它适用于几乎所有类型的数据,例如音频、图像、文本和 HTML,并具有称为标签配置的独特配置设置,你可以在其中设计自己的自定义 UI。 它具有各种算法驱动的自动化功能,包括预标记选项,可以根据现有的机器学习模型对数据进行预标记。 最后,我们喜欢它的是它拥有一个充满活力的用户社区和一个非常活跃的 Slack 频道,你可以在其中交换提示或向团队提出请求。
2、Diffgram
此列表中的第二个平台是 Diffgram! Diffgram 之前也曾在我们喜欢的工具系列中出现过,当时它还是一个付费平台。 自 2021 年春季以来,Diffgram 已转变为完全开源平台,提供可选的付费托管服务和企业支持。 我们完全支持这一转变,并且对其扩大的影响范围感到非常兴奋。
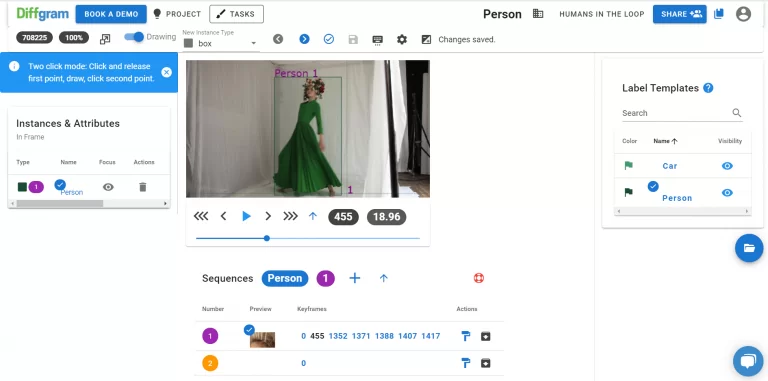
它的突出之处在于,除了作为一个标注平台之外,它还具有各种数据集和工作流管理功能。 它支持图像和视频中几乎所有类型的空间注释,包括但不限于边界框、长方体、分割、长方体和关键点。 它的语义分割功能还提供各种工具,例如自动边框、组合形状、点到全多边形等等! 此外,其视频标注支持插值和序列标记,例如事件跟踪和对象跟踪。
3、LabelIMG
LabelIMG 是另一个非常流行的开源且免费使用的图像标注工具。 事实上,它是我们在 2017 年使用的第一个标注工具,由于其简单直观的界面以及它可以离线使用以提供最大的数据安全性,它极大地方便了我们的工作。
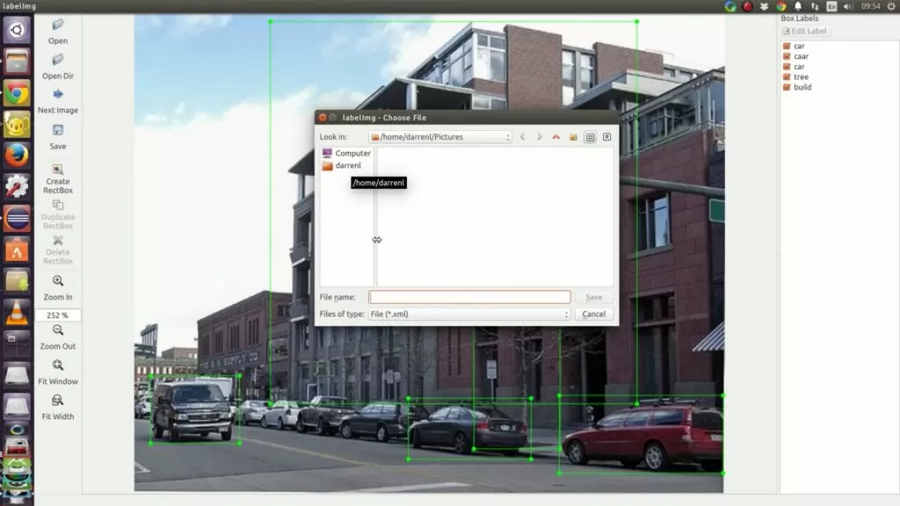
LabelIMG可以安装在几乎所有操作系统上,例如 Windows、Linux、Ubuntu 和 Mac OS,并且其 Python 库也可以在 Anaconda 或 Docker 中使用。 然而,它只支持边界框作为单独的标记方法,这就是为什么它是一个很好的第一个工具,但对于更复杂的项目来说通常可能不够。 它可以将标注保存为 PASCAL VOC 格式以及 YOLO 和 CreateML 格式的 XML 文件。
4、CVAT
CVAT(计算机视觉标注工具)是由英特尔开发的开源软件。 虽然它没有最直观的 UI,但它具有非常强大且最新的特性和功能,并且在 Chrome 中运行。 它仍然是我们和我们的客户用于标记的主要工具之一,因为它比市场上许多可用的工具要快得多。
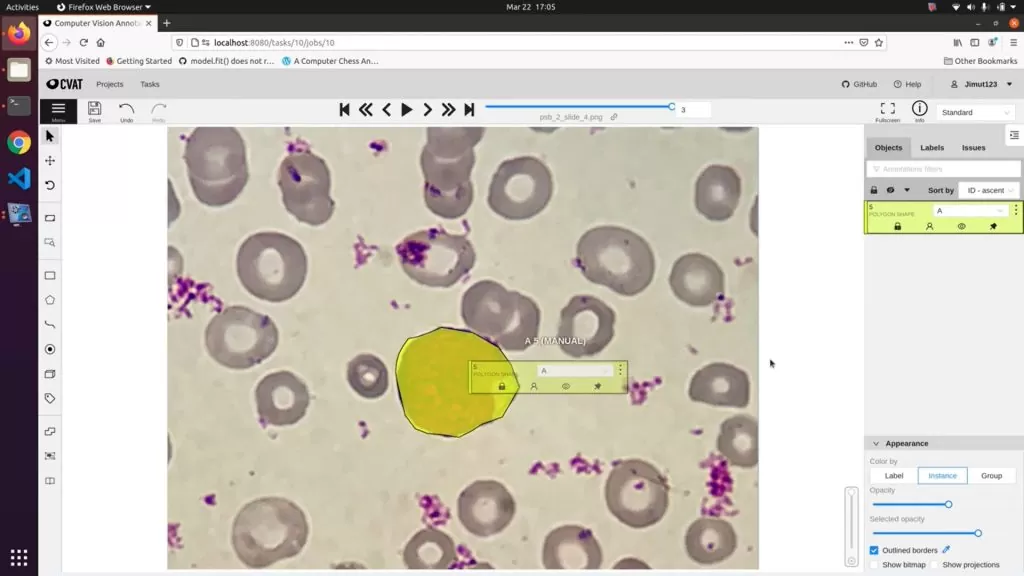
CVAT提供对象检测、图像分类、图像分割以及带有框、多边形、线条和关键点的注释。 CVAT 甚至提供各种自动化功能,例如复制和传播对象、对象跟踪和插值以及自动注释,由 TensorFlow OD API 提供支持。 在 CVAT 中协作很容易,并且可以拆分和委派工作。
5、ImageTagger
ImageTagger 是一个用于协作图像标记的开源在线平台。 该平台由汉堡大学信息学系的 Niklas Fiedler 专为机器人世界杯的需求而开发,其设计使实际的标记过程尽可能直观和快速。
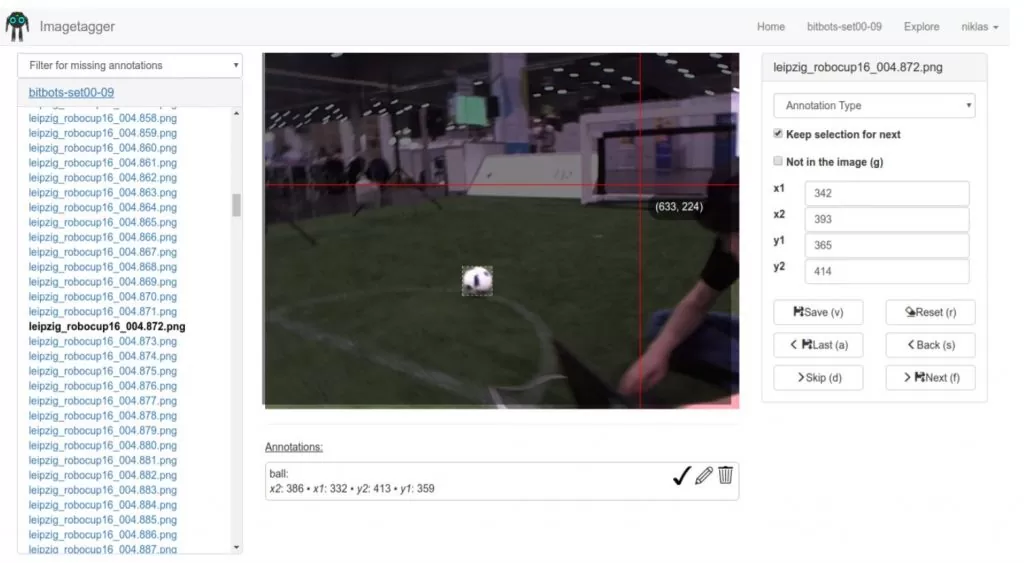
ImageTagger允许用边界框、多边形、线条和关键点来标记图像集。 它确实提供了一些有助于 QA 的项目管理选项和功能,例如图像预加载、上传现有标签和标签验证。 此外,由于它专注于协作,因此它允许通过将标记者拆分为团队来在图像集标记方面进行大规模协作。
6、LabelMe
LabelMe 是一款被认为是行业经典的开源工具。 LabelMe 由麻省理工学院于 2008 年创建,旨在构建规范的 LabelMe 数据集,可以在线或离线使用。 它可以与 Python 启动器一起在 Windows、Ubuntu 和 Mac 操作系统上运行。 LabelMe 提供带有多边形、方框、圆、直线、关键点以及语义和实例分割的图像和视频标注。
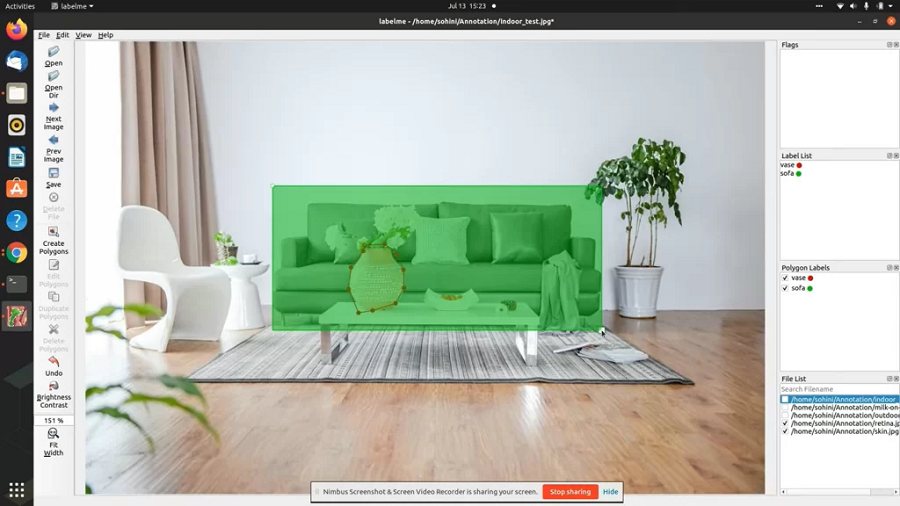
此外,它还通过图像标注工具提供分类以及清理功能,并具有可定制的用户界面。 它还允许以 VOC 和 COCO 格式导出语义和实例分割。 然而,它几乎没有项目管理功能,因为它不适用于协作标签。 相反,它与 Mechanical Turk 集成,可以轻松外包手动标签流程。
7、VCG Image Annotation
VGG Image Annotation也称为 VIA,由牛津大学视觉几何小组开发。 这是一个相当简单的注释工具,可以手动注释图像、音频和视频——它是我们仍然经常使用的最爱之一。 非常易于使用和安装,它可以在任何支持 HTML 的浏览器中用作离线应用程序。
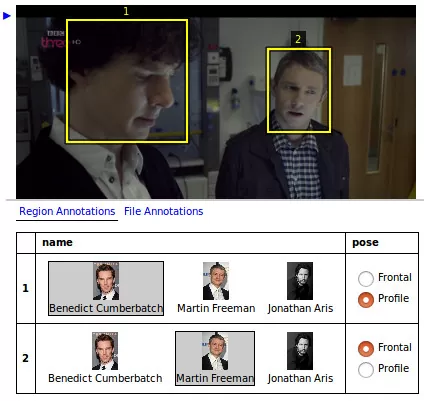
VIA 可以用方框、圆形、椭圆形、多边形、关键点和直线等形状进行标记。 VIA 支持 CSV 和 JSON 导出以及有限的项目管理功能,例如允许为注释器设置多个作业,并通过简单易用的 UI 跟踪进度。
8、Make Sense
Make Sense 是一个相对较新的开源注释平台。 Make-sense 由 Piotr Skalski 于 2019 年夏天发布,拥有令人惊叹的 UI,在标注方面没有多余的装饰,还具有额外的对象检测和图像识别功能。 首先,访问他们的网站,拖放图像,就可以立即开始注释。 他们不在线存储图像,因此不存在隐私问题。
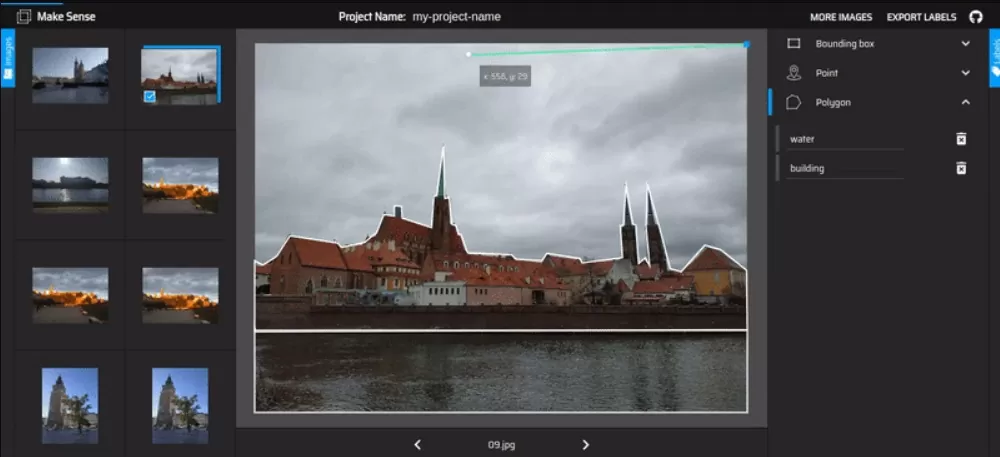
Make Sense 支持边界框、关键点、线条和多边形,甚至使用 AI 模型来自动化一些注释,例如在 COCO 数据集上预训练的 SSD 模型,以及可用于估计人的姿势和动作的 PoseNet 模型。 图像或视频中的关键主体。 目前,Make Sense 没有任何项目管理功能或 API。
9、COCO Annotator
COCO Annotator 使用 Vue.js 创建,Vue.js 是一个开源MVV前端 JavaScript 框架,用于构建用户界面和单页应用程序。 它是一种基于网络的图像分割工具,旨在帮助开发和训练对象检测、定位和关键点检测模型。

可以使用自由曲线、多边形和关键点以及其他功能来标记数据集,以标记图像片段、跟踪对象实例,甚至允许在单个实例中标记具有断开连接的可见部分的对象,同时高效存储和导出 COCO 格式的标注,因此得名。 COCO Annotator还支持使用半训练模型标注图像,并拥有 DEXTR、MaskRCNN 和 Magic Wand 等高级选择工具。 最后,它还提供了一个用户身份验证系统以确保安全。
10、Dataturks
我们的最后一个条目是一个不再更新的开源平台。 Dataturks 曾经是一项付费服务,于 2018 年被沃尔玛收购,此后Dataturks的开发已停止,现在可在 GitHub 上免费使用。 尽管在使用该软件时多次提及付费额外费用,但它是完全免费的。 它似乎已经有一段时间没有开发了,但仍然是一个可靠的开源数据标注工具。 它允许团队异步处理各种注释类型,包括图像、视频、文本和 NER。
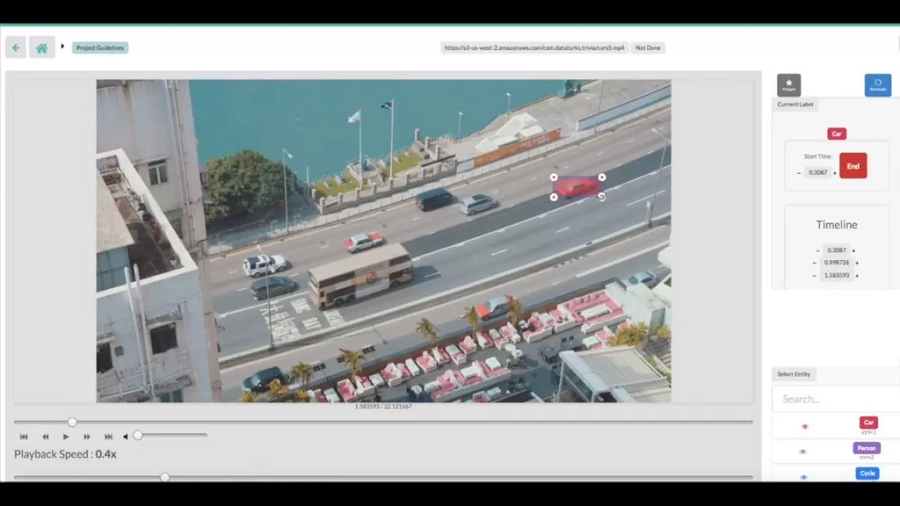
通过图像标注,它允许绘制自由形式的多边形以生成用于分割的图像掩模,并支持通过多边形标签和边界框标签进行图像分类。 它甚至具有视觉对象跟踪功能,可以在视频中的某些时间围绕对象绘制边界框,并且该工具将自动在这些点之间进行插值。 Dataturks 可以导出 VOC、Tensorflow 和 Keras 格式。
原文链接:10 of the best open-source annotation tools for computer vision
BimAnt翻译整理,转载请标明出处





