
NSDT工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器 - REVIT导出3D模型插件 - 3D模型语义搜索引擎 - AI模型在线查看 - Three.js虚拟轴心开发包 - 3D模型在线减面 - STL模型在线切割 - 3D道路快速建模
上周,一家初创公司未能围绕LLM和 RAG 开展业务,尽管他们获得了第一份 B2B 大型合同。 以下是原因以及如何避免这种情况:
创始人写了一篇博客解释了为什么他不得不关闭他的业务,我在这里总结了他的要点。
产品非常好。 那部分没问题。产品只是一个使用 GPT-4 回答用户查询的聊天应用程序。 但在回答之前,它会搜索数据库(文档、常见问题解答、产品等)并根据这些数据进行回答(是的,这只是 RAG)!
该初创公司的潜在客户旨在每月处理数十万次用户查询。 因此,这家初创公司评估了选择哪些模型。 GPT-4 为他们带来了最好的结果。 所以,创始人选择了GPT-4。
该初创公司没有选择其他开源替代方案,因为它们的测试不够好。 我不能完全同意这个结论,但对于他们的特定用例来说,这个结论很可能是正确的。 他一定处理过高度复杂的数据。 普通的开源LLM可能不适合他。
在这个阶段,这家初创公司面临着第一次现实检验。 财务现实检查。 GPT-4 太贵了!
对于每月数十万的用户查询来说,差异是每月巨大的 ChatGPT 账单。 锦上添花的是,似乎只有 GPT-4 适合这家初创公司的复杂用例。
因此,该公司很可能在评估成本提案后做出了让步。 简而言之,对于客户来说,花费巨额资金购买聊天机器人似乎不是一个可行的想法。
该初创公司未能达成合同并停止生产该产品。
故事结局。 继续阅读以获取故事链接!
但是,如果我处于他的立场并建立这家初创公司,我会记住以下 3 条规则:
1、保持对开源模型的信心

忘记 GPT-4 API,尤其是对于大量用户查询。 它只适合标记、测试和生成数据集进行微调,不能作为主模型。 技术上是最好的,但经济上不是最好的!
此外,对 Llama 2 这样的开源模型有信心。Anyscale 证明,经过微调的 Llama 2 模型在某些任务中可以优于 GPT-4。 测试您的问题并尝试看看您的微调模型是否也能优于 GPT 4! 请在此处阅读 Anyscale 的微调指南。
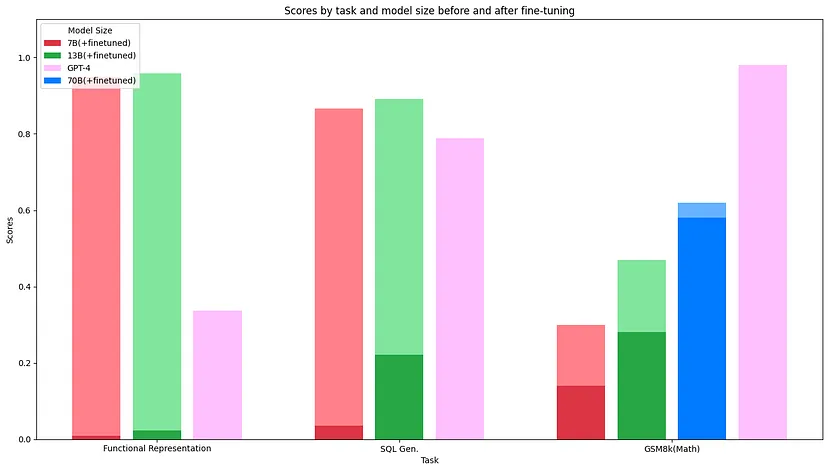
Llama-2 模型的性能增益是通过对每个任务进行微调而获得的。 每种颜色的较深阴影表示带有基线提示的 Llama-2-chat 模型的性能。 紫色显示 GPT-4 的性能,提示相同。 堆叠条形图显示了微调 Llama-2 基础模型所带来的性能增益。 在经过微调的函数表示和 SQL gen 任务中,我们可以获得比 GPT-4 更好的性能,而在数学推理等其他任务上,微调模型虽然在基础模型上有所改进,但仍然无法达到 GPT -4的性能水平。
另一方面,Anyscale 还证明,尽管两个模型的事实水平大致相同,但使用 GPT-4 进行汇总的成本仍然是 Llama-2-70b 成本的 30 倍。
为什么您对开源模型失去信心?
此外,Gradient AI 提出了一种新颖的解决方案。 这就是所谓的人工智能专家混合 (MoE) 方法! 那么它是什么。 它基本上是针对特定任务微调 Llama 2 7b 等开源模型。
例如,假设您将公司数据分为 4 类。 财务、工程、产品和运营。 现在,您可以针对 4 项任务微调 4 个模型。 每个模型都擅长完成自己的任务。
现在,当用户编写查询时,我们将尝试查找其类型。 例如,用户编写这样的查询 - 给我们推荐引擎产品的 H100 GPU 的估计数量。
最好的答案可能来自工程、产品或财务。 如果我们对前两个结果进行标准化,我们可以权衡 75% 工程和 25% 产品的答案。 我们可以通过合并这两个微调模型的响应来生成最终响应。
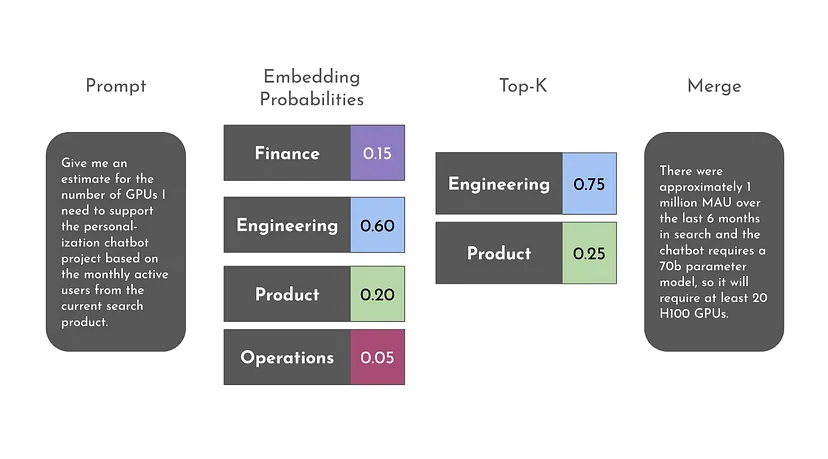
了解如何通过多个微调模型超越 GPT-4 模型。 初创公司也可以省钱。 如何?
GPT-4 的成本是 Llama-2–70b 的 18 倍! 如果我没记错的话,Llama-2–7b 比 GPT-4 便宜 30 倍。 提供 4 个经过微调的 Llama-7b 模型不会让您破产!
2、巨型人工智能模型的时代已经结束

这是萨姆·奥尔特曼说的,不是我说的。 Altman 的声明表明,GPT-4 可能是 OpenAI 使模型更大并为其提供更多数据的战略中出现的最后一个重大进步。
我先给大家讲一个故事。 在准备商学院入学考试时,我担心竞争。 我问老师,记住 GMAT 高频词汇表是否就足够了。 他说是的,但我还是担心。 如果考试中出现了不在列表中的困难词汇怎么办? 在这场竞争激烈的考试中,即使是一个分数也可能产生影响。
我的老师向我保证,说没有人能够回答这个问题。 他说我应该集中精力记住给定的高频词汇表,这就足够了。
我意识到我不能担心所有事情,所以我专注于我能控制的事情:记住一些高频 GMAT 词汇。 不试图记住一切。
我不怕练过一万种腿法的人,但我害怕一种腿法练过一万遍的人。-李小龙

因此,当这位创始人因为 GPT-4 成本高昂而其他模型性能较差而关闭他的初创公司时,这个投资回报率问题对每个人来说都是真实的,而且是无法解决的。 所以,不用担心。 没有人能够达到那么高的准确性。 你应该专注于你所拥有的。
与大多数创始人一样,您没有资金或资源来自行微调并向数十万用户提供微调后的模型。
但我虔诚地相信一件事(同样是因为同样的财务现实)。
我相信未来不在于 1 万亿个参数,而在于开源 7B 模型!
看看 Mistral 7B 或 Llama 2 7B! 但不要总是选择最新模型。 因为新模型很可能经过专门训练,在基准数据上表现最佳,但在现实生活中表现不佳。 Mistral 7B 在基准测试中比 Llama 13B 表现更好,但如果你问我哪个模型更好,我会简单地告诉你在给出任何结论性意见之前先测试一下你的用例!
我不会责怪LLM模型创建的创始人。 有的VC认为雇9个妈妈1个月就可以生个孩子! 为了保持资金流动并在 1 个月而不是 9 个月内生出婴儿,创始人将生产一些基准崩溃的糟糕模型。 甚至有一篇有趣的论文证明选择性训练数据可以优于每个模型! 谨防。
不管怎样,我也给出了足够多的例子,证明经过微调的 Llama 2 模型可以超越 GPT 4。所以,尽情测试并选择最好的开源模型和 ROI!
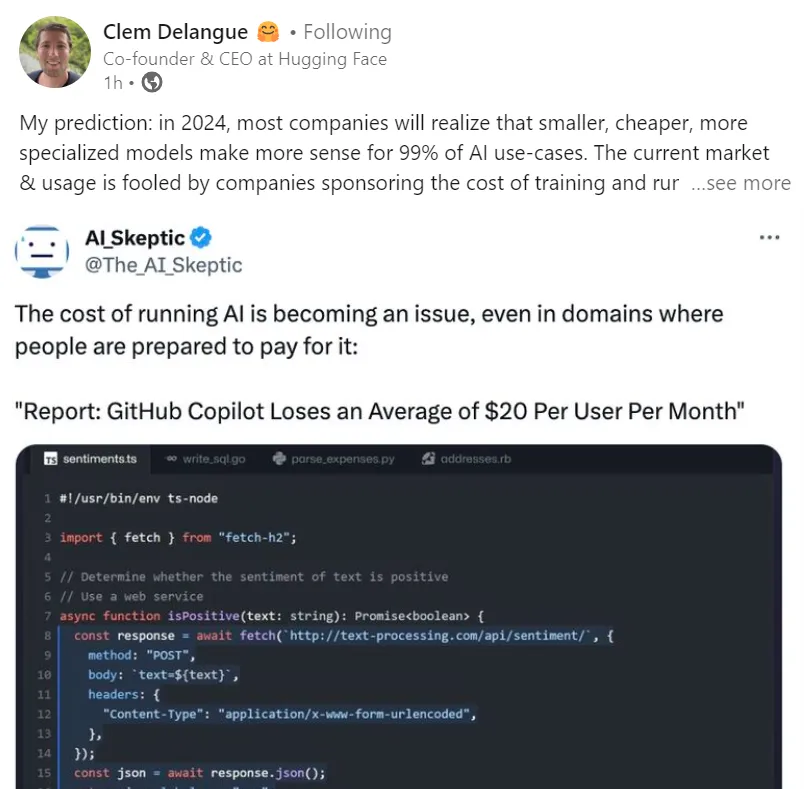
最后,Huggingface CEO的一句话证明巨型AI模型的时代已经结束了!
3、高度重视 RAG 和提示微调

我相信未来主要是 RAG,而不是微调。 同样,因为同样的财务现实!
GPT 3.5 微调已于上个月推出。 GPT 4 也将很快提供同样的功能。 但我不相信他们实际上是根据你的数据进行微调。 在这种规模上这根本不可能。 他们可能正在使用一种称为提示调整的技术。
我们可以通过及时调整来完成此任务。 一篇名为“P-Tuning:Prompt Tuning Can Comparable to Fine-tuning Across Scales and Tasks”的论文向我们展示了这一点。 我认为 OpenAI 并没有分享他们的研究成果!
Finetune 或多或少与新的格式和响应风格有关。 微调意味着告诉 LLM 模型以某种方式行事或执行不同的任务,而不仅仅是成为一个多面手聊天机器人。
RAG 基本上是让LLM了解您的新数据。 (即财务统计数据)
因此,我再次确信大规模微调不是未来。 RAG、很少的镜头提示、思想链提示和提示调整是未来的趋势,因为它成本更低,复杂性也更低。 历史一再告诉我们,简单的想法总是获胜! 再看看这个世界。 所有伟大的想法和生意都很简单。
我们将看到 RAG 领域的彻底创新! 记住我的话! 这家初创公司采用 RAG 的方式在开源模型中取得了糟糕的结果,这表明他们可以做得更好。
关于 RAG 的最后一句话:
- 使用 RAG 进行实验。 针对您的用例测试所有新颖的技术,例如 RAG Fusion。
- 构建一个复杂的 RAG 系统,而不是一个简单的系统。 Llama Index 方法很棒,但也可以构建适合您自己的方法。 每次都重新发明它。 这是一个艺术问题,而不是一个科学问题。
- 将所有语义搜索和领域知识投入其中。抛开 RAG 不谈,我在这里展示了理解语义搜索问题的重要性。
我甚至看到一位资深创始人在咆哮,他告诉你,你只需要RAG中的向量数据库。 如果图形数据库和关键字搜索足够结构化,有时可以产生更好的结果。 质疑现状。
4、结束语
是的,您可以围绕LLM建立可扩展且可行的业务。 大多数时候,都是大规模的。
GPT 4 是最好的,但它不可扩展或不可行。 因此,您正在尝试猜测撰写博客和数据透视的初创公司名称! 这是 Llamar.ai。 博客在这里:Llamar.ai:深入探讨 RAG 与LLM的可行性
我的看法是——可行多于不可行。 我希望其他初创公司能够通过构建可盈利且可扩展的人工智能产品来证明我是对的。
原文链接:Planning to build a business around GPT-4, think again!
BimAnt翻译整理,转载请标明出处





