
NSDT工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器 - REVIT导出3D模型插件 - 3D模型语义搜索引擎 - AI模型在线查看 - Three.js虚拟轴心开发包 - 3D模型在线减面 - STL模型在线切割 - 3D道路快速建模
在浏览 LinkedIn 时,我看到一条评论,让我意识到需要写一篇简单而富有洞察力的文章来阐明这个问题:
“尽管大肆宣传,但我找不到一位直接的 MLOps 工程师可以解释我们如何部署这些开源模型以及相关成本。” — 乌斯曼·阿夫里迪
本文旨在比较用于 LLM 推理和服务的不同开源库。 我们将通过实际部署示例探讨它们的杀手级功能和缺点。 我们将研究 vLLM、OpenLLM、Ray Serve 等框架。
本文中的信息截至 2023 年 8 月为最新信息,但请注意,此后可能会发生发展和变化。
以下是综合比较:

尽管LLM推理框架有很多,但每个框架都有其特定的目的。 以下是需要考虑的一些关键点:
- 当批量提示交付需要最大速度时,请使用 vLLM。
- 如果你需要本机 HuggingFace 支持并且不打算为核心模型使用多个适配器,请选择文本生成推理。
- 如果速度对你很重要并且你计划在 CPU 上运行推理,请考虑 CTranslate2。
- 如果你想将适配器连接到核心模型并利用 HuggingFace 代理,请选择 OpenLLM,特别是如果你不仅仅依赖 PyTorch。
- 考虑使用 Ray Serve 来实现稳定的管道和灵活的部署。 它最适合更成熟的项目。
- 如果你想在客户端(边缘计算)(例如 Android 或 iPhone 平台)本地部署 LLM,请使用 MLC LLM。
- 如果你已经拥有 DeepSpeed 库的经验并希望继续使用它来部署 LLM,请使用 DeepSpeed-MII。
对于硬件设置,我使用了单个 A100 GPU,内存容量为 40 GB。 我使用 LLaMA-1 13b 作为模型,因为列表中的所有库都支持它。
本文不会介绍用于服务深度学习模型的传统库,例如 TorchServe、KServe 或 Triton Inference Server。 尽管你可以使用这些库进行LLM的推理,但我只关注明确设计用于LLM的框架。
1、vLLM

vLLM是快速且易于使用的 LLM 推理和服务库。 它的吞吐量比 HuggingFace Transformers (HF) 高 14 倍至 24 倍,比 HuggingFace 文本生成推理 (TGI) 高 2.2 倍 - 2.5 倍。
vLLM的使用方法如下:
- 离线批量推理:
# pip install vllm
from vllm import LLM, SamplingParams
prompts = [
"Funniest joke ever:",
"The capital of France is",
"The future of AI is",
]
sampling_params = SamplingParams(temperature=0.95, top_p=0.95, max_tokens=200)
llm = LLM(model="huggyllama/llama-13b")
outputs = llm.generate(prompts, sampling_params)
for output in outputs:
prompt = output.prompt
generated_text = output.outputs[0].text
print(f"Prompt: {prompt!r}, Generated text: {generated_text!r}")- API服务:
# Start the server:
python -m vllm.entrypoints.api_server --env MODEL_NAME=huggyllama/llama-13b
# Query the model in shell:
curl http://localhost:8000/generate \
-d '{
"prompt": "Funniest joke ever:",
"n": 1,
"temperature": 0.95,
"max_tokens": 200
}'vLLM的杀手级功能包括:
- 连续批处理 - 迭代级调度,其中批大小由每次迭代确定。 由于批处理,vLLM 可以在繁重的查询负载下正常工作。
- PagedAttention — 注意力算法的灵感来自于操作系统中虚拟内存和分页的经典思想。 这是模型加速的秘诀。
虽然vLLM库提供了用户友好的特性和广泛的功能,但我遇到了一些限制:
- 添加自定义模型:虽然可以合并你自己的模型,但如果模型不使用与 vLLM 中现有模型类似的架构,则过程会变得更加复杂。 例如,我遇到了添加 Falcon 支持的 Pull 请求,这似乎非常具有挑战性。
- 缺乏对适配器(LoRA、QLoRA 等)的支持:开源 LLM 在针对特定任务进行微调时具有重要价值。 然而,在当前的实现中,没有单独使用模型和适配器权重的选项,这限制了有效利用此类模型的灵活性。
- 缺乏权重量化:有时,LLM 可能不适合可用的 GPU 内存,因此减少内存消耗至关重要。
vLLM是 LLM 推理最快的库。 由于其内部优化,它的性能显着优于竞争对手。 然而,它确实存在支持有限模型的弱点。
你可以在此处找到 vLLM 发展路线图。
2、HF文本生成推理

用于文本生成推理的 Rust、Python 和 gRPC 服务器。 在 HuggingFace 的生产中用于为LLM API 推理小部件提供支持。
HF文本生成推理的使用方法如下:
- 使用 docker 运行 Web 服务器
mkdir data
docker run --gpus all --shm-size 1g -p 8080:80 \
-v data:/data ghcr.io/huggingface/text-generation-inference:0.9 \
--model-id huggyllama/llama-13b \
--num-shard 1发送请求:
# pip install text-generation
from text_generation import Client
client = Client("http://127.0.0.1:8080")
prompt = "Funniest joke ever:"
print(client.generate(prompt, max_new_tokens=17 temperature=0.95).generated_text)HF文本生成推理的杀手级功能包括:
- 内置 Prometheus 指标 - 你可以监控服务器负载并深入了解其性能。
- 使用 flash-attention(和 v2)和分页注意力进行推理的优化转换器代码。 值得一提的是,并非所有模型都内置对这些优化的支持。 如果你使用不太常见的架构,可能会面临挑战。
3、CTranslate2

CTranslate2 是一个 C++ 和 Python 库,用于使用 Transformer 模型进行高效推理。
CTranslate2的用法如下:
首先,转换模型:
pip install -qqq transformers ctranslate2
# The model should be first converted into the CTranslate2 model format:
ct2-transformers-converter --model huggyllama/llama-13b --output_dir llama-13b-ct2 --force发送请求:
import ctranslate2
import transformers
generator = ctranslate2.Generator("llama-13b-ct2", device="cuda", compute_type="float16")
tokenizer = transformers.AutoTokenizer.from_pretrained("huggyllama/llama-13b")
prompt = "Funniest joke ever:"
tokens = tokenizer.convert_ids_to_tokens(tokenizer.encode(prompt))
results = generator.generate_batch(
[tokens],
sampling_topk=1,
max_length=200,
)
tokens = results[0].sequences_ids[0]
output = tokenizer.decode(tokens)
print(output)CTranslate2的杀手级功能包括:
- 在 CPU 和 GPU 上快速高效地执行 — 得益于一系列内置优化:层融合、填充去除、批量重新排序、就地操作、缓存机制等。推理 LLM 速度更快,需要的内存更少。
- 动态内存使用情况——内存使用情况根据请求大小动态变化,同时由于 CPU 和 GPU 上的缓存分配器仍然满足性能要求。
- 多CPU架构支持——该项目支持x86-64和AArch64/ARM64处理器,并集成了针对这些平台优化的多个后端:Intel MKL、oneDNN、OpenBLAS、Ruy和Apple Accelerate。
CTranslate2的优点包括:
- 并行和异步执行——可以使用多个 GPU 或 CPU 核心并行和异步处理多个批次。
- 提示缓存 - 模型在静态提示下运行一次,模型状态将被缓存并重用于将来使用相同静态提示的调用。
- 磁盘上的轻量级 — 量化可以使磁盘上的模型缩小 4 倍,同时将精度损失降至最低。
CTranslate2的局限性如下:
- 没有内置的 REST 服务器——尽管你仍然可以运行 REST 服务器,但我怀念拥有具有日志记录和监控功能的现成服务。
- 缺乏对适配器(LoRA、QLoRA 等)的支持。
我觉得CTranslate2这个库很有趣。 开发人员正在积极致力于此,从 GitHub 上的发布和提交可以明显看出,他们还分享有关其应用程序的信息丰富的博客文章。 该库的众多优化令人印象深刻,其主要亮点是能够在 CPU 上执行 LLM 推理。
4、DeepSpeed-MII

在 DeepSpeed 的支持下,MII 使低延迟和高吞吐量推理成为可能。
DeepSpeed-MII的用法如下:
- 运行网络服务器:
# DON'T INSTALL USING pip install deepspeed-mii
# git clone https://github.com/microsoft/DeepSpeed-MII.git
# git reset --hard 60a85dc3da5bac3bcefa8824175f8646a0f12203
# cd DeepSpeed-MII && pip install .
# pip3 install -U deepspeed
# ... and make sure that you have same CUDA versions:
# python -c "import torch;print(torch.version.cuda)" == nvcc --version
import mii
mii_configs = {
"dtype": "fp16",
'max_tokens': 200,
'tensor_parallel': 1,
"enable_load_balancing": False
}
mii.deploy(task="text-generation",
model="huggyllama/llama-13b",
deployment_name="llama_13b_deployment",
mii_config=mii_configs)发送请求:
import mii
generator = mii.mii_query_handle("llama_13b_deployment")
result = generator.query(
{"query": ["Funniest joke ever:"]},
do_sample=True,
max_new_tokens=200
)
print(result)DeepSpeed-MII的杀手级功能包括:
- 多个副本上的负载平衡 - 用于处理大量用户的非常有用的工具。 负载均衡器在各个副本之间有效分配传入请求,从而缩短应用程序响应时间。
- 非持久部署 - 一种更新不会永久应用于目标环境的方法。 在资源效率、安全性、一致性和易于管理性至关重要的场景中,这是一个有价值的选择。 它实现了更加受控和标准化的环境,同时减少了运营开销。
DeepSpeed-MII的优点:
- 不同的模型存储库——可通过多个开源模型存储库使用,例如 Hugging Face、FairSeq、EluetherAI 等。
- 量化延迟和成本降低——MII 可以显着降低非常昂贵的语言模型的推理成本。
- 本机和 Azure 集成 — Microsoft 开发的 MII 框架提供了与其云系统的出色集成。
DeepSpeed-MII的局限性:
- 缺乏官方版本——我花了几个小时才找到功能应用程序的正确提交。 文档的某些部分已过时并且不再相关。
- 模型数量有限——不支持 Falcon、LLaMA 2 和其他语言模型。 你可以运行的模型数量有限。
- 缺乏对适配器(LoRA、QLoRA 等)的支持
该项目基于可靠的 DeepSpeed 库,该库在社区中赢得了声誉。 如果你寻求稳定性和久经考验的解决方案,MII 将是一个绝佳的选择。 根据我的实验,该库表现出处理单个提示的最佳速度。 尽管如此,我建议在将框架实施到你的系统中之前,先针对你的特定任务测试该框架。
5、OpenLLM

用于在生产中操作大型语言模型 (LLM) 的开放平台。
OpenLLM的使用方法如下:
- 运行网络服务器:
pip install openllm scipy
openllm start llama --model-id huggyllama/llama-13b \
--max-new-tokens 200 \
--temperature 0.95 \
--api-workers 1 \
--workers-per-resource 1发送请求:
import openllm
client = openllm.client.HTTPClient('http://localhost:3000')
print(client.query("Funniest joke ever:"))OpenLLM的杀手级功能包括:
- 适配器支持 — 将多个适配器连接到仅一个已部署的 LLM。 试想一下,您可以仅使用一种模型来完成多项专门任务。
- 运行时实现 - 使用不同的实现:Pytorch (pt)、Tensorflow (tf) 或 Flax (flax)。
HuggingFace 代理 — 连接 HuggingFace 上的不同模型并使用 LLM 和自然语言对其进行管理。
OpenLLM的优点:
- 良好的社区支持——该库正在不断开发和添加新功能。
- 集成新模型 - 开发人员提供了有关如何添加自己的模型的指南。
- 量化 — OpenLLM 支持使用位和字节以及 GPTQ 进行量化。
- LangChain 集成 — 你可以使用 LangChian 与远程 OpenLLM 服务器交互。
OpenLLM的局限性:
- 缺乏批处理支持 - 对于大量消息流,这很可能成为应用程序性能的瓶颈。
- 缺乏内置的分布式推理——如果你想在多个 GPU 设备上运行大型模型,需要另外安装 OpenLLM 的服务组件 Yatai。
这是一个很好的框架,具有广泛的功能。 它使你能够以最少的费用创建灵活的应用程序。 虽然文档中可能未完全涵盖某些方面,但当你深入研究此库时,可能会发现其附加功能中的惊喜。
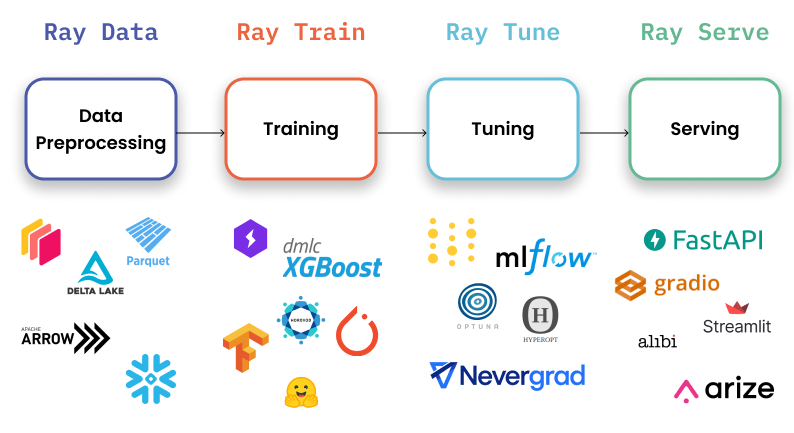
6、Ray Serve

Ray Serve 是一个可扩展的模型服务库,用于构建在线推理 API。 Serve 与框架无关,因此你可以使用单个工具包来服务深度学习模型中的所有内容。
Ray Serve的使用方法如下:
- 运行网络服务器:
# pip install ray[serve] accelerate>=0.16.0 transformers>=4.26.0 torch starlette pandas
# ray_serve.py
import pandas as pd
import ray
from ray import serve
from starlette.requests import Request
@serve.deployment(ray_actor_options={"num_gpus": 1})
class PredictDeployment:
def __init__(self, model_id: str):
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
self.model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.float16,
device_map="auto",
)
self.tokenizer = AutoTokenizer.from_pretrained(model_id)
def generate(self, text: str) -> pd.DataFrame:
input_ids = self.tokenizer(text, return_tensors="pt").input_ids.to(
self.model.device
)
gen_tokens = self.model.generate(
input_ids,
temperature=0.9,
max_length=200,
)
return pd.DataFrame(
self.tokenizer.batch_decode(gen_tokens), columns=["responses"]
)
async def __call__(self, http_request: Request) -> str:
json_request: str = await http_request.json()
return self.generate(prompt["text"])
deployment = PredictDeployment.bind(model_id="huggyllama/llama-13b")
# then run from CLI command:
# serve run ray_serve:deployment发送请求:
import requests
sample_input = {"text": "Funniest joke ever:"}
output = requests.post("http://localhost:8000/", json=[sample_input]).json()
print(output)Ray Serve的杀手级功能包括:
- 监控仪表板和 Prometheus 指标 - 可以使用 Ray 仪表板来获取 Ray 集群和 Ray Serve 应用程序状态的高级概述。
- 跨多个副本自动缩放 - Ray 通过观察队列大小并做出缩放决策来添加或删除副本来适应流量峰值。
- 动态请求批处理——当你的模型使用成本昂贵并且您希望最大限度地利用硬件时,这是必要的。
Ray Serve的优点:
- 广泛的文档——我很欣赏开发人员在这方面投入了时间并努力地进行文档创建。 你可以找到几乎每个用例的大量示例,这非常有帮助。
- 生产就绪——在我看来,这是此列表中所有框架中最成熟的框架。
- 原生 LangChain 集成 — 你可以使用 LangChian 与远程 Ray Server 进行交互。
Ray Serve的局限性:
- 缺乏内置模型优化——Ray Serve 并不专注于 LLM,它是一个用于部署任何 ML 模型的更广泛的框架。 你必须自己进行优化。
- 进入门槛高——该库有时会出现过多的附加功能,这提高了进入门槛,使新来者难以浏览和理解。
如果你需要最适合生产的解决方案,而不仅仅是深度学习,那么 Ray Serve 是一个不错的选择。 它最适合可用性、可扩展性和可观察性非常重要的企业。 此外,你可以使用其庞大的生态系统进行数据处理、培训、微调和服务。 最后,OpenAI、Shopify 和 Instacart 等公司都在使用它。
7、MLC LLM

MLC LLM 是一种通用部署解决方案,使 LLM 能够利用本机硬件加速在消费设备上高效运行。
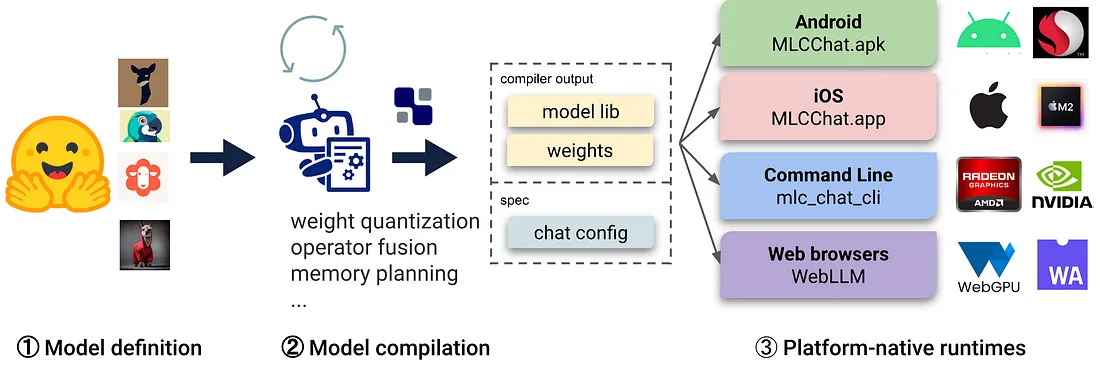
MLC LLM的使用方法如下所示:
- 运行网络服务器:
# 1. Make sure that you have python >= 3.9
# 2. You have to run it using conda:
conda create -n mlc-chat-venv -c mlc-ai -c conda-forge mlc-chat-nightly
conda activate mlc-chat-venv
# 3. Then install package:
pip install --pre --force-reinstall mlc-ai-nightly-cu118 \
mlc-chat-nightly-cu118 \
-f https://mlc.ai/wheels
# 4. Download the model weights from HuggingFace and binary libraries:
git lfs install && mkdir -p dist/prebuilt && \
git clone https://github.com/mlc-ai/binary-mlc-llm-libs.git dist/prebuilt/lib && \
cd dist/prebuilt && \
git clone https://huggingface.co/huggyllama/llama-13b dist/ && \
cd ../..
# 5. Run server:
python -m mlc_chat.rest --device-name cuda --artifact-path dist- 发送请求:
import requests
payload = {
"model": "lama-30b",
"messages": [{"role": "user", "content": "Funniest joke ever:"}],
"stream": False
}
r = requests.post("http://127.0.0.1:8000/v1/chat/completions", json=payload)
print(r.json()['choices'][0]['message']['content'])MLC LLM的杀手级功能包括:
- 平台本机运行时——部署在用户设备的本机环境上,可能没有现成的 Python 或其他必要的依赖项。 应用程序开发人员只需熟悉平台原生运行时即可将 MLC 编译的 LLM 集成到他们的项目中。
- 内存优化——你可以使用不同的技术编译、压缩和优化模型,从而将它们部署在不同的设备上。
MLC LLM的优点:
- JSON 配置中的所有设置 - 允许你在单个配置文件中定义每个编译模型的运行时配置。
- 预构建的应用程序 - 你可以为不同的平台编译模型:用于命令行的 C++、用于 Web 的 JavaScript、用于 iOS 的 Swift 和用于 Android 的 Java/Kotlin。
MLC LLM的局限性:
- 使用LLM模型的功能有限:不支持适配器、不能改变精度、没有令牌流等。该库主要专注于为不同设备编译模型。
- 仅支持分组量化——尽管这种方法已经显示出良好的结果,但其他量化方法(bitsandbytes 和 GPTQ)在社区中更受欢迎。 社区很可能会更好地开发它们。
- 安装复杂——我花了几个小时才正确安装该库。 它很可能不适合初学者开发人员。
如果你需要在 iOS 或 Android 设备上部署应用程序,这个库正是你所需要的。 它将允许你快速、本地地编译模型并将其部署到设备。 但是,如果你需要高负载的服务器,我不建议选择这个框架。
8、要点
选择一个明确的最爱对我来说是一个挑战。 每个库都有其独特的优点和缺点。 LLM仍处于发展的早期阶段,因此还没有可遵循的单一标准。 我鼓励你以我的文章为基础,选择最适合自己需求的工具。
我没有涉及模型推理成本的主题,因为它们根据你的 GPU 供应商和模型使用情况而有很大差异。 但是,可以在下面的奖励部分找到一些有用的成本削减资源。
在我的实验过程中,我使用了一些对你也有用的服务和库:
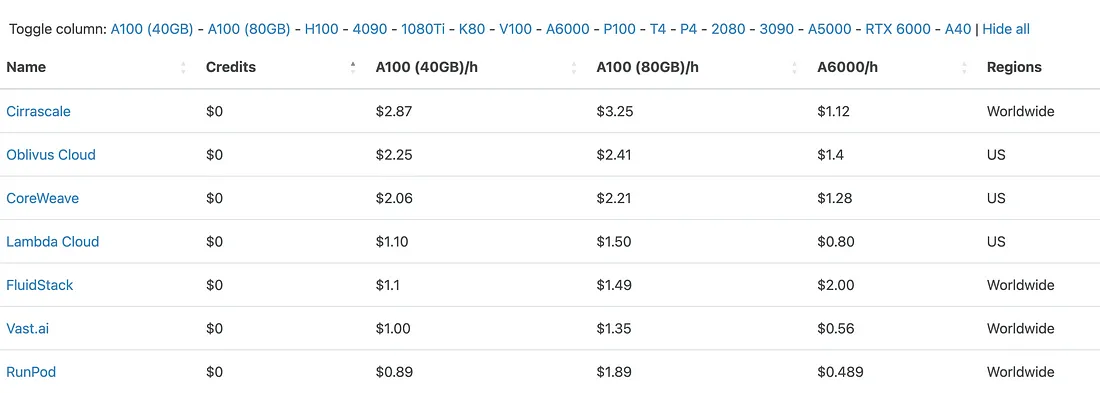
- 云 GPU 比较:在这里,你可以找到不同提供商提供的带有 GPU 的服务器的最优惠价格。
- dstack:允许你配置 LLM 推理所需的环境并使用单个命令启动它。 对我来说,这有助于减少闲置 GPU 服务器的开支。 以下是部署 LLaMA 的速度的示例:
type: task
env:
- MODEL=huggyllama/llama-13b
# (Optional) Specify your Hugging Face token
- HUGGING_FACE_HUB_TOKEN=
ports:
- 8000
commands:
- conda install cuda # Required since vLLM will rebuild the CUDA kernel
- pip install vllm
- python -m vllm.entrypoints.openai.api_server --model $MODEL --port 8000然后你所要做的就是运行命令:
dstack run . -f vllm/serve.dstack.yml原文链接:7 Frameworks for Serving LLMs
BimAnt翻译整理,转载请标明出处





